

C++ ビッグ データ開発におけるデータ統計の問題にどう対処するか?


C ビッグデータ開発におけるデータ統計の問題にどう対処するか?
ビッグデータ時代の到来により、データ統計はさまざまな分野で不可欠なものになりました。 C ビッグ データ開発では、有用な情報や洞察を得るために、大量のデータに対して統計分析を実行する必要があることがよくあります。この記事では、C ビッグ データ開発におけるデータ統計の問題を処理するいくつかの方法を紹介し、対応するコード例を示します。
- データ統計に STL ライブラリを使用する
C C 標準ライブラリの STL (標準テンプレート ライブラリ) には、コンテナおよびアルゴリズム用のさまざまなテンプレート クラスと関数が含まれています。便利に保管および処理できます。以下は、STL ライブラリのベクトル コンテナと算術関数を使用して、一連の整数の合計、平均、最大値を計算する方法を示す簡単な例です。
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
int sum = std::accumulate(data.begin(), data.end(), 0); // 计算总和
double average = static_cast<double>(sum) / data.size(); // 计算平均值
int max = *std::max_element(data.begin(), data.end()); // 计算最大值
std::cout << "Sum: " << sum << std::endl;
std::cout << "Average: " << average << std::endl;
std::cout << "Max: " << max << std::endl;
return 0;
}- 効率化のためにサードパーティ ライブラリを使用します。データ統計
STL ライブラリに加えて、C にはデータ統計をより効率的に実行するために使用できる多くのサードパーティ ライブラリもあります。たとえば、Boost ライブラリには、さまざまな統計計算を簡単に実行できる豊富な数学関数と統計関数が用意されています。以下は、線形回帰分析に Boost ライブラリを使用する例です。
#include <iostream>
#include <vector>
#include <boost/math/statistics/linear_regression.hpp>
int main() {
std::vector<double> x = {1.0, 2.0, 3.0, 4.0, 5.0};
std::vector<double> y = {2.0, 4.0, 6.0, 8.0, 10.0};
boost::math::statistics::linear_regression<double> reg;
reg.add(x.begin(), x.end(), y.begin(), y.end());
double slope = reg.slope();
double intercept = reg.intercept();
std::cout << "Slope: " << slope << std::endl;
std::cout << "Intercept: " << intercept << std::endl;
return 0;
}- データ統計を高速化するための並列コンピューティング
ビッグ データ開発では、データの量は次のとおりです。多くの場合、非常に大きくなり、単一のスレッド計算では遅すぎる可能性があります。並列コンピューティング テクノロジを使用すると、データ統計の速度が向上します。 C には、OpenMP や TBB など、並列コンピューティングを可能にするライブラリがあります。以下は、並列合計に OpenMP ライブラリを使用する例です。
#include <iostream>
#include <vector>
#include <omp.h>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
int sum = 0;
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < data.size(); ++i) {
sum += data[i];
}
std::cout << "Sum: " << sum << std::endl;
return 0;
}上の例は、STL ライブラリ、サードパーティ ライブラリ、および並列コンピューティングを使用して、C ビッグ データ開発におけるデータ統計の問題を処理する方法を示しています。テクノロジー。もちろん、これは氷山の一角にすぎません。C には他にも統計用の強力な機能やツールが多数あります。この記事が読者に参考とインスピレーションを提供し、C ビッグ データ開発におけるデータ統計の問題にもっと効率的に対処できるようになれば幸いです。
以上がC++ ビッグ データ開発におけるデータ統計の問題にどう対処するか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7533
7533
 15
1379
52
82
11
21
86
15
1379
52
82
11
21
86

 Oracleでテーブルがロックされる理由とその対処方法
Mar 03, 2024 am 09:36 AM
Oracleでテーブルがロックされる理由とその対処方法
Mar 03, 2024 am 09:36 AM
Oracle でテーブル ロックが発生する理由とその対処方法 Oracle データベースでは、テーブル ロックが一般的な現象であり、テーブル ロックが発生する理由は数多くあります。この記事では、テーブルがロックされる一般的な理由をいくつか検討し、いくつかの処理方法と関連するコード例を示します。 1. ロックの種類 Oracleデータベースでは、ロックは主に共有ロック(SharedLock)と排他ロック(ExclusiveLock)に分けられます。共有ロックは読み取り操作に使用され、複数のセッションが同じリソースを同時に読み取ることができます。
 JSON の処理方法と C++ での実装
Aug 21, 2023 pm 11:58 PM
JSON の処理方法と C++ での実装
Aug 21, 2023 pm 11:58 PM
JSON は、読み取りと書き込みが簡単で、マシンによる解析と生成も簡単な軽量のデータ交換形式です。 JSON 形式を使用すると、さまざまなシステム間でのデータ転送が簡単になります。 C++ には、JSON 処理用のオープンソース JSON ライブラリが多数あります。この記事では、一般的に使用される JSON 処理メソッドと C++ での実装をいくつか紹介します。 C++ での JSON 処理メソッド RapidJSON RapidJSON は、DOM、SAX、および
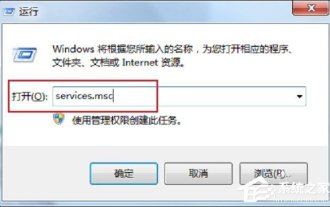 Win7 システムで使用できない RPC サーバーを処理する方法
Jul 19, 2023 pm 04:57 PM
Win7 システムで使用できない RPC サーバーを処理する方法
Jul 19, 2023 pm 04:57 PM
コンピュータを使用する過程で、私たちはしばしばいくつかの問題に遭遇し、その中には人々を圧倒する可能性があるものもあります。一部のユーザーはこの問題に遭遇します。コンピュータの電源を入れてプリンタを使用すると、RPC サーバーが利用できないというメッセージがポップアップ表示されます。どうしたの?私は何をしますか?この問題に対応して、Win7rpc サーバーが利用できない場合の解決策を共有しましょう。 1. Win+R キーを押して「ファイル名を指定して実行」を開き、「ファイル名を指定して実行」入力ボックスに「services.msc」と入力します。 2. サービス リストを入力したら、RemoteProcedureCall(RPC)Locator サービスを見つけます。 3. サービスを選択してダブルクリックします。デフォルトの状態は次のとおりです: 4. RPCLoader サービスのスタートアップの種類を自動に変更します。
 C++ 開発における配列の範囲外の問題に対処する方法
Aug 21, 2023 pm 10:04 PM
C++ 開発における配列の範囲外の問題に対処する方法
Aug 21, 2023 pm 10:04 PM
C++ 開発における配列の範囲外の問題に対処する方法 C++ 開発では、配列の範囲外は一般的なエラーであり、プログラムのクラッシュ、データの破損、さらにはセキュリティの脆弱性につながる可能性があります。したがって、配列の範囲外の問題を正しく処理することは、プログラムの品質を確保する上で重要です。この記事では、開発者が配列の範囲外の問題を回避するのに役立ついくつかの一般的な処理方法と提案を紹介します。まず、配列の範囲外の問題の原因を理解することが重要です。配列の範囲外とは、配列にアクセスするときにインデックスの定義範囲を超えることを指します。これは通常、次のシナリオで発生します: 配列にアクセスするときに負の数値が使用される
 PHP 関数を使用して大量のデータを処理する方法
Jun 16, 2023 am 10:45 AM
PHP 関数を使用して大量のデータを処理する方法
Jun 16, 2023 am 10:45 AM
インターネットの発展により、私たちは毎日大量のデータにさらされ、保存、処理、分析する必要があります。 PHP は、現在広く使用されているサーバー側スクリプト言語であり、大規模なデータ処理にも使用されます。大規模なデータを処理する場合、メモリ オーバーフローやパフォーマンスのボトルネックに直面しやすくなります。この記事では、PHP 関数を使用して大量のデータを処理する方法を紹介します。 1. メモリ制限をオンにする デフォルトでは、PHP のメモリ制限サイズは 128M ですが、大量のデータを処理する場合に問題になる可能性があります。より大きなものを扱うには
 MySQL 接続エラー 1017 が発生した場合はどうすればよいですか?
Jun 30, 2023 am 11:57 AM
MySQL 接続エラー 1017 が発生した場合はどうすればよいですか?
Jun 30, 2023 am 11:57 AM
MySQL 接続エラー 1017 に対処するにはどうすればよいですか? MySQL は、Web サイトの開発やデータ ストレージで広く使用されているオープン ソースのリレーショナル データベース管理システムです。ただし、MySQL を使用すると、さまざまなエラーが発生する可能性があります。一般的なエラーの 1 つは、接続エラー 1017 (MySQL エラー コード 1017) です。接続エラー 1017 は、データベース接続の失敗を示します。通常、ユーザー名またはパスワードが間違っていることが原因で発生します。 MySQL が指定されたユーザー名とパスワードを使用した認証に失敗した場合
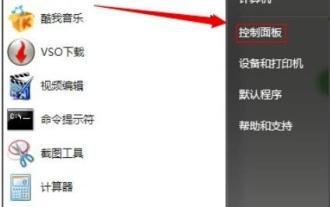 win7 でのメモリ使用量が多い問題を解決する手順
Dec 27, 2023 pm 10:27 PM
win7 でのメモリ使用量が多い問題を解決する手順
Dec 27, 2023 pm 10:27 PM
コンピュータのメモリ容量はコンピュータの動作のスムーズさに依存しており、時間の経過とともにメモリがいっぱいになり、使用量が多すぎるため、コンピュータの動作が遅くなります。以下の解決策を見てみましょう。 Windows 7 のメモリ使用量が高すぎる場合の対処方法: 方法 1. 自動更新を無効にする 1. [スタート] をクリックして [コントロール パネル] を開きます。 2. [Windows Update] をクリックします。 3. 左側の [設定の変更] をクリックします。 「アップデートを確認しない」方法 2. ソフトウェアの削除: 不要なソフトウェアをすべてアンインストールします。方法 3: プロセスを閉じて、不要なプロセスをすべて終了します。そうしないと、バックグラウンドで多数の広告が表示されてメモリがいっぱいになってしまいます。方法 4: サービスを無効にする システム内の不要なサービスの多くも閉じられるため、セキュリティが確保されるだけでなく、スペースも節約されます。
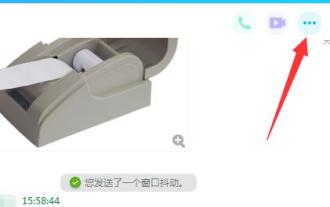 QQ リモート デスクトップ接続の問題を解決する方法
Dec 26, 2023 am 11:55 AM
QQ リモート デスクトップ接続の問題を解決する方法
Dec 26, 2023 am 11:55 AM
QQはテンセント社のチャットソフトで、ほとんどの人がQQアカウントを持っていてチャット時にリモート接続して操作することができますが、一部のユーザーでは接続できないという問題が発生する場合があります。以下を見てみましょう。 QQ リモート デスクトップが接続できない場合の対処方法: 1. チャット インターフェイスを開き、右上隅にある [...] アイコンをクリックします。 2. 赤いコンピューター アイコンを選択し、[設定] をクリックします。 3. [アクセス許可の設定—>] をクリックします。 4. 「リモート デスクトップによるこのコンピュータへの接続を許可する」にチェックを入れます。
