

Meituan のインタビューでの質問: SQL が遅いと感じたことはありますか?どのように解決されましたか?
# SQL が遅いということで、面接官と長時間雑談しましたが、面接官もとても謙虚で、いつもうなずいてくれたので、大丈夫だと思いました。 最後に、「戻って通知を待ちましょう!」と言いました。

#そこで、この遅い SQL テクノロジを皆さんと共有することにしました。次回同様の面接に遭遇した際には、スムーズかつ簡単に希望する内定を獲得できることを願っています。
人生の最大の喜びは、誰もがそれをできないと言っているにもかかわらず、あなたがそれをやり遂げることです!
Slow SQL とは何ですか?
MySQL のスロー クエリ ログは、MySQL が提供するログ レコードで、クエリ時間が設定されたしきい値 (long_query_time) を超えた (超過した) MySQL ステートメントを記録するために使用されます。スロークエリログ。中央。
このうち、long_query_time のデフォルト値は 10、単位は秒、つまり SQL クエリ時間が 10 秒を超えると、デフォルトでは遅い SQL とみなされます。
遅い SQL ログを有効にするにはどうすればよいですか?
MySQL では、遅い SQL ログはデフォルトでオンになっていないため、遅い SQL が発生しても通知されません。どの SQL が低速 SQL であるかは、低速 SQL ログを手動で有効にする必要があります。
遅い SQL が有効かどうかについては、次のコマンドで確認できます。
-- 查看慢查询日志是否开启 show variables like '%slow_query_log%';
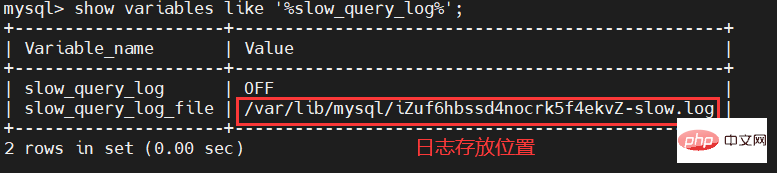
コマンドを通じて、slow_query_log 項目が OFF であることがわかります。これは、低速 SQL ログがオンになっていないことを示しています。さらに、遅い SQL ログが保存されているディレクトリとログ ファイルの名前も確認できます。
遅い SQL ログを有効にして、次のコマンドを実行しましょう:
set global slow_query_log = 1;
ここで有効になっているのは現在のデータベースであり、データベースを再起動すると無効になることに注意してください。 。
低速 SQL ログを有効にした後、もう一度確認してください:
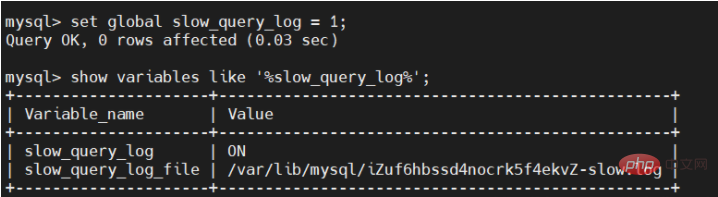
slow_query_log 項目に次のエラーが含まれていますON になるとアクティベーションが成功したことを意味します。
上で述べたように、遅い SQL のデフォルト時間は 10 秒です。次のコマンドで遅い SQL のデフォルト時間を確認できます:
show variables like '%long_query_time%';
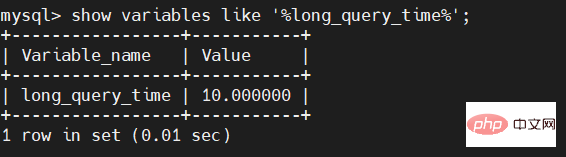
このデフォルト値を常に使用できるわけではありません。多くのビジネスでは、これより短いまたは長い時間が必要になる可能性があるため、現時点では、デフォルト時間を変更する必要があります。変更コマンドは次のとおりです:
set long_query_time = 3;
変更が完了しました。3 秒に変更されたかどうかを確認してみましょう。
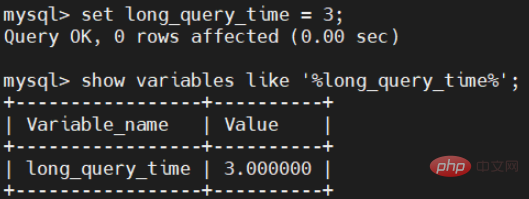
ここで注意してください: 永続的に有効にしたい場合は、構成ファイルも変更する必要があります。私のMySQL.cnfファイルの下にあります。
[mysqld] slow_query_log=1 slow_query_log_file=/var/lib/mysql/atguigu-slow.log long_query_time=3 log_output=FILE
注: オペレーティング システムが異なれば、構成も異なります。
Linux オペレーティング システムの場合
mysql 設定ファイル my.cnf に
#log-slow-queries=/var/lib/mysql/slowquery.log を追加します。 (ログ ファイルの保存場所を指定します。空でもかまいません。システムにより、デフォルト ファイル host_name-slow.log が与えられます)long_query_time=2 (超過した時間を記録します。デフォルトは 10 秒です)log-queries-not-using-indexes (log下来没有使用索引的query,可以根据情况决定是否开启)
log-long-format (如果设置了,所有没有使用索引的查询也将被记录)
Windows操作系统中
在my.ini的[mysqld]添加如下语句:
log-slow-queries = E:\web\mysql\log\mysqlslowquery.log
long_query_time = 3(其他参数如上)
执行一条慢SQL,因为我们前面已经设置好了慢SQL时间为3秒,所以,我们只要执行一条SQL时间超过3秒即可。
SELECT SLEEP(4);
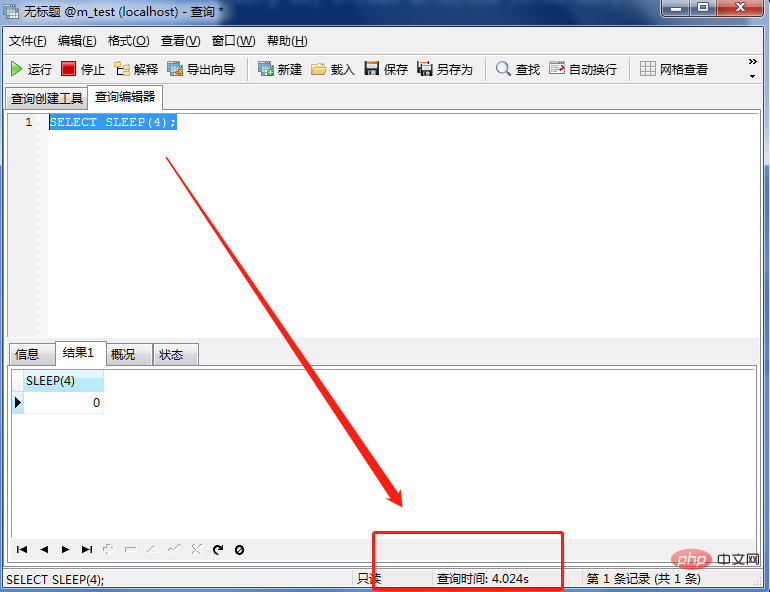
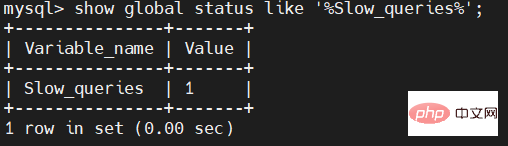
该SQL耗时4.024秒,下面我们就来查看慢SQL出现了多少条。
使用命令:
show global status like '%Slow_queries%';
查询SQL历程
找到慢SQL日志文件,打开后就会出现类似下面这样的语句;
# Time: 2021-07-20T09:17:49.791767Z # User@Host: root[root] @ localhost [] Id: 150 # Query_time: 0.002549 Lock_time: 0.000144 Rows_sent: 1 Rows_examined: 4079 SET timestamp=1566292669; select * from city where Name = 'Salala';
简单说明:
1.Time 该日志记录的时间
2.User @Host MySQL登录的用户和登录的主机地址
3.Query_time一行 第一个时间是查询的时间、第二个是锁表的时间、第三个是返回的行数、第四个是扫描的行数
4.SET timestamp 这一个是MySQL查询的时间
5.sql语句 这一行就很明显了,表示的是我们执行的sql语句
切记
long_query_time=0 を設定すると、すべてのクエリ SQL ステートメントが低速 SQL ログ ファイルに出力されることになります。
遅い SQL を見つけるにはどうすればよいですか?
通常、遅い SQL を見つけるには 2 つの方法があります。
最初の方法: 遅いクエリを見つける SQL は 2 つの表現を使用できます。
システム レベルの症状を特定します。 sar コマンドを使用し、 top現在のシステム ステータスを表示するコマンド Prometheus および Grafana 監視ツールを使用して、システム ステータスを表示することもできます。現在のシステム ステータス CPU消費が深刻です IO待機が深刻です ページの応答時間が長すぎます プロジェクト ログにタイムアウトやその他のエラーがあります -
SQL ステートメントの表現: SQL長いステートメント SQLステートメントの実行時間が長すぎます SQLフル テーブル スキャンからデータを取得 実行計画の rows と costVery big
2 番目: 異なるデータベースに応じて異なる方法を使用して問題を取得しますSQL
MySQL: 慢查询日志 测试工具loadrunner ptquery工具 Oracle: AWR报告 测试工具loadrunner 相关内部视图vsession_wait GRID CONTROL监控工具
熟悉慢SQL日志分析工具吗?
如果开启了慢SQL日志后,可能会有大量的慢SQL日志产生,此时再用肉眼看,那是不太现实的,所以大佬们就给我搞了个工具:mysqldumpslow。
mysqldumpslow能将相同的慢SQL归类,并统计出相同的SQL执行的次数,每次执行耗时多久、总耗时,每次返回的行数、总行数,以及客户端连接信息等。
通过命令
mysqldumpslow --help
可以看到相关参数的说明:
~# mysqldumpslow --help
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time比较常用的参数有这么几个:
-s 指定输出的排序方式 t : 根据query time(执行时间)进行排序; at : 根据average query time(平均执行时间)进行排序;(默认使用的方式) l : 根据lock time(锁定时间)进行排序; al : 根据average lock time(平均锁定时间)进行排序; r : 根据rows(扫描的行数)进行排序; ar : 根据average rows(扫描的平均行数)进行排序; c : 根据日志中出现的总次数进行排序; -t 指定输出的sql语句条数; -a 不进行抽象显示(默认会将数字抽象为N,字符串抽象为S); -g 满足指定条件,与grep相似; -h 用来指定主机名(指定打开文件,通常慢查询日志名称为“主机名-slow.log”,用-h exp则表示打开exp-slow.log文件);
使用方式
mysqldumpslow常用的使用方式如下:
# mysqldumpslow -s c slow.log
如上一条命令,应该是mysqldumpslow最简单的一种形式,其中-s参数是以什么方式排序的意思,c指代的是以总数从大到小的方式排序。-s的常用子参数有:c: 相同查询以查询条数和从大到小排序。t: 以查询总时间的方式从大到小排序。l: 以查询锁的总时间的方式从大到小排序。at: 以查询平均时间的方式从大到小排序。al: 以查询锁平均时间的方式从大到小排序。
同样的,还可以增加其他参数,实际使用的时候,按照自己的情况来。
其他常用方式:
# 得到返回记录集最多的10 个SQL mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log # 得到访问次数最多的10 个SQL mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log # 得到按照时间排序的前10 条里面含有左连接的查询语句 mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log # 另外建议在使用这些命令时结合| 和more 使用,否则有可能出现爆屏情况 mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
接下,我们来个实际操作。
实操
root@yunzongjitest1:~# mysqldumpslow -s t -t 3 Reading mysql slow query log from /var/lib/mysql/exp-slow.log /var/lib/mysql/yunzongjitest1-slow.log Count: 464 Time=18.35s (8515s) Lock=0.01s (3s) Rows=90884.0 (42170176), root[root]@localhost select ************ Count: 38 Time=11.22s (426s) Lock=0.00s (0s) Rows=1.0 (38), root[root]@localhost select *********** not like 'S' Count: 48 Time=5.07s (243s) Lock=0.02s (1s) Rows=1.0 (48), root[root]@localhost select ********='S'
这其中的SQL语句因为涉及某些信息,所以我都用*号将主体替换了,如果希望得到具体的值,使用-a参数。
使用mysqldumpslow查询出来的摘要信息,包含了这些内容:
Count: 464 :表示慢查询日志总共记录到这条sql语句执行的次数;
Time=18.35s (8515s):18.35s表示平均执行时间(-s at),8515s表示总的执行时间(-s t);
Lock=0.01s (3s):与上面的Time相同,第一个表示平均锁定时间(-s al),括号内的表示总的锁定时间(-s l)(也有另一种说法,说是表示的等待锁释放的时间);
Rows=90884.0 (42170176): 最初の値はスキャンされた行の平均数 (-s ar) を示し、括弧内の値はスキャンされた行の合計数 (-s r) を示します。
以上がMeituan のインタビューでの質問: SQL が遅いと感じたことはありますか?どのように解決されましたか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7345
7345
 15
1627
14
1352
46
1265
25
1214
29
15
1627
14
1352
46
1265
25
1214
29

 Hibernate フレームワークにおける HQL と SQL の違いは何ですか?
Apr 17, 2024 pm 02:57 PM
Hibernate フレームワークにおける HQL と SQL の違いは何ですか?
Apr 17, 2024 pm 02:57 PM
HQL と SQL は Hibernate フレームワークで比較されます。HQL (1. オブジェクト指向構文、2. データベースに依存しないクエリ、3. タイプ セーフティ)、SQL はデータベースを直接操作します (1. データベースに依存しない標準、2. 複雑な実行可能ファイル)。クエリとデータ操作)。
 Oracle SQLでの除算演算の使用法
Mar 10, 2024 pm 03:06 PM
Oracle SQLでの除算演算の使用法
Mar 10, 2024 pm 03:06 PM
「OracleSQLでの除算演算の使用方法」 OracleSQLでは、除算演算は一般的な数学演算の1つです。データのクエリと処理中に、除算演算はフィールド間の比率を計算したり、特定の値間の論理関係を導出したりするのに役立ちます。この記事では、OracleSQL での除算演算の使用法を紹介し、具体的なコード例を示します。 1. OracleSQL における除算演算の 2 つの方法 OracleSQL では、除算演算を 2 つの異なる方法で実行できます。
 Oracle と DB2 の SQL 構文の比較と相違点
Mar 11, 2024 pm 12:09 PM
Oracle と DB2 の SQL 構文の比較と相違点
Mar 11, 2024 pm 12:09 PM
Oracle と DB2 は一般的に使用される 2 つのリレーショナル データベース管理システムであり、それぞれに独自の SQL 構文と特性があります。この記事では、Oracle と DB2 の SQL 構文を比較し、相違点を示し、具体的なコード例を示します。データベース接続 Oracle では、次のステートメントを使用してデータベースに接続します: CONNECTusername/password@database DB2 では、データベースに接続するステートメントは次のとおりです: CONNECTTOdataba
 SQL の ID 属性は何を意味しますか?
Feb 19, 2024 am 11:24 AM
SQL の ID 属性は何を意味しますか?
Feb 19, 2024 am 11:24 AM
SQL における Identity とは何ですか? 具体的なコード例が必要です。SQL では、Identity は自動インクリメント数値の生成に使用される特別なデータ型です。多くの場合、テーブル内のデータの各行を一意に識別するために使用されます。 Identity 列は、各レコードが一意の識別子を持つようにするために、主キー列と組み合わせてよく使用されます。この記事では、Identity の使用方法といくつかの実用的なコード例について詳しく説明します。 Identity の基本的な使用方法は、テーブルを作成するときに Identity を使用することです。
 MyBatis動的SQLタグのSetタグ機能の詳細説明
Feb 26, 2024 pm 07:48 PM
MyBatis動的SQLタグのSetタグ機能の詳細説明
Feb 26, 2024 pm 07:48 PM
MyBatis 動的 SQL タグの解釈: Set タグの使用法の詳細な説明 MyBatis は、豊富な動的 SQL タグを提供し、データベース操作ステートメントを柔軟に構築できる優れた永続層フレームワークです。このうち、Set タグは、UPDATE ステートメントで SET 句を生成するために使用され、更新操作でよく使用されます。この記事では、MyBatis での Set タグの使用法を詳細に説明し、特定のコード例を通じてその機能を示します。 SetタグとはMyBatiで使用するSetタグです。
 Java は MySQL ドライバー インターセプターをどのように使用して、時間のかかる SQL 計算を実装しますか?
May 27, 2023 pm 01:10 PM
Java は MySQL ドライバー インターセプターをどのように使用して、時間のかかる SQL 計算を実装しますか?
May 27, 2023 pm 01:10 PM
背景: 企業のニーズの 1 つは、企業の既存のリンク トラッキング ログ コンポーネントが MySQL の SQL 実行時間の出力をサポートする必要があるということです。リンク トラッキングを実装する一般的な方法は、サードパーティのフレームワークまたはツールによって提供されるインターセプタ インターフェイスまたはフィルタ インターフェイスを実装することです。 MySQL も例外ではなく、実際には、MySQL によって駆動されるインターセプタ インターフェイスを実装しているだけです。 MySQL チャネルにはさまざまなバージョンがあり、バージョンごとにインターセプタ インターフェイスが異なるため、使用する MySQL ドライバのバージョンに応じて応答インターセプタを実装する必要があります。次に、MySQL チャネル 5 と 6 をそれぞれ紹介します8。バージョンの実装。ここでは、Statem を実装する例として MySQL チャネル 5.1.18 バージョンを使用して MySQL5 を実装します。
 SQL の 5120 エラーを解決する方法
Mar 06, 2024 pm 04:33 PM
SQL の 5120 エラーを解決する方法
Mar 06, 2024 pm 04:33 PM
解決策: 1. ログインしているユーザーがデータベースにアクセスまたは操作するための十分な権限を持っているかどうかを確認し、ユーザーが正しい権限を持っているかどうかを確認します; 2. SQL Server サービスのアカウントに指定されたファイルまたはデータベースにアクセスする権限があるかどうかを確認します。 3. 指定されたデータベース ファイルが他のプロセスによって開かれているかロックされているかどうかを確認し、ファイルを閉じるか解放して、クエリを再実行します。管理者として試してください。Management Studio をなどとして実行します。
 MySQL でデータの集計と統計に SQL ステートメントを使用するにはどうすればよいですか?
Dec 17, 2023 am 08:41 AM
MySQL でデータの集計と統計に SQL ステートメントを使用するにはどうすればよいですか?
Dec 17, 2023 am 08:41 AM
MySQL でデータの集計と統計に SQL ステートメントを使用するにはどうすればよいですか?データの集計と統計は、データ分析と統計を実行する際の非常に重要な手順です。 MySQL は強力なリレーショナル データベース管理システムとして、データの集約と統計操作を簡単に実行できる豊富な集約機能と統計機能を提供します。この記事では、SQL ステートメントを使用して MySQL でデータの集計と統計を実行する方法を紹介し、具体的なコード例を示します。 1. カウントには COUNT 関数を使用します。COUNT 関数は最も一般的に使用されます。
