
 テクノロジー周辺機器
AI
Baichuan Intelligent は Baichuan2 大型モデルをリリースしました。これは Llama2 よりも完全に先を行っており、トレーニング スライスもオープンソースです
テクノロジー周辺機器
AI
Baichuan Intelligent は Baichuan2 大型モデルをリリースしました。これは Llama2 よりも完全に先を行っており、トレーニング スライスもオープンソースです
Baichuan Intelligent は Baichuan2 大型モデルをリリースしました。これは Llama2 よりも完全に先を行っており、トレーニング スライスもオープンソースです

Baichuan Intelligent が大型モデルを平均 28 日でリリースしたことに業界が驚いても、同社は立ち止まりませんでした。
9 月 6 日午後の記者会見で、Baichuan Intelligent は、微調整された Baichuan-2 大型モデルの公式オープンソースを発表しました。
 中国科学院の学者で清華大学人工知能研究所の名誉院長である張波氏が記者会見に出席した。
中国科学院の学者で清華大学人工知能研究所の名誉院長である張波氏が記者会見に出席した。
これは、8 月の Baichuan-53B 大型モデルのリリース以来、Baichuan によるもう 1 つの新しいリリースです。オープンソース モデルには、Baichuan2-7B、Baichuan2-13B、Baichuan2-13B-Chat およびそれらの 4 ビット量子化バージョンが含まれており、すべて無料で商用利用可能です。
モデルの完全な公開に加えて、Baichuan Intelligence はモデル トレーニング用の Check Point をオープンソース化し、新しいモデルのトレーニングの詳細を詳述する Baichuan 2 技術レポートを公開しました。 Baichuan Intelligence の創設者兼 CEO の Wang Xiaochuan 氏は、この動きにより、大規模モデルの学術機関、開発者、企業ユーザーが大規模モデルのトレーニング プロセスを深く理解し、大規模モデルの技術開発をより促進できるようになることへの期待を表明しました。学術研究とコミュニティ。
Baichuan 2 大型モデルのオリジナルリンク: https://github.com/baichuan-inc/Baichuan2
技術レポート: https://cdn.baichuan-ai.com/paper/ Baichuan2 -technical-report.pdf
今日のオープン ソース モデルは、大規模なモデルに比べてサイズが「小さい」です。その中でも、Baichuan2-7B-Base と Baichuan2-13B-Base は両方とも 2.6 兆の高品質のデータに基づいています。多次元言語データはトレーニングに使用され、前世代のオープンソース モデルの良好な生成および作成機能、スムーズなマルチラウンド対話機能、および低い導入しきい値を維持することに基づいて、2 つのモデルは数学において優れたパフォーマンスを備えています。コード、セキュリティ、論理的推論、意味理解などの能力が大幅に向上しました。
「簡単に言えば、Baichuan7B の 70 億パラメータ モデルは、英語のベンチマークですでに LLaMA2 の 130 億パラメータ モデルと同等です。したがって、小さなモデルで大きな違いを生み出すことができ、小さなモデルは大型モデルの性能と同等であり、同じサイズのモデルでも総合的に LLaMA2 の性能を上回る、より高い性能を達成できます」と王暁川氏は述べています。
前世代の 13B モデルと比較して、Baichuan2-13B-Base は数学的機能が 49%、コーディング機能が 46%、セキュリティ機能が 37%、論理機能が 25% 向上しています。推論能力が向上し、意味理解能力が 15% 向上しました。
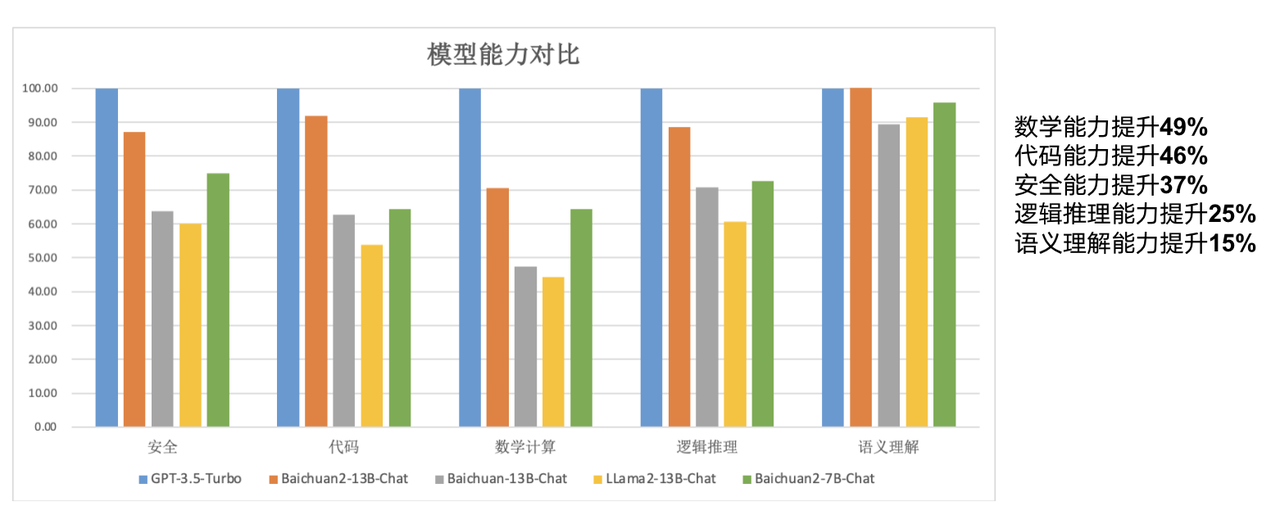
レポートによると、この新しいモデルに関して、Baichuan Intelligence の研究者はデータ収集から微調整に至るまで多くの最適化を行ったとのことです。
「以前の検索での経験をさらに活用し、大量のモデル トレーニング データに対して多粒度のコンテンツ品質スコアリングを実施し、2 億 6,000 万 T のコーパス レベルを使用して 7B および 13B モデルをトレーニングし、マルチ言語サポート」と王暁春氏は語った。 「Qianka A800 クラスターでは 180TFLOPS のトレーニング パフォーマンスを達成でき、マシン使用率は 50% を超えています。さらに、多くのセキュリティ調整作業も完了しました。」
2 つのオープンソース プロジェクトこのモデルは、主要な評価リストで良好なパフォーマンスを示しています。MMLU、CMMLU、GSM8K などのいくつかの権威ある評価ベンチマークでは、LLaMA2 を大きくリードしています。同じパラメータ数を持つ他のモデルと比較しても、パフォーマンスは非常に優れています。捕まり性能が高く、同サイズのLLaMA2競合モデルよりも振幅が優れています。
さらに注目に値するのは、MMLU などの複数の権威ある英語評価ベンチマークによると、Baichuan2-7B には、主流の英語タスクで 130 億個のパラメータを持つ LLaMA2 と同じレベルの 70 億個のパラメータがあるということです。
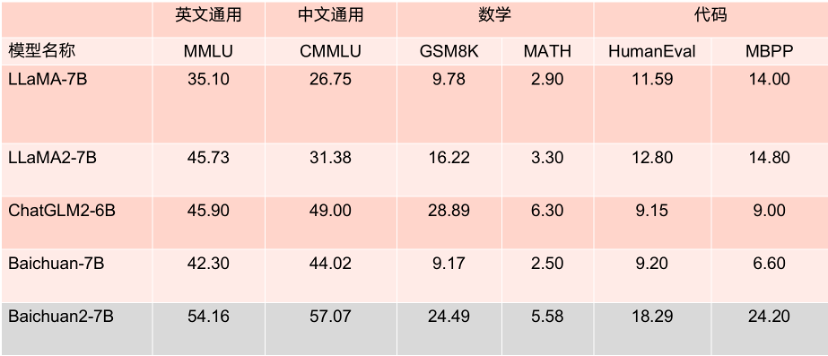
7B パラメータ モデルのベンチマーク結果。
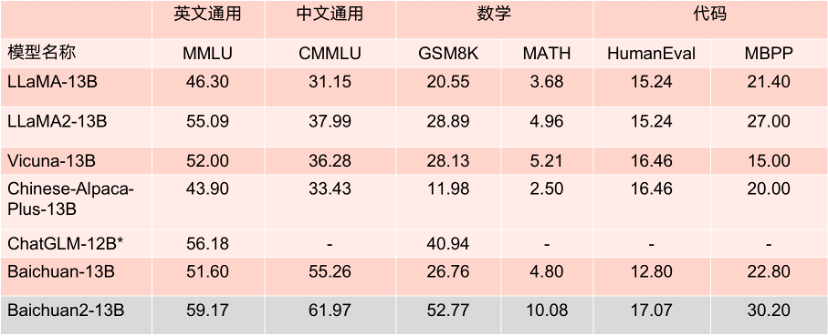
13B パラメトリック モデルのベンチマーク結果。
Baichuan2-7B および Baichuan2-13B は学術研究に完全にオープンであるだけでなく、開発者は電子メールで申請して正式な商用ライセンスを取得した後、無料で商業的に使用することもできます。
「モデルのリリースに加えて、学術分野へのさらなるサポートも提供したいと考えています」と王暁川氏は語った。 「技術レポートに加えて、Baichuan2 大型モデル トレーニング プロセスの重みパラメーター モデルも公開しました。これにより、誰もが事前トレーニングを理解したり、微調整や強化を実行したりするのに役立ちます。これも中国で初めてです。」
大規模モデルのトレーニングには、大量の高品質データの取得、大規模トレーニング クラスターの安定したトレーニング、モデル アルゴリズムのチューニングなどの複数のステップが含まれます。各リンクには多量の人材、計算能力、その他のリソースの投資が必要ですが、モデルをゼロからトレーニングするコストが高いため、学術コミュニティは大規模なモデルのトレーニングに関する詳細な研究を行うことができません。
Baichuan Intelligence は、220B から 2640B までのモデル トレーニングのプロセス全体に対して Check Ponit をオープンソース化しました。これは、科学研究機関が大型モデルのトレーニングプロセス、継続的なモデルトレーニング、モデル値の調整などを研究するのに非常に価値があり、国内の大型モデルの科学研究の進歩を促進できます。
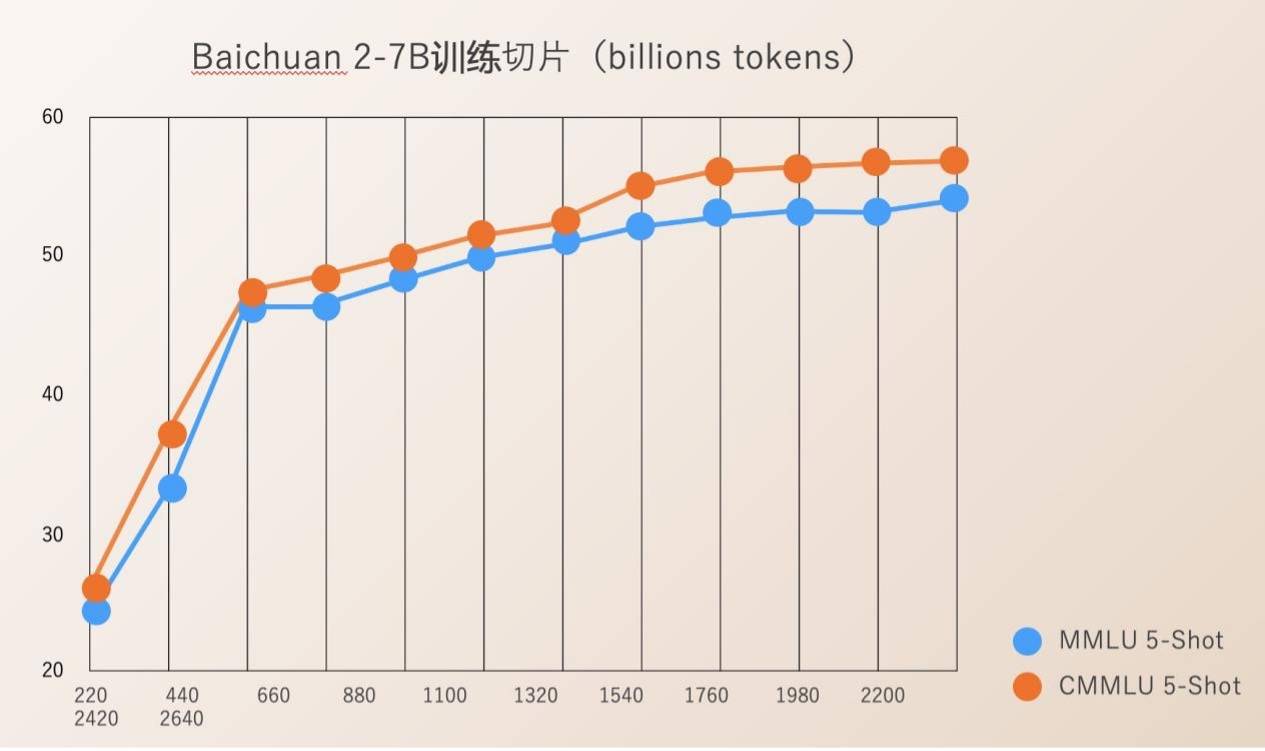
以前は、ほとんどのオープンソース モデルは、モデルの重みを外部に公開するだけで、トレーニングの詳細についてはほとんど言及されていませんでした。徹底的な調査を実施します。
Baichuan Intelligence が発行した Baichuan 2 技術レポートには、データ処理、モデル構造の最適化、スケーリング則、プロセス指標などを含む、Baichuan 2 トレーニングのプロセス全体が詳しく記載されています。
Baichuan Intelligence は設立以来、オープンソースを通じて中国の大型モデル生態系の繁栄を促進することを会社の重要な発展方向とみなしてきました。設立から 4 か月も経たないうちに、同社は 2 つのオープンソースの無料商用中国大型モデル Baichuan-7B と Baichuan-13B、および検索機能を強化した大型モデル Baichuan-53B をリリースしました。多くの信頼できるレビューでリストの上位にランクされ、500 万回以上ダウンロードされています。
先週、大規模モデルの公共サービス写真撮影の最初のバッチが開始されたことは、科学技術の分野における重要なニュースでした。今年設立された大手モデル企業の中で、百川智能は「生成型人工知能サービス管理暫定措置」に登録され、正式に一般向けにサービスを提供できる唯一の企業である。
基本的な大型モデルに業界をリードする研究開発とイノベーション機能を備えた 2 つのオープンソース Baichuan 2 モデルは、Tencent Cloud、Alibaba Cloud、Volcano Ark、Huawei、MediaTek を含む上流および下流の企業から肯定的な反応を得ています。多くの有名企業がこの会議に参加し、百川智能との協力に達しました。報告によると、Hugging Face における Baichuan Intelligence の大型モデルのダウンロード数は、過去 1 か月間で 337 万件に達しました。
Baichuan Intelligence の以前の計画によれば、今年は 1,000 億個のパラメータを備えた大規模モデルをリリースし、来年の第 1 四半期に「スーパー アプリケーション」をリリースする予定です。
以上がBaichuan Intelligent は Baichuan2 大型モデルをリリースしました。これは Llama2 よりも完全に先を行っており、トレーニング スライスもオープンソースですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1382
52
83
11
28
96
15
1382
52
83
11
28
96

 ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
これも Tusheng のビデオですが、PaintsUndo は別の道を歩んでいます。 ControlNet 作者 LvminZhang が再び生き始めました!今回は絵画の分野を目指します。新しいプロジェクト PaintsUndo は、開始されて間もなく 1.4kstar を獲得しました (まだ異常なほど上昇しています)。プロジェクトアドレス: https://github.com/lllyasviel/Paints-UNDO このプロジェクトを通じて、ユーザーが静止画像を入力すると、PaintsUndo が線画から完成品までのペイントプロセス全体のビデオを自動的に生成するのに役立ちます。 。描画プロセス中の線の変化は驚くべきもので、最終的なビデオ結果は元の画像と非常によく似ています。完成した描画を見てみましょう。
 オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com この論文の著者は全員、イリノイ大学アーバナ シャンペーン校 (UIUC) の Zhang Lingming 教師のチームのメンバーです。博士課程4年、研究者
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
乾杯!紙面でのディスカッションが言葉だけになると、どんな感じになるでしょうか?最近、スタンフォード大学の学生が、arXiv 論文のオープン ディスカッション フォーラムである alphaXiv を作成しました。このフォーラムでは、arXiv 論文に直接質問やコメントを投稿できます。 Web サイトのリンク: https://alphaxiv.org/ 実際、URL の arXiv を alphaXiv に変更するだけで、alphaXiv フォーラムの対応する論文を直接開くことができます。この Web サイトにアクセスする必要はありません。その中の段落を正確に見つけることができます。論文、文: 右側のディスカッション エリアでは、ユーザーは論文のアイデアや詳細について著者に尋ねる質問を投稿できます。たとえば、次のような論文の内容についてコメントすることもできます。
 リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
最近、2000年代の7大問題の一つとして知られるリーマン予想が新たなブレークスルーを達成した。リーマン予想は、数学における非常に重要な未解決の問題であり、素数の分布の正確な性質に関連しています (素数とは、1 とそれ自身でのみ割り切れる数であり、整数論において基本的な役割を果たします)。今日の数学文献には、リーマン予想 (またはその一般化された形式) の確立に基づいた 1,000 を超える数学的命題があります。言い換えれば、リーマン予想とその一般化された形式が証明されれば、これらの 1,000 を超える命題が定理として確立され、数学の分野に重大な影響を与えることになります。これらの命題の一部も有効性を失います。 MIT数学教授ラリー・ガスとオックスフォード大学から新たな進歩がもたらされる
 公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
LLM に因果連鎖を示すと、LLM は公理を学習します。 AI はすでに数学者や科学者の研究を支援しています。たとえば、有名な数学者のテレンス タオは、GPT などの AI ツールを活用した研究や探索の経験を繰り返し共有しています。 AI がこれらの分野で競争するには、強力で信頼性の高い因果推論能力が不可欠です。この記事で紹介する研究では、小さなグラフでの因果的推移性公理の実証でトレーニングされた Transformer モデルが、大きなグラフでの推移性公理に一般化できることがわかりました。言い換えれば、Transformer が単純な因果推論の実行を学習すると、より複雑な因果推論に使用できる可能性があります。チームが提案した公理的トレーニング フレームワークは、デモンストレーションのみで受動的データに基づいて因果推論を学習するための新しいパラダイムです。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 最初の Mamba ベースの MLLM が登場しました!モデルの重み、トレーニング コードなどはすべてオープンソースです
Jul 17, 2024 am 02:46 AM
最初の Mamba ベースの MLLM が登場しました!モデルの重み、トレーニング コードなどはすべてオープンソースです
Jul 17, 2024 am 02:46 AM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com。はじめに 近年、さまざまな分野でマルチモーダル大規模言語モデル (MLLM) の適用が目覚ましい成功を収めています。ただし、多くの下流タスクの基本モデルとして、現在の MLLM はよく知られた Transformer ネットワークで構成されています。
