

言語モデリングの新時代が到来しました。大規模言語モデル (LLM) には並外れた機能があります。自然言語を理解できるだけでなく、ユーザーのニーズに応じてカスタマイズされたコードを生成することもできます。
その結果、API を使用してコード スニペットを生成したり、コードのバグを検出したりするなど、プログラミングの質問に答えるために大規模な言語モデルをクエリすることを選択するソフトウェア エンジニアが増えています。大規模な言語モデルでは、Stack Overflow のようなオンライン プログラミング フォーラムを検索するよりも、プログラミングの質問に対して適切に調整された回答を取得できます。
LLM は高速ですが、コード生成における潜在的なリスクも隠蔽します。ソフトウェア エンジニアリングの観点から見ると、LLM のコード生成機能の堅牢性と信頼性は、(構文エラーの回避と生成されたコードの意味的理解を向上させるという点で) 多くの研究結果が発表されているにもかかわらず、十分に研究されていません。
Web プログラミング フォーラムの場合とは異なり、LLM によって生成されたコードはコミュニティ ピアによってレビューされないため、ファイルの読み取りや変数の境界の欠落など、API の誤用の問題が発生する可能性があります。インデックス作成。チェック、ファイル I/O クロージャの欠落、トランザクション完了の失敗など。生成されたコード サンプルが実行できたり、機能を正しく実行できたとしても、誤用すると、メモリ リーク、プログラムのクラッシュ、ガベージ データ コレクションの失敗など、製品に重大な潜在リスクが発生する可能性があります。
さらに悪いことに、これらの質問をするプログラマは、API を初めて使用する可能性が高く、生成されたコード スニペットの潜在的な問題を識別できないため、最も脆弱になります。
次の図は、ソフトウェア エンジニアが LLM にプログラミングの質問をする例を示しています。Llama-2 が正しい構文、正しい関数、および構文を含むコード セグメントを提供できることがわかります。ファイルが既に存在する場合やフォルダが存在しない場合を考慮していないため、十分に堅牢ではないという問題があります。

したがって、大規模な言語モデルのコード生成機能を評価するときは、コードの信頼性を考慮する必要があります。
大規模な言語モデルのコード生成機能を評価するという観点から見ると、既存のベンチマークのほとんどは、生成されたコードの実行結果の機能の正確さに焦点を当てています。コード ユーザーの機能上のニーズを満たすことができれば、ユーザーはそれを受け入れるでしょう。
しかし、ソフトウェア開発の分野では、コードが正しく実行されるだけでは十分ではありません。ソフトウェア エンジニアが必要としているのは、長期的には潜在的なリスクを伴うことなく、新しい API を正しく確実に使用できるコードです。
さらに、最近のプログラミングの問題の範囲は、ソフトウェア エンジニアリングからは遠く離れています。データ ソースのほとんどは、Codeforces、Kattis、Leetcode などのオンライン プログラミング チャレンジ ネットワークです。この成果は注目に値しますが、実際のアプリケーション シナリオでのソフトウェア開発作業を支援するには十分ではありません。
この目的を達成するために、カリフォルニア大学サンディエゴ校の Li Zhong 氏と Zilong Wang 氏は、大規模な言語モデルによって生成されたコードの信頼性と堅牢性を評価できるフレームワークである RobustAPI を提案しました。プログラミング問題データセットと抽象構文ツリー (AST) を使用した評価器。

論文アドレス: https://arxiv.org/pdf/2308.10335.pdf
ここでデータセットの目標は、実際のソフトウェア開発に近い評価設定を作成することです。この目的を達成するために、研究者らは Java に関する代表的な質問を Stack Overflow から収集しました。 Java は最も人気のあるプログラミング言語の 1 つであり、WORA (Write Once Run Anywhere) 機能のおかげでソフトウェア開発に広く使用されています。
各質問について、研究者は詳細な説明と関連する Java API を提供しました。また、大規模な言語モデルを呼び出してコード スニペットと対応する説明を生成するためのテンプレートのセットも設計しました。
研究者らは、抽象構文ツリー (AST) を使用して、生成されたコード スニペットを分析し、予想される API 使用パターンと比較する評価ツールも提供しています。
研究者らはまた、Zhang et al. (2018) の方法に従って、AI の使用パターンを構造化された呼び出しシーケンスに形式化しました。この構造化された一連の呼び出しは、これらの API を正しく使用して潜在的なシステム リスクを排除する方法を示しています。ソフトウェア エンジニアリングの観点からは、この構造化された呼び出しシーケンスに違反すると失敗とみなされます。
研究者らは、24 の代表的な Java API を含む 1,208 件の実際の質問を Stack Overflow から収集しました。研究者らはまた、クローズドソース言語モデル (GPT-3.5 および GPT-4) だけでなく、オープンソース言語モデル (Llama-2 および Vicuna-1.5) を含む実験評価も実施しました。モデルのハイパーパラメータ設定については、デフォルト設定が使用され、それ以上のハイパーパラメータ調整は実行されませんでした。また、ゼロショットとワンショットという 2 つの実験形式も設計しました。これらは、それぞれプロンプトにゼロまたは 1 つのデモンストレーション サンプルを提供します。
研究者らは、LLM によって生成されたコードを包括的に分析し、一般的な API の誤用を研究しました。彼らは、これによって、コード生成時に LLM が API を誤用するという重要な問題に光が当たることを期待しており、またこの研究は、一般的に使用されている機能の正確性を超えた、LLM の評価に新しい次元を提供することになると期待しています。さらに、データセットと推定ツールはオープンソースになります。
この論文の貢献は次のように要約されます:
RobustAPI は、LLM で生成されたコードの信頼性と堅牢性を包括的に評価するためのフレームワークです。
このデータセットを構築する際のデータ収集プロセスとプロンプト生成プロセスを以下に説明し、その後、RobustAPI で評価された API 誤用パターンと、誤用の潜在的な結果を示します。最後に、抽象構文ツリーを使用して API の誤用を検出するために RobustAPI を使用する静的分析も紹介します。
新しい方法は、キーワード マッチングなどのルールベースの方法と比較して、LLM で生成されたコードの API 誤用をより高い精度で評価できることがわかりました。
データ収集
ソフトウェア工学分野における既存の研究成果を活用するために、研究者は、開始点は ExampleCheck (Zhang et al. 2018) のデータセットです。 ExampleCheck は、Web Q&A フォーラムで一般的な Java API の誤用を研究するためのフレームワークです。
研究者は、以下の表 1 に示すように、このデータセットから 23 の一般的な Java API を選択しました。これら 23 の API は、文字列処理、データ構造、モバイル開発、暗号化、データベース操作を含む 5 つの領域をカバーします。

プロンプトの生成
RobustAPI には、次のようなプロンプト テンプレートも含まれています。データセットからのサンプルを埋め込んで使用されます。次に、研究者らはプロンプトに対する LLM の応答を収集し、API チェッカーを使用してコードの信頼性を評価しました。

このプロンプトでは、タスクの概要と必要な応答形式が最初に示されます。次に、実行された実験が少数サンプルの実験である場合は、少数サンプルのデモンストレーションも行われます。以下に例を示します。
デモ サンプル
##デモ サンプルは、LLM が自然言語を理解するのに役立つことが証明されています。 LLM のコード生成能力を徹底的に分析するために、研究者らは、単一サンプルの無関係なデモンストレーションと単一サンプル依存のデモンストレーションという 2 つの少数ショット設定を設計しました。
単一サンプルに依存しないデモ設定では、LLM 用に提供されるデモ サンプルは、依存しない API を使用します。研究者らは、このような実証例によって、生成されたコードの構文エラーが排除されるだろうと仮説を立てました。 RobustAPI で使用される無関係な例は次のとおりです:

単一サンプル相関デモ設定では、LLM に提供されるデモ サンプルは、指定された問題と同じ API を使用します。この例には、質問と回答のペアが含まれています。このデモの質問はテスト データセットには含まれておらず、API の誤用がなく、回答と質問のセマンティクスが適切に調整されていることを確認するために、回答は手動で修正されました。
Java API の誤用
研究者は、RobustAPI の 23 API に対する 40 の API ルールを要約しました。これらの API のドキュメントを参照してください。これらのルールには次のものが含まれます。
(1) API のガード条件。API 呼び出し前にチェックする必要があります。たとえば、File.exists () の結果は、File.createNewFile () の前にチェックする必要があります。
(2) 必要な API 呼び出しシーケンス、つまり API は特定の順序で呼び出される必要があります。たとえば、close () は File.write () の後に呼び出す必要があります。
(3) API 制御構造。たとえば、SimpleDateFormat.parse () は try-catch 構造に含める必要があります。
例を以下に示します。

API の誤用の検出
コード内の API 使用の正しさを評価するために、RobustAPI は、以下に示すように、コード セグメントから呼び出し結果と制御構造を抽出することにより、API 使用ルールに従って API の誤使用を検出できます。 。

コード チェッカーはまず、生成されたコード セグメントをチェックして、このコードがメソッド内のコードの一部であるか、クラスのメソッドからのコードであるかを確認します。そのコード部分をカプセル化し、それを使用して抽象構文ツリー (AST) を構築できるようにします。
インスペクターは AST を走査し、すべてのメソッド呼び出しと制御構造を順番に記録し、一連の呼び出しを生成します。
次に、チェッカーは、この一連の呼び出しを API 使用ルールと比較します。各メソッド呼び出しのインスタンス タイプを推論し、そのタイプとメソッドをキーとして使用して、対応する API 使用規則を取得します。
最後に、チェッカーは、この呼び出しシーケンスと API 使用ルールの間の最長の共通シーケンスを計算します。
呼び出しシーケンスが予想される API 使用ルールと一致しない場合、チェッカーは API の誤使用を報告します。
研究者らは、GPT-3.5、GPT-4、Llama の 4 つの LLM で RobustAPI を評価しました。 2とビクーニャ-1.5。
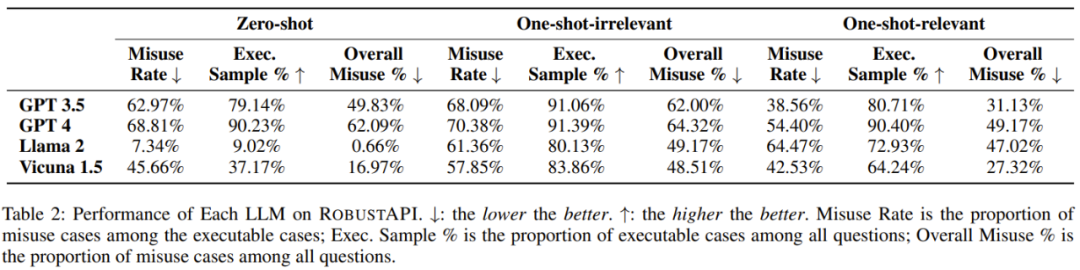
実験で使用される評価指標には、API 誤使用率、実行可能サンプルの割合、全体的な API 誤使用の割合が含まれます。
実験の目的は、次の質問に答えてみることです:
具体的な実験プロセスについては、元の論文を参照してください。研究者によって得られた 5 つの発見は次のとおりです。発見 1: 現実世界のプログラミング問題に対する現在の最先端の大規模言語モデルの答えは、広範な API の誤用に悩まされています。
調査結果 2: 実行可能コードを含むすべての LLM 回答のうち、コード セグメントの 57 ~ 70% に API 誤用の問題があります。これは深刻な事態を引き起こす可能性があります。生産への影響。

調査結果 3: 無関係なサンプル例は API 誤用率の削減には役立ちませんが、より効果的な回答を導き出し、モデルのパフォーマンスのベンチマークに効果的に使用できます。
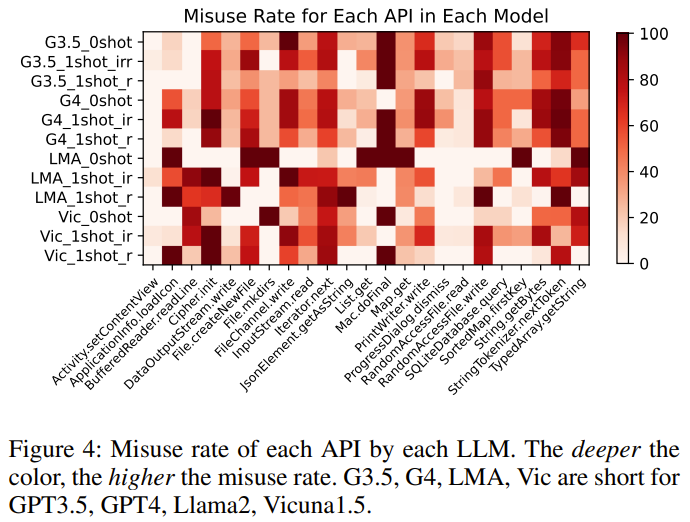
発見 4: 一部の LLM は正しい使用例を学習できるため、API の誤使用率を減らすことができます。
調査結果 5: GPT-4 は、実行可能コードを含む回答の数が最も多くなっています。ベースライン API の場合、LLM が異なれば、誤使用率の傾向も異なります。
さらに、研究者は論文の中で GPT-3.5 に基づく典型的なケースも実証しました。モデルは、異なる実験設定では異なる応答を示します。
このタスクは、PrintWriter.write API を使用してファイルに文字列を書き込むのを支援するようにモデルに依頼することです。

#ゼロサンプルと単一サンプルの無関係なデモ設定では答えが若干異なりますが、API の誤用の問題が発生します - 例外は考慮されません。 。モデルに API 使用法の正しい例が与えられると、モデルは API の使用方法を学習し、信頼性の高いコードを生成します。
詳細については、元の論文を参照してください。
以上がGPT-4: 私が書いたコードを使用する勇気はありますか?調査によると、API の誤用率は 62% を超えていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



