

Code Llama が登場するとすぐに、誰もが誰かが量的スリム化を継続することを期待していました。幸いなことに、これはローカルで実行できます。
実際に行動を起こしたのは、llama.cpp の作者である Georgi Gerganov でした。 :
量子化を行わない場合、Code LLama の 34B コードは Apple コンピュータ上で実行でき、FP16 精度であっても 1 秒あたり 20 トークンを超える推論速度を実現できます
 写真
写真
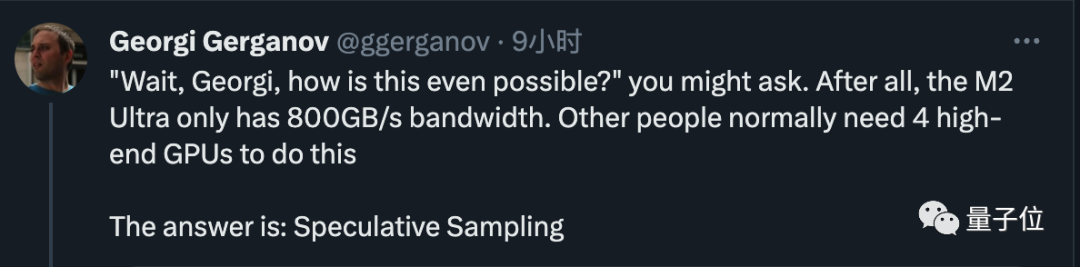
800 GB/秒の帯域幅を持つ M2 Ultra を使用するだけで、当初 4 つのハイエンド GPU を必要としたタスクを完了し、非常に迅速にコードを作成できるようになりました
老人はその秘密を明らかにしました。答えは非常に簡単です。投機的なサンプリング/デコードを実行することです。
 画像
画像
# がトリガーされ、多くの人の注目が集まります。業界の巨人
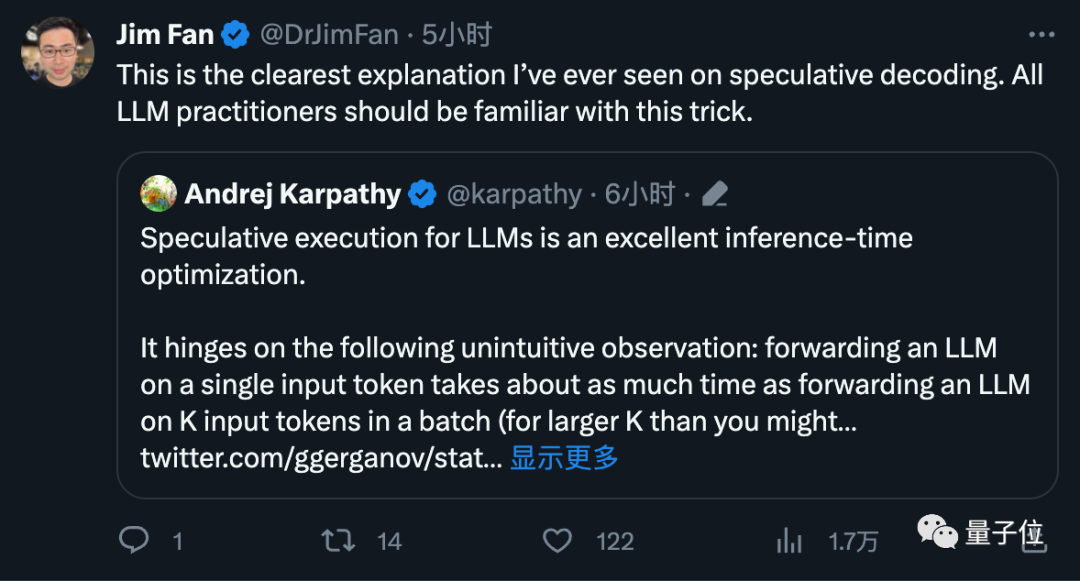
OpenAI の創設メンバーである Andrej Karpathy 氏は、これは優れた推論時間の最適化であるとコメントし、より技術的な説明を行いました。
NVIDIA の科学者である Fan Linxi 氏も、これは大規模モデルを扱うすべての人がよく知っておくべきテクニックであると考えています。
 写真
写真
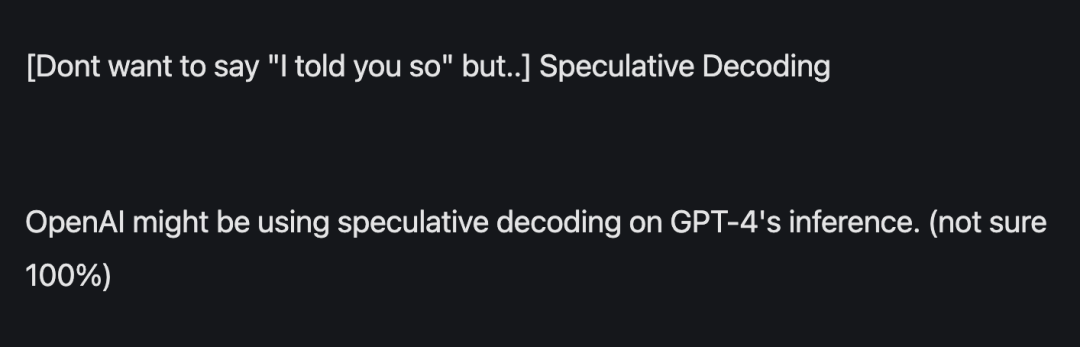
投機的サンプリングを使用している人は、大規模なモデルをローカルで実行している人に限定されません。Google や OpenAI などの超大手もこのテクノロジーを使用しています
によると前 漏洩情報によると、GPT-4 は推論コストを削減するためにこの方法を使用しました。そうでなければ、そのようなコストを費やす余裕はありません。
 写真
写真
最新のニュースでは、Google DeepMind が共同開発した次世代大型モデル Gemini も使用される可能性が高いことが示されています。
OpenAI の具体的な手法は機密ですが、Google チームは関連論文を公開しており、その論文は ICML 2023 の口頭報告書に選ばれました
 写真
写真
方法は非常に簡単です。まず、大規模モデルと同様で安価な小規模モデルをトレーニングします。最初に小規模モデルに K 個のトークンを生成させ、その後、大規模モデルに判断を行わせます。
大規模モデルは承認された部分を直接使用し、受け入れられなかった部分を大規模モデルで変更できます
元の研究では、デモンストレーションに T5-XXL モデルが使用され、生成は維持 結果は変わりませんが、2 ~ 3 倍の推論加速が得られます
 写真
写真
Andjrey Karpathy 氏は、この方法を「最初に小さなモデルを作成する」と例えています。草案を準備してください。」
#彼は、この方法の有効性の鍵は、大規模なモデルがトークンとトークンのバッチに入力されたとき、次のトークンを予測するのに必要な時間がほぼ同じであることであると説明しました各トークンは前のトークンに依存するため、通常の状況では複数のトークンを同時にサンプリングすることは不可能です小規模なモデルは機能が貧弱ですが、実際に文を生成する場合は非常に単純な部分が多く、小さなモデルもできます。それは有能です。難しい部分は大きなモデルに任せるだけです。 元の論文では、既存の成熟したモデルは構造の変更や再トレーニングを行わずに直接高速化できると指摘しています。この点は精度を低下させるものではなく、この点については論文の付録にも記載されています。数学的議論。 写真
写真
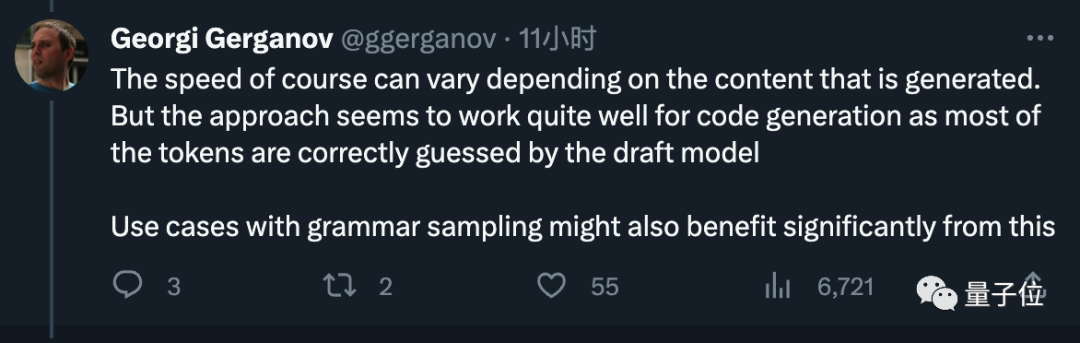
#写真  # さらに、速度は生成されるコンテンツによって異なる可能性があるが、コードでは非常に効果的であると述べています。世代に応じて、ドラフト モデルはほとんどのトークンを正確に推測できます。
# さらに、速度は生成されるコンテンツによって異なる可能性があるが、コードでは非常に効果的であると述べています。世代に応じて、ドラフト モデルはほとんどのトークンを正確に推測できます。
 写真
写真
最後に、将来モデルをリリースするときに、Meta が小さなドラフト モデルを直接含めることも提案し、これは全員から好評でした。
 写真
写真
Georgi Gerganov が著者で、第一世代の LlaMA を C に移植しました。今年の3月は優秀。彼のオープンソース プロジェクト llama.cpp は、約 40,000 個のスターを獲得しました。
 写真
写真
彼は当初、これを趣味としてのみ考えていましたが、反響は圧倒的でした。そして6月にはエッジデバイス上でAIを実行することに特化した新会社ggml.aiを発表した。同社の主力製品は、llama.cpp の背後にある C 言語機械学習フレームワークです。
写真 ビジネスの初期段階では、サポートを得ることができました。 GitHub Executive の元最高経営責任者 Nat Friedman 氏と Y Combinator パートナーの Daniel Gross 氏のプレシード投資から
ビジネスの初期段階では、サポートを得ることができました。 GitHub Executive の元最高経営責任者 Nat Friedman 氏と Y Combinator パートナーの Daniel Gross 氏のプレシード投資から
彼は LlaMA2 のリリース後も非常に活発でしたが、最も冷酷なのは大規模なモデルを直接詰め込むことでした。ブラウザ。
写真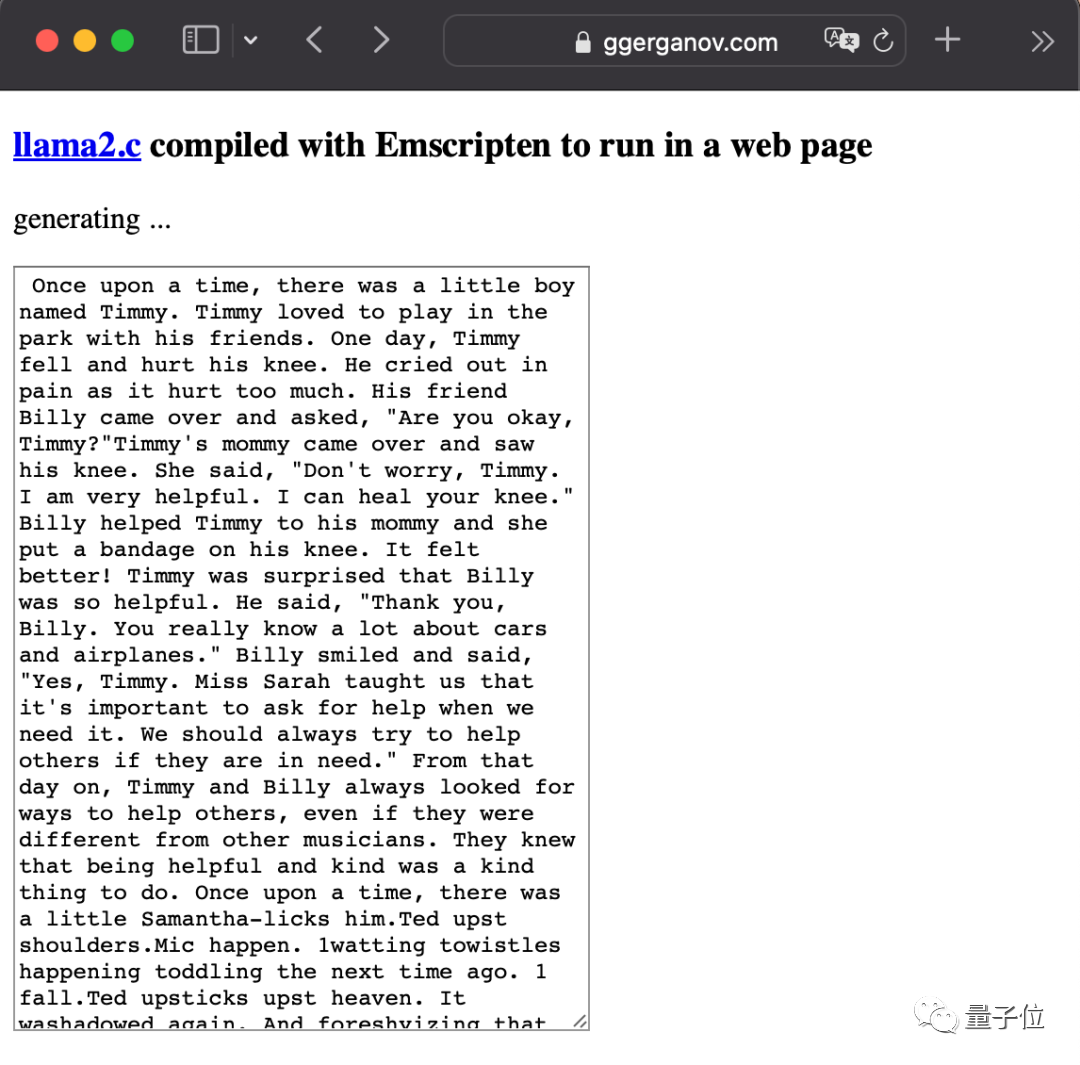 Google の推測的サンプリング ペーパーを確認してください: https://arxiv.org/abs/2211.17192
Google の推測的サンプリング ペーパーを確認してください: https://arxiv.org/abs/2211.17192
参考リンク: [ 1]https://x.com/ggerganov/status/1697262700165013689 [2]https://x.com/karpathy/status/1697318534555336961
以上がApple コアは計算精度を落とさずに大規模なモデルを実行します。投機的サンプリングはクレイジーです。GPT-4 も使用されます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



