

動的プロトタイピング拡張機能を備えた自己トレーニング方法を使用して、オープンワールドのテスト セグメントのトレーニング手法を探索します。

モデルの一般化能力の向上は、視覚ベースの知覚手法の実装を促進するための重要な基盤です。テスト時間トレーニング/適応 (テスト時間トレーニング/適応) は、モデルを未知のターゲット ドメイン データに一般化します。流通セグメント。既存の TTT/TTA 手法は通常、閉ループの世界でターゲット ドメイン データの下でテスト セグメントのトレーニング パフォーマンスを向上させることに焦点を当てています。
ただし、多くのアプリケーション シナリオでは、ターゲット ドメインは、セマンティック カテゴリに関係のないデータなどの強力なドメイン外データ (強力な OOD) によって簡単に汚染されます。このシナリオは、Open World Test Segment Training (OWTTT) とも呼ばれます。この場合、既存の TTT/TTA は通常、強力なドメイン外データを既知のカテゴリに分類することを強制するため、最終的にノイズの影響を受けた画像などの弱いドメイン外データ (弱い OOD) を解決する機能が妨げられます
最近、華南理工大学とA*STARチームは初めてオープンワールドテストセグメントトレーニングの設定を提案し、対応するトレーニング方法を開始しました

- #論文: https://arxiv.org/abs/2308.09942
- コード: https://github. com/Yushu-Li/OWTTT
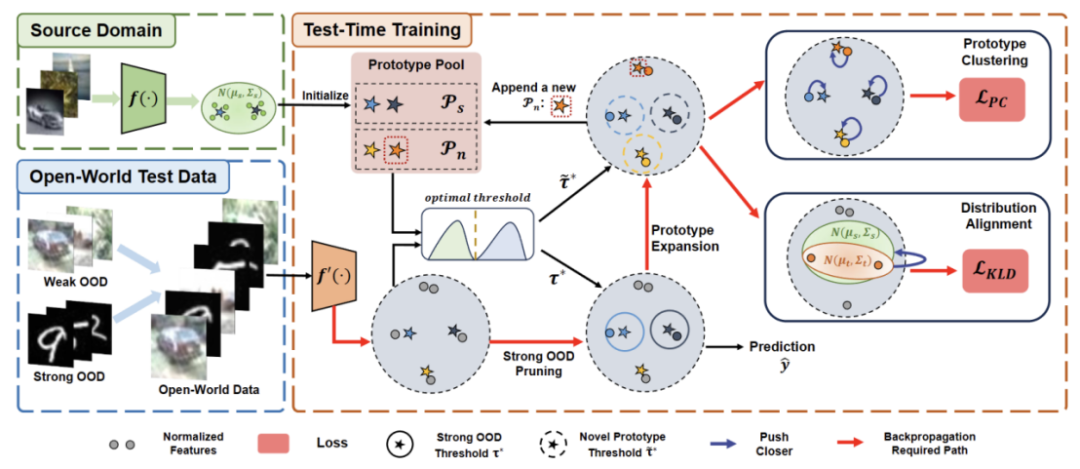
この論文では、まず、自己学習 TTT の堅牢性を向上させるための、適応しきい値を備えた強力なドメイン外データ サンプル フィルタリング方法を提案します。オープンワールドでのメソッド。この方法はさらに、動的に拡張されたプロトタイプに基づいて強力なドメイン外サンプルを特徴付けて、弱い/強いドメイン外データ分離効果を改善する方法を提案します。最後に、自己トレーニングは分布の調整によって制約されます
この研究の方法は、5 つの異なる OWTTT ベンチマークで最高のパフォーマンスを達成し、その後の TTT 研究に新たな方向性を切り開きました。より堅牢な TTT メソッドを実現します。この研究は ICCV 2023 の口頭発表論文として採択されました
はじめに
テストセグメントトレーニング (TTT) は対象ドメインのみにアクセスできます推論フェーズのデータ中に、分布シフトのあるテスト データに対してオンザフライ推論を実行します。 TTT の成功は、人工的に選択された多数の合成的に破損したターゲット ドメイン データで実証されています。ただし、既存の TTT 手法の機能の限界は十分に調査されていません。
オープン シナリオで TTT アプリケーションを促進するために、研究の焦点は、TTT 手法が失敗する可能性があるシナリオの調査に移ってきました。より現実的なオープンワールド環境で安定した堅牢な TTT 手法を開発するために多くの努力が払われてきました。この作業では、ターゲット ドメインに、ソース ドメインとは異なるセマンティック カテゴリや単なるランダム ノイズなど、大幅に異なる環境から抽出されたテスト データ分布が含まれる可能性がある、一般的だが見落とされているオープンワールド シナリオを掘り下げます。
上記のテスト データを強力な分布外データ (strong OOD) と呼びます。本作で弱いOODデータと呼んでいるのは、一般的な合成ダメージなどの分布シフトを伴うテストデータです。したがって、この現実的な環境に関する既存の作業が不足しているため、テスト データが強力な OOD サンプルによって汚染されているオープン ワールド テスト セグメント トレーニング (OWTTT) の堅牢性の向上を検討する動機になります。
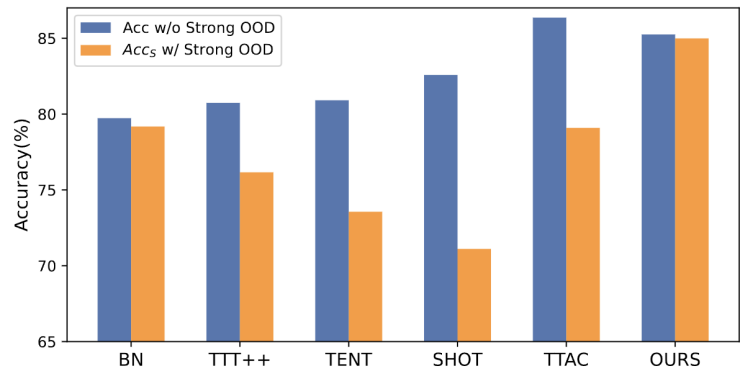
図 1: OWTTT 設定での既存の TTT メソッドの評価結果
図に示すとおり、図に示すとおり図 1 では、最初に OWTTT 設定の下で既存の TTT メソッドを評価し、自己トレーニングと分布調整による TTT メソッドが強い OOD サンプルの影響を受けることを発見しました。これらの結果は、オープンワールドでの安全なテスト時間トレーニングは、既存の TTT 技術を適用することによっては達成できないことを示しています。彼らの失敗は次の 2 つの理由によると考えられます。
- セルフトレーニング ベースの TTT では、テスト サンプルを既知のクラスに割り当てる必要があるため、強力な OOD サンプルを処理するのが困難です。一部の信頼性の低いサンプルは、半教師あり学習で使用されるしきい値を適用することで除外できますが、すべての強力な OOD サンプルが除外されるという保証はまだありません。
- 分布調整に基づく方法は、ターゲット ドメインの分布を推定するために強力な OOD サンプルを計算するときに影響を受けます。グローバル分布アライメント [1] とクラス分布アライメント [2] の両方が影響を受け、不正確なフィーチャ分布アライメントにつながる可能性があります。
既存の TTT 手法の失敗の潜在的な原因を解決するために、2 つの技術を組み合わせて自己環境下でのオープンワールド TTT の堅牢性を向上させる手法を提案します。 - トレーニング フレームワーク。
まず、自己トレーニングされたバリアントで TTT のベースラインを構築します。つまり、ソース ドメイン プロトタイプをクラスター センターとしてターゲット ドメインでクラスタリングします。誤った擬似ラベルを使用した強力な OOD に対する自己トレーニングの影響を軽減するために、強力な OOD サンプルを拒否するハイパーパラメーターを使用しないメソッドを設計します。
弱い OOD サンプルと強い OOD サンプルの特性をさらに分離するために、分離された強い OOD サンプルを選択することでプロトタイプ プールを拡張できるようにします。したがって、自己トレーニングにより、強力な OOD サンプルが、新しく拡張された強力な OOD プロトタイプの周囲に密なクラスターを形成できるようになります。これにより、ソース ドメインとターゲット ドメイン間の配布の調整が容易になります。さらに、確証バイアスのリスクを軽減するために、世界的な分布の調整を通じて自己訓練を定期的に行うことを提案します。
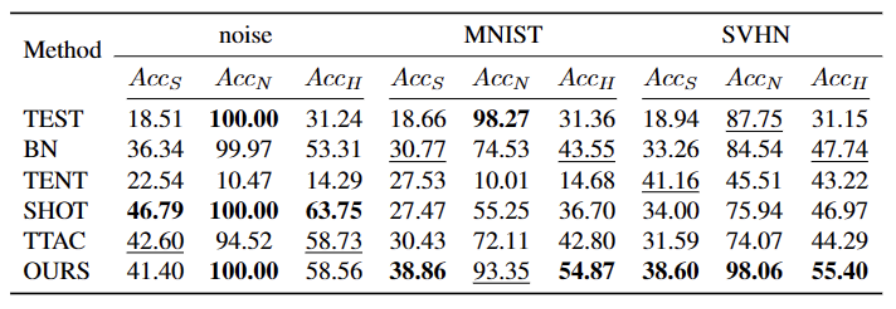
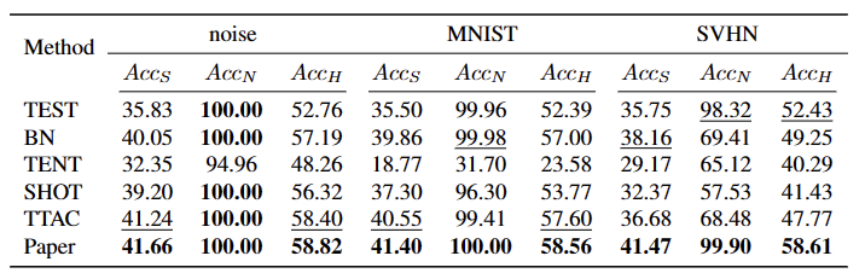
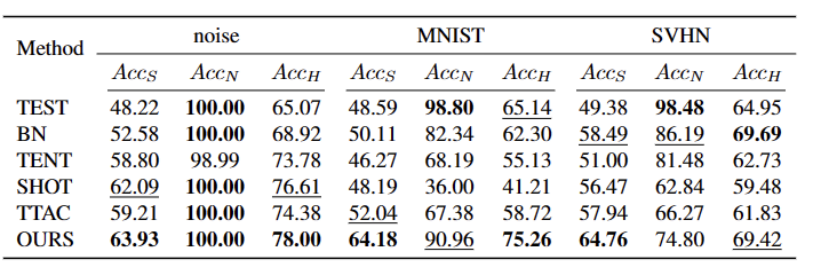
最後に、オープンワールド TTT シナリオを合成するために、CIFAR10-C、CIFAR100-C、ImageNet-C、VisDA-C、ImageNet-R、Tiny-ImageNet を使用します。 、MNIST および SVHN データセットを使用し、一方のデータセットを弱い OOD として、もう一方のデータセットを強い OOD として利用してベンチマーク データセットを確立します。私たちはこのベンチマークをオープンワールド テスト セグメント トレーニング ベンチマークと呼び、これにより、より現実的なシナリオでのテスト セグメント トレーニングの堅牢性に焦点を当てた今後の作業が促進されることを期待しています。
#方法
この論文では、提案する方法を 4 つのパートに分けて紹介します
1 ) オープンワールドでのテスト セグメント のトレーニング タスクの設定 の概要。
#2) コンテンツを クラスター分析 に書き換えて TTT を実装する方法と、オープンワールドのテスト時トレーニング用にプロトタイプを拡張する方法について説明します。
3) 動的プロトタイプ拡張のためのターゲット ドメイン データの使用方法を紹介します。
4) ディストリビューション調整を、書き直されたコンテンツと組み合わせて導入します: 強力なオープンワールドのテスト時トレーニングを実現するクラスター分析。
タスク設定
TTT の目的は、ソース ドメインの事前トレーニング済みモデルをターゲット ドメインに適応させることであり、ターゲット ドメインではソース ドメインに対して分散移行が行われる場合があります。標準のクローズドワールド TTT では、ソース ドメインとターゲット ドメインのラベル スペースは同じです。ただし、オープンワールド TTT では、ターゲット ドメインのラベル スペースにソース ドメインのターゲット スペースが含まれます。これは、ターゲット ドメインにまだ見たことのない新しいセマンティック カテゴリがあることを意味します。TTT 定義間のギャップを避ける 混乱を避けるため、評価には TTAC [2] で提案されている逐次テスト時間トレーニング (sTTT) プロトコルを採用します。 sTTT プロトコルでは、テスト サンプルが順次テストされ、テスト サンプルの小さなバッチを観察した後にモデルの更新が実行されます。タイムスタンプ t に到着するテスト サンプルの予測は、t k (k は 0 より大きい) に到着するテスト サンプルの影響を受けません。
内容を次のように書き換えました: クラスター分析
ドメイン適応タスクでのクラスター化を使用した作業に触発されました [3、4]では、テスト セグメントのトレーニングを、ターゲット ドメイン データ内のクラスター構造を発見するものとして扱います。代表的なプロトタイプをクラスター中心として特定することにより、クラスター構造がターゲット ドメイン内で特定され、テスト サンプルをプロトタイプの 1 つの近くに埋め込むことが推奨されます。書き換えられた内容は次のとおりです。 クラスター分析の目標は、次の式に示すように、サンプルとクラスター中心間のコサイン類似度の負の対数尤度損失を最小限に抑えることと定義されます。
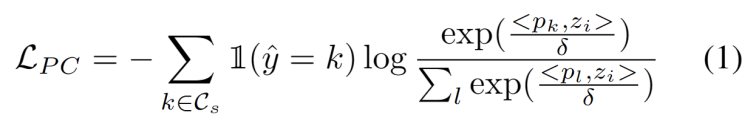
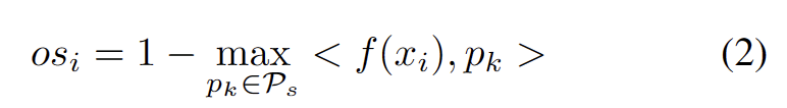
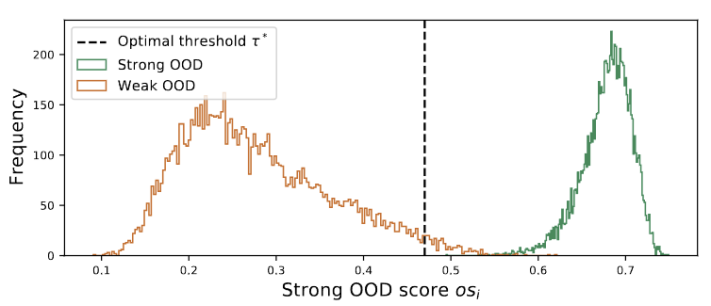
図 3 に示すように、外れ値が二峰性分布に従っていることがわかります。したがって、固定のしきい値を指定する代わりに、2 つの分布を分離する最良の値として最適しきい値を定義します。具体的には、この問題は外れ値を 2 つのクラスターに分割するものとして定式化でき、最適なしきい値は のクラスター内分散を最小化します。次の式の最適化は、0 から 1 までのすべての可能なしきい値を 0.01 刻みで徹底的に検索することで効率的に実現できます。 動的なプロトタイプの拡張 強力な OOD プロトタイプ プールを拡張するには、次のことが必要です。テストサンプルを評価するために、ソースドメインと強力な OOD プロトタイプを同時に検討する必要があります。データからクラスターの数を動的に推定するために、以前の研究では同様の問題が調査されてきました。決定論的ハード クラスタリング アルゴリズム DP-means [5] は、既知のクラスター中心までのデータ ポイントの距離を測定することによって開発され、その距離がしきい値を超えると、新しいクラスターが初期化されます。 DP 平均は、K 平均目標の最適化と同等であることが示されていますが、クラスター数に追加のペナルティがあり、動的なプロトタイプ拡張のための実行可能なソリューションを提供します。 追加のハイパーパラメータを推定する困難を軽減するために、まず、既存のソース ドメイン プロトタイプと強力な OOD プロトタイプに最も近い距離として、拡張された強力な OOD スコアを持つテスト サンプルを次のように定義します。が続きます。したがって、このしきい値を超えてサンプルをテストすると、新しいプロトタイプが構築されます。近くのテストサンプルを追加しないようにするために、このプロトタイプの拡張プロセスを段階的に繰り返します。 他の強力な OOD プロトタイプが特定されると、テスト サンプルのリライトをクラスター分析の損失として定義し、2 つの要素を考慮します。まず、既知のクラスに分類されたテスト サンプルは、プロトタイプに近く、他のプロトタイプからは遠くに埋め込まれる必要があります。これが K クラス分類タスクを定義します。第 2 に、強力な OOD プロトタイプとして分類されたテスト サンプルは、K 1 クラス分類タスクを定義するソース ドメイン プロトタイプから遠く離れている必要があります。これらの目標を念頭に置いて、内容を次のように書き直します。 クラスター分析の損失は次のように定義されます。 分散配置制約とは、デザインまたはレイアウト内の要素が特定の方法で配置および位置合わせされる必要があることを意味します。この制約は、Web デザイン、グラフィック デザイン、スペース レイアウトなど、さまざまなシナリオに適用できます。分散配置制約を使用すると、要素間の関係がより明確かつ統一され、デザイン全体の美しさと読みやすさが向上します。 よく知られているように、自己トレーニングはエラーの影響を受けやすい 疑似ラベルの影響。ターゲット ドメインが OOD サンプルで構成されている場合、状況はさらに悪化します。失敗のリスクを軽減するために、次のように、自己学習のための正則化として分布アラインメント [1] をさらに使用します。 合成的に破損したデータセットやスタイルを含む、5 つの異なる OWTTT ベンチマーク データセットでテストしました。さまざまなデータセット。実験では主に、弱OOD分類精度ACCS、強OOD分類精度ACCN、およびその2つの調和平均ACCH #の3つの評価指標を使用します。書き換える必要がある内容は次のとおりです。 Cifar10-C データセット内のさまざまなメソッドのパフォーマンスを以下の表に示します。 書き換えられる内容は次のとおりです: Cifar100 -C データセット内のさまざまなメソッドのパフォーマンスを次の表に示します。 書き換える必要がある内容ImageNet-C データセットでは、メソッドのパフォーマンスは次の表に示されています。 #表 4 ImageNet-R データ セットに対するさまざまなメソッドのパフォーマンス 表5 VisDA-C データセットでのさまざまなメソッドのパフォーマンス 上の表に示すように、ほぼすべてのデータセットで現在の最良のメソッドと比較して、私たちのメソッドは大幅に向上しました。強い OOD サンプルを効果的に識別し、弱い OOD サンプルの分類への影響を軽減できます。したがって、オープンワールドのシナリオでは、私たちの方法はより堅牢な TTT を実現できます この論文では、最初にオープンワールドを提案します。テスト セグメント トレーニング (OWTTT) の問題と設定。ソース ドメイン サンプルからのセマンティック オフセットを持つ強力な OOD サンプルを含むターゲット ドメイン データを処理するときに、既存の方法が困難に遭遇することを指摘し、動的プロトタイプ拡張ベースの自己トレーニングを提案します。この方法は上記の問題を解決します。私たちは、この研究が、より堅牢な TTT 手法を探求するための TTT に関するその後の研究に新たな方向性を提供できることを願っています。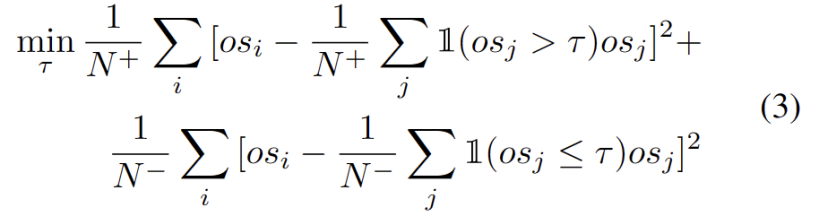
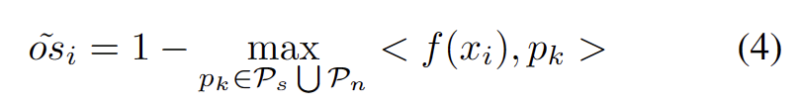
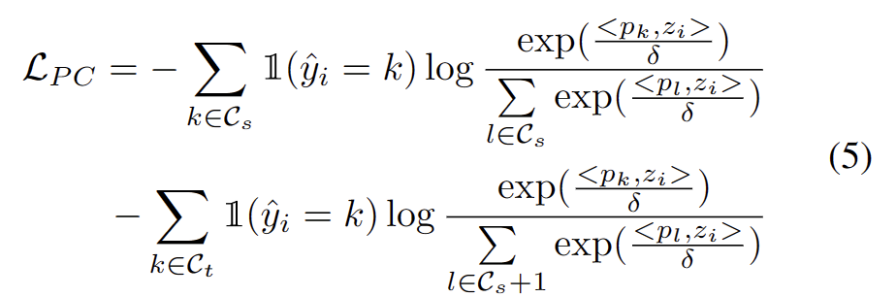
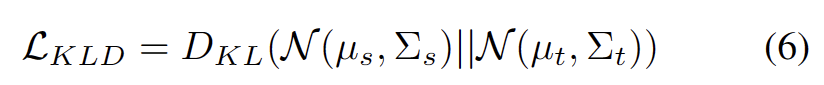
実験


概要
以上が動的プロトタイピング拡張機能を備えた自己トレーニング方法を使用して、オープンワールドのテスト セグメントのトレーニング手法を探索します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7715
7715
 15
1641
14
1395
52
1289
25
1232
29
15
1641
14
1395
52
1289
25
1232
29

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 furmark についてどう思いますか? - furmark はどのように資格があるとみなされますか?
Mar 19, 2024 am 09:25 AM
furmark についてどう思いますか? - furmark はどのように資格があるとみなされますか?
Mar 19, 2024 am 09:25 AM
furmark についてどう思いますか? 1. メインインターフェイスで「実行モード」と「表示モード」を設定し、「テストモード」も調整して「開始」ボタンをクリックします。 2. しばらく待つと、グラフィックス カードのさまざまなパラメータを含むテスト結果が表示されます。ファーマークはどのように資格を取得しますか? 1. ファーマークベーキングマシンを使用し、約 30 分間結果を確認します。室温 19 度、ピーク値は 87 度で、基本的に 85 度前後で推移します。大型シャーシ、シャーシ ファン ポートが 5 つあり、前面に 2 つ、上部に 2 つ、背面に 1 つありますが、ファンは 1 つだけ取り付けられています。すべてのアクセサリはオーバークロックされていません。 2. 通常の状況では、グラフィックス カードの通常の温度は「30 ~ 85℃」である必要があります。 3. 周囲温度が高すぎる夏でも、通常の温度は「50〜85℃」です
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
何?ズートピアは国産AIによって実現するのか?ビデオとともに公開されたのは、「Keling」と呼ばれる新しい大規模な国産ビデオ生成モデルです。 Sora も同様の技術的ルートを使用し、自社開発の技術革新を多数組み合わせて、大きく合理的な動きをするだけでなく、物理世界の特性をシミュレートし、強力な概念的結合能力と想像力を備えたビデオを制作します。データによると、Keling は、最大 1080p の解像度で 30fps で最大 2 分の超長時間ビデオの生成をサポートし、複数のアスペクト比をサポートします。もう 1 つの重要な点は、Keling は研究所が公開したデモやビデオ結果のデモンストレーションではなく、ショートビデオ分野のリーダーである Kuaishou が立ち上げた製品レベルのアプリケーションであるということです。さらに、主な焦点は実用的であり、白紙小切手を書かず、リリースされたらすぐにオンラインに移行することです。Ke Ling の大型モデルは Kuaiying でリリースされました。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
 総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
大規模言語モデル (LLM) を人間の価値観や意図に合わせるには、人間のフィードバックを学習して、それが有用で、正直で、無害であることを確認することが重要です。 LLM を調整するという点では、ヒューマン フィードバックに基づく強化学習 (RLHF) が効果的な方法です。 RLHF 法の結果は優れていますが、最適化にはいくつかの課題があります。これには、報酬モデルをトレーニングし、その報酬を最大化するためにポリシー モデルを最適化することが含まれます。最近、一部の研究者はより単純なオフライン アルゴリズムを研究しており、その 1 つが直接優先最適化 (DPO) です。 DPO は、RLHF の報酬関数をパラメータ化することで、選好データに基づいてポリシー モデルを直接学習するため、明示的な報酬モデルの必要性がなくなります。この方法は簡単で安定しています
 わずか 250 ドルで、Hugging Face のテクニカル ディレクターが Llama 3 を段階的に微調整する方法を教えます
May 06, 2024 pm 03:52 PM
わずか 250 ドルで、Hugging Face のテクニカル ディレクターが Llama 3 を段階的に微調整する方法を教えます
May 06, 2024 pm 03:52 PM
Meta が立ち上げた Llama3、MistralAI が立ち上げた Mistral および Mixtral モデル、AI21 Lab が立ち上げた Jamba など、おなじみのオープンソースの大規模言語モデルは、OpenAI の競合相手となっています。ほとんどの場合、モデルの可能性を最大限に引き出すには、ユーザーが独自のデータに基づいてこれらのオープンソース モデルを微調整する必要があります。単一の GPU で Q-Learning を使用して、大規模な言語モデル (Mistral など) を小規模な言語モデルに比べて微調整することは難しくありませんが、Llama370b や Mixtral のような大規模なモデルを効率的に微調整することは、これまで課題として残されています。 。したがって、HuggingFace のテクニカル ディレクター、Philipp Sch 氏は次のように述べています。
