

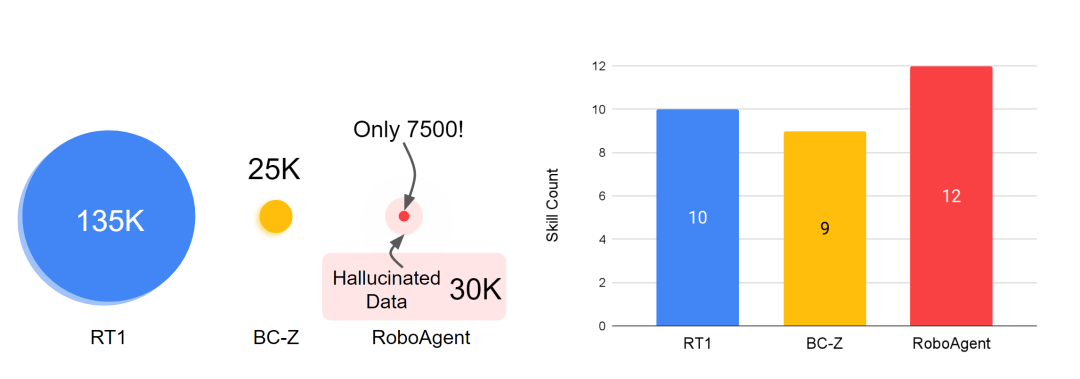
7,500 の軌道データ、CMU および Meta を使用したトレーニングにより、ロボットはオールラウンドなリビングルームとキッチンのレベルに到達できます。

このロボットは、7500 の軌跡データを使用してトレーニングするだけで、ピッキングやプッシュに限定されず、関節オブジェクトの操作やオブジェクトの位置変更など、38 のタスクで 12 の異なる操作スキルを実証できます。さらに、これらのスキルは、未知の物体、未知の作業、さらにはまったく未知のキッチン環境など、何百もの異なる未知の状況に適用できます。こういうロボットって本当にカッコいいですね!

何十年もの間、多様な環境で任意の物体を操作できるロボットを作成することは、とらえどころのない目標でした。理由の 1 つは、そのようなエージェントをトレーニングするための多様なロボット データセットが不足していること、およびそのようなデータセットを生成できる汎用エージェントが不足していることです。
この問題を克服するには、カーネギー メロン大学の著者と Meta AI は、2 年をかけてユニバーサル RoboAgent を開発しました。彼らの主な目標は、限られたデータで複数のスキルを備えた一般的なエージェントをトレーニングし、これらのスキルをさまざまな未知の状況に一般化できる効率的なパラダイムを開発することです

RoboAgent はモジュール式で構成されています:
- #RoboPen - 長期ノンストップ運用を可能にする汎用ハードウェアで構築された分散ロボット インフラストラクチャ; #RoboHive - シミュレーションおよび現実世界の操作におけるロボット学習のための統合フレームワーク;
- RoboSet - さまざまなシナリオで日常の物体を使用する複数のスキルを表す高品質のデータセット。
- MT-ACT - 効率的な言語条件付きマルチタスクオフライン模倣学習フレームワーク。既存のロボットの経験に基づいて意味的に強化された多様なコレクションを作成し、それによってオフラインデータセットを拡張し、限られたデータ予算戦略の下で良好なパフォーマンスを回復するための、新しいポリシー アーキテクチャと効率的なアクション表現方法。
さまざまな分野で一般化できるデータ セットを構築しますさまざまな状況 ロボット エージェントはまず、広範囲をカバーするデータ セットを必要とします。スケールアップの取り組みが役立つ場合が多いことを考えると(たとえば、RT-1 は約 130,000 のロボット軌道で結果を実証しました)、限られたデータセット、多くの場合低データのコンテキストで学習システムの効率と汎化原理を理解する必要があります。過学習につながります。したがって、著者らの主な目標は、過剰適合の問題を回避しながら、低データ状況で一般化可能な一般戦略を学習できる強力なパラダイムを開発することです。
 #ロボット学習におけるスキルとデータのパノラマは重要な分野です。ロボット学習におけるスキルとは、ロボットが学習とトレーニングを通じて獲得し、特定のタスクを実行するために使用できる能力を指します。これらのスキルの開発は、大量のデータのサポートから切り離すことはできません。データはロボット学習の基礎であり、データを分析および処理することで、ロボットはデータから学習し、スキルを向上させることができます。したがって、スキルとデータはロボット学習に不可欠な 2 つの側面です。継続的に学習して新しいデータを取得することによってのみ、ロボットはスキル レベルを向上し続け、さまざまなタスクでより高い知能と効率を発揮できます
#ロボット学習におけるスキルとデータのパノラマは重要な分野です。ロボット学習におけるスキルとは、ロボットが学習とトレーニングを通じて獲得し、特定のタスクを実行するために使用できる能力を指します。これらのスキルの開発は、大量のデータのサポートから切り離すことはできません。データはロボット学習の基礎であり、データを分析および処理することで、ロボットはデータから学習し、スキルを向上させることができます。したがって、スキルとデータはロボット学習に不可欠な 2 つの側面です。継続的に学習して新しいデータを取得することによってのみ、ロボットはスキル レベルを向上し続け、さまざまなタスクでより高い知能と効率を発揮できます
RoboAgent のトレーニングに使用されるデータセット RoboSet (MT-ACT) には、7,500 個の軌跡しか含まれていません (RT-1 のデータの 18 分の 1)。このデータセットは事前に収集され、凍結されたままになります。このデータセットは、汎用ロボット ハードウェア (Robotiq グリッパーを備えた Franka-Emika ロボット) を使用した人間の遠隔操作中に、複数のタスクとシナリオにわたって収集された高品質の軌跡で構成されています。 RoboSet (MT-ACT) は、いくつかの異なる状況における 12 の固有のスキルをまばらにカバーしています。データは、毎日のキッチン活動 (お茶を入れる、パンを焼くなど) をさまざまなサブタスクに分割することによって収集され、それぞれが独自のスキルを表します。データセットには、一般的なピック アンド プレイス スキルだけでなく、拭く、蓋をする、多関節オブジェクトに関連するスキルなどの接触が多いスキルも含まれています。 書き直された内容: RoboAgent のトレーニングに使用されるデータセットである RoboSet (MT-ACT) には、わずか 7,500 個の軌跡が含まれています (RT-1 のデータより 18 分の 1)。このデータセットは事前に収集され、凍結されたままになります。このデータセットは、汎用ロボット ハードウェア (Robotiq グリッパーを備えた Franka-Emika ロボット) を使用した人間の遠隔操作中に、複数のタスクとシナリオにわたって収集された高品質の軌跡で構成されています。 RoboSet (MT-ACT) は、いくつかの異なる状況における 12 の固有のスキルをまばらにカバーしています。データは、毎日のキッチン活動 (お茶を入れる、パンを焼くなど) をさまざまなサブタスクに分割することによって収集され、それぞれが独自のスキルを表します。データセットには、一般的なピック アンド プレイス スキルだけでなく、ワイピング、キャッピング、多関節オブジェクトに関連するスキルなどの接触が豊富なスキルも含まれています

# MT- ACT: マルチタスク アクション チャンキング トランスフォーマー
RoboAgent は、2 つの重要な洞察に基づいて、低データ状況における共通ポリシーを学習します。これは、基礎となるモデルの世界に関する事前知識を活用してモード崩壊を回避し、高度にマルチモーダルなデータを取り込むことができる新しい効率的な表現戦略を採用します。 1. セマンティック強化: RoboAgent は、セマンティック強化により、既存の基本モデルから世界の事前知識を RoboSet (MT-ACT) に注入します。結果として得られるデータセットは、追加の人的コストやロボットコストを発生させることなく、ロボットの経験と世界に関する事前知識を組み合わせたものです。 SAM を使用してターゲット オブジェクトをセグメント化し、形状、色、テクスチャの変更に関して意味的に強化します。 書き換えられた内容: 1. セマンティック強化: RoboAgent は、セマンティック強化により、既存の基本モデルから世界の事前知識を RoboSet (MT-ACT) に注入します。このようにして、人間やロボットに追加のコストをかけることなく、ロボットの経験と世界に関する事前知識を組み合わせることができます。 SAM を使用してターゲット オブジェクトをセグメント化し、形状、色、テクスチャの変更に関してセマンティック拡張を実行します
#2. 効率的な戦略表現: 結果として得られるデータセットは非常にマルチモーダルであり、豊富な情報が含まれています。さまざまなスキル、タスク、シナリオ。私たちはアクション チャンキング手法をマルチタスク設定に適用し、過剰適合を回避しながら少量のデータで高度にマルチモーダルなデータセットを取得できる、斬新で効率的なポリシー表現 (MT-ACT) を開発します。
##実験結果

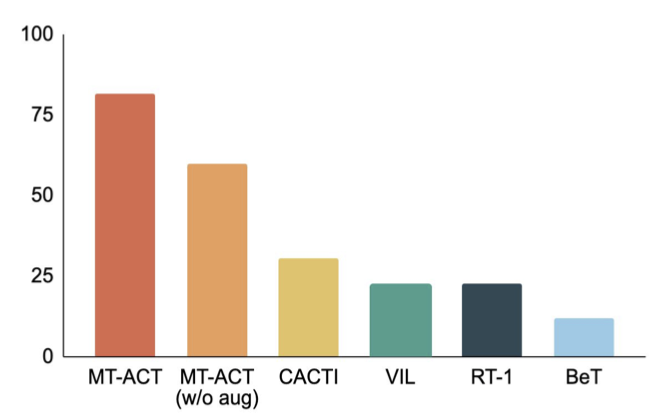
次の図は、著者が提案した MT-ACT 戦略表現といくつかの模倣学習アーキテクチャを比較しています。作成者は、オブジェクトのポーズの変更や部分的な照明の変更などの環境変更のみを使用します。以前の研究と同様に、著者らはこれが L1 一般化によるものであると考えています。 RoboAgent の結果から、アクション チャンキングを使用してサブ軌道をモデル化することは、すべてのベースライン手法よりも大幅に優れていることが明らかです。したがって、サンプル効率の学習における著者の提案した戦略表現の有効性がさらに証明されています
RoboAgent は複数の抽象化レベルで優れています
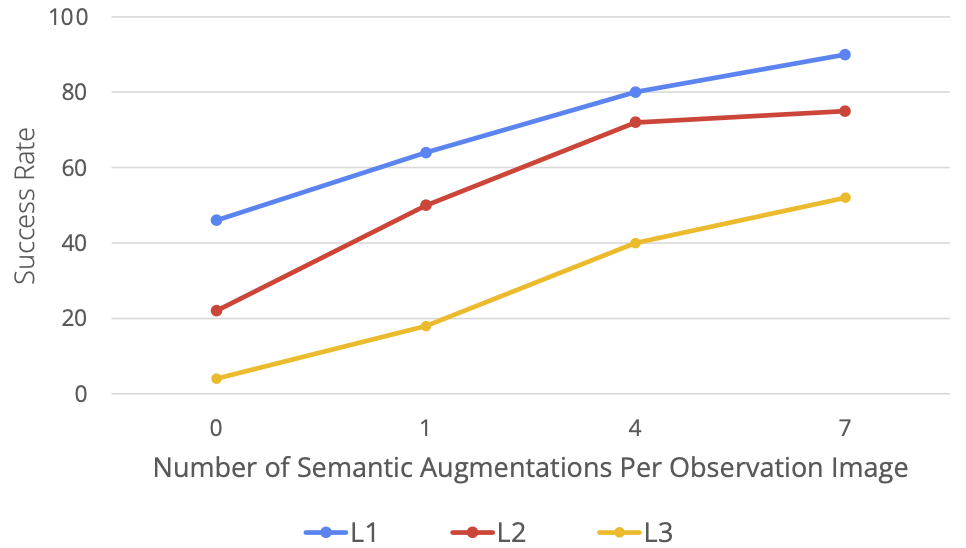
次の図は、著者がさまざまな一般化レベルでメソッドをテストした結果を示しています。同時に、一般化レベルも視覚化によって示されます。L1 はオブジェクトのポーズの変化を表し、L2 はさまざまなデスクトップの背景と干渉要因を表し、L3 は新しいスキルとオブジェクトの組み合わせを表します。次に、著者らは、各手法がこれらの一般化レベルでどのように機能するかを示します。厳密な評価研究では、MT-ACT は、特に一般化のより難しいレベル (L3) ## RoboAgent は拡張性が高い 著者らは、セマンティック強化のレベルを上げながら RoboAgent のパフォーマンスを評価し、それをアクティビティで評価される 5 つのスキルで示しました。以下の図からわかるように、データが増加すると (つまり、フレームあたりの拡張の数が増加すると)、一般化のすべてのレベルでパフォーマンスが大幅に向上します。特に注目に値するのは、より困難なタスク (L3 汎化) では、パフォーマンスの向上がより明白であることです。 RoboAgent は次のことを行うことができます。さまざまな活動で彼のスキルを実証する ##


以上が7,500 の軌道データ、CMU および Meta を使用したトレーニングにより、ロボットはオールラウンドなリビングルームとキッチンのレベルに到達できます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7517
7517
 15
1378
52
79
11
21
66
15
1378
52
79
11
21
66

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
何?ズートピアは国産AIによって実現するのか?ビデオとともに公開されたのは、「Keling」と呼ばれる新しい大規模な国産ビデオ生成モデルです。 Sora も同様の技術的ルートを使用し、自社開発の技術革新を多数組み合わせて、大きく合理的な動きをするだけでなく、物理世界の特性をシミュレートし、強力な概念的結合能力と想像力を備えたビデオを制作します。データによると、Keling は、最大 1080p の解像度で 30fps で最大 2 分の超長時間ビデオの生成をサポートし、複数のアスペクト比をサポートします。もう 1 つの重要な点は、Keling は研究所が公開したデモやビデオ結果のデモンストレーションではなく、ショートビデオ分野のリーダーである Kuaishou が立ち上げた製品レベルのアプリケーションであるということです。さらに、主な焦点は実用的であり、白紙小切手を書かず、リリースされたらすぐにオンラインに移行することです。Ke Ling の大型モデルは Kuaiying でリリースされました。
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 AI はどのようにロボットをより自律的で順応性のあるものにすることができるのでしょうか?
Jun 03, 2024 pm 07:18 PM
AI はどのようにロボットをより自律的で順応性のあるものにすることができるのでしょうか?
Jun 03, 2024 pm 07:18 PM
産業オートメーション技術の分野では、人工知能 (AI) と Nvidia という無視できない 2 つの最近のホットスポットがあります。元のコンテンツの意味を変更したり、コンテンツを微調整したり、コンテンツを書き換えたり、続行しないでください。「それだけでなく、Nvidia はオリジナルのグラフィックス プロセッシング ユニット (GPU) に限定されていないため、この 2 つは密接に関連しています。」このテクノロジーはデジタル ツインの分野にまで広がり、新たな AI テクノロジーと密接に関係しています。「最近、NVIDIA は、Aveva、Rockwell Automation、Siemens などの大手産業オートメーション企業を含む多くの産業企業と提携に至りました。シュナイダーエレクトリック、Teradyne Robotics とその MiR および Universal Robots 企業も含まれます。最近、Nvidiahascoll
 2か月後、人型ロボットWalker Sが服をたたむことができるようになった
Apr 03, 2024 am 08:01 AM
2か月後、人型ロボットWalker Sが服をたたむことができるようになった
Apr 03, 2024 am 08:01 AM
Machine Power Report 編集者: Wu Xin 国内版の人型ロボット + 大型模型チームは、衣服を折りたたむなどの複雑で柔軟な素材の操作タスクを初めて完了しました。 OpenAIのマルチモーダル大規模モデルを統合したFigure01の公開により、国内同業者の関連動向が注目を集めている。つい昨日、中国の「ヒューマノイドロボットのナンバーワン株」であるUBTECHは、Baidu Wenxinの大型モデルと深く統合されたヒューマノイドロボットWalkerSの最初のデモを公開し、いくつかの興味深い新機能を示した。 Baidu Wenxin の大規模モデル機能の恩恵を受けた WalkerS は次のようになります。 Figure01 と同様に、WalkerS は動き回るのではなく、机の後ろに立って一連のタスクを完了します。人間の命令に従って服をたたむことができる
 柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
今週、OpenAI、Microsoft、Bezos、Nvidiaが投資するロボット企業FigureAIは、7億ドル近くの資金調達を受け、来年中に自立歩行できる人型ロボットを開発する計画であると発表した。そしてテスラのオプティマスプライムには繰り返し良い知らせが届いている。今年が人型ロボットが爆発的に普及する年になることを疑う人はいないだろう。カナダに拠点を置くロボット企業 SanctuaryAI は、最近新しい人型ロボット Phoenix をリリースしました。当局者らは、多くのタスクを人間と同じ速度で自律的に完了できると主張している。人間のスピードでタスクを自律的に完了できる世界初のロボットである Pheonix は、各オブジェクトを優しくつかみ、動かし、左右にエレガントに配置することができます。自律的に物体を識別できる
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
