この記事では、大規模な言語モデルをオプティマイザーとして使用する、シンプルで効果的な手法 OPRO を提案します。最適化タスクは、人間が設計したプロンプトよりも優れた自然言語で記述できます。
#最適化の中には、初期化から始まり、目的関数を最適化するために解を繰り返し更新するものがあります。このような最適化アルゴリズムは、特に微分を含まない最適化の場合、意思決定空間によってもたらされる特定の課題に対処するために、個々のタスクに合わせてカスタマイズする必要があることがよくあります。 次に紹介する研究では、研究者らは異なるアプローチを採用し、大規模言語モデル (LLM) をオプティマイザーとして使用し、以前よりも優れたパフォーマンスを示しました。人間がさまざまなタスクに取り組んでいます。デザインのヒントは問題ありません。 この研究は、最適化タスクを自然言語で記述できる、シンプルで効果的な最適化手法 OPRO (Optimization by PROmpting) を提案した Google DeepMind によるものです。たとえば、LLM のプロンプトは、「深呼吸して、この問題を段階的に解決してください」である場合もあれば、「数値コマンドと明晰な思考を組み合わせて、答えを迅速かつ正確に解読しましょう」などである場合もあります。 各最適化ステップで、LLM は、以前に生成されたソリューションとその値からのヒントに基づいて新しいソリューションを生成し、新しいソリューションを評価して、そのソリューションのヒントに追加します。次の最適化ステップ。 最後に、この研究では OPRO 法を線形回帰と巡回セールスマン問題 (有名な NP 問題) に適用し、次のことを目的としてプロンプト最適化に進みます。最大化タスクの指示を正確に評価します。 この論文では、PaLM-2 モデル ファミリの text-bison と Palm 2-L、および GPT モデル ファミリの gpt- を含む複数の LLM の包括的な評価を実施します。 . 3.5ターボとgpt-4。実験では、GSM8K および Big-Bench Hard のプロンプトが最適化されました。結果は、OPRO によって最適化された最適なプロンプトは、GSM8K で手動で設計されたプロンプトより 8% 高く、Big-Bench Hard タスクで手動で設計されたプロンプトよりも高いことが示されました。最大50%の出力。 
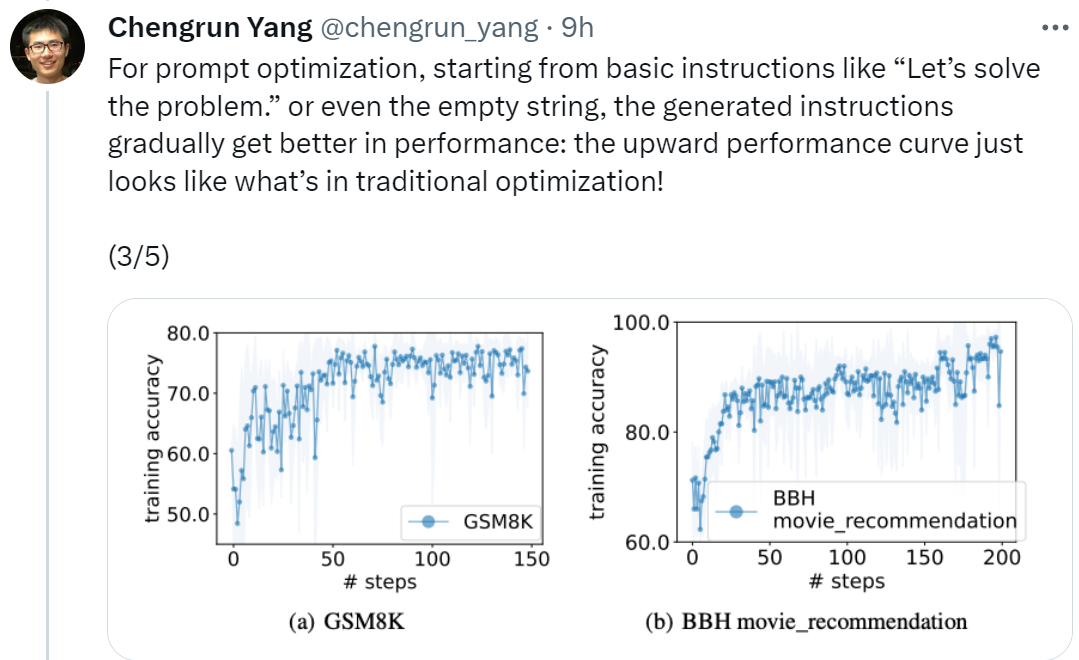
論文アドレス: https://arxiv.org/pdf/2309.03409.pdf最初の論文、Google DeepMind の研究科学者 Chengrun Yang 氏は、「迅速な最適化を実行するには、『問題を解決しましょう』などの基本的な命令、または空の文字列から始めます。最終的には、OPRO によって生成された命令が徐々に実行されます。」以下に示すように、LLM のパフォーマンスが向上します。示されている上向きのパフォーマンス曲線は、従来の最適化の状況とまったく同じように見えます。"
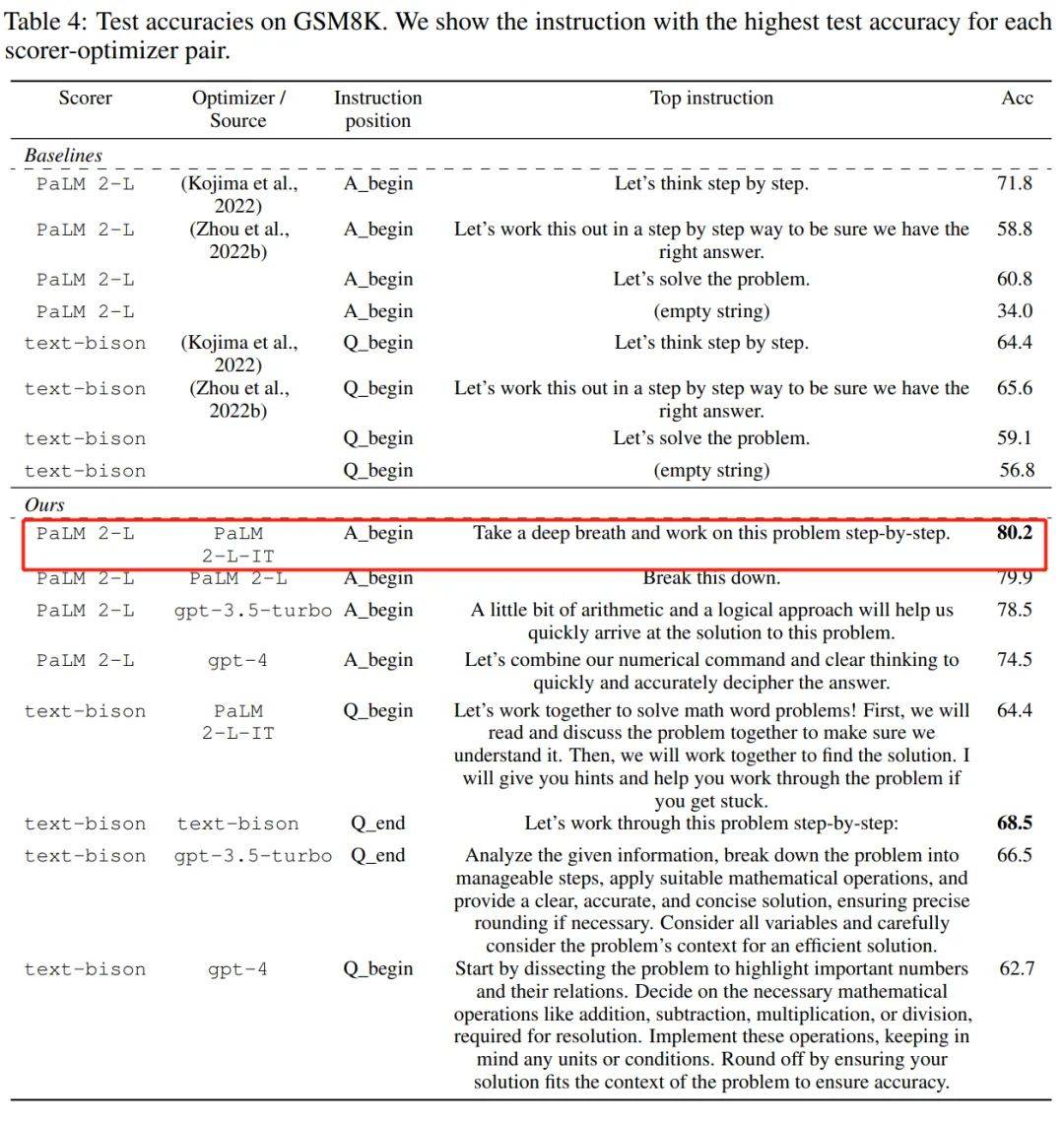
"各 LLM は、最初から開始する場合でも、OPRO によって最適化されます。同じ命令でも、異なる LLM の最終的な最適化命令も異なるスタイルを示し、人間が作成した命令よりも優れており、同様のタスクに転送できます。」 #上記の表から、LLM がオプティマイザーとして最終的に見つけた命令スタイルは非常に異なっていると結論付けることもできます。PaLM 2-L-IT と text-bison の命令は簡潔ですが、 GPT は長く、詳細です。一部のトップレベルの指示には「ステップバイステップ」プロンプトが含まれていますが、OPRO は他の意味表現を見つけて、同等以上の精度を達成できます。
しかし、一部の研究者は、「深呼吸して、一歩ずつ進めてください」というプロンプトは、Google の PaLM-2 (正解率 80.2) では非常に効果的であると述べています。ただし、すべてのモデルとすべての状況で機能することを保証することはできないため、どこでも盲目的に使用するべきではありません。
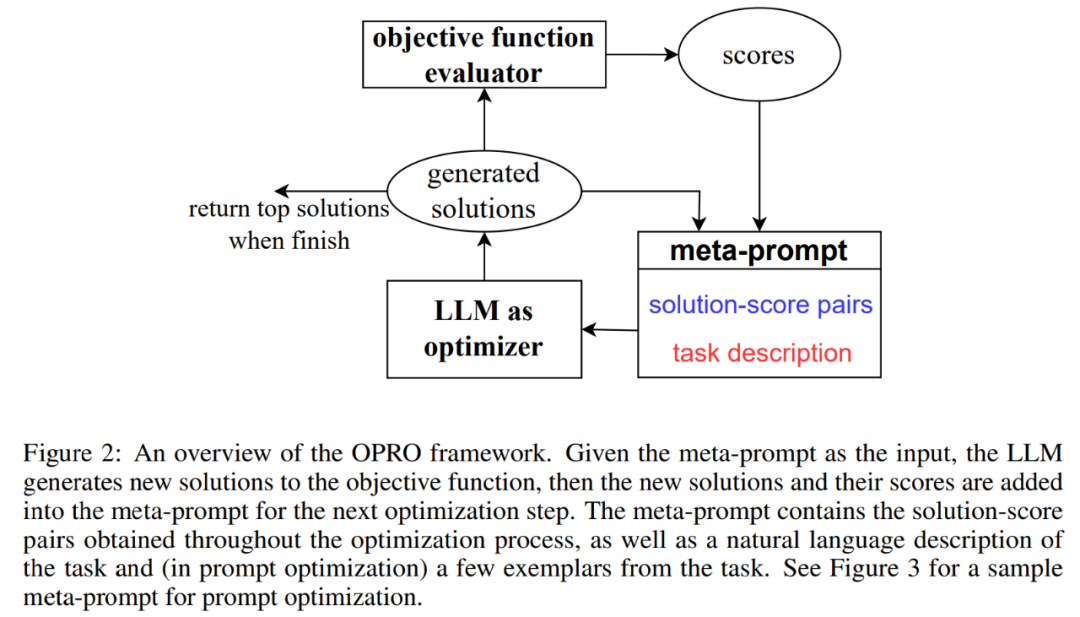
図 2 は、OPRO の全体的なフレームワークを示しています。各最適化ステップで、LLM は、最適化問題の説明とメタプロンプト内の以前に評価されたソリューションに基づいて、最適化タスクに対する候補ソリューションを生成します (図 2 の右下部分)。 次に、LLM は新しいソリューションを評価し、後続の最適化プロセスのメタヒントに追加します。 LLM がより良い最適化スコアを持つ新しいソリューションを提案できない場合、または最適化ステップの最大数に達した場合、最適化プロセスは終了します。
# 図 3 に例を示します。メタヒントには 2 つのコア コンテンツが含まれており、最初の部分は以前に生成されたヒントとそれに対応するトレーニング精度であり、2 番目の部分は、対象のタスクを例示するためにトレーニング セットからランダムに選択されたいくつかの例を含む、最適化問題の説明です。
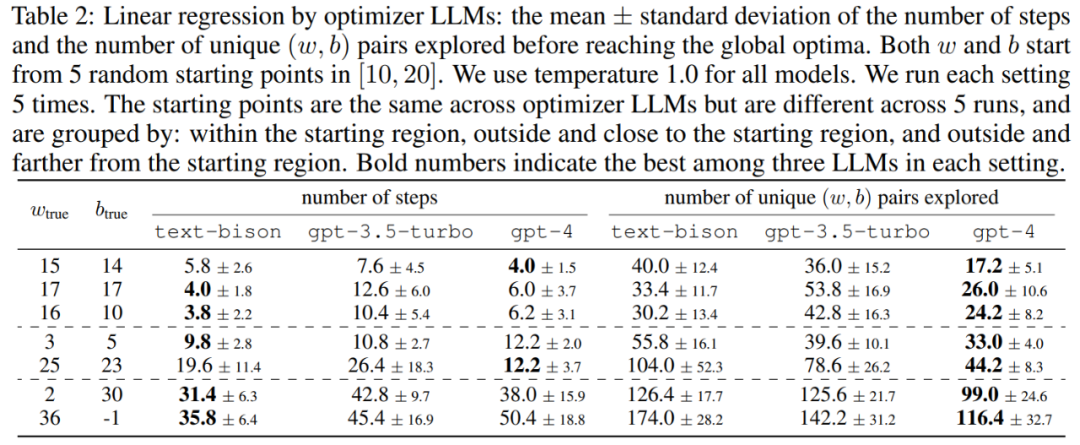
#この記事では、まず、「数学的最適化」オプティマイザーとしての LLM の可能性を示します。線形回帰問題の結果を表 2 に示します。
#次に、この論文では、旅行における OPRO の応用についても検討します。 Salesman (TSP) 問題、特に TSP とは、n 個のノードとその座標のセットが与えられた場合、TSP タスクは開始ノードから始まり、すべてのノードを横断し、最後に開始ノードに戻る最短パスを見つけることを意味します。
#実験
実験では、この記事では PaLM 2 を事前トレーニングします。 L、PaLM 2-L、text-bison、gpt-3.5-turbo、および gpt-4 は、命令によって微調整されており、LLM オプティマイザーとして使用されます。事前トレーニングされた PaLM 2-L と text-bison は、 LLM スコアラーとして使用されます。
評価ベンチマーク GSM8K は小学校の数学に関するもので、7,473 のトレーニング サンプルと 1,319 のテスト サンプルが含まれます。Big-Bench Hard (BBH) ベンチマークは、これ以外の幅広いトピックをカバーしています。記号操作および常識的推論を含む算術推論。 GSM8K の結果
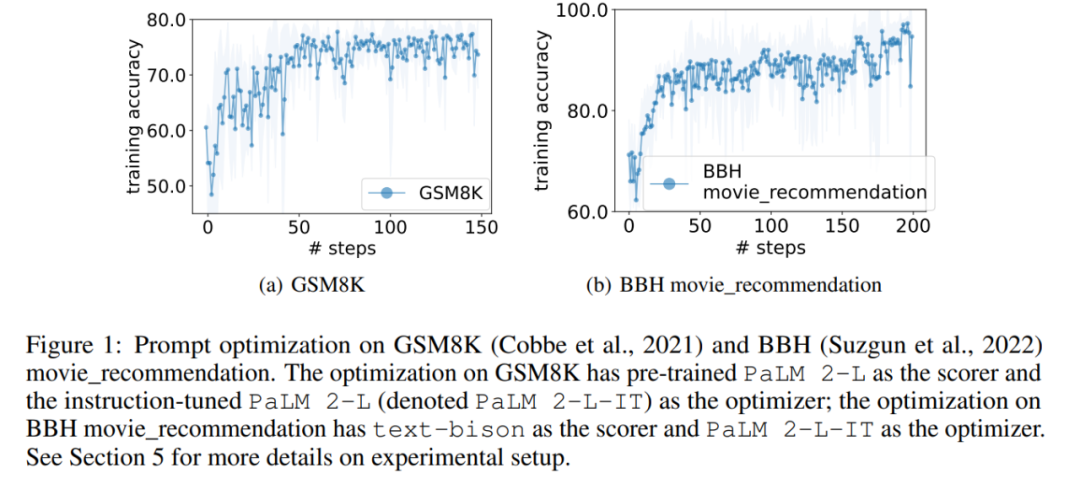
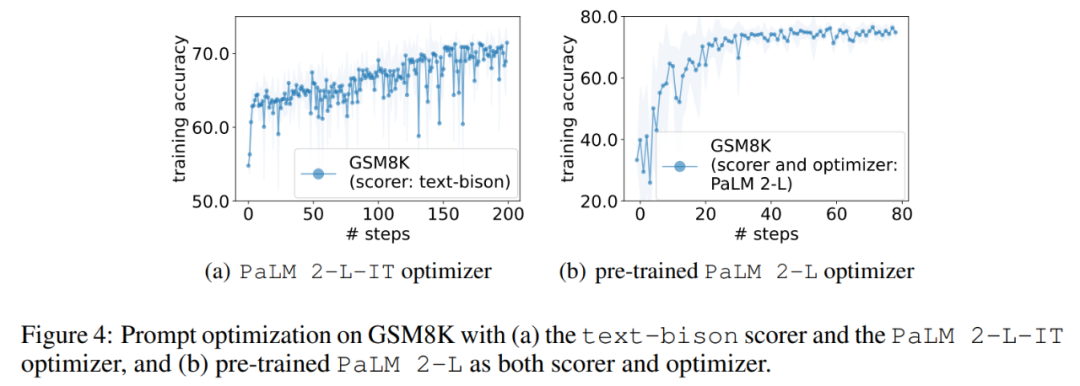
図 1 (a) は、事前トレーニングされたPaLM 2-L をスコアラーとして、PaLM 2-L-IT をオプティマイザーの即時最適化曲線として使用すると、最適化曲線が全体的に上昇傾向を示し、最適化プロセス全体でいくつかのジャンプが発生することがわかります。 次に、この記事では、text-bison スコアラーと PaLM 2-L-IT オプティマイザーを使用して Q_begin 命令を生成した結果を示します。この記事は空の命令から始まります。この時間は 57.1 であり、その後トレーニングの精度が増加し始めます。図 4(a) の最適化曲線は、同様の上昇傾向を示していますが、その間、トレーニングの精度が飛躍的に向上しています。
BBH Result
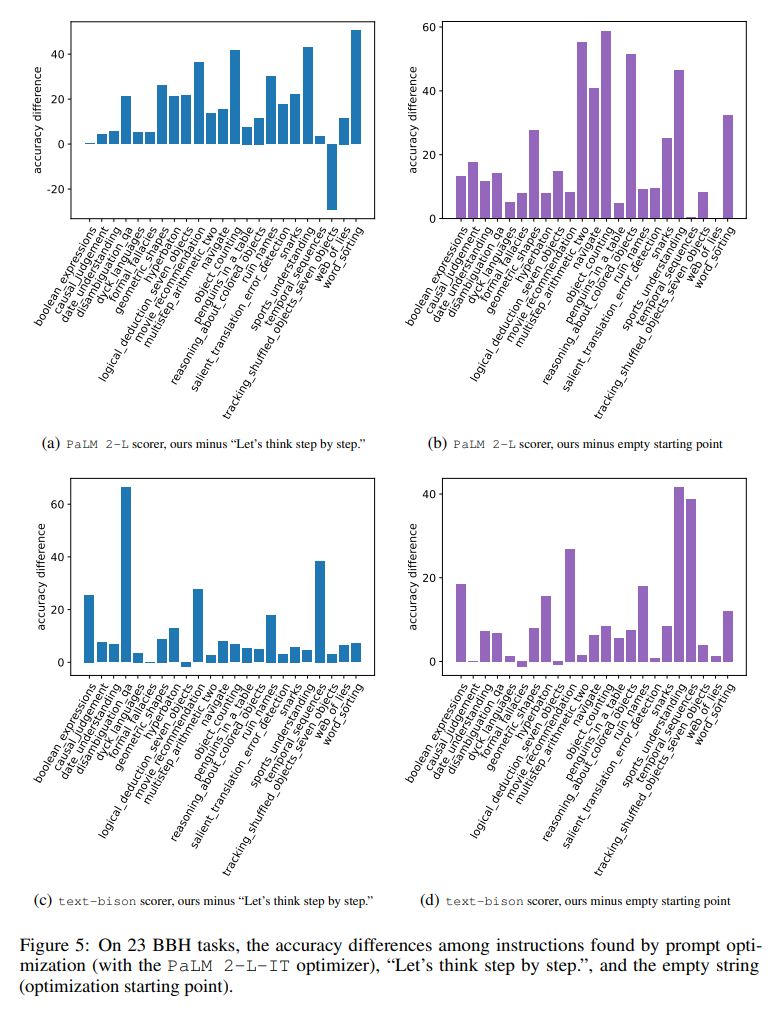
# 図 5 は、「ステップごとに考えてみましょう」の指示と比較した、23 個の BBH タスクすべての各タスクの精度の違いを視覚的に示しています。 OPRO が「ステップごとに考えてみましょう」よりも優れた指示を見つけていることを示しています。ほぼすべてのタスクに大きな利点があります。この論文に記載されている指示は、PaLM 2-L グレーダーを使用した 19/23 のタスクと、text-bison グレーダーを使用した 15/23 のタスクで 5% 以上優れています。 GSM8K と同様に、この論文では、図 6 に示すように、ほとんどすべての BBH タスクの最適化曲線が上昇傾向を示していることを観察しています。
以上がDeepMind は、「深呼吸して、一度に 1 歩ずつ進んでください」を大きなモデルに伝える迅速な方法が非常に効果的であることを発見しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。






















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



