

Jia Qianghuai: アリの大規模知識グラフの構築と応用


最初に、ナレッジ グラフの基本概念をいくつか紹介します。
1. ナレッジ グラフとは何ですか?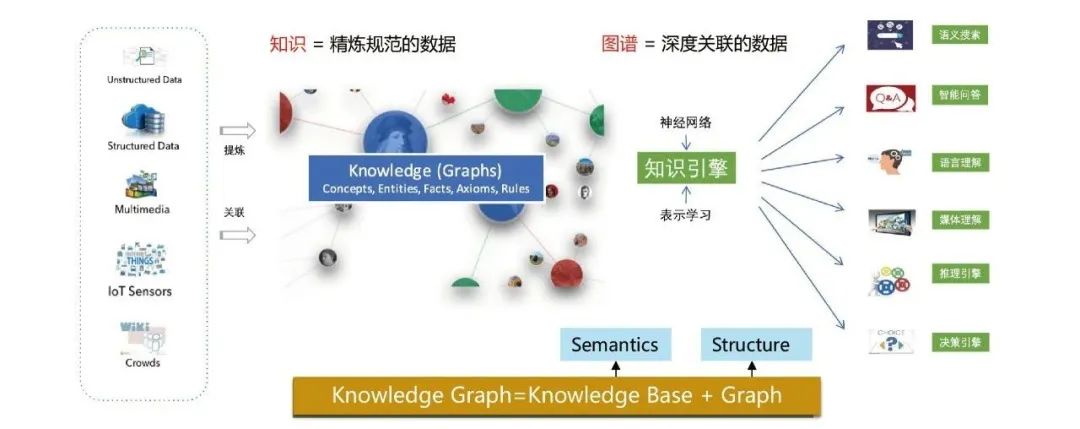
ナレッジ グラフは、グラフ構造を使用してモデル化、識別、推論することを目的としています。複雑な関係と蓄積されたドメイン知識は、認知知能を実現するための重要な基礎であり、検索エンジン、インテリジェントな質問応答、言語意味理解、ビッグデータ意思決定分析などの多くの分野で広く使用されています。
ナレッジ グラフは、データ間の意味的関係と構造的関係の両方をモデル化し、深層学習テクノロジと組み合わせることで、2 つの関係をより適切に統合して表現できます。
2. ナレッジ グラフを構築する理由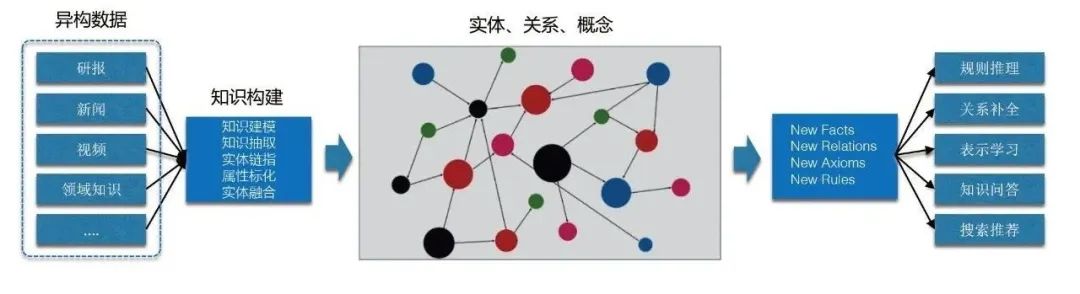
主に次の 2 つの点からナレッジ グラフを構築したいと考えています: それは一方ではアリ自身のデータソースの背景特性であり、他方ではナレッジグラフがもたらすことができる利点です。
[1] データ ソース自体は多様かつ異質であり、統一された知識理解システムが不足しています。
[2] ナレッジ グラフは次のような多くの利点をもたらします。
- セマンティック標準化: グラフ構築の使用 テクノロジーの向上エンティティ、関係、概念などの標準化と正規化のレベル。
- #ドメイン知識の蓄積: セマンティクスとグラフ構造に基づいた知識表現と相互接続を実現し、それによって豊富なドメイン知識を蓄積します。
- ナレッジの再利用: 高品質の Ant ナレッジ グラフを構築し、統合、リンク、その他のサービスを通じて複数のダウンストリーム サービスを提供することで、ビジネス コストを削減し、効率を向上します。 #知識推論の発見: グラフ推論テクノロジーに基づいて、より多くのロングテールの知識を発見し、リスク管理、信用、請求、マーチャントの運営、マーケティングの推奨事項などのシナリオに対応します。 、など。
- #3. ナレッジ グラフの構築方法の概要
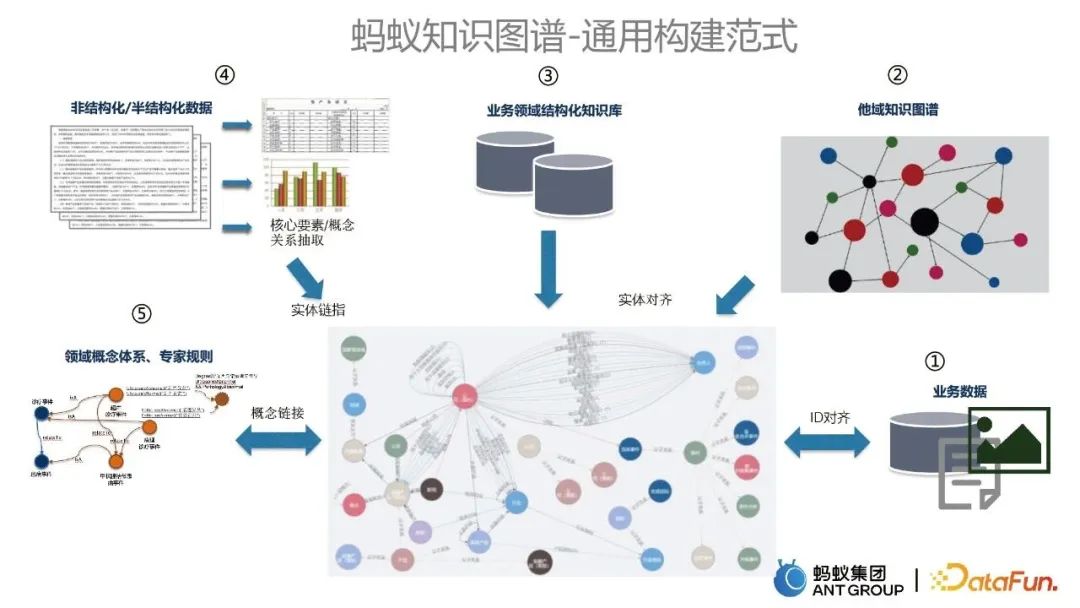 さまざまなビジネス ナレッジを構築する過程でグラフ では、アリ ナレッジ グラフの一般的な構築パラダイムのセットを作成しました。これらは主に次の 5 つの部分に分かれています:
さまざまなビジネス ナレッジを構築する過程でグラフ では、アリ ナレッジ グラフの一般的な構築パラダイムのセットを作成しました。これらは主に次の 5 つの部分に分かれています:
重要な部分としてビジネス データから始まります。グラフ データ ソースのコールド スタート。
- 他のドメインのナレッジ グラフは、エンティティ アライメント テクノロジによって既存のグラフと統合されます。
- ビジネス ドメインの構造化ナレッジ ベースと既存のナレッジ グラフの統合も、エンティティ アライメント テクノロジによって実現されます。
- テキストなどの非構造化データおよび半構造化データは、エンティティ リンク テクノロジを通じて情報を抽出し、既存のマップを更新するために使用されます。
- ドメイン概念システムとエキスパート ルールの統合により、関連する概念とルールが既存のナレッジ グラフにリンクされます。
#共通の構築パラダイムを確立したら、体系的な構築を実行する必要があります。 Ant Knowledge Graph の体系的な構築を 2 つの観点から見てみましょう。まず、アルゴリズムの観点から見ると、知識推論、知識照合などのさまざまなアルゴリズム機能があります。実装の観点から見ると、下から上に、最も低い基本依存関係にはグラフ コンピューティング エンジンとコグニティブ ベース コンピューティングが含まれ、その上には NLP およびマルチモーダル プラットフォームとグラフ プラットフォームを含むグラフ ベースがあり、その上にはさまざまなグラフ構築テクノロジがあり、これに基づいて、アリのナレッジ グラフを構築できます。ナレッジ グラフに基づいて、いくつかのグラフ推論を実行できます。さらに、いくつかの一般的なアルゴリズム機能を提供し、最上位にビジネス アプリケーションがあります。 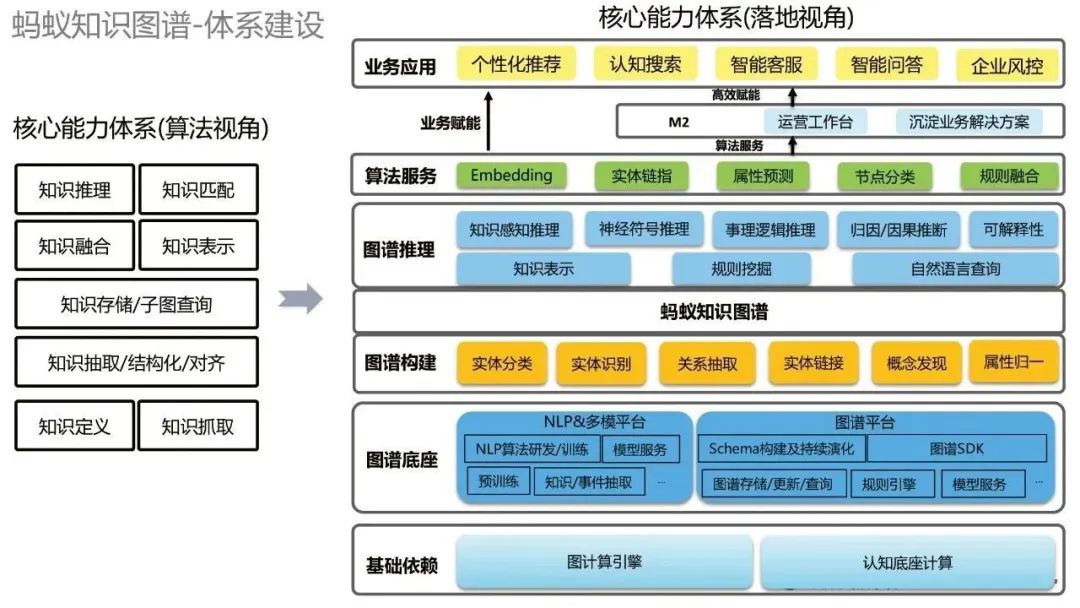
2. グラフの構築
次に、グラフの構築、グラフの融合、グラフの認識など、ナレッジ グラフの構築における Ant Group のコア機能の一部を共有します。1. グラフの構築
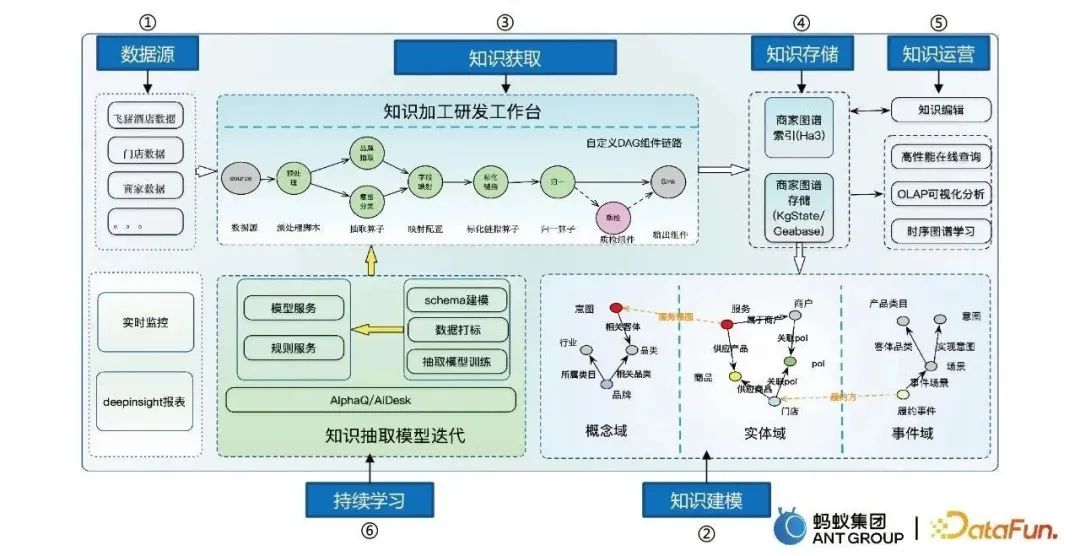
グラフ構築プロセスには主に 6 つのステップが含まれます:
- データ多変量データを取得するためのソース。
- ナレッジ モデリングは、大量のデータを構造化データに変換し、概念、エンティティ、イベントの 3 つのドメインからモデル化します。
- 知識の獲得と知識処理の研究開発プラットフォームの構築。
- Ha3 ストレージやグラフ ストレージなどのナレッジ ストレージ。
- ナレッジ編集、オンラインクエリ、抽出などを含むナレッジ操作。
- 継続学習により、モデルは自動的かつ反復的に学習できます。
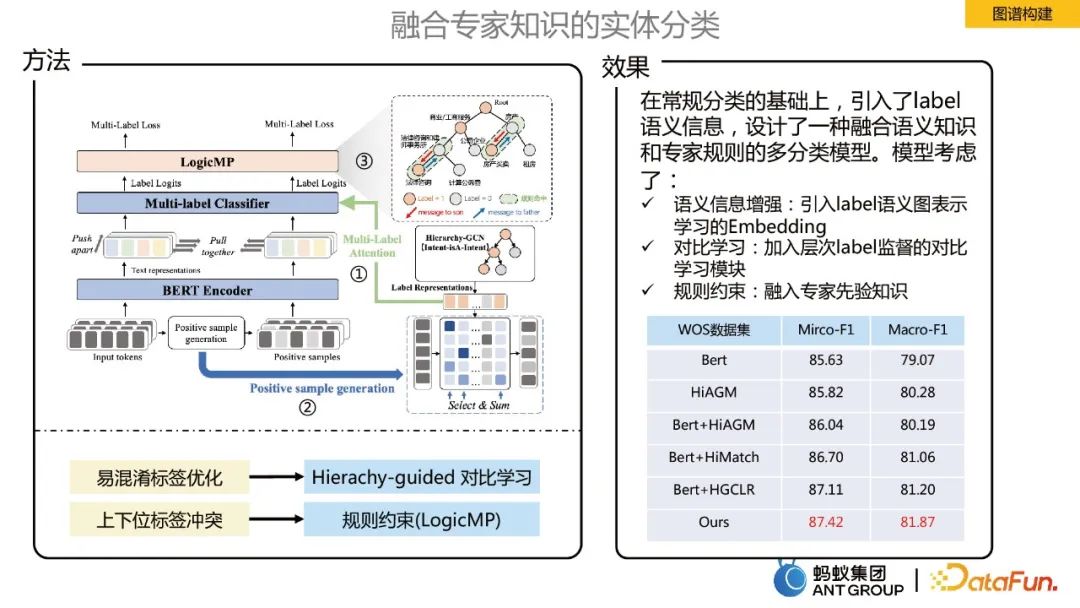
- 意味情報の強化: ラベル意味グラフ表現学習の埋め込みを導入します。
- 対照学習: 比較のための階層ラベル監視を追加します。
- 論理ルールの制約: 専門家の事前知識を組み込みます。
- #ドメイン語彙にエンティティ認識を挿入
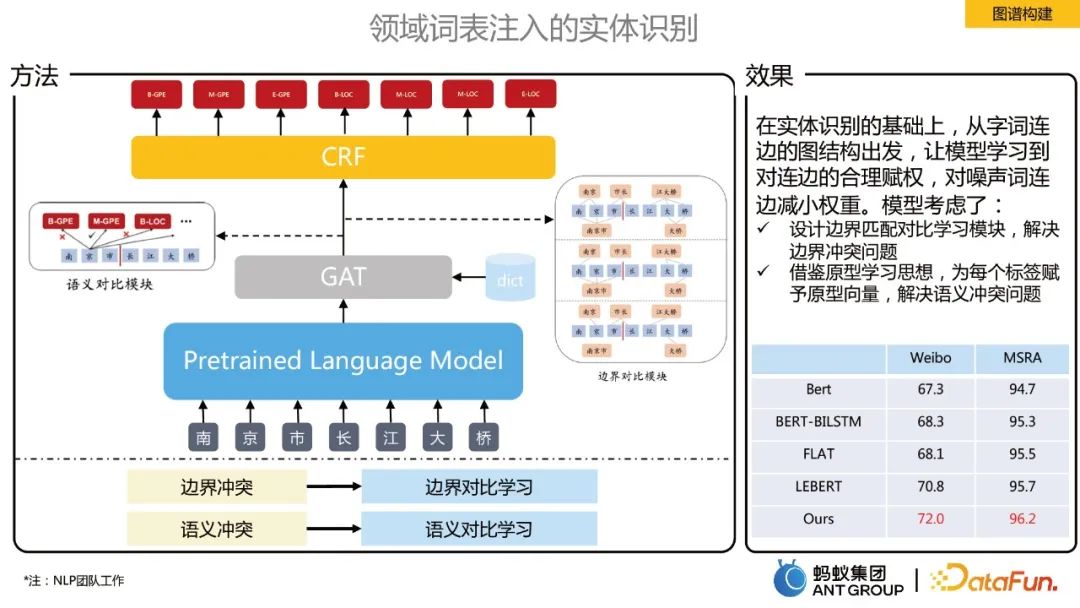
- 境界コントラスト学習は、境界競合問題を解決するために使用されます。語彙が注入された後、全結合グラフが構築され、GAT を使用して各トークンの表現が学習されます。境界分類の正しい部分は正の例のグラフを構築し、不正確な部分は負の例のグラフを構築します。比較を通じて、モデルは各トークンを学習します トークンの境界情報。
- #セマンティック対照学習は、セマンティック競合の問題を解決するために使用されます。プロトタイプ学習のアイデアに基づいて、ラベルの意味表現が追加され、各トークンとラベルの意味の関連付けが強化されます。 #論理ルールに制約された小規模なサンプル関係抽出
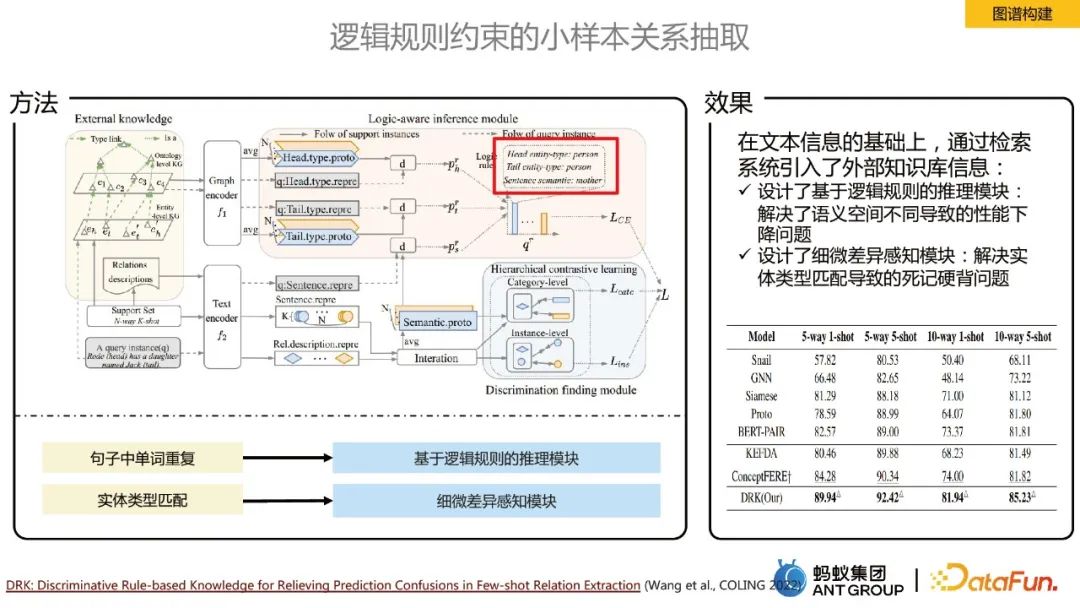 アノテーション サンプルは、ドメインの問題に関して非常に大規模ですこれより少ない場合は、数ショットまたはゼロショットのシナリオに直面します。この場合、関係抽出の中心となるアイデアは、外部ナレッジ ベースを導入することです。原因となるパフォーマンス低下の問題を解決するために、異なる意味空間により、論理規則に基づく推論モジュールを設計し、エンティティタイプのマッチングによって引き起こされる暗記学習の問題を解決するために、微妙な差異認識モジュールを設計します。
アノテーション サンプルは、ドメインの問題に関して非常に大規模ですこれより少ない場合は、数ショットまたはゼロショットのシナリオに直面します。この場合、関係抽出の中心となるアイデアは、外部ナレッジ ベースを導入することです。原因となるパフォーマンス低下の問題を解決するために、異なる意味空間により、論理規則に基づく推論モジュールを設計し、エンティティタイプのマッチングによって引き起こされる暗記学習の問題を解決するために、微妙な差異認識モジュールを設計します。
2. グラフ フュージョン
グラフ フュージョンとは、異なるビジネス分野のグラフ間の情報を融合することを指します。
グラフ フュージョンの利点: 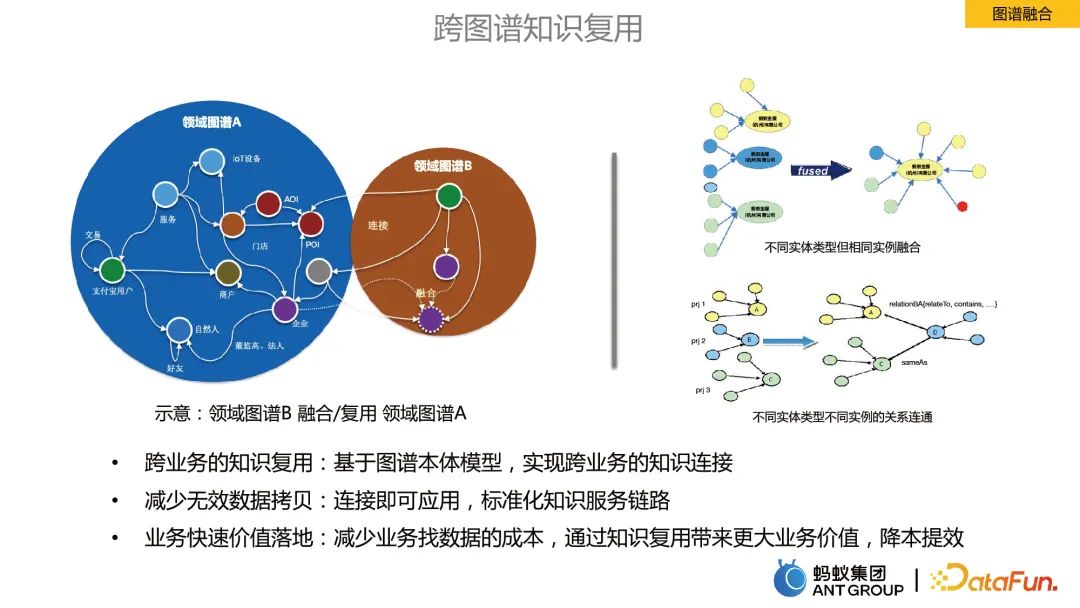
- ビジネスを超えた知識の再利用: グラフ オントロジー モデルに基づく、ビジネスを超えた知識のつながりを実現します。
- # 無効なデータ コピーを削減: 接続直後に適用され、標準化されたナレッジ サービス リンクが適用されます。
- ビジネス価値の迅速な実現: ビジネスのためのデータを見つけるコストを削減し、ナレッジの再利用を通じてより大きなビジネス価値をもたらし、コストを削減し、効率を向上させます。
- グラフ フュージョンにおけるエンティティの配置
ナレッジ グラフ融合プロセスの中核となる技術ポイントはエンティティのアライメントです。ここでは SOTA アルゴリズム BERT-INT を使用します。これには主に 2 つのモジュールが含まれています。1 つはプレゼンテーション モジュール、もう 1 つはインタラクション モジュールです。
アルゴリズムの実装プロセスには主にリコールとソートが含まれます:
リコール: プレゼンテーション モジュールでは、タイトル テキストは BERT ベクトル類似性リコールを使用します。
タイトル属性の近傍に基づくモデルの並べ替え: ü 表現モジュールを使用して、タイトル、属性、および近傍のベクトル表現を完成させます:
- タイトルの cos 類似度を計算します。
- 2 つのエンティティの属性と近傍セット間の類似度行列をそれぞれ計算し、1 次元の類似度特徴を抽出します。
- # 3 つの特徴を特徴ベクトルに結合して、損失を計算します。
#3. グラフ認知
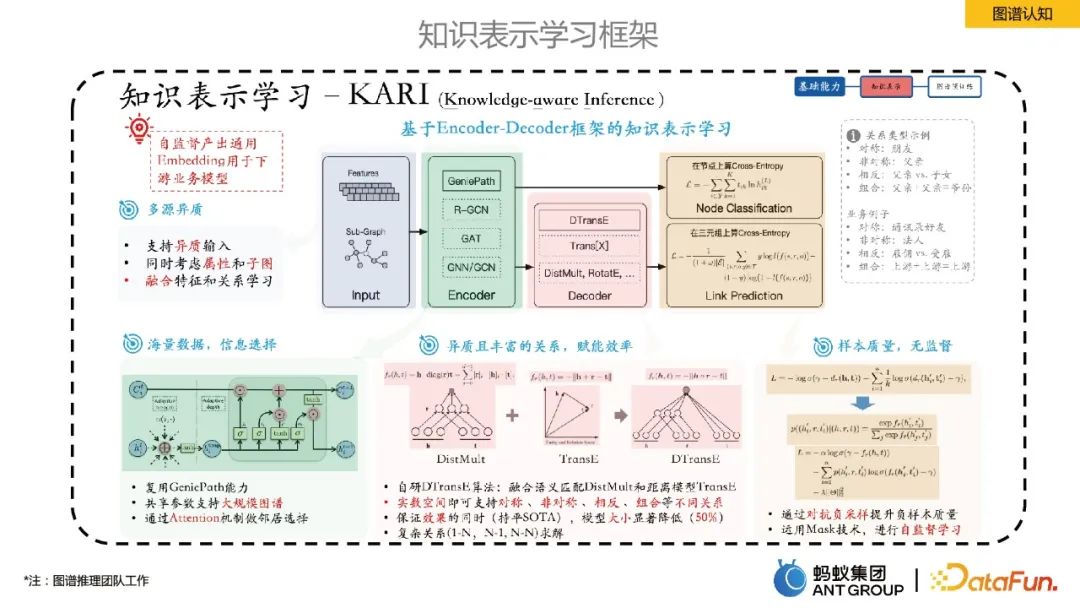
このパートでは主にアリフレームの内部知識表現学習を紹介します。
Ant は、Encoder-Decoder フレームワークに基づいた知識表現学習を提案しました。このうち、Encoder はグラフ ニューラル学習手法であり、Decoder はリンク予測などの知識表現学習です。この表現学習フレームワークは、普遍的なエンティティ/関係エンベディングの生成を自己監視でき、これにはいくつかの利点があります: 1) エンベディング サイズが元の特徴空間よりもはるかに小さいため、ストレージ コストが削減されます; 2) 低次元ベクトルが高密度になり、効果的に緩和されます。データの疎性の問題; 3) 同じベクトル空間での学習により、複数のソースからの異種データの融合がより自然になります; 4) 埋め込みには一定の普遍性があり、下流のビジネス用途に便利です。
3. グラフの適用
次に、Ant Group におけるナレッジ グラフの典型的な適用事例をいくつか紹介します。
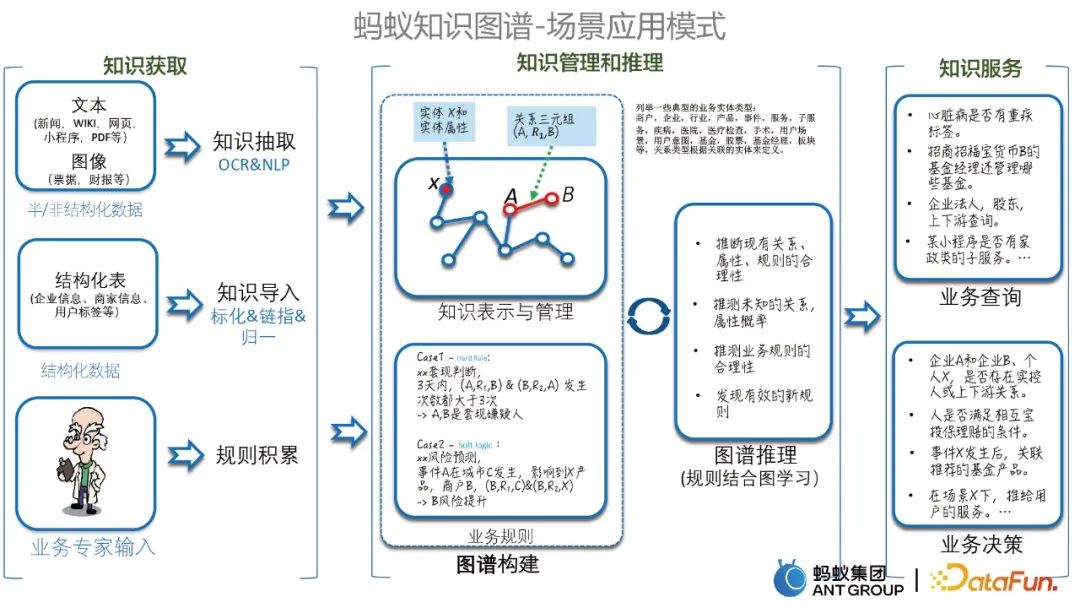
1. グラフのシナリオ適用モード
特定のケースを紹介する前に、まず、知識の獲得、ナレッジなど、Ant Knowledge Graph のシナリオ適用のいくつかのモードを紹介します。管理と推論、および知識サービス。以下に示すように。
#2. いくつかの典型的なケース
ケース 1: ナレッジ グラフに基づいた構造化された一致再現
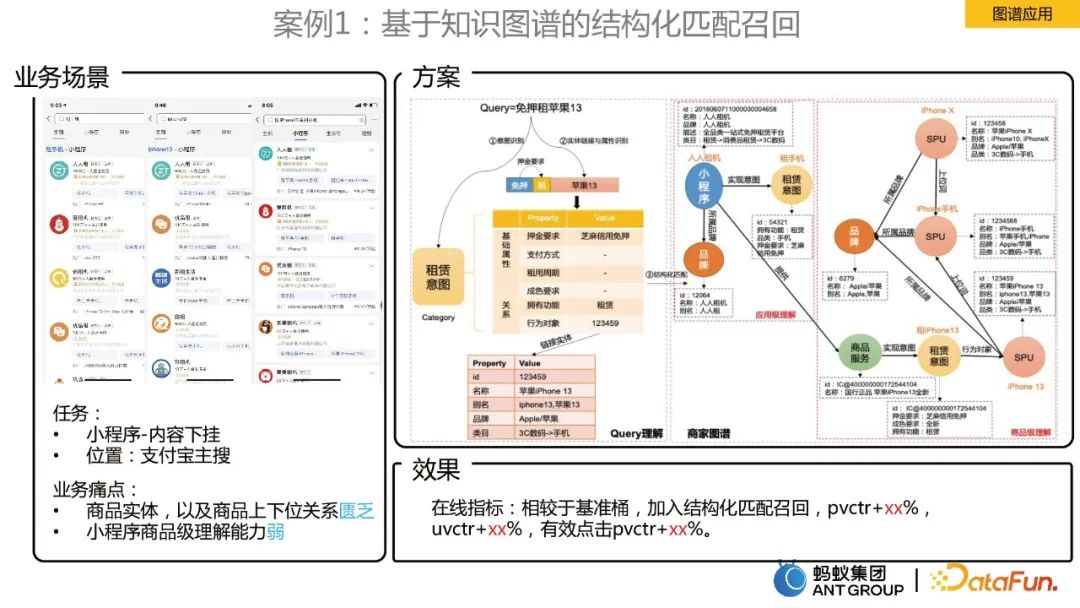
ビジネス シナリオは、Alipay のメイン検索でミニ プログラムのコンテンツをダウンロードすることです。解決すべきビジネスの問題点は次のとおりです:
- products エンティティ、および商品と製品間の関係が欠落しています。
- #小規模プログラムに対する製品レベルの理解が不十分。
#解決策は、マーチャント ナレッジ グラフを構築することです。販売者マップの製品関係と組み合わせることで、ユーザーのクエリ製品レベルの構造化された理解が達成されます。
ケース 2: レコメンデーション システムにおけるユーザーの意図のリアルタイム予測
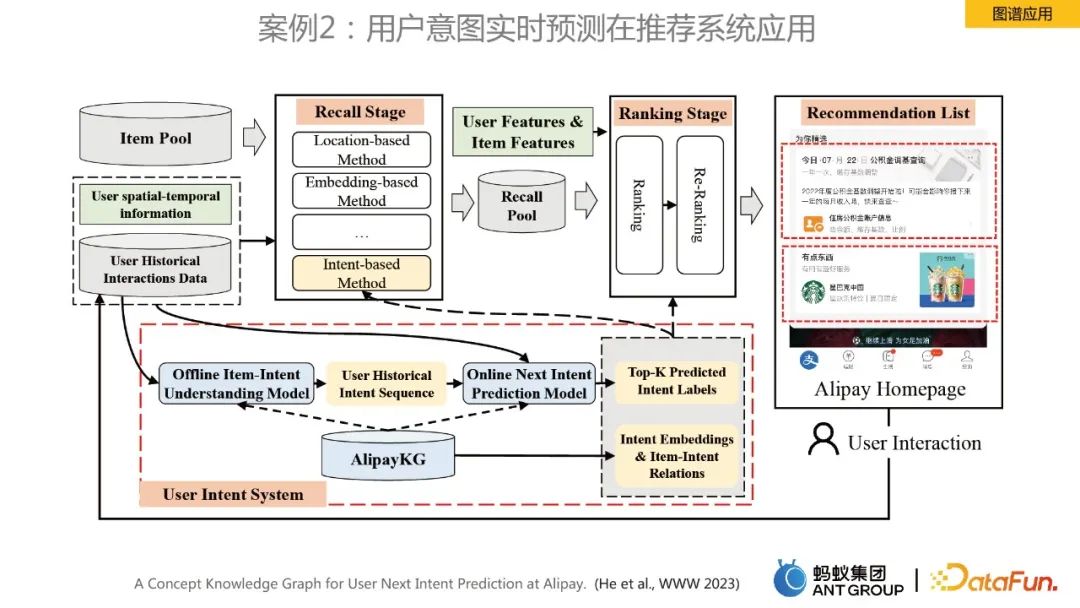
このケースは、ユーザーのリアルタイム予測を目的としています。ホームページの推奨を目的として、AlipayKG が構築され、そのフレームワークは上の図に示されています。関連研究は、トップカンファレンス www 2023 にも掲載されました。さらに理解するには、この論文を参照してください。
#ケース 3: 知識表現を統合したマーケティング クーポンの推奨
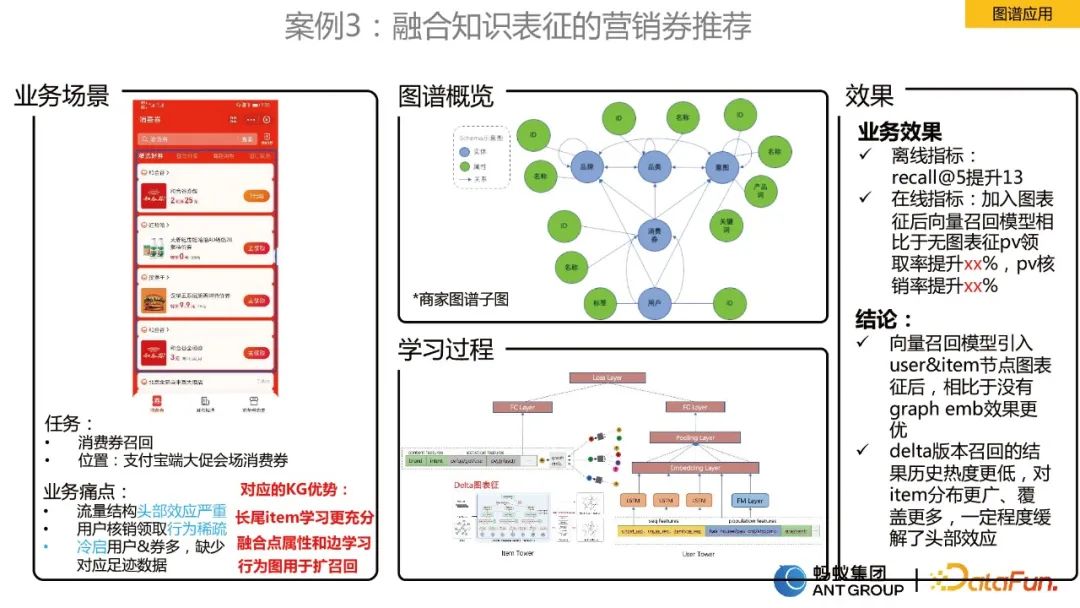
#このシナリオは、消費者向けクーポンの推奨とビジネスのシナリオです。問題点は次のとおりです:
- #頭部への影響は深刻です。
- # ユーザーの検証と収集の動作はまばらです。
- #コールド スタート ユーザーとクーポンは多数ありますが、対応するフットプリント データが不足しています。
#上記の問題を解決するために、動的グラフ表現を統合するディープベクトルリコールアルゴリズムを設計しました。ユーザー消費クーポンの動作は周期的であることが判明したため、静的な単一エッジではこの周期的動作をモデル化できません。この目的のために、最初に動的グラフを構築し、次にチームが独自に開発した動的グラフ アルゴリズムを使用して埋め込み表現を学習し、表現を取得した後、それをベクトル再現のためにツインタワー モデルに組み込みました。
ケース 4: 診断および治療イベントに基づくインテリジェント クレーム エキスパート ルール推論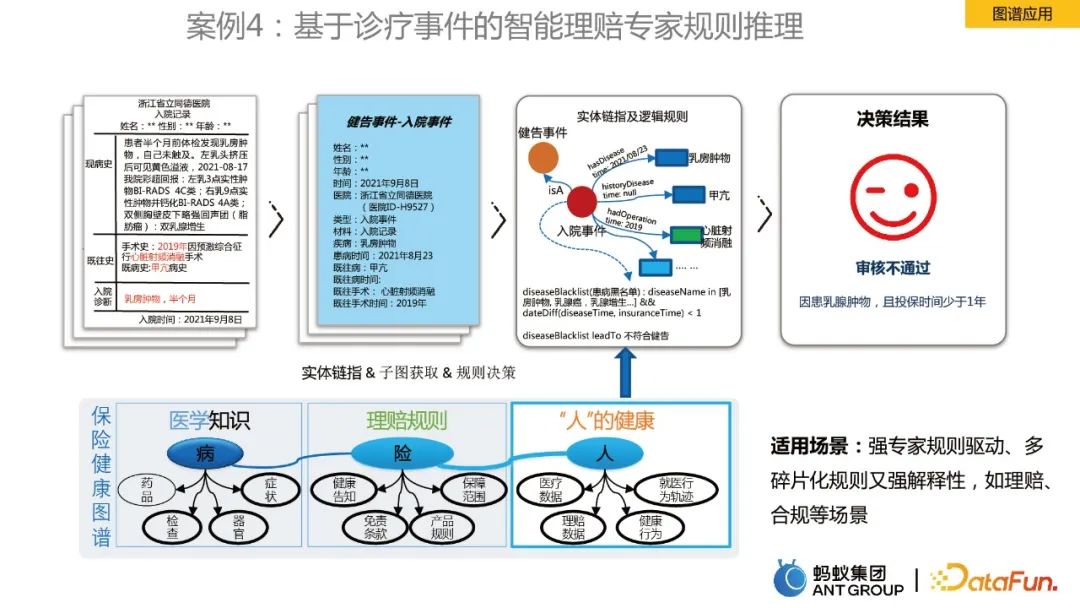
最後のケースは、グラフ ルール推論に関するものです。医療保険の健康マップを例にとると、これには医学的知識、請求ルール、および「個人」の健康情報が含まれており、これらはエンティティに関連付けられ、意思決定の基礎として論理的なルールと結合されています。マップを通じて、専門家による請求解決の効率が向上しました。
4. グラフと大規模モデル最後に、現在急速に開発されている大規模モデルの文脈におけるナレッジ グラフの機会について簡単に説明します。
1. ナレッジ グラフと大規模モデルの関係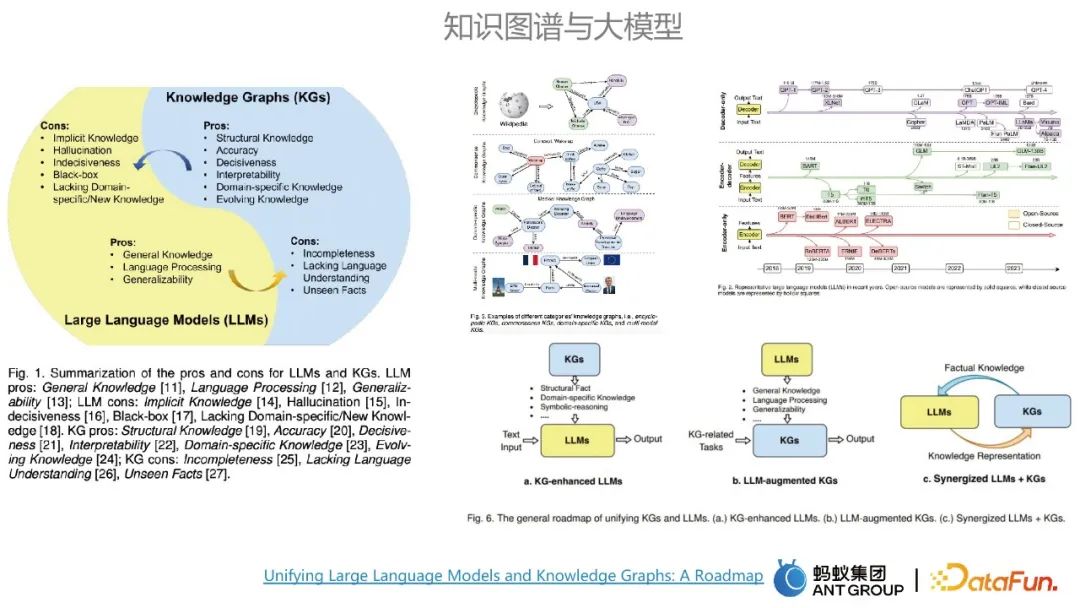
ナレッジ グラフと大規模モデルには、それぞれ長所と短所があります。大規模モデルの主な利点は、一般知識のモデリングと汎用性の利点があり、大規模モデルの欠点はナレッジ グラフの利点によって補うことができます。地図の利点としては、高精度と強力な解釈可能性が挙げられます。大規模なモデルとナレッジ グラフは相互に影響を与える可能性があります。
グラフと大規模なモデルを統合するには、通常 3 つの方法があります。1 つはナレッジ グラフを使用して大規模なモデルを強化すること、2 つ目は大規模なモデルを使用してナレッジ グラフを強化することです。 3 番目は、ナレッジ グラフを使用して大規模なモデルを強化することです。大規模なモデルとナレッジ グラフは連携して相互に補完します。大規模なモデルはパラメータ化された知識ベースと考えることができ、ナレッジ グラフは表示された知識ベースと考えることができます。 #2. 大規模モデルとナレッジ グラフの適用事例
大規模モデルのナレッジ グラフ構築への適用
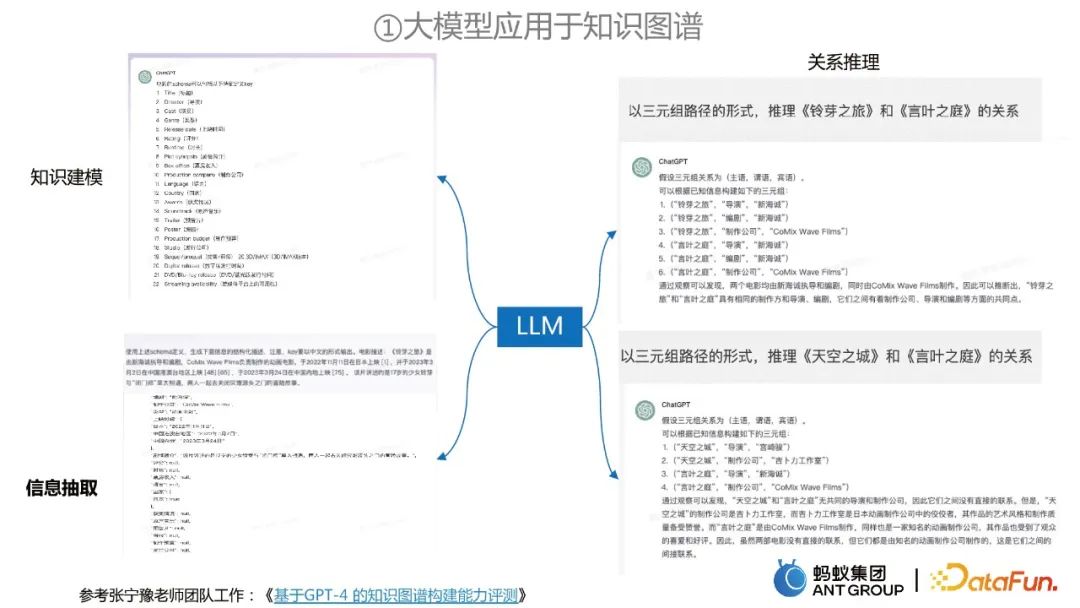
大規模モデルを使用してナレッジ グラフからの情報抽出に適用する方法

- 最初の段階では、テキスト内に存在するエンティティ、関係、またはイベント タイプを検索して、検索スペースを削減し、計算の複雑さ。
- #第 2 段階では、以前に抽出したタイプと指定された対応するリストに基づいて、関連情報をさらに抽出します。 #ナレッジ グラフを大規模モデルに適用する
##ナレッジ グラフを大規模モデルに適用するには、主に 3 つの側面が含まれます。 : 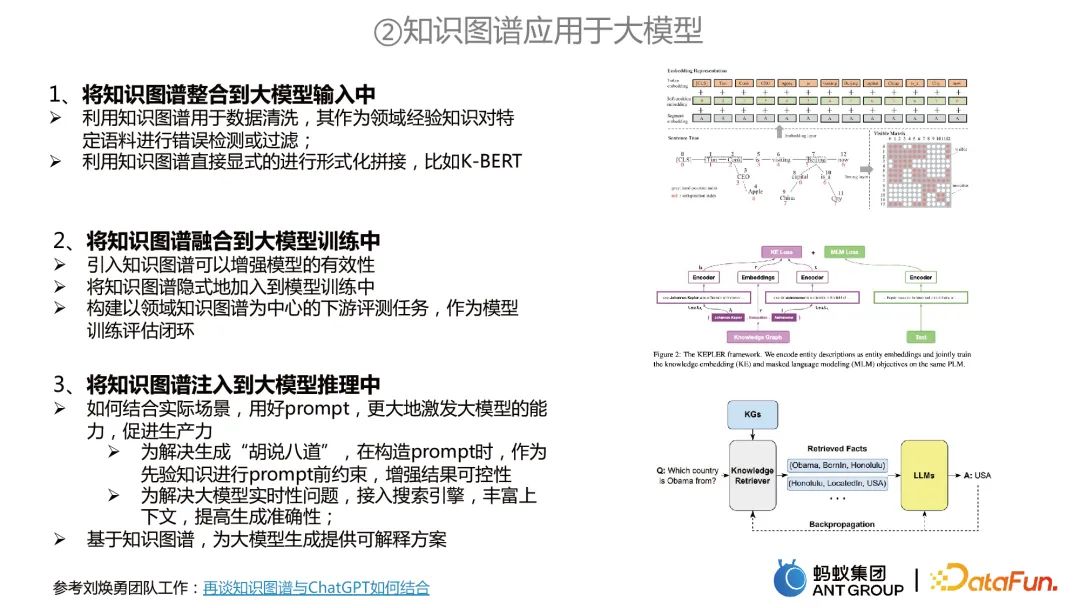
ナレッジ グラフを大規模モデル入力に統合します。ナレッジ グラフをデータ クリーニングに使用したり、ナレッジ グラフを使用して正式なスプライシングを直接実行したりできます。
ナレッジ グラフを大規模なモデルのトレーニングに統合します。たとえば、2 つのタスクを同時にトレーニングします。ナレッジ グラフは知識表現タスクに使用でき、大規模モデルは MLM の事前トレーニングに使用でき、この 2 つは共同でモデル化されます。
ナレッジ グラフを大規模なモデル推論に挿入します。まず、大規模モデルに関する 2 つの問題を解決できます。1 つは、大規模モデルの「無意味」を回避するためのアプリオリ制約としてナレッジ グラフを使用することです。2 つ目は、大規模モデルの適時性の問題を解決することです。一方、ナレッジ グラフに基づいて、大規模なモデル生成に対して解釈可能なソリューションを提供できます。
ナレッジ強化型質疑応答システム
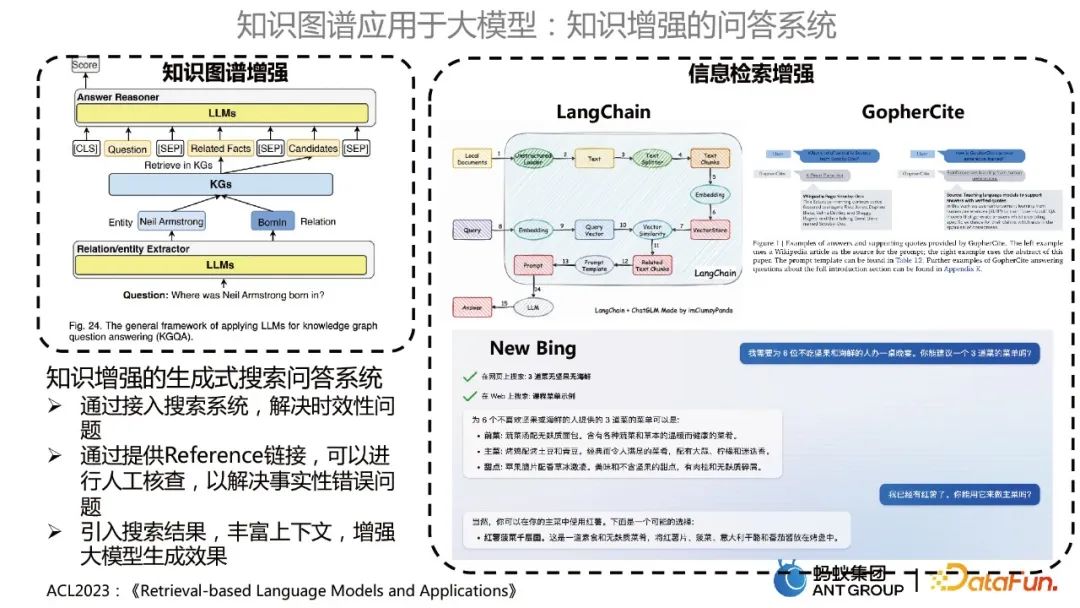
主に 2 つのカテゴリがあり、1 つは大規模なモデルを使用するナレッジ グラフ強化型質疑応答システムです。 KBQA モデルを最適化すること、もう 1 つは、LangChain、GopherCite、New Bing などが大規模なモデルを使用してナレッジ ベースの質問と回答を行う方法と同様の、情報検索の強化です。
知識強化型生成検索 Q&A システムには、次の利点があります。
- 検索システムにアクセスすると、適時性の問題を解決します。
- # 参照リンクを提供すると、手動検証を実行して事実上の誤りを解決できます。
- #検索結果を導入し、コンテキストを充実させ、大規模なモデル生成の効果を高めます。

ナレッジ グラフと大規模モデルをより適切に操作および共同作業する方法進歩には次の 3 つの方向性が含まれます。
- NLP、質問応答システム、その他の分野におけるナレッジ グラフと大規模モデルの徹底的な適用を促進します。
- ナレッジ グラフを使用して、大規模モデルの幻覚検出と無毒化を行います。
- ナレッジ グラフと組み合わせた大規模ドメイン モデルの研究開発。
以上がJia Qianghuai: アリの大規模知識グラフの構築と応用の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7526
7526
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 Python での感情分析に BERT を使用する方法と手順
Jan 22, 2024 pm 04:24 PM
Python での感情分析に BERT を使用する方法と手順
Jan 22, 2024 pm 04:24 PM
BERT は、2018 年に Google によって提案された事前トレーニング済みの深層学習言語モデルです。正式名は BidirectionEncoderRepresentationsfromTransformers で、Transformer アーキテクチャに基づいており、双方向エンコードの特性を備えています。従来の一方向コーディング モデルと比較して、BERT はテキストを処理するときにコンテキスト情報を同時に考慮できるため、自然言語処理タスクで優れたパフォーマンスを発揮します。その双方向性により、BERT は文内の意味関係をより深く理解できるようになり、それによってモデルの表現能力が向上します。事前トレーニングおよび微調整方法を通じて、BERT は感情分析、命名などのさまざまな自然言語処理タスクに使用できます。
 一般的に使用される AI 活性化関数の分析: Sigmoid、Tanh、ReLU、Softmax のディープラーニングの実践
Dec 28, 2023 pm 11:35 PM
一般的に使用される AI 活性化関数の分析: Sigmoid、Tanh、ReLU、Softmax のディープラーニングの実践
Dec 28, 2023 pm 11:35 PM
活性化関数は深層学習において重要な役割を果たしており、ニューラル ネットワークに非線形特性を導入することで、ネットワークが複雑な入出力関係をより適切に学習し、シミュレートできるようになります。活性化関数の正しい選択と使用は、ニューラル ネットワークのパフォーマンスとトレーニング結果に重要な影響を与えます。この記事では、よく使用される 4 つの活性化関数 (Sigmoid、Tanh、ReLU、Softmax) について、導入、使用シナリオ、利点、欠点と最適化ソリューション アクティベーション関数を包括的に理解できるように、次元について説明します。 1. シグモイド関数 シグモイド関数の公式の概要: シグモイド関数は、任意の実数を 0 と 1 の間にマッピングできる一般的に使用される非線形関数です。通常は統一するために使用されます。
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 潜在空間の埋め込み: 説明とデモンストレーション
Jan 22, 2024 pm 05:30 PM
潜在空間の埋め込み: 説明とデモンストレーション
Jan 22, 2024 pm 05:30 PM
潜在空間埋め込み (LatentSpaceEmbedding) は、高次元データを低次元空間にマッピングするプロセスです。機械学習と深層学習の分野では、潜在空間埋め込みは通常、高次元の入力データを低次元のベクトル表現のセットにマッピングするニューラル ネットワーク モデルです。このベクトルのセットは、「潜在ベクトル」または「潜在ベクトル」と呼ばれることがよくあります。エンコーディング」。潜在空間埋め込みの目的は、データ内の重要な特徴をキャプチャし、それらをより簡潔でわかりやすい形式で表現することです。潜在空間埋め込みを通じて、低次元空間でデータの視覚化、分類、クラスタリングなどの操作を実行し、データをよりよく理解して活用できます。潜在空間埋め込みは、画像生成、特徴抽出、次元削減など、多くの分野で幅広い用途があります。潜在空間埋め込みがメイン
 1 つの記事で理解: AI、機械学習、ディープラーニングのつながりと違い
Mar 02, 2024 am 11:19 AM
1 つの記事で理解: AI、機械学習、ディープラーニングのつながりと違い
Mar 02, 2024 am 11:19 AM
今日の急速な技術変化の波の中で、人工知能 (AI)、機械学習 (ML)、および深層学習 (DL) は輝かしい星のようなもので、情報技術の新しい波をリードしています。これら 3 つの単語は、さまざまな最先端の議論や実践で頻繁に登場しますが、この分野に慣れていない多くの探検家にとって、その具体的な意味や内部のつながりはまだ謎に包まれているかもしれません。そこで、まずはこの写真を見てみましょう。ディープラーニング、機械学習、人工知能の間には密接な相関関係があり、進歩的な関係があることがわかります。ディープラーニングは機械学習の特定の分野であり、機械学習
 産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
1. 背景の紹介 まず、Yunwen Technology の開発の歴史を紹介します。 Yunwen Technology Company ...2023 年は大規模モデルが普及する時期であり、多くの企業は大規模モデルの後、グラフの重要性が大幅に低下し、以前に検討されたプリセット情報システムはもはや重要ではないと考えています。しかし、RAG の推進とデータ ガバナンスの普及により、より効率的なデータ ガバナンスと高品質のデータが民営化された大規模モデルの有効性を向上させるための重要な前提条件であることがわかり、ますます多くの企業が注目し始めています。知識構築関連コンテンツへ。これにより、知識の構築と処理がより高いレベルに促進され、探索できる技術や方法が数多く存在します。新しいテクノロジーの出現によってすべての古いテクノロジーが打ち破られるわけではなく、新旧のテクノロジーが統合される可能性があることがわかります。
 超強い!深層学習アルゴリズムのトップ 10!
Mar 15, 2024 pm 03:46 PM
超強い!深層学習アルゴリズムのトップ 10!
Mar 15, 2024 pm 03:46 PM
2006 年にディープ ラーニングの概念が提案されてから、ほぼ 20 年が経過しました。ディープ ラーニングは、人工知能分野における革命として、多くの影響力のあるアルゴリズムを生み出してきました。では、ディープラーニングのトップ 10 アルゴリズムは何だと思いますか?私の考えでは、ディープ ラーニングのトップ アルゴリズムは次のとおりで、いずれもイノベーション、アプリケーションの価値、影響力の点で重要な位置を占めています。 1. ディープ ニューラル ネットワーク (DNN) の背景: ディープ ニューラル ネットワーク (DNN) は、多層パーセプトロンとも呼ばれ、最も一般的なディープ ラーニング アルゴリズムです。最初に発明されたときは、コンピューティング能力のボトルネックのため疑問視されていました。最近まで長年にわたる計算能力、データの爆発的な増加によって画期的な進歩がもたらされました。 DNN は、複数の隠れ層を含むニューラル ネットワーク モデルです。このモデルでは、各層が入力を次の層に渡し、
 Elasticsearch ベクトル検索の開発の歴史を基礎から実践まで振り返ります。
Oct 23, 2023 pm 05:17 PM
Elasticsearch ベクトル検索の開発の歴史を基礎から実践まで振り返ります。
Oct 23, 2023 pm 05:17 PM
1. はじめに ベクトル検索は、最新の検索および推奨システムの中核コンポーネントとなっています。テキスト、画像、音声などの複雑なオブジェクトを数値ベクトルに変換し、多次元空間で類似性検索を実行することにより、効率的なクエリ マッチングとレコメンデーションが可能になります。基本から実践まで、Elasticsearch の開発の歴史を確認します。この記事では、各段階の特徴と進歩に焦点を当てて、Elasticsearch ベクトル検索の開発の歴史を振り返ります。歴史をガイドとして考慮すると、Elasticsearch ベクトル検索の全範囲を確立するのは誰にとっても便利です。
