

GET3D の生成モデルに関する 5 分間の詳細な技術トーク

Part 01●
まえがき
近年、MidjourneyやStable Diffusionに代表される人工知能画像生成ツールの台頭により、2D人工知能画像生成技術は欠かせないものとなっています。実際のプロジェクトでエンジニアが使用する補助ツールは、さまざまなビジネスシーンに適用され、ますます実用的な価値を生み出しています。同時に、メタバースの台頭により、多くの産業が大規模な 3D 仮想世界を構築する方向に向かっており、ゲーム、ロボット、建築、建築などの産業において、多様で高品質な 3D コンテンツの重要性がますます高まっています。そしてソーシャルプラットフォーム。ただし、3D アセットを手動で作成するには時間がかかり、特定の芸術的およびモデリングのスキルが必要です。主な課題の 1 つはスケールの問題です。3D マーケットプレイスには多数の 3D モデルが存在しますが、ゲームや映画ですべて異なって見えるキャラクターや建物のグループを作成するには、依然としてアーティストの多大な投資が必要です。時間。その結果、3D コンテンツの量、質、多様性を拡張できるコンテンツ作成ツールの必要性がますます明らかになってきています。
 #写真
#写真
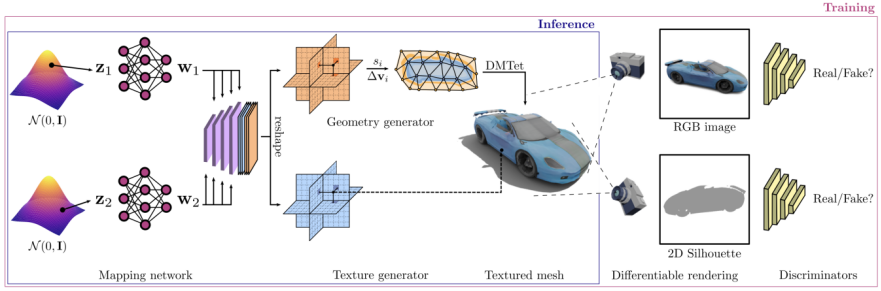
2D 画像は明示的な 3D 形状よりも一般的であるため、監視に 2D 画像を使用することが可能です。パート 023D 生成モデルの概要コンテンツをわかりやすくするため作成プロセスを改善し、実用的なアプリケーションを可能にするジェネレーティブ 3D ネットワークは、高品質で多様な 3D アセットを作成できる活発な研究分野となっています。毎年、ICCV、NeurlPS、ICML およびその他のカンファレンスで、次のような最先端のモデルを含む多くの 3D 生成モデルが公開されています。Textured3DGAN は、テクスチャ付き 3D メッシュを生成する畳み込み手法を拡張した生成モデルです。 。 2D の監視下で GAN を使用して、物理画像からテクスチャ メッシュを生成する方法を学習できます。以前の方法と比較して、Textured3DGAN は姿勢推定ステップのキーポイントの要件を緩和し、ラベルのない画像コレクションや ImageNetDIB-R などの新しいカテゴリ/データセットに方法を一般化します。これは微分可能なレンダラー ベースです。補間には、下部にある PyTorch 機械学習フレームワークを使用します。このレンダラーは、3D Deep Learning PyTorch GitHub リポジトリ (Kaolin) に追加されました。この方法では、画像内のすべてのピクセルの勾配を分析的に計算できます。中心となるアイデアは、前景のラスタライゼーションをローカル属性の加重補間として扱い、背景のラスタライゼーションをグローバル ジオメトリの距離ベースの集約として扱うことです。このようにして、単一の画像から形状、テクスチャ、光などの情報を予測できます。PolyGen: PolyGen は、メッシュを直接モデリングするための Transformer アーキテクチャに基づく自己回帰生成モデルです。モデルはメッシュの頂点と面を順番に予測します。 ShapeNet Core V2 データセットを使用してモデルをトレーニングし、得られた結果は人間が構築したメッシュ モデル SurfGen: 明示的な表面識別器を使用した敵対的 3D 形状合成に非常に近いものでした。エンドツーエンドでトレーニングされたモデルは、さまざまなトポロジーで忠実度の高い 3D 形状を生成できます。 GET3D は、画像を学習することで高品質な 3D テクスチャ形状を生成できる生成モデルです。その核となるのは、微分可能サーフェス モデリング、微分可能レンダリング、および 2D 生成敵対的ネットワークです。 GET3D は、2D 画像のコレクションをトレーニングすることにより、複雑なトポロジー、豊富な幾何学的詳細、および忠実度の高いテクスチャを備えた、明示的にテクスチャー処理された 3D メッシュを直接生成できます。 ##書き換えが必要な内容は以下のとおりです: 図2 GET3D生成モデル (出典: GET3D論文公式Webサイト https://nv-tlabs.github.io/GET3D/) GET3Dは最近提案された3Dです生成モデル。椅子、オートバイ、車、人物、建物などの複雑なジオメトリを持つ複数のカテゴリに対して、ShapeNet、Turbosquid、Renderpeople を使用して 3D 形状を無制限に生成する最先端のパフォーマンスを実証します。
パート 03
GET3D のアーキテクチャと特性
 写真
写真
GET3D アーキテクチャは GET3D Paper 公式 Web サイトから引用しています。図 3 は、このアーキテクチャを示しています。
は 2 つの潜在エンコーディングを通じて 3D SDF (Directed Distance Field) とテクスチャ フィールドを生成し、DMTet (Deep Marching Tetrahedra) を使用して SDF から 3D サーフェス メッシュを抽出して追加します。クラウドはテクスチャ フィールドをクエリして色を取得します。プロセス全体は、2D 画像で定義された敵対的損失を使用してトレーニングされます。特に、RGB イメージと輪郭は、ラスタライズベースの微分可能レンダラーを使用して取得されます。最後に、入力が本物か偽物かを区別するために、それぞれ RGB 画像と輪郭に対して 2 つの 2D 識別器が使用されます。モデル全体をエンドツーエンドでトレーニングできます。
GET3D は他の面でも非常に柔軟で、出力式としての明示的なメッシュに加えて、次のような他のタスクにも簡単に適応できます。ジオメトリとテクスチャの分離の実装: モデルのジオメトリとテクスチャの間で適切な分離が実現され、ジオメトリ 潜在コードとテクスチャ 潜在コードの有意義な補間が可能になります。
異なるカテゴリの形状の生成間のスムーズな移行が可能になります。潜在空間内でランダム ウォークを実行し、対応する 3D 形状を生成することで実現します。
新しい形状の生成: 小さなノイズを追加することで、ローカルの潜在コードを混乱させて、類似しているが局所的にわずかに異なる形状を生成できます。
教師なしマテリアル生成: DIBR と組み合わせることで、マテリアルは完全に教師なしで生成され、意味のあるビュー依存の照明効果を生成します。
テキストガイドによる形状生成へ: StyleGAN NADA を組み合わせることにより、 - 計算上レンダリングされた 2D 画像とユーザーが指定したテキストの指向性クリップ損失を使用して 3D ジェネレーターを調整します。ユーザーはテキスト プロンプトを使用して多数の意味のある形状を生成できます
画像 図 4 を参照してください。テキストに基づいて図形を生成するプロセスが示されています。この図のソースは GET3D 論文の公式 Web サイトで、URL は https://nv-tlabs.github.io/GET3D/
図 4 を参照してください。テキストに基づいて図形を生成するプロセスが示されています。この図のソースは GET3D 論文の公式 Web サイトで、URL は https://nv-tlabs.github.io/GET3D/
Part 04
summary
## です。 #GET3D は実用的な 3D テクスチャ形状の生成モデルとして重要な一歩を踏み出しましたが、まだいくつかの制限があります。特に、トレーニング プロセスは依然として 2D シルエットとカメラ分布の知識に依存しています。したがって、現在 GET3D は合成データに基づいてのみ評価できます。有望な拡張機能は、インスタンス セグメンテーションとカメラ ポーズ推定の進歩を活用して、この問題を軽減し、GET3D を現実世界のデータに拡張することです。 GET3D は現在、カテゴリごとにのみトレーニングされていますが、カテゴリ間の多様性をより適切に表現するために、将来的には複数のカテゴリに拡張される予定です。この研究により、人々が人工知能を使用して 3D コンテンツを自由に作成できるようになることが期待されています。以上がGET3D の生成モデルに関する 5 分間の詳細な技術トークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 Microsoft Teams の 3D Fluent 絵文字について学ぶ
Apr 24, 2023 pm 10:28 PM
Microsoft Teams の 3D Fluent 絵文字について学ぶ
Apr 24, 2023 pm 10:28 PM
特に Teams ユーザーの場合は、Microsoft が仕事中心のビデオ会議アプリに 3DFluent 絵文字の新しいバッチを追加したことを覚えておく必要があります。 Microsoft が昨年 Teams と Windows 向けの 3D 絵文字を発表した後、その過程で実際に 1,800 を超える既存の絵文字がプラットフォーム用に更新されました。この大きなアイデアと Teams 用の 3DFluent 絵文字アップデートの開始は、公式ブログ投稿を通じて最初に宣伝されました。 Teams の最新アップデートでアプリに FluentEmojis が追加 Microsoft は、更新された 1,800 個の絵文字を毎日利用できるようになると発表
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 Windows 11 のペイント 3D: ダウンロード、インストール、および使用ガイド
Apr 26, 2023 am 11:28 AM
Windows 11 のペイント 3D: ダウンロード、インストール、および使用ガイド
Apr 26, 2023 am 11:28 AM
新しい Windows 11 が開発中であるというゴシップが広まり始めたとき、すべての Microsoft ユーザーは、新しいオペレーティング システムがどのようなもので、何をもたらすのかに興味を持ちました。憶測を経て、Windows 11が登場しました。オペレーティング システムには新しい設計と機能の変更が加えられています。いくつかの追加に加えて、機能の非推奨と削除が行われます。 Windows 11 に存在しない機能の 1 つは Paint3D です。描画、落書き、落書きに適したクラシックなペイントは引き続き提供していますが、3D クリエイターに最適な追加機能を提供する Paint3D は廃止されています。追加機能をお探しの場合は、最高の 3D デザイン ソフトウェアとして Autodesk Maya をお勧めします。のように
 カード1枚で30秒でバーチャル3D嫁をゲット! Text to 3D は、毛穴の詳細が明確な高精度のデジタル ヒューマンを生成し、Maya、Unity、その他の制作ツールとシームレスに接続します
May 23, 2023 pm 02:34 PM
カード1枚で30秒でバーチャル3D嫁をゲット! Text to 3D は、毛穴の詳細が明確な高精度のデジタル ヒューマンを生成し、Maya、Unity、その他の制作ツールとシームレスに接続します
May 23, 2023 pm 02:34 PM
ChatGPT は AI 業界に鶏の血を注入し、かつては考えられなかったすべてのことが今日では基本的な慣行になりました。進化を続ける Text-to-3D は、AIGC 分野において Diffusion(画像)、GPT(テキスト)に次ぐホットスポットとされ、前例のない注目を集めています。いいえ、ChatAvatar と呼ばれる製品が控えめなパブリック ベータ版として公開され、すぐに 700,000 回を超えるビューと注目を集め、Spacesoftheweek で特集されました。 △ChatAvatarは、AIが生成した単一視点/多視点の原画から3Dの様式化されたキャラクターを生成するImageto3D技術にも対応しており、現在のベータ版で生成された3Dモデルは広く注目を集めています。
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
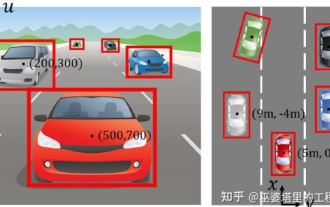 自動運転のための 3D 視覚認識アルゴリズムの詳細な解釈
Jun 02, 2023 pm 03:42 PM
自動運転のための 3D 視覚認識アルゴリズムの詳細な解釈
Jun 02, 2023 pm 03:42 PM
自動運転アプリケーションの場合、最終的には 3D シーンを認識することが必要になります。理由は簡単で、車両は画像から得られる知覚結果に基づいて運転することはできませんし、人間のドライバーであっても画像に基づいて運転することはできません。物体までの距離やシーンの奥行き情報は2D認識結果に反映できないため、自動運転システムが周囲の環境を正しく判断するための鍵となります。一般に、自動運転車の視覚センサー(カメラなど)は、車体上部または車内のバックミラーに設置されます。どこにいても、カメラが取得するのは、現実世界を透視図 (PerspectiveView) (世界座標系から画像座標系) に投影したものです。この視点は人間の視覚システムに非常に似ており、
