

自己教師あり学習アルゴリズムは、自然言語処理やコンピューター ビジョンなどの分野で大きな進歩を遂げました。これらの自己教師あり学習アルゴリズムは概念的には一般的ですが、その特定の操作は特定のデータ モダリティに基づいています。これは、異なるデータ モダリティに対して異なる自己教師あり学習アルゴリズムを開発する必要があることを意味します。この目的を達成するために、この文書では、あらゆるデータ モダリティに適用できる一般的なデータ拡張手法を提案します。既存の汎用自己教師あり学習と比較して、この方法は大幅なパフォーマンスの向上を達成でき、特定のモダリティ向けに設計された一連の複雑なデータ拡張方法を置き換えて、同様のパフォーマンスを達成できます。

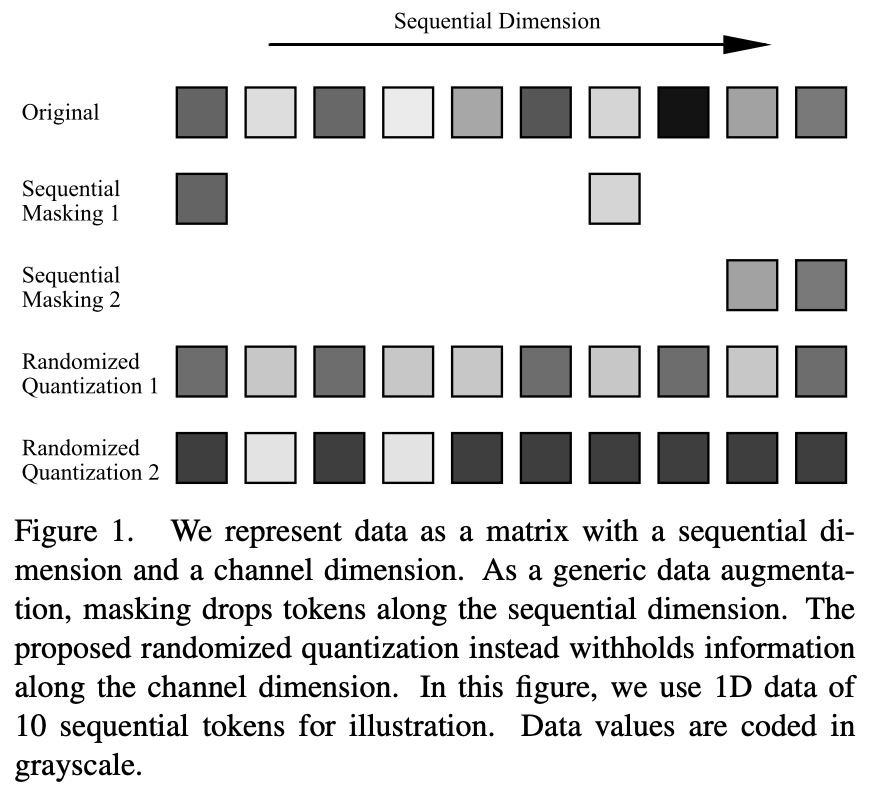
一般に、入力データは次のように表すことができます。シーケンスの次元とチャネルの次元。シーケンスの次元は、画像の空間次元、音声の時間次元、言語の構文次元など、データのモダリティに関連することがよくあります。チャネルの次元はモダリティには依存しません。自己教師あり学習では、オクルージョン モデリング、またはデータ拡張としてオクルージョンを使用することが効果的な学習方法となっています。ただし、これらの操作はシーケンス次元で実行されます。さまざまなデータ モダリティに広く適用できるように、この論文ではチャネル次元に作用するデータ拡張方法、つまりランダム量子化を提案します。不均一量子化器を使用して各チャネルのデータを動的に量子化することで、量子化された値がランダムに分割された間隔からランダムにサンプリングされます。このようにして、異なる間隔のデータの相対的なサイズを保持しながら、同じ間隔の元の入力の情報の差分が削除され、それによってマスキングの効果が得られます
 #この手法は、自然画像、3D 点群、音声、テキスト、センサー データ、医療画像などを含むさまざまなデータ モダリティにおいて、既存の自己教師あり学習手法を上回ります。対照学習 (MoCo-v3 など) や自己蒸留自己教師あり学習 (BYOL など) などのさまざまなトレーニング前の学習タスクで、既存の方法よりも優れた機能が学習されます。この方法は、CNN や Transformer などのさまざまなバックボーン ネットワーク構造でも検証されています。
#この手法は、自然画像、3D 点群、音声、テキスト、センサー データ、医療画像などを含むさまざまなデータ モダリティにおいて、既存の自己教師あり学習手法を上回ります。対照学習 (MoCo-v3 など) や自己蒸留自己教師あり学習 (BYOL など) などのさまざまなトレーニング前の学習タスクで、既存の方法よりも優れた機能が学習されます。この方法は、CNN や Transformer などのさまざまなバックボーン ネットワーク構造でも検証されています。
方法
#この記事では、各入力チャネル データを複数の重複しないランダムな間隔 (
) に独立して分割し、元のデータをマッピングするランダム化量子化操作を提案します。各間隔内にある入力を、その間隔からランダムにサンプリングされた定数 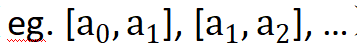 に変換します。
に変換します。 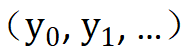

具体的には、ランダム プロセスによりサンプルが豊富になり、ランダム定量化操作が実行されるたびに同じデータから異なるデータ サンプルが生成される可能性があります。同時に、ランダム処理により、元のデータがさらに強化されます。たとえば、大きなデータ間隔がランダムに分割されたり、マッピング ポイントが間隔の中央点から逸脱したりすると、元の入出力が損なわれる可能性があります。間隔の間に落ち、差が大きくなります。
区間の分割数を適宜減らすことで、強調強度を容易に高めることができる。このようにして、シャム表現学習に適用すると、2 つのネットワーク ブランチは十分な情報差を持つ入力データを受信できるため、強力な学習信号が構築され、特徴学習に役立ちます
次の図は、このデータ拡張方法を使用した後のさまざまなデータ モダリティの効果を視覚化したものです:
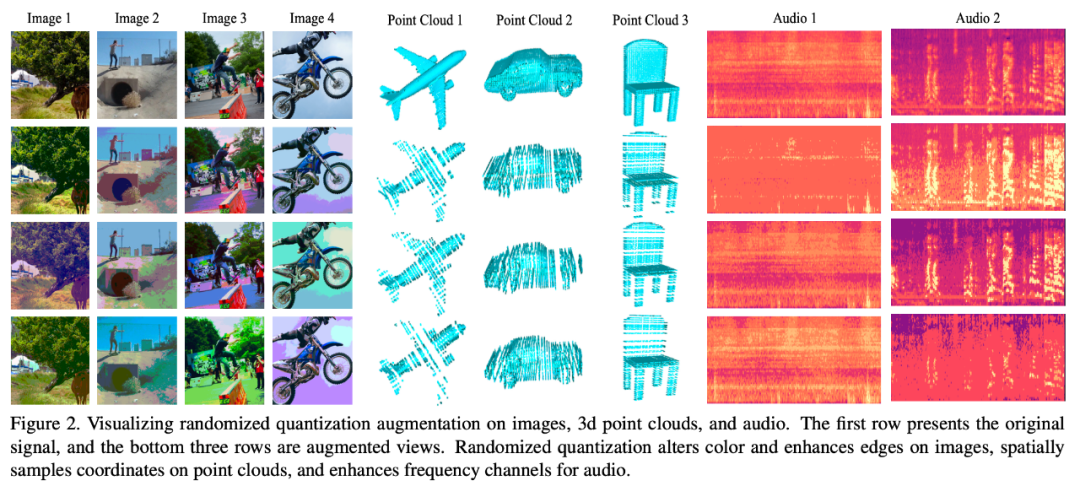
リライト内容は次のとおりです: モード 1: 画像
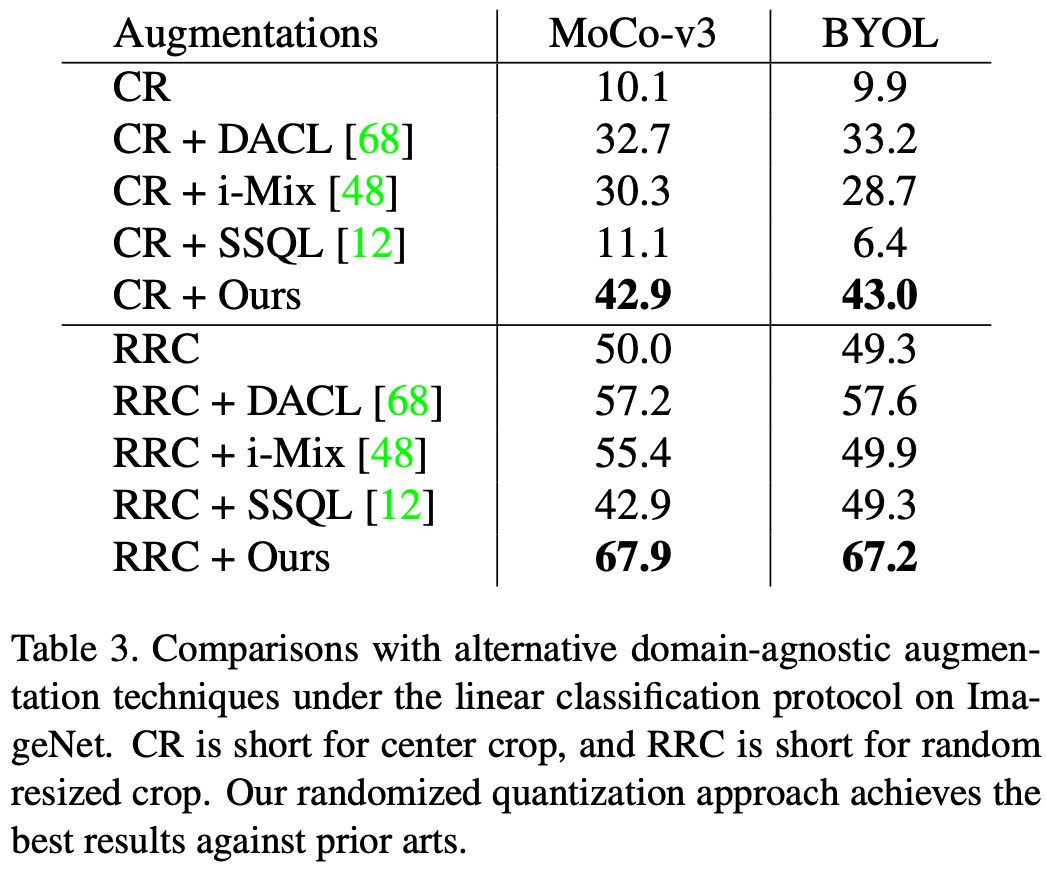
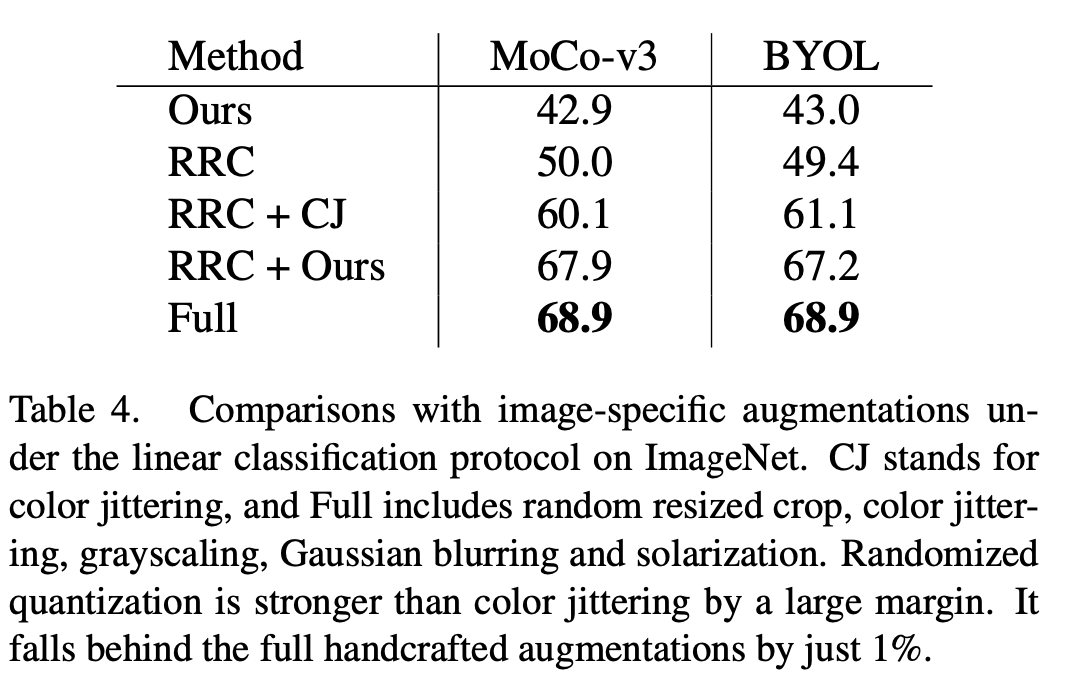
この記事では、MoCo-v3 に適用されるランダム化量子化を評価します。BYOL の効果の評価指標は線形評価です。唯一のデータ拡張方法として単独で使用した場合、つまり、この記事の拡張を元の画像の中央のトリミングに適用した場合、および一般的なランダム サイズ変更トリミング (RRC) と組み合わせて使用した場合、この方法はより良い結果を達成しました。既存の一般的な自己教師付き学習方法よりも優れた結果が得られます。
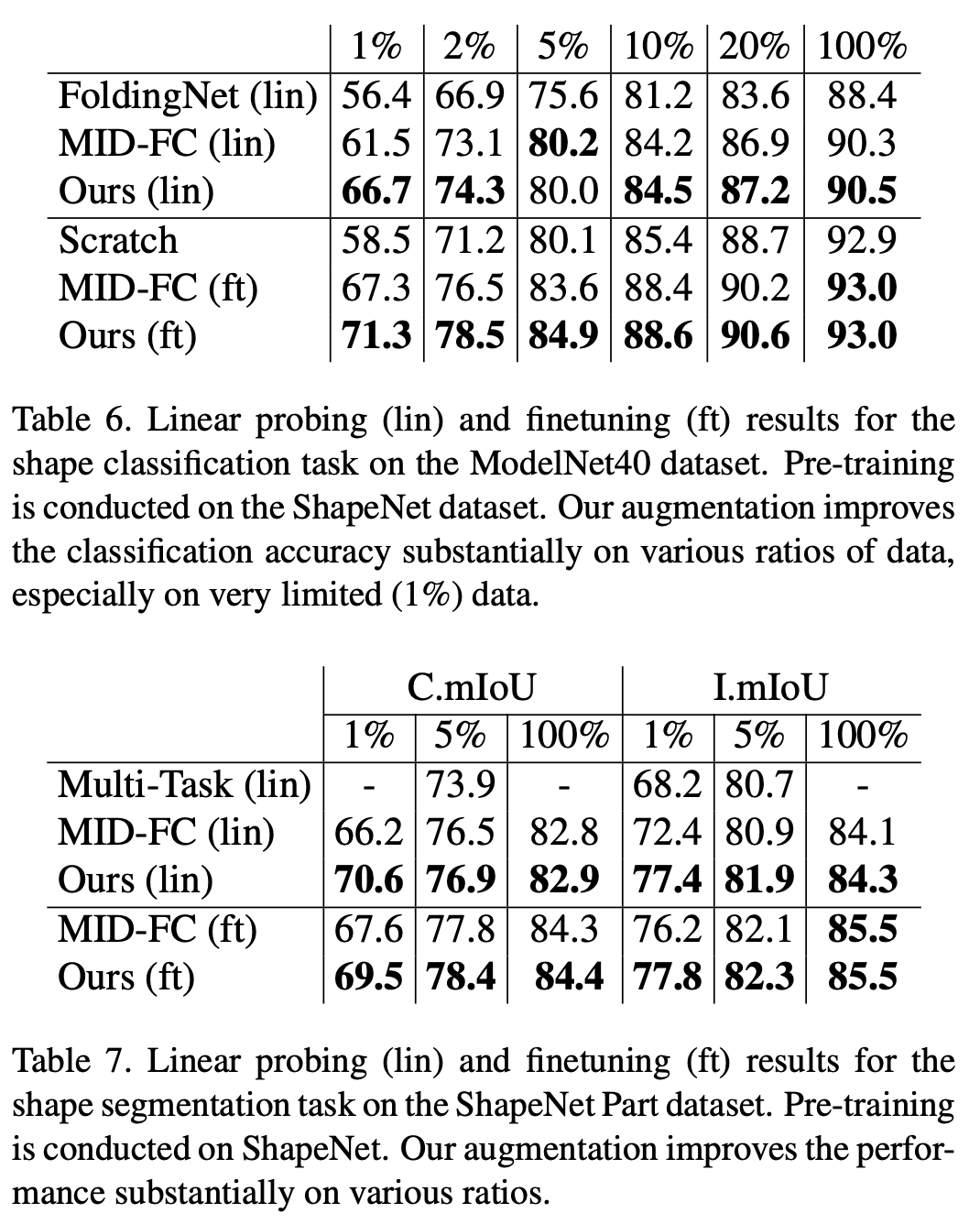
##ModelNet40 データセットの分類タスクと ShapeNet Part データセットのセグメンテーション タスクにおいて、この研究では、既存の自己教師あり手法に対するランダム量子化の優位性が検証されました。特に下流のトレーニング セットのデータ量が少ない場合、この研究の方法は既存の点群自己教師ありアルゴリズムを大幅に上回ります
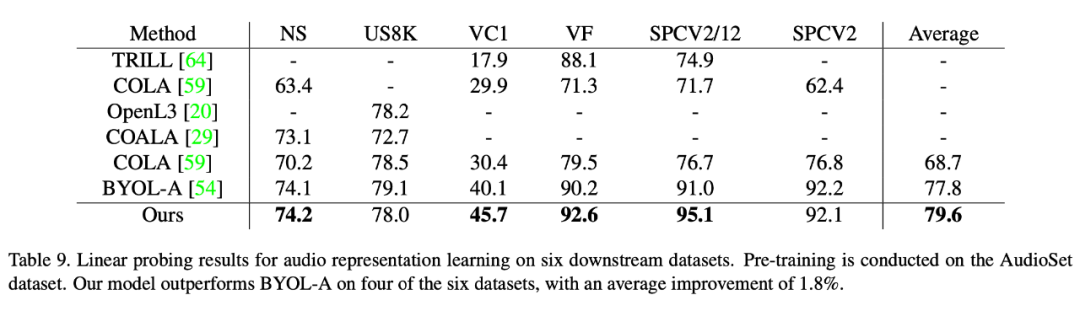
音声データセットに関しても、この記事の方法は既存の方法よりも優れた結果を達成しました。教師あり学習法のパフォーマンスが向上します。本稿では、6 つの下流データセットでこの手法の優位性を検証し、その中でも最も困難なデータセット VoxCeleb1 (カテゴリ数が最も多く、他のデータセット数をはるかに上回る) において、この手法は大幅な性能向上を達成しました。 (5.6点)。
 ##書き換えられた内容は次のとおりです: モード 4: DABS
##書き換えられた内容は次のとおりです: モード 4: DABS
DABS は、自然画像、テキスト、音声、センサー データ、医療画像、グラフィックスなどを含むさまざまなモーダル データをカバーする一般的な自己教師あり学習ベンチマークです。 DABS でカバーされるさまざまなモーダル データに関して、私たちの方法は既存のモーダル自己教師あり学習方法よりも優れています。
興味のある読者は元の論文を読むことができます。研究内容について詳しく知りたい場合は
以上がユニバーサルデータ強化テクノロジー、ランダム量子化はあらゆるデータモダリティに適していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



