

H100推理が8倍に急上昇! NVIDIA が 10 以上のモデルをサポートするオープンソース TensorRT-LLM を正式発表

「GPU 貧乏人」は、その苦境に別れを告げようとしています。
たった今、NVIDIA は、H100
## で実行される大規模な言語モデルの推論プロセスを高速化できる TensorRT-LLM と呼ばれるオープン ソース ソフトウェアをリリースしました。 
#それでは、何回改善できるでしょうか?
TensorRT-LLM とその一連の最適化機能 (In-Flight バッチ処理を含む) を追加した後、モデルの合計スループットは 8 倍に増加しました。
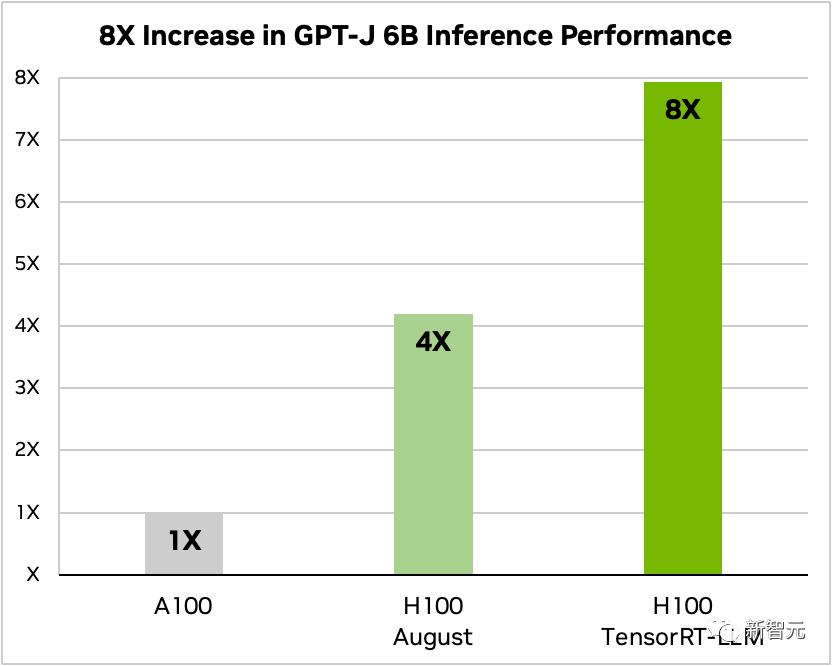
#Compare Llama 2 70B 、比較TensorRT-LLM を使用した場合と使用しない場合の A100 と H100 の比較
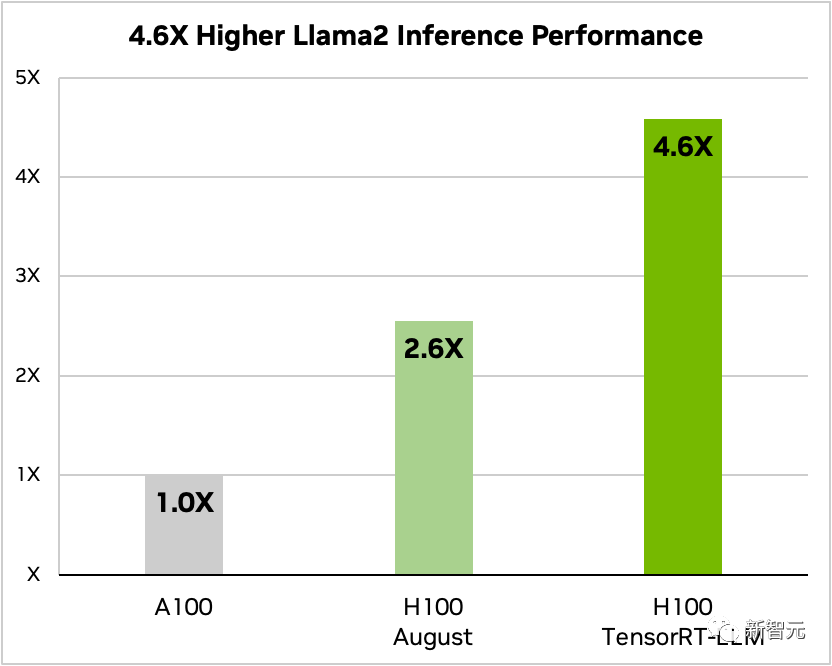
TensorRT-LLM: 大規模モデル推論高速化アーティファクト
現在、大規模モデルのパラメータ規模が膨大なため、「デプロイメント」が困難になっています。 「推理」の難易度とコストは依然として高い。 
#NVIDIA が開発した TensorRT-LLM は、LLM のスループットを大幅に向上させ、GPU を通じてコストを削減することを目的としています。
## 具体的には、TensorRT-LLM は、TensorRT の深層学習コンパイラ、FasterTransformer の最適化されたカーネル、前処理および後処理、およびマルチ GPU/マルチノード通信をシンプルなオープンソース Python API ## にカプセル化します。 ##NVIDIA は、FasterTransformer をさらに強化して製品化したソリューションにしました。

C や CUDA の深い知識を必要としないプログラマーは、さまざまな大規模な言語モデルをデプロイ、実行、デバッグでき、優れたパフォーマンスと迅速なカスタマイズを実現できます。
##NVIDIA の公式ブログによると、TensorRT-LLM は 4 つの方法を使用して Nvidia GPU での LLM 推論パフォーマンスを向上させます
まず、現在の上位 10 モデルには TensorRT-LLM が導入されており、開発者はすぐに実行できるようになります。
第 2 に、TensorRT-LLM は、オープン ソース ソフトウェア ライブラリとして、LLM が複数の GPU および複数の GPU サーバーで同時に推論を実行できるようにします。 
これらのサーバーは、それぞれ NVIDIA の NVLink および InfiniBand 相互接続を介して接続されています。
3 番目のポイントは、「マシン内バッチ処理」についてです。これは、異なるモデルのタスクが他のタスクから独立して GPU に出入りできるようにする新しいスケジューリング技術です。
最後に、TensorRT-LLM は、H100 Transformer Engine を使用してモデル推論中のメモリ使用量とレイテンシを削減するように最適化されました。
TensorRT-LLM がモデルのパフォーマンスをどのように向上させるかを詳しく見てみましょう
豊富な LLM エコシステムをサポート
TensorRT -LLMオープンソース モデル エコシステムに優れたサポートを提供します書き直す必要があるのは次のとおりです: Meta によって発売された Llama 2-70B などの最大かつ最先端の言語モデルには、複数の GPU の動作が必要ですリアルタイムで応答を提供するために連携します
以前は、LLM 推論の最高のパフォーマンスを達成するには、開発者が AI モデルを手動で書き直して複数の部分に分割し、実行を調整する必要がありました。 GPU 間
#

#TensorRT-LLM は、テンソル並列テクノロジーを使用して重み行列を各デバイスに配布することで、プロセスを簡素化し、大規模な効率的な推論を可能にします
各モデルは、開発者の介入やモデルの変更を行わずに、NVLink 経由で接続された複数の GPU および複数のサーバー上で並行して実行できます。
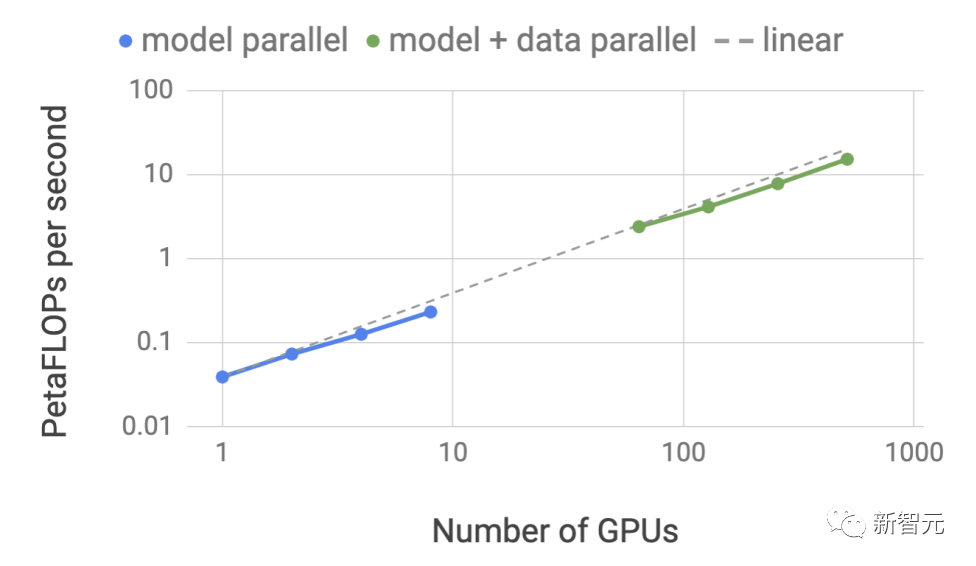
新しいモデルとモデル アーキテクチャの導入により、開発者は TensorRT-LLM モデルでオープンソース化された最新の NVIDIA AI カーネル (カーナル) を使用して最適化できます。
書き直す必要がある内容は次のとおりです: サポートされているカーネル フュージョン (Kernal Fusion) には、最新の FlashAttendant 実装と、GPT モデルのコンテキストおよび生成ステージ用のマスクされたマルチヘッド アテンションが含まれています。実行 Li ら
#さらに、TensorRT-LLM には、現在人気のある多くの大規模な言語モデルの、完全に最適化され、すぐに実行できるバージョンも含まれています。これらのモデルには、Meta Llama 2、OpenAI GPT-2 および GPT-3、Falcon、Mosaic MPT、BLOOM など 10 種類以上が含まれます。これらのモデルはすべて、使いやすい TensorRT-LLM Python API を使用して呼び出すことができます。
これらの機能は、開発者がカスタマイズされた大規模な言語モデルをより迅速かつ正確に構築し、さまざまなニーズを満たすのに役立ちます。あらゆる分野で。
実行中のバッチ処理
現在、大規模な言語モデルが幅広いアプリケーションで使用されています。単一のモデルは、チャットボットでの単純な Q&A 応答から文書の要約や長いコード ブロックの生成まで、一見異質に見える複数のタスクに同時に使用でき、ワークロードは非常に動的です。出力サイズは、さまざまな規模のタスクのニーズを満たす必要があります。
タスクの多様性により、リクエストを効率的にバッチ処理し、効率的な並列実行を実行することが困難になる可能性があり、一部のリクエストが他のリクエストよりも早く完了する可能性があります。

大規模言語モデルの中核原理は、テキスト生成プロセス全体がモデルの複数回の反復を通じて実現できるということです。
-flight バッチ処理 を使用すると、TensorRT-LLM ランタイムは、バッチ全体が完了するのを待ってから次のリクエスト セットに進むのではなく、完了したシーケンスをバッチから即座に解放します。
新しいリクエストを実行するとき、前のバッチの完了していない他のリクエストはまだ処理中です。
オンボード バッチ処理を実行し、追加のカーネル レベルの最適化を行うことにより、GPU 使用率が向上し、その結果、H100 上の LLM の実際のリクエスト ベンチマークのスループットが少なくとも 2 倍になります
FP 8 の H100 Transformer Engine の使用
TensorRT-LLM は、大規模なモデル推論中のメモリ消費とレイテンシを効果的に削減できる H100 Transformer Engine と呼ばれる機能も提供します。LLM には数十億のモデルの重みと活性化関数が含まれているため、通常、これらは FP16 または BF16 の値でトレーニングおよび表現され、それぞれが 16 ビットのメモリを占有します。
ただし、推論時には、8 ビットまたは 4 ビット整数 (INT8 または INT4) などの量子化手法を使用して、ほとんどのモデルを低精度で効果的に表現できます。
量子化は、精度を犠牲にすることなくモデルの重みとアクティベーション精度を減らすプロセスです。より低い精度を使用すると、各パラメーターが小さくなり、モデルが GPU メモリ内で占有するスペースが少なくなります。
 #同じハードウェアを使用して、実行中のメモリ操作の時間消費を削減しながら、より大きなモデルを推論できます
#同じハードウェアを使用して、実行中のメモリ操作の時間消費を削減しながら、より大きなモデルを推論できます
H100 Transformer Engine テクノロジーにより、TensorRT-LLM を備えた H100 GPU により、ユーザーはモデルの重みを新しい FP8 形式に簡単に変換し、モデルを自動的にコンパイルして最適化された FP8 カーネルを利用できるようになります。
そして、このプロセスにはコードは必要ありません。 H100 によって導入された FP8 データ形式により、開発者はモデルを定量化し、モデルの精度を低下させることなくメモリ消費量を大幅に削減できます。
INT8 や INT4 などの他のデータ形式と比較して、FP8 量子化はより高い精度を維持しながら最速のパフォーマンスを実現し、実装が最も便利です。 INT8 や INT4 などの他のデータ形式と比較して、FP8 量子化は最高のパフォーマンスを達成しながら高い精度を維持し、実装が最も便利です。
TensorRT-LLM の入手方法
TensorRT-LLM はまだ正式リリースされていませんが、事前に体験できるようになりました
##アプリケーションのリンクは次のとおりです:
# https://developer.nvidia.com/tensorrt-llm-early-access/joinNVIDIA は、TensorRT-LLM が間もなく NVIDIA NeMo フレームワークに統合されるとも述べました。
このフレームワークは、NVIDIA が最近立ち上げた AI Enterprise の一部であり、企業顧客に安全で安定しており、管理性の高いエンタープライズ レベルの AI ソフトウェア プラットフォームを提供します
開発者と研究者は、NVIDIA NGC の NeMo フレームワークまたは GitHub のプロジェクトを通じて TensorRT-LLM にアクセスできます。
# ただし、ユーザーは次のことを行う必要があることに注意してください。 NVIDIA 開発者プログラムに登録して、早期アクセス バージョンを申請してください。
ネチズンの熱い議論
Reddit 上のユーザーは、TensorRT-LLM のリリースについて白熱した議論を交わしました
最適化後は想像を絶するほどLLM 専用のハードウェアを使用すると、効果が大幅に向上します。
 しかし、一部のネチズンは、このことの目的はLao HuangがH100をより多く売るのを助けることであると信じています。
しかし、一部のネチズンは、このことの目的はLao HuangがH100をより多く売るのを助けることであると信じています。
 一部のネチズンはこれについてさまざまな意見を持っており、Tensor RT はディープ ラーニングをローカルにデプロイするユーザーにも役立つと考えています。 RTX GPU を持っている限り、将来同様の製品から恩恵を受ける可能性があります
一部のネチズンはこれについてさまざまな意見を持っており、Tensor RT はディープ ラーニングをローカルにデプロイするユーザーにも役立つと考えています。 RTX GPU を持っている限り、将来同様の製品から恩恵を受ける可能性があります
 よりマクロな観点から見ると、おそらく LLM の場合、特にハードウェア レベルを対象とした一連の最適化措置が存在し、パフォーマンスを向上させるために LLM 用に特別に設計されたハードウェアも存在する可能性があります。この状況は多くの一般的なアプリケーションで発生しており、LLM も例外ではありません
よりマクロな観点から見ると、おそらく LLM の場合、特にハードウェア レベルを対象とした一連の最適化措置が存在し、パフォーマンスを向上させるために LLM 用に特別に設計されたハードウェアも存在する可能性があります。この状況は多くの一般的なアプリケーションで発生しており、LLM も例外ではありません
 #
#
以上がH100推理が8倍に急上昇! NVIDIA が 10 以上のモデルをサポートするオープンソース TensorRT-LLM を正式発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
28
96
15
1382
52
83
11
28
96

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
オープンな LLM コミュニティは百花繚乱の時代です Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1 などがご覧いただけます。優秀なパフォーマーモデル。しかし、GPT-4-Turboに代表される独自の大型モデルと比較すると、オープンモデルには依然として多くの分野で大きなギャップがあります。一般的なモデルに加えて、プログラミングと数学用の DeepSeek-Coder-V2 や視覚言語タスク用の InternVL など、主要な領域に特化したいくつかのオープン モデルが開発されています。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 「AI Factory」はソフトウェア スタック全体の再構築を促進し、NVIDIA はユーザーが展開できる Llama3 NIM コンテナを提供します
Jun 08, 2024 pm 07:25 PM
「AI Factory」はソフトウェア スタック全体の再構築を促進し、NVIDIA はユーザーが展開できる Llama3 NIM コンテナを提供します
Jun 08, 2024 pm 07:25 PM
6月2日の当サイトのニュースによると、現在開催中のHuang Renxun 2024 Taipei Computexの基調講演で、Huang Renxun氏は、生成人工知能がソフトウェアスタック全体の再構築を促進すると紹介し、NIM(Nvidia Inference Microservices)のクラウドネイティブマイクロサービスをデモしました。 。 Nvidia は、「AI ファクトリー」が新たな産業革命を引き起こすと信じています。Microsoft が開拓したソフトウェア業界を例に挙げると、Huang Renxun 氏は、生成人工知能がそのフルスタックの再構築を促進すると信じています。あらゆる規模の企業による AI サービスの導入を促進するために、NVIDIA は今年 3 月に NIM (Nvidia Inference Microservices) クラウドネイティブ マイクロサービスを開始しました。 NIM+ は、市場投入までの時間を短縮するために最適化されたクラウドネイティブのマイクロサービスのスイートです
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
 総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
大規模言語モデル (LLM) を人間の価値観や意図に合わせるには、人間のフィードバックを学習して、それが有用で、正直で、無害であることを確認することが重要です。 LLM を調整するという点では、ヒューマン フィードバックに基づく強化学習 (RLHF) が効果的な方法です。 RLHF 法の結果は優れていますが、最適化にはいくつかの課題があります。これには、報酬モデルをトレーニングし、その報酬を最大化するためにポリシー モデルを最適化することが含まれます。最近、一部の研究者はより単純なオフライン アルゴリズムを研究しており、その 1 つが直接優先最適化 (DPO) です。 DPO は、RLHF の報酬関数をパラメータ化することで、選好データに基づいてポリシー モデルを直接学習するため、明示的な報酬モデルの必要性がなくなります。この方法は簡単で安定しています
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
