

C++ を使用して高性能の自然言語処理とインテリジェントな対話を実現するにはどうすればよいですか?


C を使用して高性能の自然言語処理とインテリジェントな対話を実現するにはどうすればよいでしょうか?
はじめに:
自然言語処理 (NLP) とインテリジェントな対話は、人工知能の分野で現在注目の研究分野であり、機械翻訳、テキスト分析、インテリジェントな顧客サービスなどの分野で広く使用されています。この記事では、C を使用して高性能の自然言語処理とインテリジェントな対話を実現する方法を紹介し、コード例を示します。
1. 字句解析
1. 単語分割ツール
テキストの分割は自然言語処理の最初のステップであり、処理には C のオープンソースの単語分割ツールを使用できます。たとえば、MMSEG を使用して中国語のテキストをセグメント化できます。以下は、中国語の単語分割に MMSEG を使用するコード例です:
#include <mmseg/segmenter.h>
void segmentText(const char* text) {
MMSeg::Segmenter segmenter;
if (segmenter.open(text)) {
MMSeg::Chunk chunk;
while (segmenter.getChunk(chunk)) {
cout << chunk.getLexemeText() << endl; // 输出每个词的结果
}
}
}2. 品詞タグ付け
品詞タグ付けは、単語分割結果をさらに意味論的に分析して、より詳細な情報を提供することです。後続の処理のための正確な情報。 ICTCLAS などのオープンソースの中国語品詞タグ付けツールを使用して処理できます。 ICTCLAS を使用した品詞タグ付けのサンプルコードは以下のとおりです。
#include <ICTCLAS50/ICTCLAS50.h>
void posTagging(const char* text) {
ICTCLAS50 ic;
if (ic.ICTCLAS_Init() != 0) {
ic.ICTCLAS_Exit();
return;
}
int len = strlen(text);
const char* result = ic.ICTCLAS_ParagraphProcess(text, len, false);
if (result) {
// 处理标注结果
cout << result << endl;
}
ic.ICTCLAS_Exit();
} 2. 構文解析
構文解析とは、文の構造を解析し、依存関係に基づいた意味解析を行うことです。処理には、Harbin Institute of Technology LTP などのオープンソースの構文解析ツールを使用できます。以下は、構文解析に LTP を使用するサンプル コードです。
#include <ltp/segment_dll.h>
#include <ltp/postag_dll.h>
#include <ltp/parser_dll.h>
void syntacticParsing(const char* text) {
void * segmentor = segmentor_create_segmentor("cws.model");
std::vector<std::string> words;
segmentor_segment(segmentor, text, words);
segmentor_release_segmentor(segmentor);
void * postagger = postagger_create_postagger("pos.model");
std::vector<std::string> tags;
postagger_postag(postagger, words, tags);
postagger_release_postagger(postagger);
void * parser = parser_create_parser("parser.model");
std::vector<int> heads;
std::vector<std::string> deprels;
parser_parse(parser, words, tags, heads, deprels);
parser_release_parser(parser);
for (int i = 0; i < words.size(); ++i) {
cout << words[i] << " " << tags[i] << " " << heads[i] << " " << deprels[i] << endl;
}
} 3. インテリジェント ダイアログ
インテリジェント ダイアログは、ユーザーからの質問に対してインテリジェントな応答を提供するテクノロジーです。 ChatBot などのオープンソースの会話型ボット フレームワークを使用して構築できます。以下は、ChatBot を使用してインテリジェントな対話を実現するためのサンプル コードです。
#include <ChatBot/ChatBot.h>
void chat(const char* question) {
ChatBot chatbot;
chatbot.loadModel("model.dat"); // 加载预训练模型
std::string answer = chatbot.getResponse(question);
cout << answer << endl;
}結論:
この記事では、C を使用して高性能の自然言語処理とインテリジェントな対話を実現する方法を紹介します。オープンソースのツールとフレームワークを使用することで、字句解析、構文解析、インテリジェントな対話機能を迅速に実装できます。この記事の紹介とサンプル コードを通じて、読者が自然言語処理とインテリジェントな対話に C を使用する方法を理解し、それを実際のアプリケーションに適用および拡張できることを願っています。
以上がC++ を使用して高性能の自然言語処理とインテリジェントな対話を実現するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7518
7518
 15
1378
52
80
11
21
67
15
1378
52
80
11
21
67

 PHP の自然言語処理の初心者ガイド
Jun 11, 2023 pm 06:30 PM
PHP の自然言語処理の初心者ガイド
Jun 11, 2023 pm 06:30 PM
人工知能技術の発展に伴い、自然言語処理 (NLP) は非常に重要な技術となっています。 NLP は、人間の言語をよりよく理解して分析し、インテリジェントな顧客サービス、感情分析、機械翻訳などの自動化されたタスクを実現するのに役立ちます。この記事では、PHP を使用した自然言語処理の基本とツールについて説明します。自然言語処理とは 自然言語処理とは、人工知能技術を利用して処理を行う手法です。
 Java ベースの自然言語処理における固有表現認識および関係抽出テクノロジとアプリケーション
Jun 18, 2023 am 09:43 AM
Java ベースの自然言語処理における固有表現認識および関係抽出テクノロジとアプリケーション
Jun 18, 2023 am 09:43 AM
インターネット時代の到来により、私たちの視界には大量の文字情報が氾濫し、人々の情報処理・分析に対するニーズはますます高まっています。同時に、インターネット時代は自然言語処理技術の急速な発展ももたらし、人々がテキストから貴重な情報をより適切に取得できるようになりました。中でも、固有表現認識と関係抽出技術は、自然言語処理アプリケーションの分野における重要な研究方向の 1 つです。 1. 固有表現認識技術 固有表現とは、人、場所、組織、時間、通貨、百科事典の知識、測定用語、職業などを指します。
 自然言語処理: コンピューターが人間の言語を理解して処理できるようにする
Sep 21, 2023 pm 03:53 PM
自然言語処理: コンピューターが人間の言語を理解して処理できるようにする
Sep 21, 2023 pm 03:53 PM
自然言語処理 (NLP) は、人工知能の分野における重要かつ刺激的なテクノロジーであり、その目標は、コンピューターが人間の言語を理解し、解析し、生成できるようにすることです。 NLP の開発は目覚ましい進歩を遂げ、コンピューターが人間とより適切に対話できるようになり、より広範囲のアプリケーションを実現できるようになりました。この記事では、自然言語処理の概念、テクノロジ、アプリケーション、および将来の展望について説明します。自然言語処理の概念. 自然言語処理は、コンピューターが人間の言語を理解して処理できるようにする方法を研究する学問です。人間の言語の複雑さと曖昧さにより、コンピューターは理解と処理において大きな課題に直面しています。 NLP の目標は、コンピューターがテキストから情報を抽出できるようにするアルゴリズムとモデルを開発することです。
 自然言語処理で Java 関数を使用すると、どのように会話型の対話が促進されるでしょうか?
Apr 30, 2024 am 08:03 AM
自然言語処理で Java 関数を使用すると、どのように会話型の対話が促進されるでしょうか?
Apr 30, 2024 am 08:03 AM
Java 関数は、会話型対話のエクスペリエンスを強化するカスタム ソリューションを作成するために NLP で広く使用されています。これらの関数は、テキストの前処理、感情分析、意図認識、エンティティ抽出に使用できます。たとえば、感情分析に Java 関数を使用すると、アプリケーションはユーザーの口調を理解して適切に応答し、会話エクスペリエンスを向上させることができます。
![[Python NLTK] チュートリアル: 簡単に始めて自然言語処理を楽しむ](https://img.php.cn/upload/article/000/465/014/170882721469561.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) [Python NLTK] チュートリアル: 簡単に始めて自然言語処理を楽しむ
Feb 25, 2024 am 10:13 AM
[Python NLTK] チュートリアル: 簡単に始めて自然言語処理を楽しむ
Feb 25, 2024 am 10:13 AM
1. NLTK の概要 NLTK は、Steven Bird と Edward Loper によって 2001 年に作成された、Python プログラミング言語用の自然言語処理ツールキットです。 NLTK は、テキストの前処理、単語の分割、品詞のタグ付け、構文分析、意味分析などを含む幅広いテキスト処理ツールを提供し、開発者が自然言語データを簡単に処理できるようにします。 2.NLTK のインストール NLTK は、次のコマンドを使用してインストールできます。 fromnltk.tokenizeimportWord_tokenizetext="Hello, world!Thisisasampletext."tokens=word_tokenize(te
 Linux システムで IntelliJ IDEA を使用して自然言語処理を構成する方法
Jul 05, 2023 pm 10:45 PM
Linux システムで IntelliJ IDEA を使用して自然言語処理を構成する方法
Jul 05, 2023 pm 10:45 PM
Linux システムでの自然言語処理に IntelliJIDEA を使用するための構成方法 IntelliJIDEA は、複数のプログラミング言語に適した強力な統合開発環境 (IDE) です。この記事では、自然言語処理 (NLP) 開発を容易にするために、Linux システム上で IntelliJIDEA を構成する方法を紹介します。ステップ 1: IntelliJIDEA をダウンロードしてインストールする まず、公式 Web サイト https://www にアクセスする必要があります。
 JavaScript での自然言語処理とテキスト分析を学ぶ
Nov 03, 2023 pm 04:32 PM
JavaScript での自然言語処理とテキスト分析を学ぶ
Nov 03, 2023 pm 04:32 PM
JavaScript で自然言語処理とテキスト分析を学習するには、特定のコード サンプルが必要です。自然言語処理 (NLP) は、人工知能とコンピューター サイエンスに関連する学問です。コンピューターと人間の自然言語の間の相互作用を研究します。今日の情報技術の急速な発展を背景に、NLP はインテリジェントな顧客サービス、機械翻訳、テキストマイニングなどのさまざまな分野で広く使用されています。フロントエンド開発としての JavaScript
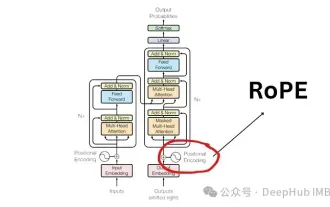 大規模な言語モデルで一般的に使用される回転位置エンコーディング RoPE の詳細な説明: なぜ絶対位置エンコーディングや相対位置エンコーディングよりも優れているのですか?
Apr 01, 2024 pm 08:19 PM
大規模な言語モデルで一般的に使用される回転位置エンコーディング RoPE の詳細な説明: なぜ絶対位置エンコーディングや相対位置エンコーディングよりも優れているのですか?
Apr 01, 2024 pm 08:19 PM
2017 年に発表された「tentionIsAllYouNeed」論文以来、Transformer アーキテクチャは自然言語処理 (NLP) 分野の基礎となってきました。その設計は長年にわたってほとんど変わっておらず、2022 年にはロータリー ポジション エンコーディング (RoPE) の導入によりこの分野で大きな発展が見られました。回転位置埋め込みは、最先端の NLP 位置埋め込み技術です。最も一般的な大規模言語モデル (Llama、Llama2、PaLM、CodeGen など) はすでにこれを使用しています。この記事では、回転位置エンコーディングとは何か、また、回転位置エンコーディングが絶対位置エンコーディングと相対位置エンコーディングの利点をどのようにうまく組み合わせているのかについて詳しく説明します。 Ro を理解するための位置エンコーディングの必要性
