

異常検出: ルール エンジンで誤検知を最小限に抑える

異常とは、予想されるパターンからの逸脱であり、銀行取引、産業運営、マーケティング業界、医療監視など、さまざまな環境で発生する可能性があります。従来の検出方法では、多くの場合、高い誤警報率が発生します。誤検知は、システムが日常的なイベントを異常として誤って識別した場合に発生し、不必要な調査作業や運用の遅延が発生します。この非効率性はリソースを浪費し、解決すべき実際の問題から注意をそらすため、差し迫った問題です。この記事では、ルールベースのエンジンを広範囲に活用した異常検出への特殊なアプローチについて詳しく説明します。このアプローチでは、複数の主要業績評価指標 (KPI) を相互参照することで、違反を特定する精度が向上します。このアプローチは、異常の存在をより効果的に検証または反証できるだけでなく、場合によっては問題の根本原因を分離して特定することもできます。
システム アーキテクチャの概要
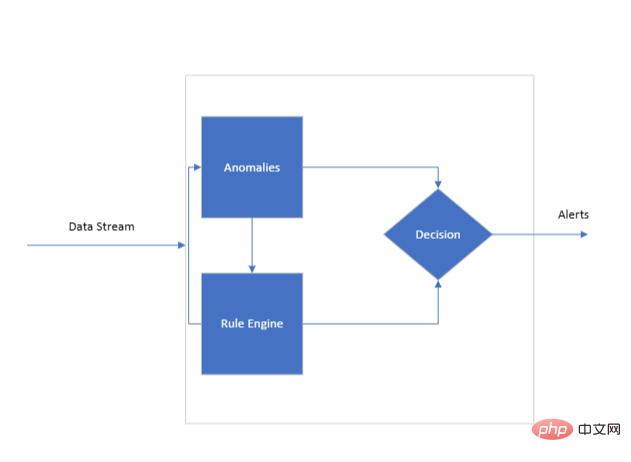
データ フロー
これは、エンジン。フロー内の各ポイントは、トレーニング ルールセットに対して評価するためにルール エンジンによって使用される 1 つ以上の KPI に関連付けることができます。リアルタイム監視にはデータの継続的なフローが不可欠であり、エンジンの動作に必要な情報が提供されます。
ルール エンジン アーキテクチャ
システムの中心となるのはルール エンジンであり、KPI の微妙な違いを理解するためにトレーニングする必要があります。監視します。ここで、一連の KPI ルールが登場します。これらのルールはエンジンのアルゴリズムの基礎として機能し、2 つ以上の KPI を相互に関連付けるように設計されています。
KPI ルールの種類:
- データ品質: データ フローの一貫性、正確性、信頼性に焦点を当てたルール。
- #KPI 関連性: 特定の KPI の関連性に焦点を当てたルール
ルール適用プロセス
#データを受信すると、エンジンは受信した KPI の逸脱または異常をすぐに探します。ここでの異常とは、所定の許容範囲外にあるメトリックを指します。エンジンは、さらなる調査のためにこれらの異常にフラグを立てます。調査は、受け入れ、拒否、絞り込みという 3 つの主要な操作に分けることができます。これには、検出された異常を検証または否定するために、ある KPI を別の KPI と関連付けることが含まれる場合があります。方法
ルールの形成
基本的な手順には、関連する一連の KPI の作成が含まれます。複数の KPI を相互に関連付けたルールにします。たとえば、ルールは製品の品質指標を工場設定での生産速度に関連付けることができます。例えば:######
- KPI 間の直接的な関係: 2 つの KPI 間の「直接的な関係」とは、一方の KPI が増加すると他方の KPI も増加するか、一方の KPI が減少すると他方の KPI も減少することを意味します。たとえば、小売業では、広告費の増加 (KPI1) が売上収益の増加 (KPI2) に直接関係している可能性があります。この場合、一方の側面の増加は他方にもプラスの影響を及ぼします。この知識は、戦略計画やリソースの割り当てに役立つため、企業にとって非常に貴重です。
- KPI 間の逆関係: 一方、「逆関係」とは、1 つの KPI が増加すると、もう 1 つの KPI が減少し、その逆も同様であることを意味します。たとえば、製造環境では、製品の生産にかかる時間 (KPI1) が生産性 (KPI2) と逆の関係にある場合があります。生産時間が短縮されると、生産性が向上する可能性があります。両方の KPI を最適化するにはバランスをとる手段が必要になる場合があるため、逆関係を理解することもビジネスの最適化にとって重要です。
- KPI を組み合わせて新しいルールを作成する: 場合によっては、2 つ以上の KPI を組み合わせて、ビジネス パフォーマンスに関する貴重な洞察を提供できる新しい指標を作成すると有益な場合があります。たとえば、顧客生涯価値 (KPI1) と顧客獲得コスト (KPI2) を組み合わせると、3 番目の KPI、つまり顧客価値対コスト比が得られます。この新しい KPI は、新規顧客を獲得するためのコストが、長期にわたって提供する価値に見合ったものであるかどうかをより包括的に理解できるようにします。
#トレーニング ルール エンジン
ルール エンジンは包括的にトレーニングされており、効果的に適用できます。これらのルール。
リアルタイムレビュー
ルール エンジンは受信データを積極的に監視し、トレーニングされたルールを適用して異常または潜在的な異常を特定します。
意思決定
潜在的な異常を特定する際のエンジン:
- 例外の受け入れ: 確認フェーズ: 例外にフラグが立てられると、エンジンは事前トレーニングされた KPI ルールを使用して、例外を他の関連する KPI と比較します。ここでのポイントは、その異常が実際に問題なのか、それとも単なる外れ値なのかを判断することです。この確認は、プライマリ KPI とセカンダリ KPI 間の相関関係に基づいて行われます。
- 例外の拒否: 偽陽性フェーズ: すべての例外が問題を示しているわけではありません。一部の例外は統計的な外れ値またはデータ エラーである可能性があります。この場合、エンジンはトレーニングを使用して異常を拒否し、基本的に異常を誤検知として識別します。これは、不必要なアラート疲労を排除し、リソースを実際の問題に集中させるために重要です。
- 例外の範囲の絞り込み: 改善フェーズ: 例外は、複数のコンポーネントに影響を与えるより大きな問題の一部である場合があります。ここで、エンジンは、問題を特定の KPI コンポーネントに絞り込むことで、問題の正確な性質をさらに正確に特定します。この高度なフィルタリングは、問題を迅速に特定し、根本原因を解決するのに役立ちます。
利点
- 誤検知の削減: 複数の KPI を相互参照するルール エンジンを使用することにより、システムは大幅に誤検知の発生率を削減します。
- 時間とコストの効率: 異常の検出と解決が向上し、運用時間と関連コストが削減されます。
- 精度の向上: 複数の KPI を比較対照する機能により、異常なイベントをより詳細かつ正確に表現できるようになります。
#結論
この記事では、さまざまな KPI ルール セットでトレーニングされたルール エンジンを使用した異常検出のアプローチについて概説します。多くの場合、統計アルゴリズムまたは機械学習モデルのみに依存する従来の異常検出システムとは対照的に、このアプローチは、基礎として特殊なルール エンジンを使用します。さまざまな KPI 間の関係と相互作用をより深く掘り下げることで、企業は、単純なスタンドアロンの指標では得られない、より詳細な洞察を得ることができます。これにより、より堅牢な戦略計画、より優れたリスク管理、およびビジネス目標を達成するための全体的により効果的なアプローチが可能になります。異常にフラグが立てられると、エンジンは事前にトレーニングされた KPI ルールを使用して、異常を他の関連する KPI と比較します。ここでのポイントは、その異常が実際に問題なのか、それとも単なる外れ値なのかを判断することです。
以上が異常検出: ルール エンジンで誤検知を最小限に抑えるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7481
7481
 15
1377
52
77
11
19
34
15
1377
52
77
11
19
34

 PHP を使用して異常検出と不正分析を実装する方法
Jul 30, 2023 am 09:42 AM
PHP を使用して異常検出と不正分析を実装する方法
Jul 30, 2023 am 09:42 AM
PHP を使用して異常検出と不正分析を実装する方法 要約: 電子商取引の発展に伴い、不正行為は無視できない問題になっています。この記事では、PHP を使用して異常検出と不正分析を実装する方法を紹介します。ユーザーのトランザクション データと行動データを収集し、機械学習アルゴリズムと組み合わせることで、ユーザーの行動がシステム内でリアルタイムに監視および分析され、潜在的な不正行為が特定され、それに対応する措置が講じられます。キーワード: PHP、異常検出、不正分析、機械学習 1. はじめに 電子商取引の急速な発展に伴い、人々がインターネット上で行う取引の数は増加しています。
 Nginx セキュリティ パフォーマンスの監視と異常検出
Jun 10, 2023 pm 04:15 PM
Nginx セキュリティ パフォーマンスの監視と異常検出
Jun 10, 2023 pm 04:15 PM
Nginx は、インターネット上で広く使用されている、無料のオープンソース、高性能、軽量の HTTP サーバー ソフトウェアです。ただし、Nginx はパブリック ネットワークに面していることが多く、重要な Web サービスを担当しているため、定期的なセキュリティ パフォーマンスの監視と異常検出を実行し、Web サイトの正常な動作とデータのセキュリティを確保するためにタイムリーかつ効果的なセキュリティ対策を講じる必要があります。 1. Nginx のセキュリティ性能監視 Nginx のセキュリティ性能監視には主に以下の内容が含まれます。 (1) Nginx のアクセスログ監視 Nginx
 MySql ログ監視: MySQL のエラーと例外を迅速に検出して分析する方法
Jun 15, 2023 pm 09:42 PM
MySql ログ監視: MySQL のエラーと例外を迅速に検出して分析する方法
Jun 15, 2023 pm 09:42 PM
インターネットとビッグデータ時代の到来に伴い、MySQL データベースは、一般的に使用されるオープンソース データベース管理システムとして、ますます多くの企業や組織で採用されています。ただし、実際のアプリケーションプロセスでは、システムクラッシュ、クエリタイムアウト、デッドロックなど、MySQL データベースでさまざまなエラーや例外が発生する可能性があります。これらの異常はシステムの安定性とデータの整合性に重大な影響を与えるため、MySQL のエラーと異常を迅速に検出して分析することは非常に重要なタスクです。ログ監視は MySQL の重要な機能です
 Python での異常検出の例
Jun 09, 2023 pm 09:33 PM
Python での異常検出の例
Jun 09, 2023 pm 09:33 PM
Python は、学習が容易で強力な高級プログラミング言語であり、可読性が高く、コード量が少なく、メンテナンスが容易であるため、科学技術計算、データ分析、人工知能などの分野で広く使用されています。ただし、どのプログラミング言語でもエラーや例外が発生する可能性があるため、開発者がこれらの状況に適切に対処できるように、Python には例外メカニズムも用意されています。この記事では、Python の異常検出メカニズムの使用方法といくつかの例を紹介します。 1. Py における Python の例外タイプ
 Python でのデータ信頼性検証とモデル評価のベスト プラクティスとアルゴリズムの選択
Oct 27, 2023 pm 12:01 PM
Python でのデータ信頼性検証とモデル評価のベスト プラクティスとアルゴリズムの選択
Oct 27, 2023 pm 12:01 PM
Python でデータの信頼性検証とモデル評価のベスト プラクティスとアルゴリズムの選択を実行する方法 はじめに: 機械学習とデータ分析の分野では、データの信頼性の検証とモデルのパフォーマンスの評価は非常に重要なタスクです。データの信頼性を検証することで、データの品質と精度が保証され、モデルの予測力が向上します。モデルの評価は、最適なモデルを選択し、そのパフォーマンスを判断するのに役立ちます。この記事では、Python でのデータ信頼性検証とモデル評価のベスト プラクティスとアルゴリズムの選択を紹介します。
 時系列に基づく異常検出問題
Oct 09, 2023 pm 04:33 PM
時系列に基づく異常検出問題
Oct 09, 2023 pm 04:33 PM
時系列に基づく異常検出の問題には、具体的なコード例が必要です 時系列データとは、株価、気温の変化、交通の流れなど、時間の経過とともに一定の順序で記録されたデータです。実際のアプリケーションでは、時系列データの異常検出は非常に重要です。外れ値は、通常のデータ、ノイズ、誤ったデータ、または特定の状況における予期せぬイベントと一致しない極端な値である可能性があります。異常検出は、これらの異常を発見し、適切な措置を講じるのに役立ちます。時系列異常検出問題の場合、一般的に使用される
 時系列分析のための Python: 予測と異常検出
Aug 31, 2023 pm 08:09 PM
時系列分析のための Python: 予測と異常検出
Aug 31, 2023 pm 08:09 PM
Python はデータ サイエンティストやアナリストにとって最適な言語となっており、包括的なデータ分析ライブラリとツールを提供しています。特にPythonは時系列分析に優れ、予測や異常検知に優れています。 Python は、そのシンプルさ、多用途性、そして統計および機械学習技術の強力なサポートにより、時間依存データから貴重な洞察を抽出するための理想的なプラットフォームを提供します。この記事では、予測と異常検出に焦点を当てて、時系列分析における Python の優れた機能について説明します。これらのタスクの実践的な側面を掘り下げることで、Python のライブラリとツールがどのように時系列データの異常の正確な予測と特定を可能にするかを強調します。実際の例と実証的なインプットを通じて
 C# で異常検出アルゴリズムを実装する方法
Sep 19, 2023 am 08:09 AM
C# で異常検出アルゴリズムを実装する方法
Sep 19, 2023 am 08:09 AM
C# で異常検出アルゴリズムを実装するには、特定のコード例が必要です はじめに: C# プログラミングでは、例外処理は非常に重要な部分です。プログラム内でエラーや予期せぬ状況が発生した場合、例外処理メカニズムはこれらのエラーを適切に処理し、プログラムの安定性と信頼性を確保するのに役立ちます。この記事では、C# で異常検出アルゴリズムを実装する方法と具体的なコード例を詳しく紹介します。 1. 例外処理の基礎知識 例外の定義と分類 例外とは、プログラムの実行中に発生するエラーや予期せぬ状況であり、プログラムの通常の実行フローを中断します。
