

Interspeech 2023 | Volcano Engine ストリーミング オーディオ テクノロジー音声強化と AI オーディオ コーディング


背景紹介
マルチデバイス、複数人、複数ノイズのシナリオなど、さまざまな複雑な音声およびビデオ通信シナリオに対処するために、ストリーミングメディアコミュニケーション技術は徐々に人々の生活の一部となり、なくてはならない技術となっています。より良い主観的体験を実現し、ユーザーが明瞭かつ真に聞こえるようにするために、ストリーミング オーディオ テクノロジー ソリューションは、従来の機械学習と AI ベースの音声強化ソリューションを組み合わせ、ディープ ニューラル ネットワーク テクノロジー ソリューションを使用して音声ノイズの低減とエコー キャンセルを実現します。リアルタイム通信における音声品質を保護するために、干渉音声の除去やオーディオのエンコードとデコードなどを行います。
Interspeech は、音声信号処理研究分野の主力国際会議として、音響分野における最先端の研究の方向性を常に代表してきました。Interspeech 2023 には、音声信号の音声強化に関する多数の記事が含まれています。 volcanoengine ストリーミング オーディオ チームからの音声強調、AI ベースのエンコードとデコード #、エコーなど、合計 4 件の研究論文がカンファレンスに採択されました。キャンセル、および教師なし適応音声強調。
教師なし適応音声強化の分野では、ByteDance と NPU の共同チームが今年の CHiME (マルチソース環境におけるコンピュータ聴覚) チャレンジで教師なしドメイン適応会話音声のサブタスクを成功裏に完了したことは言及する価値があります。強化 (会話音声強化のための教師なしドメイン適応、UDASE) が優勝しました (https://www.chimechallenge.org/current/task2/results)。 CHiME Challengeは、フランスのコンピュータ科学オートメーション研究所、英国のシェフィールド大学、米国の三菱電子研究所などの著名な研究機関によって2011年に開始された重要な国際コンテストです。音声研究分野における遠隔の問題に挑戦するこのイベントは、今年で7回目となります。これまでの CHiME コンテストの参加チームには、英国のケンブリッジ大学、米国のカーネギー メロン大学、ジョンズ ホプキンス大学、日本の NTT、日立研究院、その他の国際的に有名な大学や研究機関、清華大学、中国科学院大学、中国科学院音響研究所、NPU、iFlytekなどの国内トップクラスの大学や研究機関。 この記事では、これら 4 つの論文によって解決されたシナリオの中核問題と技術的解決策を紹介します。AI エンコーダ、エコー キャンセル、教師なし適応型音声強化に基づく音声強化における Volcano Engine ストリーミング オーディオ チームの進捗状況を共有します。現場で考え、実践する。
学習可能なくし型フィルタに基づく軽量音声高調波強調手法論文アドレス: https://www.isca-speech.org/archive/interspeech_2023/ le23_interspeech.html背景リアルタイム オーディオおよびビデオ通信シナリオにおける音声強調は、遅延とコンピューティング リソースによって制限されるため、通常、フィルター バンクに基づく入力機能を使用します。 Mel や ERB などのフィルター バンクを通じて、元のスペクトルは低次元のサブバンドに圧縮されます。サブバンド ドメインでは、深層学習ベースの音声強調モデルの出力は、ターゲット音声エネルギーの割合を表すサブバンドの音声ゲインです。ただし、圧縮されたサブバンド領域で強化されたオーディオは、スペクトルの詳細が失われるためぼやけており、多くの場合、高調波を強化するための後処理が必要です。 RNNoise と PercepNet は高調波を強化するためにコム フィルターを使用しますが、基本周波数推定とコム フィルターのゲイン計算とモデルのデカップリングのため、エンドツーエンドで最適化することはできません。DeepFilterNet は時間周波数ドメイン フィルターを使用して高調波間ノイズを抑制します。ただし、音声の基本周波数情報を明示的に利用するわけではありません。上記の問題に対処するために、研究チームは、基本周波数推定とコムフィルタリングを組み合わせ、エンドツーエンドでコムフィルタのゲインを最適化できる学習可能なコムフィルタに基づく音声高調波強調手法を提案しました。実験により、この方法は既存の方法と同様の計算量でより優れた高調波強調を実現できることが示されています。 モデル フレームワーク構造基本周波数推定器 (F0 推定器)基本周波数推定の困難さを軽減し、リンク全体をエンドツーエンドで実行できるようにするためターゲットの基本周波数範囲は N 個の離散基本周波数に離散化され、分類器を使用して推定されます。非有声フレームを表すために 1 次元が追加され、最終的なモデル出力は N 個の 1 次元確率になります。 CREPE と一致して、チームはトレーニング ターゲットとしてガウス平滑特徴を使用し、損失関数としてバイナリ クロス エントロピーを使用します。コム フィルター上記の個別の基本周波数ごとに、チームは PercepNet に似た FIR フィルターをコム フィルターに使用し、変調されたパルス列として表現できます。
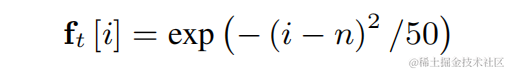
2 次元畳み込み層 (Conv2D) を使用して、トレーニング中にすべての離散基本周波数のフィルタリング結果を同時に計算します。2 次元畳み込みの重みは、下図の行列として表現できます。行列には N があります。 1 次元であり、各次元は上記のフィルターを使用して初期化されます。
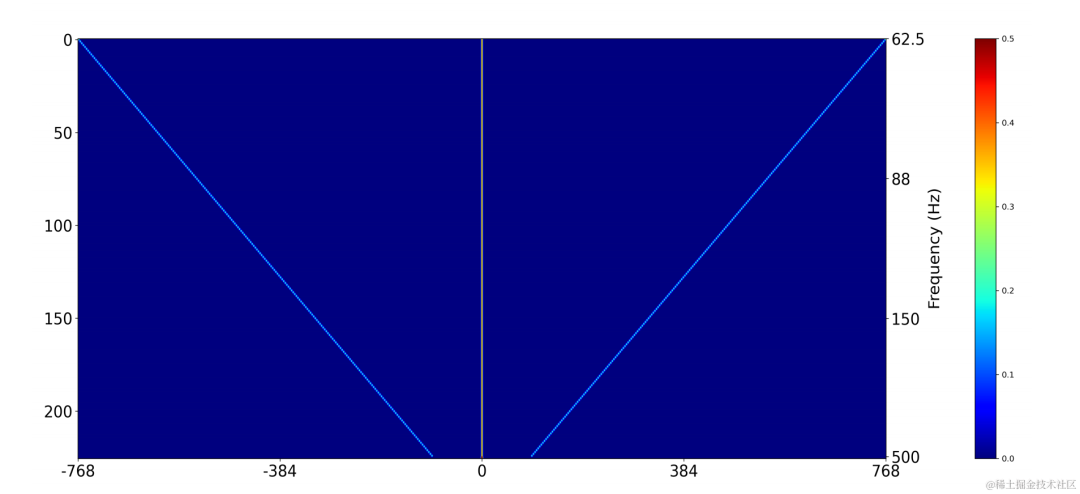
各フレームの基本周波数に対応するフィルター結果は、ターゲット基本周波数と 2 次元畳み込みの出力:

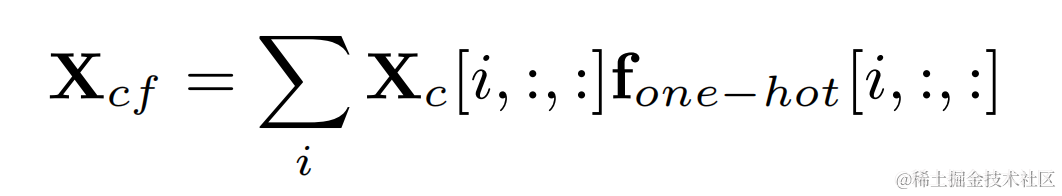
高調波強化オーディオは重み付けされて元のオーディオに追加され、サブ周波数で乗算されます。最終出力を取得するためのバンド ゲイン:
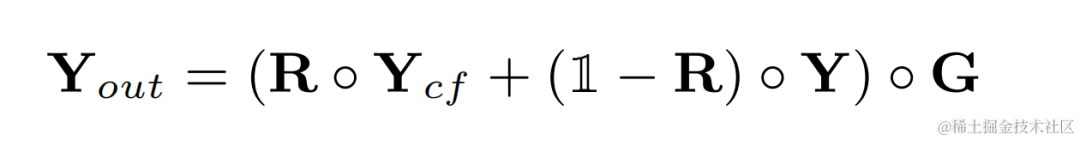
推論中、各フレームは 1 つの基本周波数のフィルター結果を計算するだけでよいため、この方法の計算コストは低くなります。 。
モデル構造
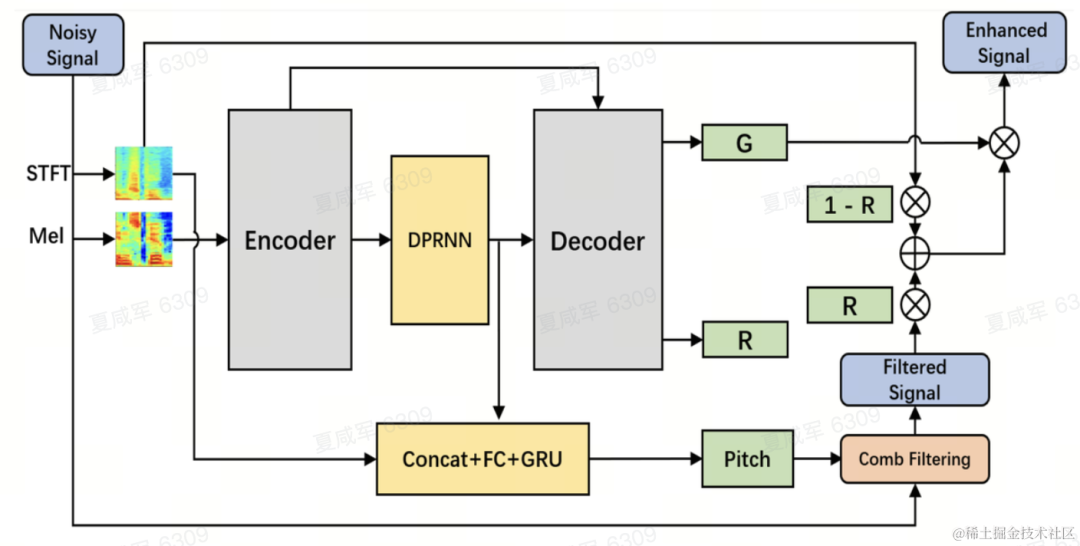
チームは、音声強調モデルのバックボーンとしてデュアルパス畳み込み再帰ネットワーク (DPCRN) を使用し、基本周波数推定器を追加しました。エンコーダとデコーダは深さ分離可能な畳み込みを使用して対称構造を形成し、デコーダにはサブバンド ゲイン G と重み付け係数 R をそれぞれ出力する 2 つの並列ブランチがあります。基本周波数推定器への入力は、DPRNN モジュールの出力と線形スペクトルです。このモデルの計算量は約300M MACであり、そのうちコムフィルタ計算量は約0.53M MACである。
モデル トレーニング
実験では、VCTK-DEMAND および DNS4 チャレンジ データセットがトレーニングに使用され、音声強調の損失関数と基本周波数推定がマルチタスク学習に使用されました。
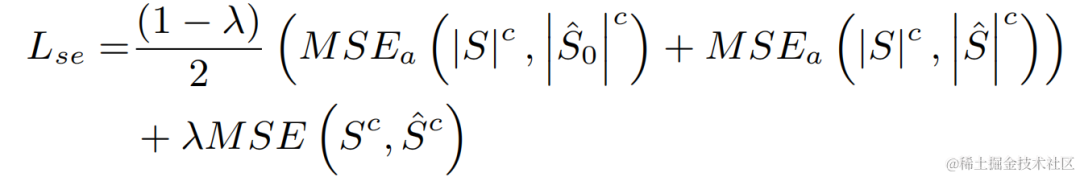
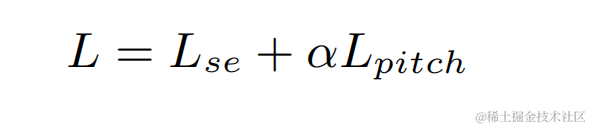
実験結果
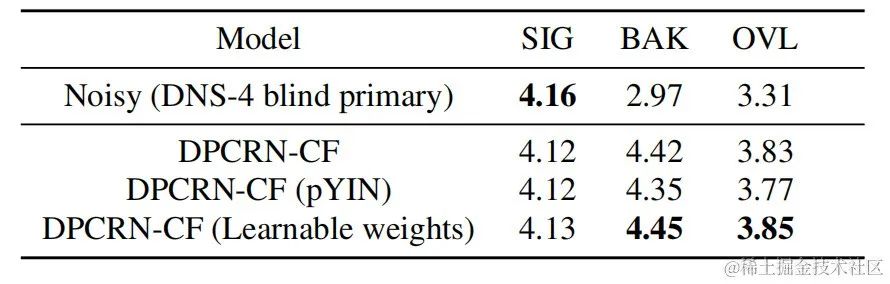
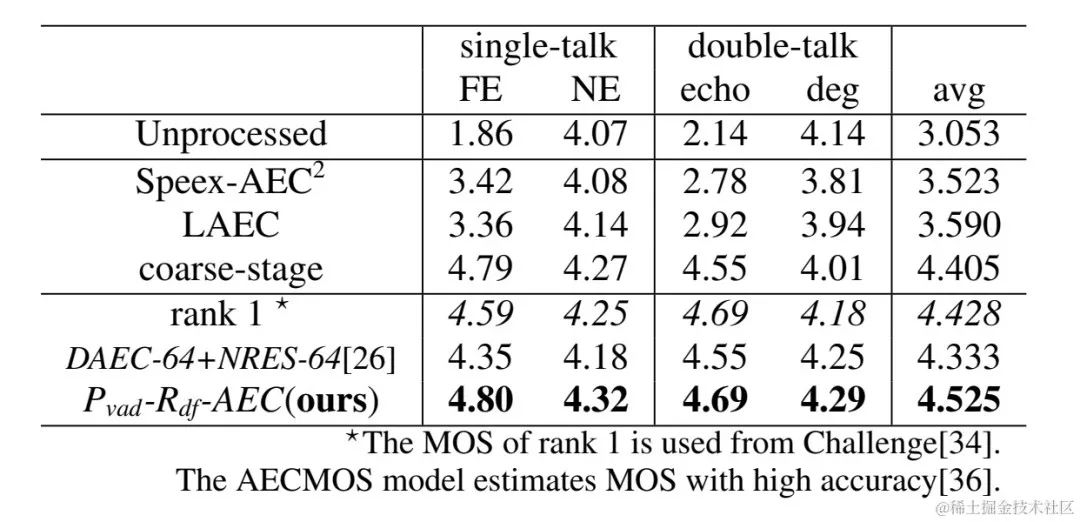
ストリーミング オーディオ チームは、提案された学習可能なコム フィルタリング モデルと、PercepNet および DeepFilterNet を使用したコム フィルタリングを組み合わせました。フィルタリング アルゴリズム モデルは次のとおりです。これらはそれぞれ DPCRN-CF、DPCRN-PN、DPCRN-DF と呼ばれます。 VCTK テスト セットでは、この記事で提案された方法は既存の方法よりも優れていることがわかります。
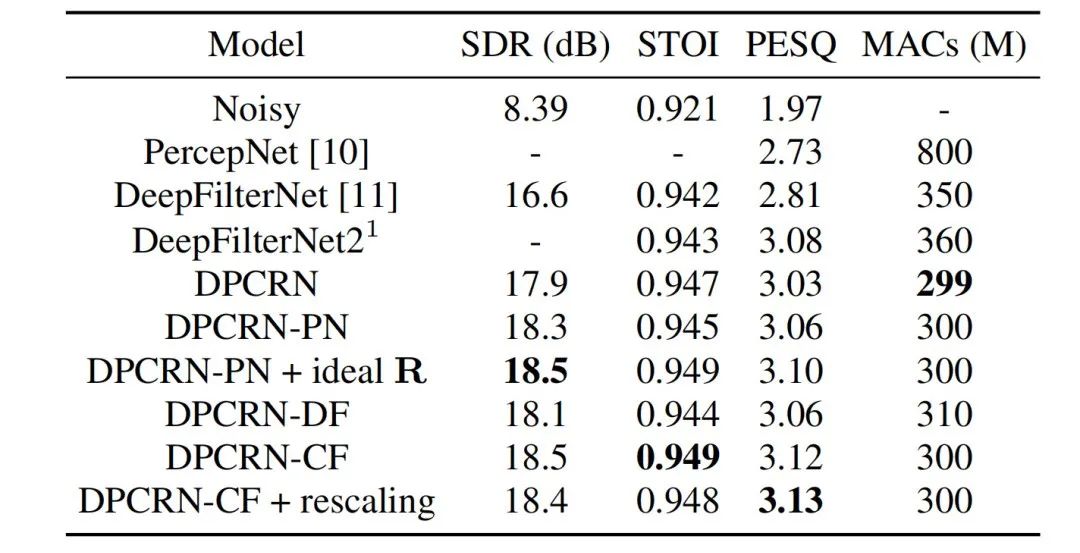
同時に、チームは基本周波数推定と学習可能なフィルターに関するアブレーション実験を実施しました。実験結果は、信号処理ベースの基本周波数推定アルゴリズムとフィルター重みを使用するよりも、エンドツーエンド学習の方が良い結果を生み出すことを示しています。
Intra-BRNN および GB-RVQ に基づくエンドツーエンドのニューラル ネットワーク オーディオ エンコーダ
論文アドレス: https://www.isca- speech .org/archive/pdfs/interspeech_2023/xu23_interspeech.pdf
背景
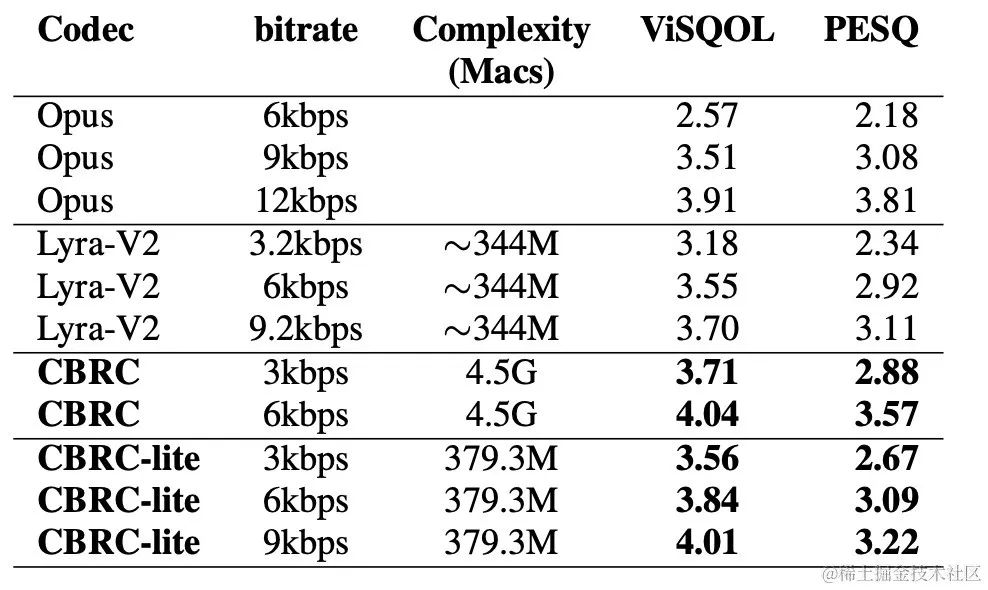
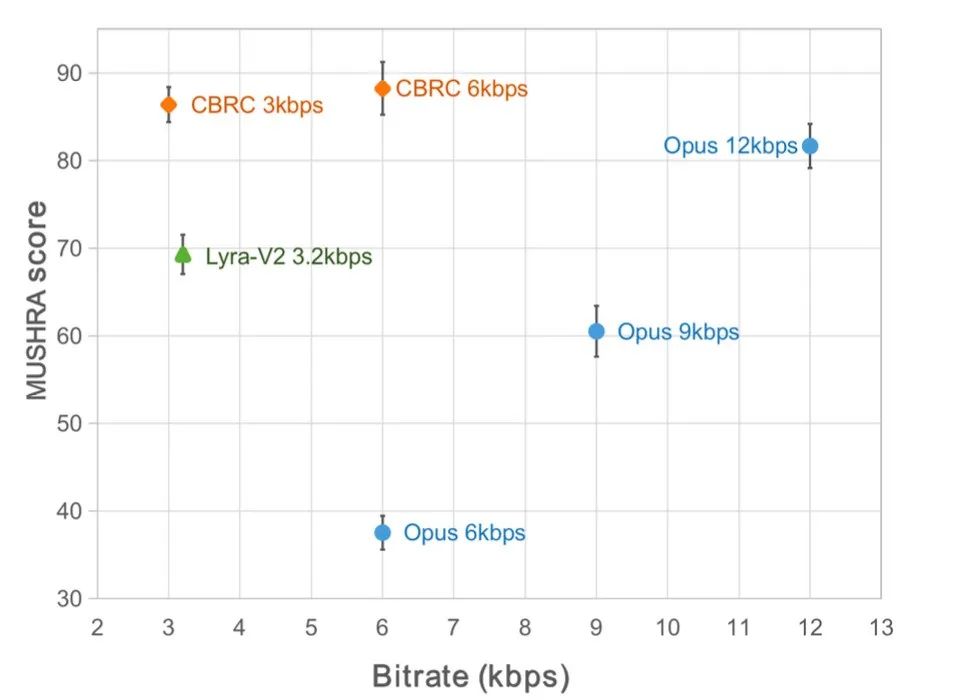
近年、低ビットレートの音声コーディング タスクに多くのニューラル ネットワーク モデルが使用されていますが、一部のニューラル ネットワーク モデルはエンドツー-end モデルは失敗しました。フレーム内関連情報を最大限に活用し、導入された量子化器は量子化誤差が大きく、エンコード後の音質が低下します。エンドツーエンドのニューラル ネットワーク オーディオ エンコーダーの品質を向上させるために、ストリーミング オーディオ チームはエンドツーエンドのニューラル音声コーデック、つまり CBRC (Convolutional and Bidirectional Recurrent neural Codec) を提案しました。 CBRC は、1D-CNN (1 次元畳み込み) と Intra-BRNN (フレーム内双方向リカレント ニューラル ネットワーク) のインターリーブ構造を使用して、フレーム内相関をより効果的に利用します。さらに、チームは CBRC のグループごとのビーム探索残差ベクトル量子化器 (GB-RVQ) を使用して、量子化ノイズを削減します。 CBRC は、システム遅延を追加することなく、20 ミリ秒のフレーム長で 16 kHz オーディオをエンコードし、リアルタイム通信シナリオに適しています。実験結果は、ビットレート 3kbps の CBRC エンコーディングの音声品質が、12kbps の Opus の音声品質よりも優れていることを示しています。
モデルフレームワーク構造
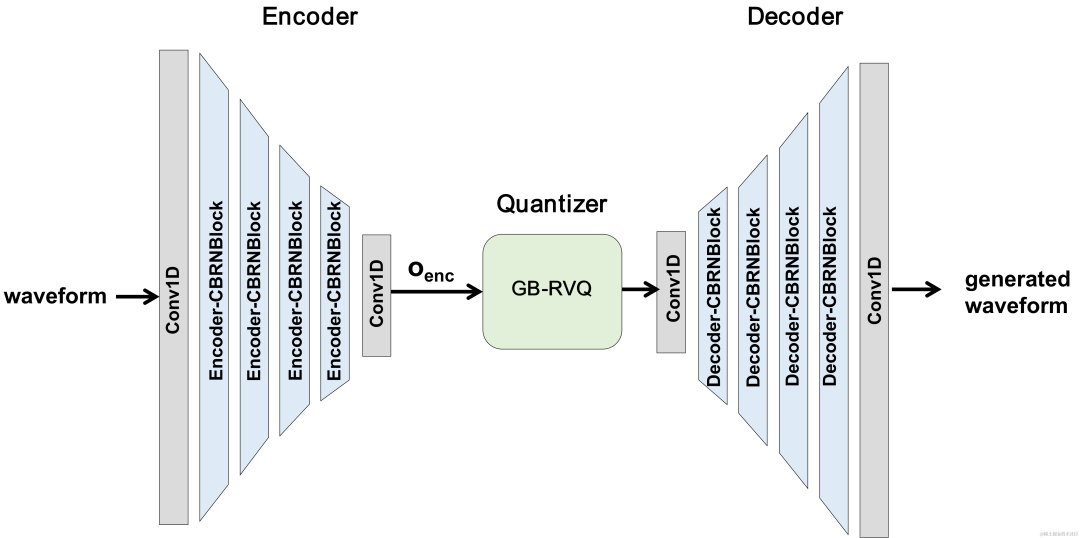
CBRC 全体構造
エンコーダとデコーダのネットワーク構造
エンコーダは、オーディオ特徴を抽出するために 4 つのカスケード CBRNBlock を使用します。各 CBRNBlock は、特徴を抽出するための 3 つの ResidualUnits と、ダウンサンプリング レートを制御する 1 次元の畳み込みで構成されます。エンコーダー内の特徴がダウンサンプリングされるたびに、特徴チャンネルの数は 2 倍になります。 ResidualUnit は、残差畳み込みモジュールと残差双方向リカレント ネットワークで構成されます。このネットワークでは、畳み込み層は因果畳み込みを使用しますが、Intra-BRNN の双方向 GRU 構造は 20 ミリ秒のフレーム内オーディオ機能のみを処理します。 Decoder ネットワークは Encoder のミラー構造であり、アップサンプリングに 1 次元の転置畳み込みを使用します。 1D-CNN とイントラ BRNN のインターリーブ構造により、エンコーダとデコーダは追加の遅延を発生させることなく 20 ミリ秒のオーディオフレーム内相関を最大限に活用できます。
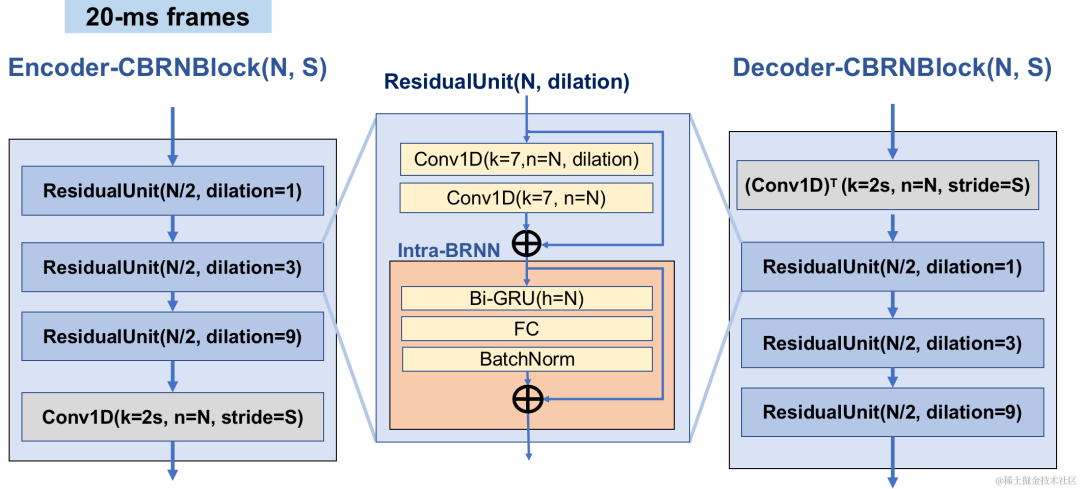
CBRNBlock 構造
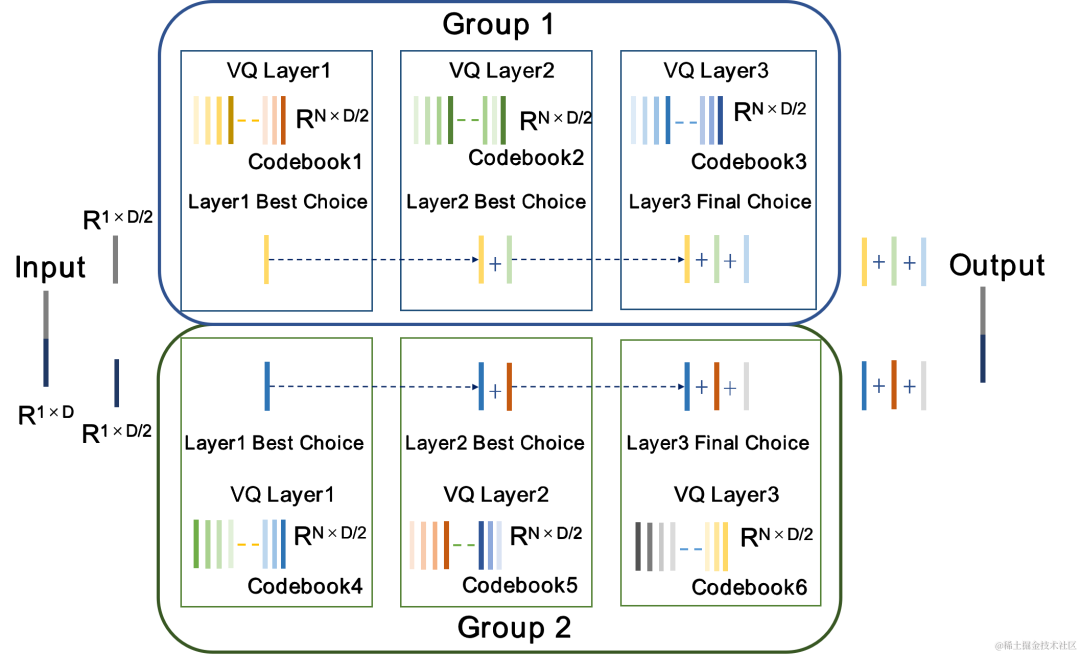
グループおよびビーム検索残差ベクトル量子化器 GB-RVQ
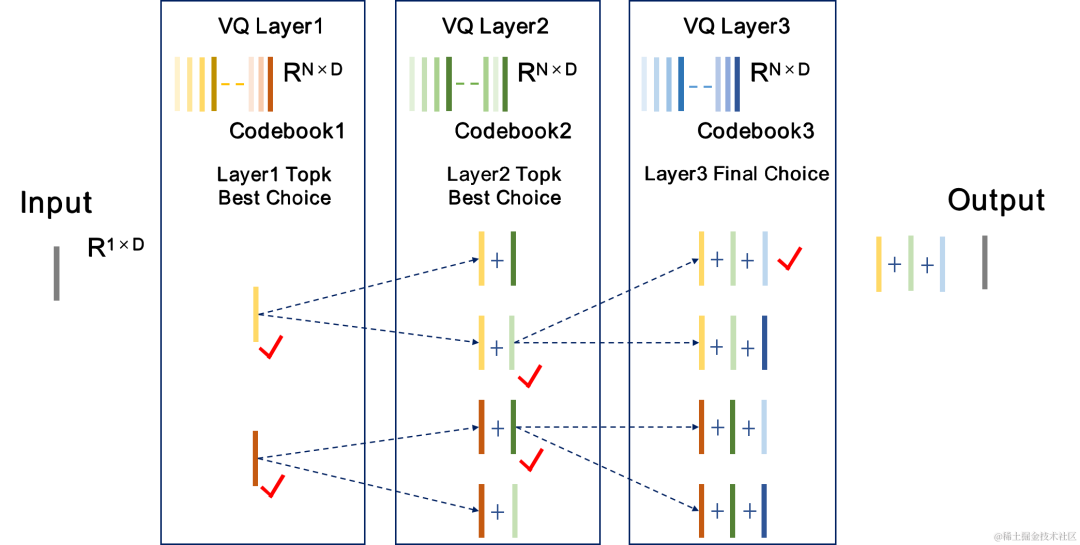
CBRC は残差を使用します。ベクトル量子化器 (RVQ) は、エンコード ネットワークの出力特徴を量子化して、指定されたビット レートに圧縮します。 RVQ は、多層ベクトル量子化器 (VQ) カスケードを使用して特徴を圧縮します。VQ の各層は、VQ の前の層の量子化残差を量子化するため、同じビットでの VQ の単一層のコードブック パラメータの量を大幅に削減できます。レート。研究チームは、CBRC における 2 つのより優れた量子化器構造、すなわちグループごとの RVQ とビーム探索残差ベクトル量子化器 (ビーム探索 RVQ) を提案しました。
| #グループ残差ベクトル量子化器グループごとの RVQ | ビームサーチ残差ベクトル量子化器ビームサーチ RVQ |
|
|
|
|
|
|
|

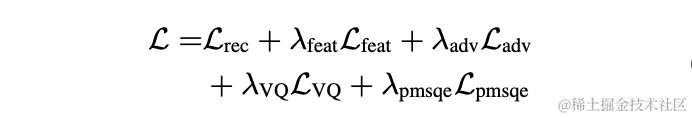
| ##客観的なスコア |
主観的なリスニング体験のスコア |
|
|


 具体例
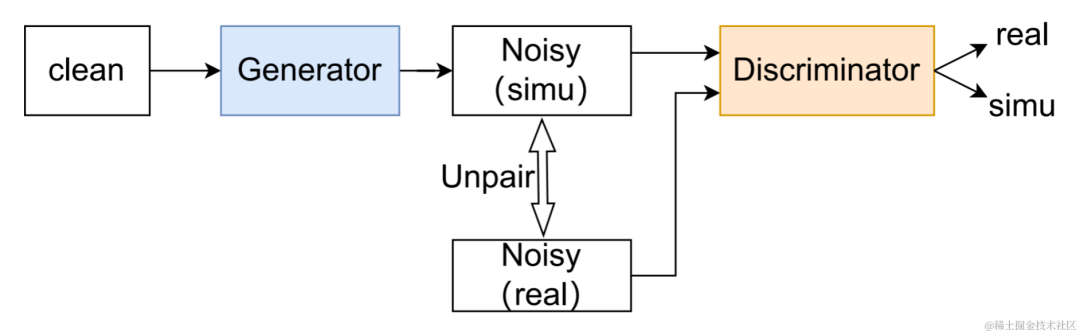
具体例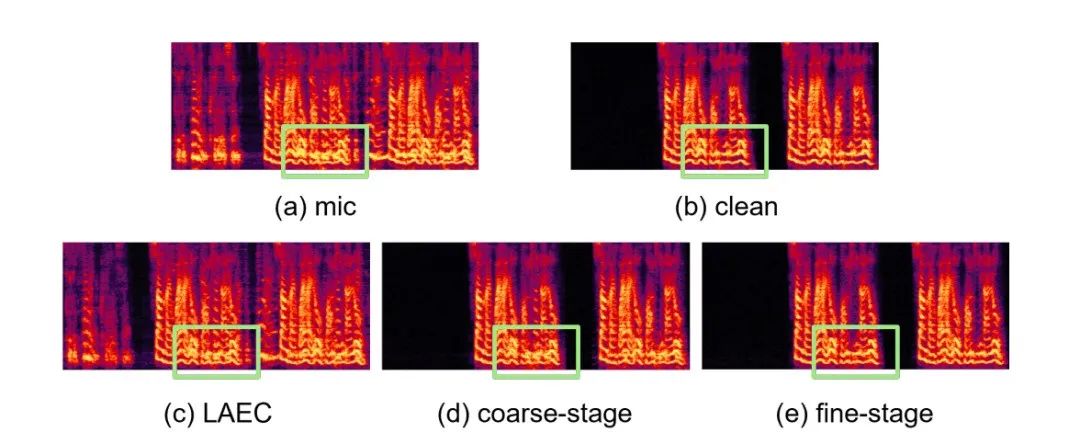 CHiME-7 Unsupervised Domain Adaptive Speech Enhancement (UDASE) Challenge Champion Solution
CHiME-7 Unsupervised Domain Adaptive Speech Enhancement (UDASE) Challenge Champion Solution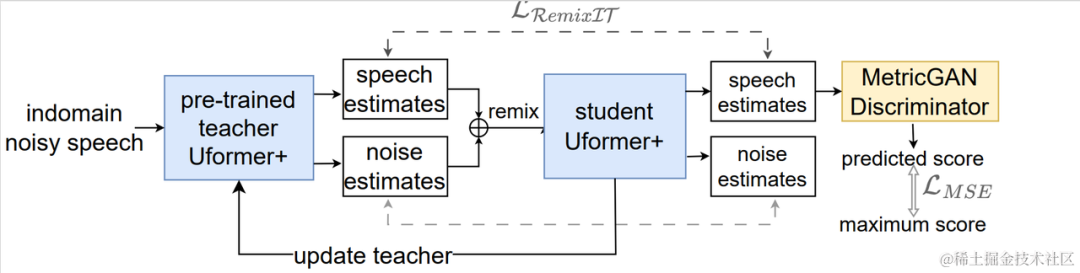 教師なしドメイン適応型音声強調システムのフローチャート
教師なしドメイン適応型音声強調システムのフローチャート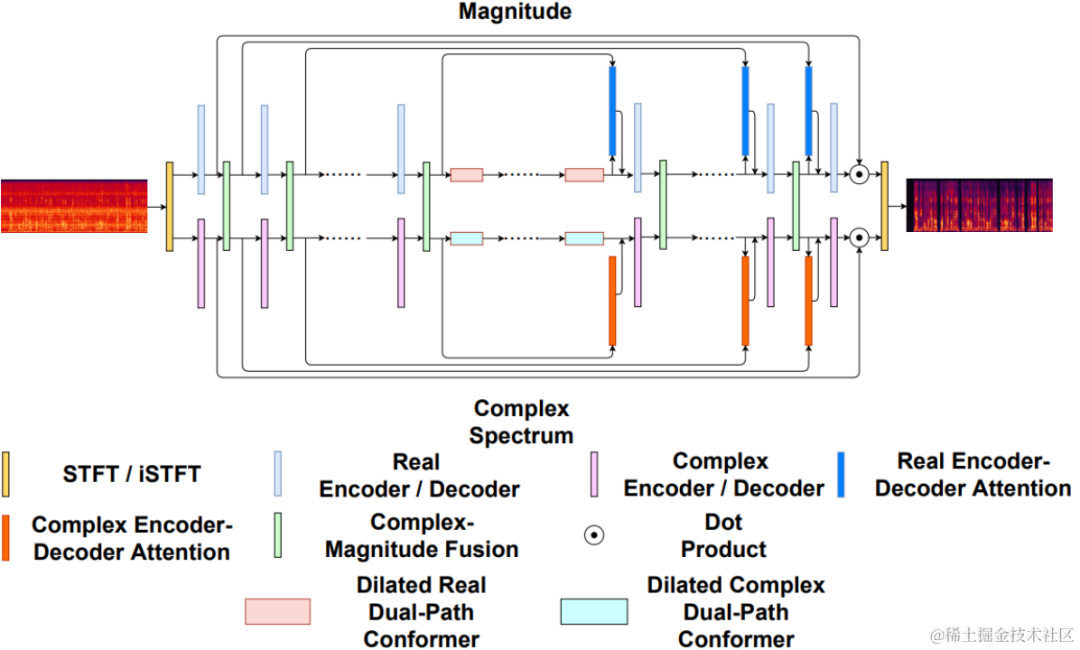
以上がInterspeech 2023 | Volcano Engine ストリーミング オーディオ テクノロジー音声強化と AI オーディオ コーディングの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7470
7470
 15
1377
52
77
11
19
29
15
1377
52
77
11
19
29

 カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
カーソルAIでバイブコーディングを試してみましたが、驚くべきことです!
Mar 20, 2025 pm 03:34 PM
バイブコーディングは、無限のコード行の代わりに自然言語を使用してアプリケーションを作成できるようにすることにより、ソフトウェア開発の世界を再構築しています。 Andrej Karpathyのような先見の明に触発されて、この革新的なアプローチは開発を許可します
 2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月のトップ5 Genai発売:GPT-4.5、Grok-3など!
Mar 22, 2025 am 10:58 AM
2025年2月は、生成AIにとってさらにゲームを変える月であり、最も期待されるモデルのアップグレードと画期的な新機能のいくつかをもたらしました。 Xai’s Grok 3とAnthropic's Claude 3.7 SonnetからOpenaiのGまで
 オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
オブジェクト検出にYolo V12を使用する方法は?
Mar 22, 2025 am 11:07 AM
Yolo(あなたは一度だけ見ています)は、前のバージョンで各反復が改善され、主要なリアルタイムオブジェクト検出フレームワークでした。最新バージョンYolo V12は、精度を大幅に向上させる進歩を紹介します
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google' s Gencast:Gencast Mini Demoを使用した天気予報
Mar 16, 2025 pm 01:46 PM
Google Deepmind's Gencast:天気予報のための革新的なAI 天気予報は、初歩的な観察から洗練されたAI駆動の予測に移行する劇的な変化を受けました。 Google DeepmindのGencast、グラウンドブレイク
 chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
chatgptよりも優れたAIはどれですか?
Mar 18, 2025 pm 06:05 PM
この記事では、Lamda、Llama、GrokのようなChatGptを超えるAIモデルについて説明し、正確性、理解、業界への影響における利点を強調しています(159文字)
 O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
O1対GPT-4O:OpenAIの新しいモデルはGPT-4Oよりも優れていますか?
Mar 16, 2025 am 11:47 AM
OpenaiのO1:12日間の贈り物は、これまでで最も強力なモデルから始まります 12月の到着は、世界の一部の地域で雪片が世界的に減速し、雪片がもたらされますが、Openaiは始まったばかりです。 サム・アルトマンと彼のチームは12日間のギフトを立ち上げています
 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
