

3D モデルのテクスチャ マッピングは 30 秒で簡単に完了でき、シンプルかつ効率的です。

拡散モデルを使用して 3D オブジェクトのテクスチャを生成するこれは 1 つの文で実行できます!
「茶色と黒の幾何学模様の椅子」と入力すると、拡散モデルによってすぐに古代のテクスチャが追加され、時代の雰囲気が与えられます
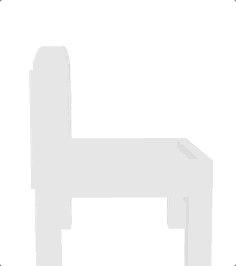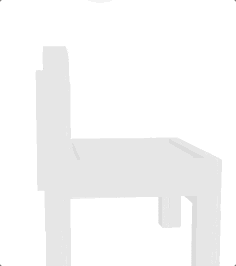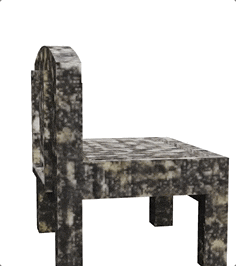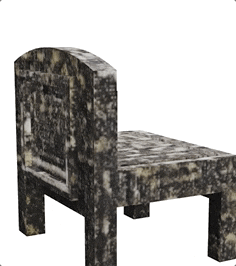
AI は、デスクトップがどのようなものであるかを判断できないスクリーンショットだけでも、想像力によってすぐに詳細な木のテクスチャをデスクトップに追加できます

ご存知のとおり、追加テクスチャを 3D オブジェクトに追加することは、単に「色を変更する」というだけではありません。
マテリアルを設計するときは、粗さ、反射、透明度、渦、ブルームなどの複数のパラメータを考慮する必要があります。良いエフェクトをデザインするには、マテリアル、ライティング、レンダリングなどの知識を理解するだけでなく、レンダリングのテストと修正を繰り返す必要があります。マテリアルが変更された場合は、デザインをやり直す必要がある場合があります
 #書き直す必要がある内容は次のとおりです: ゲーム シーンでのテクスチャ損失の影響
#書き直す必要がある内容は次のとおりです: ゲーム シーンでのテクスチャ損失の影響
 #書き直す必要がある内容は次のとおりです: ゲーム シーンでのテクスチャ損失の影響
#書き直す必要がある内容は次のとおりです: ゲーム シーンでのテクスチャ損失の影響しかし、以前は人工知能によって設計されたテクスチャは見た目が理想的ではないため、テクスチャの設計は常に時間と労力がかかる作業であり、そのためコストも高くなります。
HKU の研究者, 香港の中国人とTCLは最近、3Dオブジェクトのテクスチャを設計するための新しい人工知能手法を開発しました。この方法は、オブジェクトの元の形状を完全に保持するだけでなく、オブジェクトの表面に完全にフィットする、より現実的なテクスチャをデザインすることもできます。
この研究は、ICCV 2023 の口頭報告論文として収録されました
##書き直す必要があるのは、この問題の解決策は何でしょうか?見てみましょう
生成プロセス中に、3D オブジェクト自体のジオメトリが特別に処理されるため、生成されたテクスチャは、元のオブジェクトに完全にフィットすると、奇妙な形状が「飛び出し」ます 
したがって、詳細でリアルなテクスチャを生成しながら 3D オブジェクト構造の安定性を確保するために、これは研究では 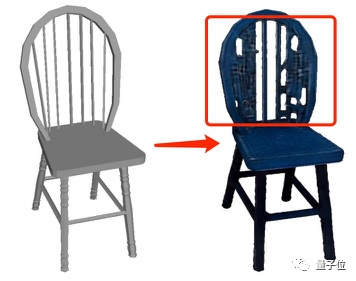 Point-UV diffusion
Point-UV diffusion
このフレームワークには「ラフデザイン」と「仕上げ」という2つのモジュールが含まれており、どちらも普及モデル
に基づいていますが、2つで使用される普及モデルは異なります。最初の「ラフデザイン」モジュールでは、オブジェクトの形状を予測するための入力条件として形状特徴 (表面法線、座標、マスクを含む)
を使用して 3D 拡散モデルをトレーニングします。
「仕上げ」モジュールでは、さらに活用できるように 2D 拡散モデルも設計されています。以前に生成されたラフテクスチャ画像とオブジェクトの形状を入力条件として使用し、より細かいテクスチャを生成します。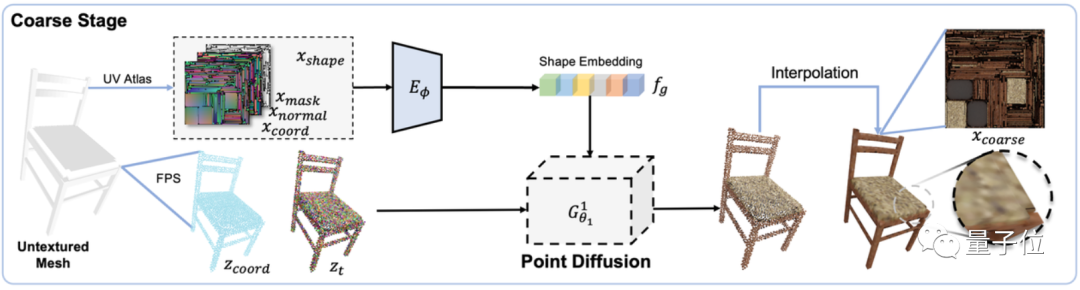
この設計構造を採用した理由は、以前の高解像度点群生成の計算コストにあります。この方法は通常高すぎます。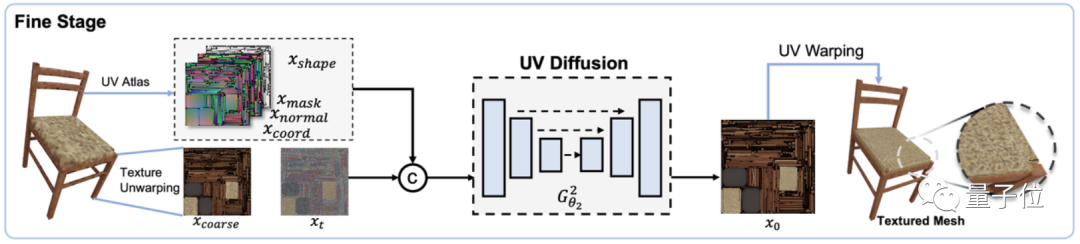
CLIP
の「貢献」です。元の意味を変えないように、内容を中国語に書き直す必要があります。書き直す必要があるのは、入力に関して、作成者はまず事前にトレーニングされた CLIP モデルを使用してテキストまたは画像の埋め込みベクトルを抽出し、次にそれを MLP モデルに入力し、最後に条件を「ラフな設計」に統合します。 「」と「仕上げ」の 2 段階のネットワーク
# では、テキストと画像を通じて生成されるテクスチャを制御することで、最終的な出力結果を実現できます。 それでは、このモデルの実装効果は何でしょうか。 ?生成速度が 10 分から 30 秒に短縮されました
まず点 UV 拡散の生成効果を見てみましょう
レンダリングからわかるように、テーブルや椅子に加えて、Point-UV 拡散は車などのオブジェクトのテクスチャをより豊富に生成することもできます。

テキストに基づいてテクスチャを生成するだけではありません:

対応するオブジェクトのテクスチャ効果は、画像に基づいて生成することもできます。

著者らはまた、前の方法で Point-UV 拡散によって生成されたテクスチャ効果
チャートを観察すると、Texture Fields、Texturify、PVD-Tex などの他のテクスチャ生成モデルと比較して、Point-UV が確認できることがわかります。拡散は、構造と細かさの点でより良い結果を示します

著者はまた、同じハードウェア構成の下では、計算に 10 分かかる Text2Mesh と比較して、Point-UV 拡散の方が優れているとも述べています。所要時間は 30 秒 だけです。

ただし、著者は点 UV 拡散の現在の制限もいくつか指摘しました。たとえば、UV マップ内に「断片化」された部分が多すぎる場合でも、シームレスなテクスチャ効果を実現することはできません。また、トレーニングを 3D データに依存しているため、現時点では 3D データの洗練された質と量が 2D データのレベルに達していないため、生成されるエフェクトはまだ 2D 画像生成の洗練されたエフェクトを実現できません。
 この研究に興味がある方は、以下のリンクをクリックして論文を読むことができます~
この研究に興味がある方は、以下のリンクをクリックして論文を読むことができます~
https: //cvmi-lab.github.io/Point-UV-Diffusion/paper/point_uv_diffusion.pdf
プロジェクト アドレス (まだ作成中):https:/ /github.com/CVMI-Lab/Point-UV-Diffusion
以上が3D モデルのテクスチャ マッピングは 30 秒で簡単に完了でき、シンプルかつ効率的です。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1657
1657
 14
1415
52
1309
25
1257
29
1230
24
14
1415
52
1309
25
1257
29
1230
24

 ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価格は20,000ドルから30,000ドルの範囲です。 1。ビットコインの価格は2009年以来劇的に変動し、2017年には20,000ドル近くに達し、2021年にはほぼ60,000ドルに達しました。2。価格は、市場需要、供給、マクロ経済環境などの要因の影響を受けます。 3.取引所、モバイルアプリ、ウェブサイトを通じてリアルタイム価格を取得します。 4。ビットコインの価格は非常に不安定であり、市場の感情と外部要因によって駆動されます。 5.従来の金融市場と特定の関係を持ち、世界の株式市場、米ドルの強さなどの影響を受けています。6。長期的な傾向は強気ですが、リスクを慎重に評価する必要があります。
 2025年のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの1つです
Apr 28, 2025 pm 08:12 PM
2025年のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの1つです
Apr 28, 2025 pm 08:12 PM
2025年の世界の上位10の暗号通貨取引所には、Binance、Okx、Gate.io、Coinbase、Kraken、Huobi、Bitfinex、Kucoin、Bittrex、Poloniexが含まれます。これらはすべて、高い取引量とセキュリティで知られています。
 世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界の上位10の暗号通貨取引プラットフォームには、Binance、Okx、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、Kucoin、Poloniexが含まれます。これらはすべて、さまざまな取引方法と強力なセキュリティ対策を提供します。
 トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
Binance、OKX、Gate.ioなどの上位10のデジタル通貨交換は、システムを改善し、効率的な多様化したトランザクション、厳格なセキュリティ対策を改善しました。
 復号化GATE.IO戦略のアップグレード:Memebox 2.0でCrypto Asset Managementを再定義する方法は?
Apr 28, 2025 pm 03:33 PM
復号化GATE.IO戦略のアップグレード:Memebox 2.0でCrypto Asset Managementを再定義する方法は?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0は、革新的なアーキテクチャとパフォーマンスのブレークスルーを通じて、暗号資産管理を再定義します。 1)3つの主要な問題点を解決します。資産サイロ、収入の減少、セキュリティと利便性のパラドックスです。 2)インテリジェントアセットハブ、動的リスク管理およびリターンエンハンスメントエンジン、クロスチェーン移動速度、平均降伏率、およびセキュリティインシデント応答速度が向上します。 3)ユーザーに、ユーザー価値の再構築を実現し、資産の視覚化、ポリシーの自動化、ガバナンス統合を提供します。 4)生態学的なコラボレーションとコンプライアンスの革新により、プラットフォームの全体的な有効性が向上しました。 5)将来的には、スマート契約保険プール、予測市場統合、AI主導の資産配分が開始され、引き続き業界の発展をリードします。
 トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
現在、上位10の仮想通貨交換にランクされています。1。Binance、2。Okx、3。Gate.io、4。CoinLibrary、5。Siren、6。HuobiGlobal Station、7。Bybit、8。Kucoin、9。Bitcoin、10。BitStamp。
 推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム:1。OKX、2。Binance、3。Coinbase、4。Kraken、5。Huobi、6。Kucoin、7。Bitfinex、8。Gemini、9。Bitstamp、10。Poloniex、これらのプラットフォームは、セキュリティ、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのために知られています。
 CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用すると、時間と時間の間隔をより正確に制御できます。このライブラリの魅力を探りましょう。 CのChronoライブラリは、時間と時間の間隔に対処するための最新の方法を提供する標準ライブラリの一部です。 Time.HとCtimeに苦しんでいるプログラマーにとって、Chronoは間違いなく恩恵です。コードの読みやすさと保守性を向上させるだけでなく、より高い精度と柔軟性も提供します。基本から始めましょう。 Chronoライブラリには、主に次の重要なコンポーネントが含まれています。STD:: Chrono :: System_Clock:現在の時間を取得するために使用されるシステムクロックを表します。 STD :: Chron
