

「人物とシーンのインタラクティブ生成」で新たな躍進!天達大学と清華大学がナレーターをリリース: テキスト駆動、自然に制御可能 | ICCV 2023

自然で制御可能なヒューマン シーン インタラクション (HSI) の生成は、仮想現実/拡張現実 (VR/AR) コンテンツ作成や人間中心の人工知能などの多くの分野で重要な役割を果たしています。
#しかし、既存の方法には制御性が限られ、インタラクションの種類が限られ、生成される結果が不自然であり、実際の適用シナリオが大幅に制限されています。 ICCV 2023 での研究では、天津大学と清華大学のチームが、この問題を調査するためにナレーターと呼ばれるソリューションを提案しました。このソリューションは、テキストの説明から現実的で多様な人間のシーンのインタラクションを自然かつ制御可能に生成するという困難なタスクに焦点を当てています Picture
Picture
#メソッド モチベーション
既存の人間とシーンのインタラクション生成方法は主にインタラクションの物理的な幾何学的関係に焦点を当てていますが、生成に対する意味論的な制御が欠如しており、単一人物の生成に限定されています。
したがって、著者らは、自然言語記述から現実的で多様な人間のシーンのインタラクションを制御可能に生成するという困難なタスクに焦点を当てます。著者らは、人間は通常、空間認識と行動認識を使用して、さまざまな場所でさまざまな相互作用に従事している人々を自然に描写していることを観察しました。
画像 書き換えられたコンテンツは次のとおりです。 図 1 によると、ナレーターは意味的に一貫した物理的なメッセージを自然かつ制御可能に生成できます。合理的な人間とシーンのインタラクションは、次の状況に適しています: (a) 空間関係に基づいたインタラクション、(b) 複数のアクションに基づいたインタラクション、(c) 複数人のシーンのインタラクション、および (d) 上記のインタラクション タイプの組み合わせ- シーン インタラクション
書き換えられたコンテンツは次のとおりです。 図 1 によると、ナレーターは意味的に一貫した物理的なメッセージを自然かつ制御可能に生成できます。合理的な人間とシーンのインタラクションは、次の状況に適しています: (a) 空間関係に基づいたインタラクション、(b) 複数のアクションに基づいたインタラクション、(c) 複数人のシーンのインタラクション、および (d) 上記のインタラクション タイプの組み合わせ- シーン インタラクション
具体的には、空間関係を使用して、シーンまたはローカル エリア内のさまざまなオブジェクト間の相互関係を説明できます。インタラクティブなアクションは、人間の両足が地面に着く、胴にもたれる、右手でタップする、頭を下げるなど、原子の各部分の状態によって指定されます。 ##これを出発点として、著者は空間関係を表すためにシーン グラフが使用され、後続の世代にグローバルな位置認識を提供するためにジョイント グローバルおよびローカル シーン グラフ (JGLSG) メカニズムが提案されています。
同時に、ボディパーツの状態がテキストと一致する現実的なインタラクションをシミュレートするための鍵であることを考慮して、著者はパーツレベルアクション (PLA) メカニズムを導入して、人体の各部位とそれらの間の動作の対応関係。
効果的な観察的認知と、提案された関係論的推論の柔軟性と再利用可能性の恩恵を受けて、著者はさらに、シンプルで効果的な複数人生成戦略を提案します。これは、当時初めて自然に制御可能なものでした。ユーザーフレンドリーなマルチヒューマンシーンインタラクション(MHSI)生成ソリューション。
メソッドのアイデア
ナレーター フレームワークの概要
ナレーターの目標は自然であることですテキストの説明と意味的に一貫性があり、3 次元シーンと物理的に一致するキャラクターとシーン間のインタラクションを生成する制御可能な方法
##Picture図 2 ナレーター フレームワークの概要
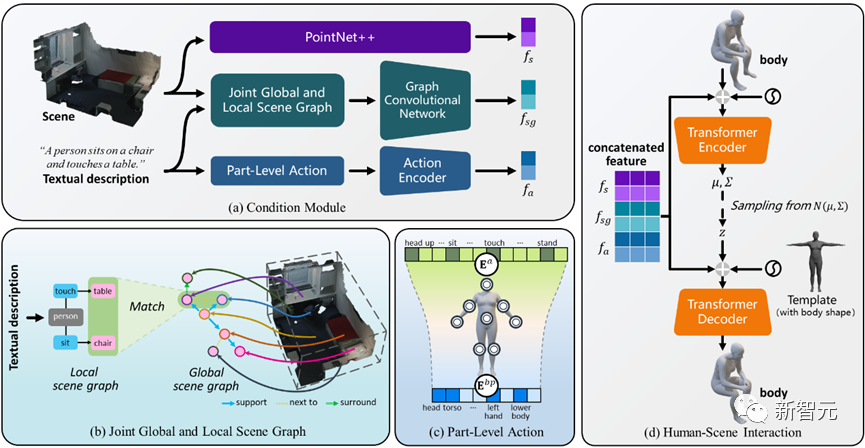 図 2 に示すように、このメソッドは Transformer ベースの条件付き変分オートエンコーダー (cVAE) を使用します。これには主に次のいくつかの部分が含まれます。
図 2 に示すように、このメソッドは Transformer ベースの条件付き変分オートエンコーダー (cVAE) を使用します。これには主に次のいくつかの部分が含まれます。
2)人間は体のさまざまな部分でインタラクティブなアクションを同時に完了するという観察に基づいて、現実的で多様なインタラクションを実現するために、コンポーネント レベルのアクション メカニズムが導入されています。最適化プロセスを意識し、より良い生成結果を得るためにインタラクティブな両面損失を追加導入しました
4) さらに複数人のインタラクションの生成まで拡張し、最終的には複数人のシーン インタラクションの最初のステップを促進します。
グローバル シーン グラフとローカル シーン グラフのメカニズムを組み合わせた
空間関係の推論により、モデルに特定のシーンに関する手がかりを提供できます。人間とシーンのインタラクションを実現し、自然な制御性が重要な役割を果たします。
この目標を達成するために、著者は、次の 3 つのステップを通じて実装される、グローバルおよびローカルのシーン グラフ結合メカニズムを提案します。 1. グローバル シーン グラフの生成: 与えられたシーンで、事前トレーニングされたシーン グラフ モデルを使用してグローバル シーン グラフ、つまり
を生成します。ここで、、
はカテゴリ ラベル を持つオブジェクトです。は 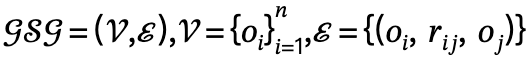 と
と 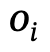 の間の関係、n はオブジェクトの数、m は関係の数です;
の間の関係、n はオブジェクトの数、m は関係の数です; 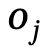
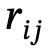
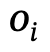
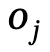 2. ローカル シーン グラフの生成: セマンティック分析ツールを使用して、識別して説明する 文構造が抽出および生成され、ローカル シーン
2. ローカル シーン グラフの生成: セマンティック分析ツールを使用して、識別して説明する 文構造が抽出および生成され、ローカル シーン
は主語、述語、目的語の 3 つの要素を定義します。
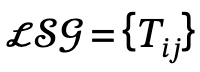
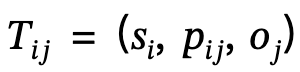 シーン グラフのマッチング: ~同じオブジェクト セマンティクス ラベルを使用すると、モデルはグローバル シーン グラフとローカル シーン グラフのノードに対応し、エッジ関係を拡張して位置情報を提供する仮想ヒューマン ノードを追加します
シーン グラフのマッチング: ~同じオブジェクト セマンティクス ラベルを使用すると、モデルはグローバル シーン グラフとローカル シーン グラフのノードに対応し、エッジ関係を拡張して位置情報を提供する仮想ヒューマン ノードを追加します
コンポーネント レベルのアクション (PLA) メカニズム
著者は、モデルが身体の重要な部分の状態に気づき、特定の状態から無関係な部分を無視できるようにする、きめの細かいパーツ レベルのアクション メカニズムを提案します。インタラクション
具体的には、著者は豊富で多様なインタラクティブなアクションを探索し、これらの可能なアクションを人体の 5 つの主要な部分 (頭、胴体、左/右腕、左/右手) にマッピングします。そして左右の下半身。
#後続のエンコードでは、One-Hot を使用してこれらのアクションと身体部分を同時に表現し、対応する関係に従ってそれらを接続できます 著者は、身体構造のさまざまな部分の状態を学習するために、マルチアクションのインタラクション生成でアテンション メカニズムを使用しています。 インタラクティブ アクションの特定の組み合わせでは、各アクションに対応する身体部分と他のすべてのアクションの間の注意は自動的にブロックされます。 「キャビネットを使って地面にしゃがむ人」を例にとると、しゃがむということは下半身の状態に相当するため、他の部分によってマークされた注意力はゼロになります。 書き換え内容:「キャビネットを使って地面にしゃがむ人」を例にとると、しゃがむということは下半身の状態に相当するため、他の部位への注意が完全に遮断されてしまう#シーンを意識した最適化
作者は、幾何学的および物理的制約を使用してシーンを意識した最適化を実行し、生成結果を改善しました。この方法では、最適化プロセス全体を通じて、生成されたポーズが逸脱しないようにしながら、シーンとの接触を促進し、シーンとの相互侵入を避けるために身体を拘束します。
与えられた 3 次元シーンS 生成された SMPL-X パラメータを追加した後の最適化損失は次のとおりです:
その中で、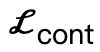 はボディの頂点がシーンに接触することを促します。
はボディの頂点がシーンに接触することを促します。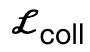 は符号付き距離に基づく衝突項です。
は符号付き距離に基づく衝突項です。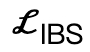 はサンプリングされた既存の作業と比較して追加で導入されたインタラクティブ二部構成 (IBS) 損失です。 from シーンと人体との間の等距離点のコレクション;
はサンプリングされた既存の作業と比較して追加で導入されたインタラクティブ二部構成 (IBS) 損失です。 from シーンと人体との間の等距離点のコレクション; 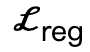 は、初期化から逸脱したパラメーターにペナルティを与えるために使用される正則化係数です。
は、初期化から逸脱したパラメーターにペナルティを与えるために使用される正則化係数です。
複数人シーン インタラクション (MHSI)
現実世界のシーンでは、多くの場合、シーンと対話しているのは 1 人だけではなく、複数人です。独立して、または関係的に相互作用します。
ただし、MHSI データセットが不足しているため、既存の方法では通常、追加の手動作業が必要であり、このタスクを制御された自動方法で処理することはできません。
この目的を達成するために、著者は既存の 1 人のデータセットのみを利用し、複数人の生成方向のためのシンプルで効果的な戦略を提案します。
複数の人物に関連するテキストの説明が与えられた後、作成者はまずそれを複数のローカル シーン グラフ 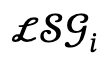 とインタラクティブ アクション
とインタラクティブ アクション 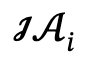 に解析し、候補セットを ## として定義します。 #、l は人数です。
に解析し、候補セットを ## として定義します。 #、l は人数です。 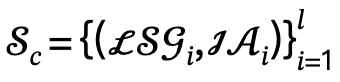
および対応するグローバル シーン グラフ 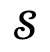 とともにナレーターに入力され、その後、最適化プロセスが実行されます。 。
とともにナレーターに入力され、その後、最適化プロセスが実行されます。 。 
が導入されます。ここで、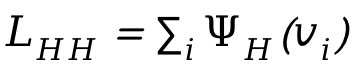 は人々の間の記号的な距離です。
は人々の間の記号的な距離です。 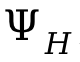
; それ以外の場合、生成された結果は信頼できないとみなされ、対応するオブジェクトが削除されます。  を更新するシールド ノードです。
を更新するシールド ノードです。 
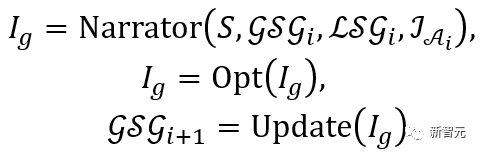
##実験結果
既存の方法では、テキスト記述から直接人間とシーンのインタラクションを自然かつ制御可能に生成できないという事実を考慮して、PiGraph [1]、POSA [2]、および COINS [3] を使用します。テキストの説明を処理できるように合理的に拡張し、同じデータセットを使用して公式モデルをトレーニングしました。変更後、これらのメソッドに PiGraph-Text、POSA-Text、COINS-Text
という名前を付けました。 図
図
図 3 さまざまな方法の定性的比較結果
ナレーターと 3 つのベースラインを図 3 に示します。定性的比較結果。 PiGraph-Text の表現制限により、より深刻な浸透の問題が発生します。
POSA-Text は、最適化プロセス中に極小値に陥ることが多く、その結果、インタラクティブな接触が不良になります。 COINS-Text はアクションを特定のオブジェクトにバインドし、シーンの全体的な認識を欠き、不特定のオブジェクトの侵入につながり、複雑な空間関係を処理するのが困難です。
対照的に、ナレーターは、さまざまなレベルのテキスト説明に基づいて空間関係を正確に推論し、複数のアクションの下で身体の状態を分析することで、より良い生成結果を達成できます。
表 1 に示すように、定量的な比較の観点からは、ナレーターは 5 つの指標において他の方法よりも優れており、この方法によって生成された結果はテキストの一貫性がより正確であり、物理的な妥当性が優れていることがわかります。
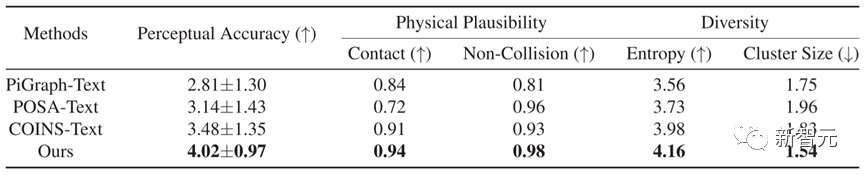 #表 1 さまざまな方法の定量的比較結果
#表 1 さまざまな方法の定量的比較結果
 図 4 COINS 逐次生成および最適化手法を使用した MHSI との定性的比較
図 4 COINS 逐次生成および最適化手法を使用した MHSI との定性的比較


主な研究方向には、3 次元ビジョン、コンピュータ ビジョン、人間によるインタラクティブ生成が含まれます。シーン付き


 ##研究の方向性は主に人間中心のコンピュータ ビジョンとグラフィックスに焦点を当てています
##研究の方向性は主に人間中心のコンピュータ ビジョンとグラフィックスに焦点を当てています
##主な研究方向: コンピューター グラフィックス、3 次元ビジョン、コンピューテーショナル フォトグラフィー
##個人ホームページのリンク: https://liuyebin.com/

主な研究方向: 3 次元ビジョン、インテリジェントな再構成と生成
個人ホームページ: http:// cic .tju.edu.cn/faculty/likun
参考文献:
[1] Savva M、Chang A X、Hanrahan P、ほか Pigraphs: From Observationインタラクティブ スナップショットの学習[J]. ACM Transactions on Graphics (TOG)、2016、35(4): 1-12.
[2] Hassan M、Ghosh P、Tesch J 他、3D シーンの作成人間とシーンのインタラクションを学習することによる[C]. コンピューター ビジョンとパターン認識に関する IEEE/CVF 会議議事録. 2021: 14708-14718.
[3] Zhao K、Wang S、Zhang Y、他. セマンティック制御を使用した構成的ヒューマンシーン インタラクション合成 [C]. コンピュータ ビジョンに関する欧州会議. Cham: Springer Nature Switzerland, 2022: 311-327.
以上が「人物とシーンのインタラクティブ生成」で新たな躍進!天達大学と清華大学がナレーターをリリース: テキスト駆動、自然に制御可能 | ICCV 2023の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7502
7502
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 清華鏡の完璧なガイド 出典: ソフトウェアのインストールをよりスムーズに
Jan 16, 2024 am 10:08 AM
清華鏡の完璧なガイド 出典: ソフトウェアのインストールをよりスムーズに
Jan 16, 2024 am 10:08 AM
清華ミラー ソースの使用ガイド: ソフトウェアのインストールをよりスムーズにするには、特定のコード サンプルが必要です。コンピューターを日常的に使用する過程で、さまざまなニーズを満たすためにさまざまなソフトウェアをインストールする必要があることがよくあります。ただし、ソフトウェアをインストールするとき、特に外部のミラー ソースを使用している場合、ダウンロード速度が遅い、接続できないなどの問題が発生することがよくあります。この問題を解決するために、清華大学は豊富なソフトウェア リソースを提供し、ダウンロード速度が非常に速いミラー ソースを提供しています。次に、清華ミラーソースの使用戦略について学びましょう。初め、
 Java で ClassCastException はどのようなシナリオで発生しますか?
Jun 25, 2023 pm 09:19 PM
Java で ClassCastException はどのようなシナリオで発生しますか?
Jun 25, 2023 pm 09:19 PM
Java は、実行時にデータ型の一致を必要とする厳密に型指定された言語です。 Java の厳密な型変換メカニズムにより、コード内でデータ型の不一致がある場合、ClassCastException が発生します。 ClassCastException は Java 言語でよく発生する例外の 1 つで、この記事では ClassCastException の原因と回避方法を紹介します。 ClassCastExceptionとは何ですか
 Linux システム用のこれらのストレス テスト ツールを使用したことがありますか?
Mar 21, 2024 pm 04:12 PM
Linux システム用のこれらのストレス テスト ツールを使用したことがありますか?
Mar 21, 2024 pm 04:12 PM
運用保守担当者として、このようなシナリオに遭遇したことがありますか?ツールを使用して、システムの CPU またはメモリの高い使用率をテストしてアラームをトリガーしたり、ストレス テストを通じてサービスの同時実行機能をテストしたりする必要があります。運用およびメンテナンス エンジニアは、これらのコマンドを使用して障害シナリオを再現することもできます。この記事は、一般的に使用されるテスト コマンドとツールを習得するのに役立ちます。 1. はじめに 場合によっては、プロジェクト内の問題を特定して再現するには、ツールを使用して系統的なストレス テストを実施し、障害シナリオをシミュレートおよび復元する必要があります。現時点では、テストまたはストレス テスト ツールが特に重要になります。次に、さまざまなシナリオに応じてこれらのツールの使用法を検討します。 2. テストツール 2.1 ネットワーク速度制限ツール tctc は、Linux のネットワークパラメータを調整するために使用されるコマンドラインツールで、さまざまなネットワークをシミュレートするために使用できます。
 2 文で言えば、AI に VR シーンを生成させましょう!それとも 3D または HDR パノラマのようなものですか?
Apr 12, 2023 am 09:46 AM
2 文で言えば、AI に VR シーンを生成させましょう!それとも 3D または HDR パノラマのようなものですか?
Apr 12, 2023 am 09:46 AM
Big Data Digest 制作者: Caleb 最近、ChatGPT が非常に人気があると言えます。 OpenAIは11月30日にチャットロボット「ChatGPT」をリリースし、テスト用に無料公開して以来、中国で広く利用されている。ロボットに話しかけるとは、キーワードを入力してAIに対応する画像を生成させるなど、ロボットに特定の命令の実行を依頼することです。これは珍しいことではないようですが、OpenAI も 4 月に DALL-E の新バージョンをアップデートしましたよね? OpenAIさん、あなたは何歳ですか? (なぜいつもあなたなのですか?) ダイジェストが、生成された画像が 3D 画像、HDR パノラマ、または VR ベースの画像コンテンツであると言ったらどうしますか?最近、シンガポール
 清華光学のAIがNatureに登場!物理ニューラル ネットワーク、バックプロパゲーションは不要になりました
Aug 10, 2024 pm 10:15 PM
清華光学のAIがNatureに登場!物理ニューラル ネットワーク、バックプロパゲーションは不要になりました
Aug 10, 2024 pm 10:15 PM
光を使用してニューラル ネットワークをトレーニングした清華大学の研究結果が、最近 Nature 誌に掲載されました。逆伝播アルゴリズムを適用できない場合はどうすればよいですか?彼らは、物理的な光学システムでトレーニング プロセスを直接実行する完全順方向モード (FFM) トレーニング方法を提案し、従来のデジタル コンピューター シミュレーションの制限を克服しました。簡単に言うと、これまでは物理システムを詳細にモデル化し、それらのモデルをコンピューター上でシミュレートしてネットワークをトレーニングする必要がありました。 FFM 手法ではモデリング プロセスが不要になり、システムが学習と最適化に実験データを直接使用できるようになります。これは、トレーニングで各層を後ろから前にチェックする (バックプロパゲーション) 必要がなくなり、ネットワークのパラメーターを前から後ろに直接更新できることも意味します。パズルのように例えると、バックプロパゲーションです。
 一般的な Kafka コマンドの使用方法を学び、さまざまなシナリオに柔軟に対応します。
Jan 31, 2024 pm 09:22 PM
一般的な Kafka コマンドの使用方法を学び、さまざまなシナリオに柔軟に対応します。
Jan 31, 2024 pm 09:22 PM
Kafka 学習の必需品: 一般的なコマンドをマスターし、さまざまなシナリオに簡単に対処する 1. Topicbin/kafka-topics.sh--create--topicmy-topic--partitions3--replication-factor22 を作成します。Topicbin/kafka-topics.sh をリストします - -list3. トピックの詳細を表示 bin/kafka-to
 大規模モデルのモデル融合法について話しましょう
Mar 11, 2024 pm 01:10 PM
大規模モデルのモデル融合法について話しましょう
Mar 11, 2024 pm 01:10 PM
これまでの実践では、モデル融合は、特に判別モデルで広く使用されており、パフォーマンスを着実に向上させることができる方法と考えられています。ただし、生成言語モデルの場合、復号化プロセスが関係するため、その動作方法は判別モデルほど単純ではありません。さらに、大規模なモデルのパラメータ数が増加するため、より大きなパラメータスケールのシナリオでは、単純なアンサンブル学習で考慮できる手法は、従来のスタッキング、ブースティング、およびなどの低パラメータの機械学習よりも制限されます。他の方法は、モデルをスタッキングするためです。パラメータの問題は簡単に拡張できません。したがって、大規模なモデルのアンサンブル学習には慎重な検討が必要です。以下では、モデル統合、確率的統合、グラフティング学習、クラウドソーシング投票、MOE という 5 つの基本的な統合手法について説明します。
