

Python での Requests モジュールの使用

Requests は、さまざまな HTTP リクエストの送信に使用できる Python モジュールです。これは、URL でのパラメーターの受け渡しからカスタム ヘッダーの送信や SSL 検証まで、多くの機能を備えた使いやすいライブラリです。このチュートリアルでは、このライブラリを使用して Python で単純な HTTP リクエストを送信する方法を学習します。
リクエストは、Python バージョン 2.6 ~ 2.7 および 3.3 ~ 3.6 で使用できます。続行する前に、Requests は外部モジュールであるため、このチュートリアルの例を試す前にそれをインストールする必要があることを知っておく必要があります。ターミナルで次のコマンドを実行してインストールできます:
リーリーモジュールをインストールした後、次のコマンドを使用してモジュールをインポートし、モジュールが正常にインストールされたかどうかを確認できます。 リーリー
インストールが成功すると、エラー メッセージは表示されません。GETリクエストの発行
リクエストを使用すると、HTTP リクエストの送信が非常に簡単になります。まずモジュールをインポートしてからリクエストを行います。以下に例を示します:
リーリー
リクエストに関するすべての情報は、req という名前の応答オブジェクトに保存されます。たとえば、req.encoding プロパティを使用して、Web ページのエンコーディングを取得できます。 req.status_code プロパティを使用してリクエストのステータス コードを取得することもできます。
リーリー
req.cookies を使用して、サーバーから返送された Cookie にアクセスできます。同様に、req.headers を使用して応答ヘッダーを取得できます。 req.headers プロパティは、大文字と小文字を区別しない応答ヘッダーの辞書を返します。これは、req.headers['Content-Length']、req.headers['content-length']、および req を意味します。 headers['CONTENT-LENGTH'] は、'Content-Length' 応答ヘッダーの値を返します。
req.is_redirect プロパティを使用して自動的に処理できます。応答に応じて True または False を返します。 req.elapsed プロパティを使用して、リクエストの送信から応答の取得までの経過時間を取得することもできます。
get() 関数に渡す URL は、リダイレクトなどのさまざまな理由により、応答の最終 URL と異なる場合があります。最終応答 URL を表示するには、req.url プロパティを使用できます。
リーリー
req.text プロパティを使用してアクセスできます。次に、コンテンツは Unicode に解析されます。 req.encoding プロパティを使用して、テキストのデコードに使用されるエンコードを渡すことができます。
req.content を使用してバイナリ形式でアクセスできます。このモジュールは、gzip および deflate 転送エンコーディングを自動的にデコードします。これは、メディア ファイルを操作するときに役立ちます。同様に、req.json() を使用して、応答の json エンコードされたコンテンツ (存在する場合) にアクセスできます。
req.raw を使用して、サーバーから生の応答を取得することもできます。生の応答を取得するには、リクエストで stream=True を渡す必要があることに注意してください。
iter_content(chunk_size = 1,decode_unicode=False) メソッドを使用して、ファイルを複数のチャンクに分けてダウンロードできます。
chunk_size バイト単位で繰り返します。このメソッドは、リクエストに stream=True が設定されている場合に、大規模なレスポンスのためにファイル全体を一度にメモリに読み込むことを回避します。 chunk_size パラメータには整数または None を指定できます。整数値に設定すると、chunk_size によってメモリに読み取られるバイト数が決まります。
が None に設定され、stream が True に設定されている場合、データは受信したどのチャンクでも読み取られます。サイズに関係なく、届きます。 chunk_size が None に設定され、stream が False に設定されている場合、すべてのデータが単一のチャンクとして返されます。
リクエストモジュールを使用してキノコの画像をダウンロードしましょう。これは実際の画像です:
 これは必要なコードです:
これは必要なコードです:
import requests
req = requests.get('path/to/mushrooms.jpg', stream=True)
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
for chunk in req.iter_content(chunk_size=50000):
print('Received a Chunk')
fd.write(chunk)
'path/to/mushrooms.jpg' 是实际的图像 URL。您可以将任何其他图像的 URL 放在这里来下载其他内容。给定的图像文件大小为 162kb,并且您已将 chunk_size 设置为 50,000 字节。这意味着“Received a Chunk”消息应在终端中打印四次。最后一个块的大小将仅为 32350 字节,因为前三次迭代后仍待接收的文件部分为 32350 字节。
您还可以用类似的方式下载视频。我们可以简单地将其值设置为 None,而不是指定固定的 chunk_size,然后视频将以提供的任何块大小下载。以下代码片段将从 Mixkit 下载高速公路的视频:
import requests
req = requests.get('path/to/highway/video.mp4', stream=True)
req.raise_for_status()
with open('highway.mp4', 'wb') as fd:
for chunk in req.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
尝试运行代码,您将看到视频作为单个块下载。
如果您决定使用 stream 参数,则应记住以下几点。响应正文的下载会被推迟,直到您使用 content 属性实际访问其值。这样,如果某些标头值之一看起来不正确,您就可以避免下载文件。
另请记住,在将流的值设置为 True 时启动的任何连接都不会关闭,除非您消耗所有数据或使用 close() 方法。确保连接始终关闭的更好方法是在 with 语句中发出请求,即使您部分读取了响应,如下所示:
import requests
with requests.get('path/to/highway/video.mp4', stream=True) as rq:
with open('highway.mp4', 'wb') as fd:
for chunk in rq.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
由于我们之前下载的图片文件比较小,您也可以使用以下代码一次性下载:
import requests
req = requests.get('path/to/mushrooms.jpg')
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
fd.write(req.content)
我们跳过了设置 stream 参数的值,因此默认设置为 False。这意味着所有响应内容将立即下载。借助 content 属性,将响应内容捕获为二进制数据。
请求还允许您在 URL 中传递参数。当您在网页上搜索某些结果(例如特定图像或教程)时,这会很有帮助。您可以使用 GET 请求中的 params 关键字将这些查询字符串作为字符串字典提供。这是一个例子:
import requests
query = {'q': 'Forest', 'order': 'popular', 'min_width': '800', 'min_height': '600'}
req = requests.get('https://pixabay.com/en/photos/', params=query)
req.url
# returns 'https://pixabay.com/en/photos/?order=popular&min_height=600&q=Forest&min_width=800'
发出 POST 请求
发出 POST 请求与发出 GET 请求一样简单。您只需使用 post() 方法而不是 get() 即可。当您自动提交表单时,这会很有用。例如,以下代码将向 httpbin.org 域发送 post 请求,并将响应 JSON 作为文本输出。
import requests
req = requests.post('https://httpbin.org/post', data = {'username': 'monty', 'password': 'something_complicated'})
req.raise_for_status()
print(req.text)
'''
{
"args": {},
"data": "",
"files": {},
"form": {
"password": "something_complicated",
"username": "monty"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "45",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-63ad437e-67f5db6a161314861484f2eb"
},
"json": null,
"origin": "YOUR.IP.ADDRESS",
"url": "https://httpbin.org/post"
}
'''
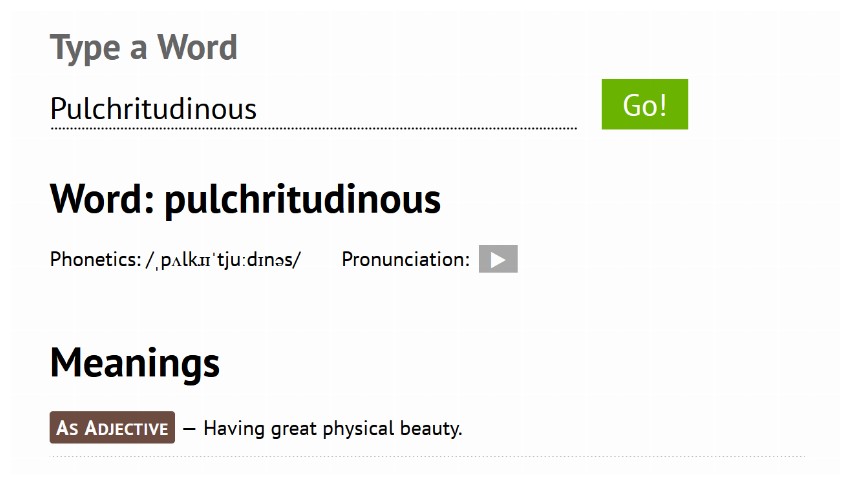
您可以将这些 POST 请求发送到任何可以处理它们的 URL。举个例子,我的一位朋友创建了一个网页,用户可以在其中输入单词并使用 API 获取其含义以及发音和其他信息。我们可以用我们查询的单词向URL发出POST请求,然后将结果保存为HTML页面,如下所示:
import requests
word = 'Pulchritudinous'
filename = word.lower() + '.html'
req = requests.post('https://tutorialio.com/tools/dictionary.php', data = {'query': word})
req.raise_for_status()
with open(filename, 'wb') as fd:
fd.write(req.content)
执行上面的代码,它会返回一个包含该单词信息的页面,如下图所示。
发送 Cookie 和标头
如前所述,您可以使用 req.cookies 和 req.headers 访问服务器发回给您的 cookie 和标头。请求还允许您通过请求发送您自己的自定义 cookie 和标头。当您想要为您的请求设置自定义用户代理时,这会很有帮助。
要将 HTTP 标头添加到请求中,您只需将它们通过 dict 传递到 headers 参数即可。同样,您还可以使用传递给 cookies 参数的 dict 将自己的 cookie 发送到服务器。
import requests
url = 'http://some-domain.com/set/cookies/headers'
headers = {'user-agent': 'your-own-user-agent/0.0.1'}
cookies = {'visit-month': 'February'}
req = requests.get(url, headers=headers, cookies=cookies)
Cookie 也可以在 Cookie Jar 中传递。它们提供了更完整的界面,允许您通过多个路径使用这些 cookie。这是一个例子:
import requests
jar = requests.cookies.RequestsCookieJar()
jar.set('first_cookie', 'first', domain='httpbin.org', path='/cookies')
jar.set('second_cookie', 'second', domain='httpbin.org', path='/extra')
jar.set('third_cookie', 'third', domain='httpbin.org', path='/cookies')
url = 'http://httpbin.org/cookies'
req = requests.get(url, cookies=jar)
req.text
# returns '{ "cookies": { "first_cookie": "first", "third_cookie": "third" }}'
会话对象
有时,在多个请求中保留某些参数很有用。 Session 对象正是这样做的。例如,它将在使用同一会话发出的所有请求中保留 cookie 数据。 Session 对象使用 urllib3 的连接池。这意味着底层 TCP 连接将被重复用于向同一主机发出的所有请求。这可以显着提高性能。您还可以将 Requests 对象的方法与 Session 对象一起使用。
以下是使用和不使用会话发送的多个请求的示例:
import requests
reqOne = requests.get('https://tutsplus.com/')
reqOne.cookies['_tuts_session']
#returns 'cc118d94a84f0ea37c64f14dd868a175'
reqTwo = requests.get('https://code.tutsplus.com/tutorials')
reqTwo.cookies['_tuts_session']
#returns '3775e1f1d7f3448e25881dfc35b8a69a'
ssnOne = requests.Session()
ssnOne.get('https://tutsplus.com/')
ssnOne.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
reqThree = ssnOne.get('https://code.tutsplus.com/tutorials')
reqThree.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
正如您所看到的,会话cookie在第一个和第二个请求中具有不同的值,但当我们使用Session对象时它具有相同的值。当您尝试此代码时,您将获得不同的值,但在您的情况下,使用会话对象发出的请求的 cookie 将具有相同的值。
当您想要在所有请求中发送相同的数据时,会话也很有用。例如,如果您决定将 cookie 或用户代理标头与所有请求一起发送到给定域,则可以使用 Session 对象。这是一个例子:
import requests
ssn = requests.Session()
ssn.cookies.update({'visit-month': 'February'})
reqOne = ssn.get('http://httpbin.org/cookies')
print(reqOne.text)
# prints information about "visit-month" cookie
reqTwo = ssn.get('http://httpbin.org/cookies', cookies={'visit-year': '2017'})
print(reqTwo.text)
# prints information about "visit-month" and "visit-year" cookie
reqThree = ssn.get('http://httpbin.org/cookies')
print(reqThree.text)
# prints information about "visit-month" cookie
如您所见,"visit-month" 会话 cookie 随所有三个请求一起发送。但是, "visit-year" cookie 仅在第二次请求期间发送。第三个请求中也没有提及 "vist-year" cookie。这证实了单个请求上设置的 cookie 或其他数据不会与其他会话请求一起发送。
结论
本教程中讨论的概念应该可以帮助您通过传递特定标头、cookie 或查询字符串来向服务器发出基本请求。当您尝试抓取网页以获取信息时,这将非常方便。现在,一旦您找出 URL 中的模式,您还应该能够自动从不同的网站下载音乐文件和壁纸。
学习 Python
无论您是刚刚入门还是希望学习新技能的经验丰富的程序员,都可以通过我们完整的 Python 教程指南学习 Python。
以上がPython での Requests モジュールの使用の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7546
7546
 15
1381
52
83
11
21
89
15
1381
52
83
11
21
89

 PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPとPythonには独自の利点と短所があり、選択はプロジェクトのニーズと個人的な好みに依存します。 1.PHPは、大規模なWebアプリケーションの迅速な開発とメンテナンスに適しています。 2。Pythonは、データサイエンスと機械学習の分野を支配しています。
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
PythonとJavaScriptには、コミュニティ、ライブラリ、リソースの観点から、独自の利点と短所があります。 1)Pythonコミュニティはフレンドリーで初心者に適していますが、フロントエンドの開発リソースはJavaScriptほど豊富ではありません。 2)Pythonはデータサイエンスおよび機械学習ライブラリで強力ですが、JavaScriptはフロントエンド開発ライブラリとフレームワークで優れています。 3)どちらも豊富な学習リソースを持っていますが、Pythonは公式文書から始めるのに適していますが、JavaScriptはMDNWebDocsにより優れています。選択は、プロジェクトのニーズと個人的な関心に基づいている必要があります。
 ミニオペンCentosの互換性
Apr 14, 2025 pm 05:45 PM
ミニオペンCentosの互換性
Apr 14, 2025 pm 05:45 PM
MINIOオブジェクトストレージ:CENTOSシステムの下での高性能展開Minioは、Amazons3と互換性のあるGO言語に基づいて開発された高性能の分散オブジェクトストレージシステムです。 Java、Python、JavaScript、Goなど、さまざまなクライアント言語をサポートしています。この記事では、CentosシステムへのMinioのインストールと互換性を簡単に紹介します。 Centosバージョンの互換性Minioは、Centos7.9を含むがこれらに限定されない複数のCentosバージョンで検証されています。
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
 NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NGINXのインストールをインストールするには、次の手順に従う必要があります。開発ツール、PCRE-Devel、OpenSSL-Develなどの依存関係のインストール。 nginxソースコードパッケージをダウンロードし、それを解凍してコンパイルしてインストールし、/usr/local/nginxとしてインストールパスを指定します。 nginxユーザーとユーザーグループを作成し、アクセス許可を設定します。構成ファイルnginx.confを変更し、リスニングポートとドメイン名/IPアドレスを構成します。 nginxサービスを開始します。依存関係の問題、ポート競合、構成ファイルエラーなど、一般的なエラーに注意する必要があります。パフォーマンスの最適化は、キャッシュをオンにしたり、ワーカープロセスの数を調整するなど、特定の状況に応じて調整する必要があります。
 CentosでPytorchバージョンを選択する方法
Apr 14, 2025 pm 06:51 PM
CentosでPytorchバージョンを選択する方法
Apr 14, 2025 pm 06:51 PM
PytorchをCentosシステムにインストールする場合、適切なバージョンを慎重に選択し、次の重要な要因を検討する必要があります。1。システム環境互換性:オペレーティングシステム:Centos7以上を使用することをお勧めします。 Cuda and Cudnn:PytorchバージョンとCudaバージョンは密接に関連しています。たとえば、pytorch1.9.0にはcuda11.1が必要ですが、pytorch2.0.1にはcuda11.3が必要です。 CUDNNバージョンは、CUDAバージョンとも一致する必要があります。 Pytorchバージョンを選択する前に、互換性のあるCUDAおよびCUDNNバージョンがインストールされていることを確認してください。 Pythonバージョン:Pytorch公式支店
