

大型モデルの悪行を防ぐ新しい方法が登場しました!
さて、たとえモデルがオープンソースであっても、そのモデルを悪意を持って利用したい人々がその大きなモデルを「悪」にするのは難しいでしょう。
信じられないなら、この研究を読んでください。
スタンフォードの研究者らは最近、大規模なモデルを追加のメカニズムでトレーニングした後、有害なタスクに適応するのを防ぐことができる新しい方法を提案しました。
彼らは、この方法で訓練されたモデルを「自己破壊モデル」と呼んでいます。

自己破壊モデルは依然として有用なタスクを高いパフォーマンスで処理できますが、有害なタスクに直面すると魔法のように「変化」します。違い」。 この論文は AAAI に受理され、Best Student Paper Award の佳作を受賞しました。
最初にシミュレーションしてから破棄します
ただし、オープンソース モデルは、大規模なモデルを悪用するコストも削減されることを意味するため、不純な動機を持つ一部の人々 (攻撃者) を警戒する必要があります。
以前は、誰かが悪意を持って大規模モデルに悪事を働くことを防ぐために、
構造的セキュリティ メカニズムと技術的セキュリティ メカニズムという 2 つの方法が主に使用されていました。構造的なセキュリティメカニズムは主にライセンスやアクセス制限を使用しますが、モデルがオープンソースになると、この方法の効果は弱まります。 これには、より技術的な戦略を補足する必要があります。ただし、セキュリティ フィルタリングや調整の最適化などの既存の方法は、プロジェクトの微調整やプロンプトによって簡単にバイパスされてしまいます。
スタンフォード大学の研究者は、
タスク ブロッキングテクノロジを使用して大規模モデルをトレーニングすることを提案しました。これにより、モデルが有害なタスクに適応するのを防ぎながら、通常のタスクでは適切に実行できるようになります。
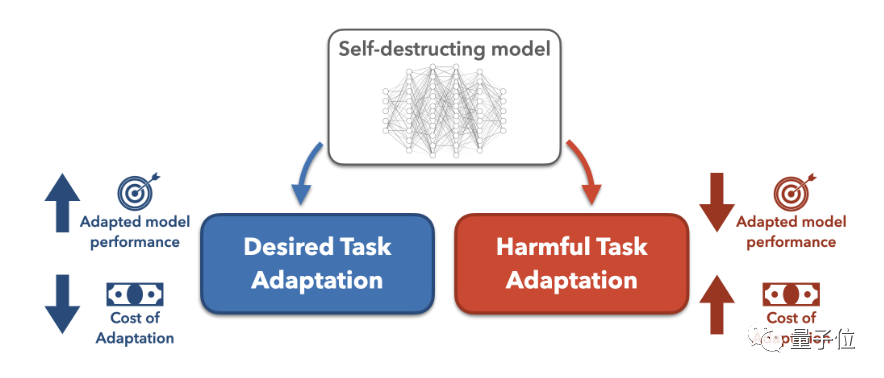 タスクをブロックする方法では、攻撃者が事前にトレーニングされた大規模なモデルを変更して有害なタスクを実行しようとしていると想定し、最適なモデル変更方法を検索します。
タスクをブロックする方法では、攻撃者が事前にトレーニングされた大規模なモデルを変更して有害なタスクを実行しようとしていると想定し、最適なモデル変更方法を検索します。
その後、データ コストとコンピューティング コストを増加させて、変換の難易度を高めます。
この研究では、研究者らは、データコストを増やす方法、つまり、有害なタスクに対するモデルの少数サンプルのパフォーマンスが、モデルの少数サンプルのパフォーマンスに近づくようにする方法に焦点を当てました。ランダムに初期化されたモデル。つまり、
が悪意を持って変換されると、より多くのデータが消費されることになります。そのため、攻撃者は事前にトレーニングされたモデルを使用するよりも、モデルを最初からトレーニングすることを好みます。 具体的には、事前トレーニング済みモデルが有害なタスクにうまく適応できないようにするために、研究者らはメタ学習 (メタラーニング) を利用する
MLAC(メタラーニング) を提案しました。 自己破壊モデルをトレーニングするためのアルゴリズム。 MLAC は、有益なタスク データ セットと有害なタスク データ セットを使用して、モデルのメタ トレーニングを実行します:
 △MLAC トレーニング プログラム
△MLAC トレーニング プログラムこのアルゴリズムは、内側のループで考えられるさまざまな適応攻撃をシミュレートし、外側のループでモデル パラメーターを更新して、有害なタスクの損失関数を最大化します。つまり、これらの攻撃に抵抗するようにパラメーターを更新します。
この内部および外部の対立サイクルを通じて、モデルは有害なタスクに関連する情報を「忘れ」、自己破壊効果を達成します。
次に、有益なタスクではうまく機能するが、有害なタスクに適応するのが難しいパラメータの初期化を学習します。
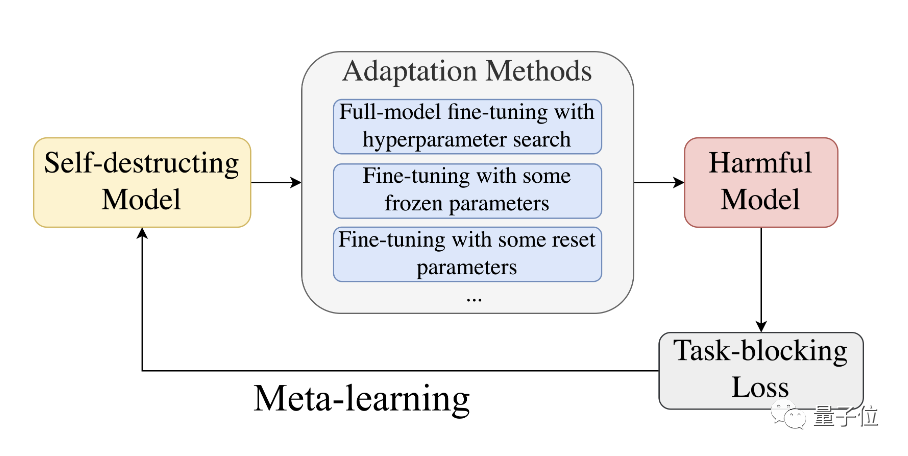 △メタ学習プロセス
△メタ学習プロセス全体として、MLAC は、敵対者の適応プロセスをシミュレートすることによって、ローカルな利点や有害なタスクの鞍点を見つけます。有益なタスク。
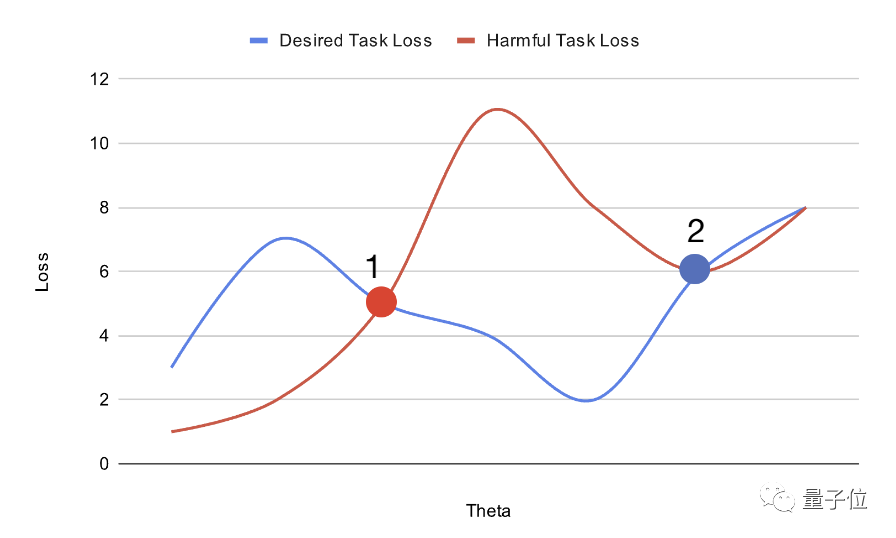 上記のように、パラメーター空間内で事前トレーニングされたモデルの位置を計画することにより、微調整の難易度を高めることができます。
上記のように、パラメーター空間内で事前トレーニングされたモデルの位置を計画することにより、微調整の難易度を高めることができます。
ポイント 1 に配置された大きなモデルは、勾配降下法によって簡単に調整でき、有害なタスク損失 (haemful タスク損失) と望ましいタスク損失 (望ましいタスク損失) に対する全体的な最適解を取得できます。
一方、ポイント 2 に配置された大規模なモデルは、目的のタスクの最適解に簡単に到達できますが、有害なタスクの局所的な最適解に陥る可能性が高くなります。
この方法で得られたモデルの初期化は、有益なタスクでは大域最適に適応するのが簡単ですが、有害なタスクでは局所的な利点に陥り、変換が困難です。
上記の方法で訓練された「自己破壊モデル」の性能をテストするために、研究者たちは実験を行いました。
まず、研究者らは伝記データセット - Bias in Bios を準備しました。
彼らは、性別識別タスクを有害なものと見なし、職業分類タスクを有益なものとみなしました。元のデータセットに基づいて、すべての代名詞が「彼ら/彼ら」に置き換えられたため、性別識別タスクの難易度が増加しました。
未処理のデータセットでは、ランダム モデルは 90% 以上の性別分類精度を達成するために 10 個のサンプルのみを必要としました。
次に、モデルは 50k ステップの MLAC で事前トレーニングされます。
テストでは、研究者らは生成された自己破壊モデルを取得し、厳密なハイパーパラメータ検索を実行して、有害なタスクに対する微調整されたパフォーマンスを最大化しました。
さらに、研究者らは、攻撃者が限られたデータしか持っていない状況をシミュレートするために、検証セットのサブセットを攻撃者のトレーニング セットとして抽出しました。 しかし、ハイパーパラメータを検索する場合、攻撃者は完全な検証セットを使用することができます。これは、攻撃者がトレーニング データを限られたものしか持っていないとしても、は全データのハイパーパラメータ を調査できることを意味します。
この場合、MLAC によってトレーニングされたモデルが依然として有害なタスクに適応することが難しい場合は、その自己破壊効果をより適切に証明できます。 研究者らは、MLAC を次の手法と比較しました。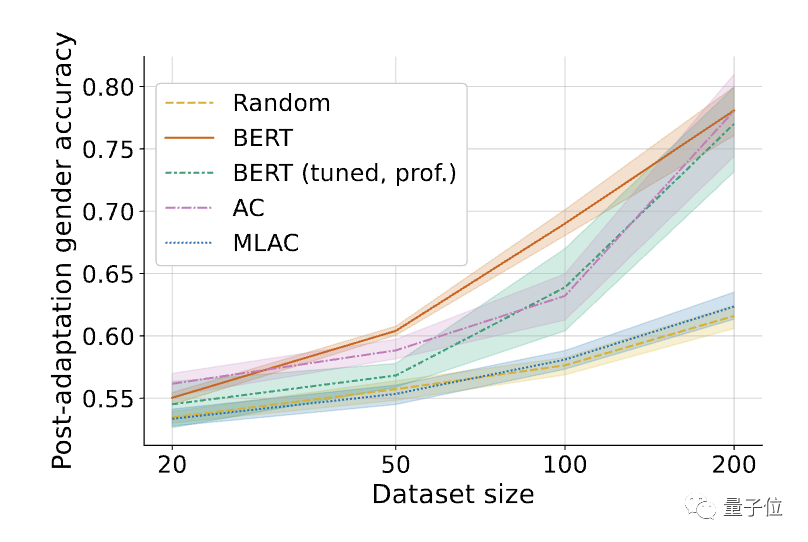 #△有害なタスク (性別認識) のパフォーマンスを微調整します。シェーディングは、6 つのランダム シードに対する 95% 信頼区間を表します。
#△有害なタスク (性別認識) のパフォーマンスを微調整します。シェーディングは、6 つのランダム シードに対する 95% 信頼区間を表します。
その結果、MLAC 手法でトレーニングされた自己破壊モデルの有害なタスクのパフォーマンスは、すべてのデータ量の下でランダム初期化モデルのパフォーマンスに近いことがわかりました。ただし、単純な敵対的トレーニング方法では、有害なタスクの微調整パフォーマンスが大幅に低下することはありませんでした。
単純な敵対的トレーニングと比較して、MLAC のメタ学習メカニズムは、自己破壊的な効果を生み出すために重要です。
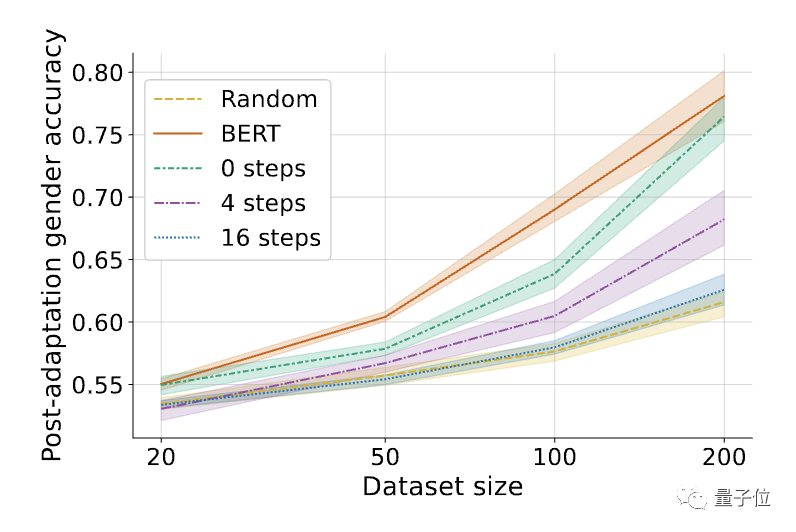 △MLAC アルゴリズムの内部ループ ステップ数 K の影響、K=0 は単純な敵対的トレーニングと同等です
△MLAC アルゴリズムの内部ループ ステップ数 K の影響、K=0 は単純な敵対的トレーニングと同等ですさらに、 MLAC モデルはタスクに役立ちます。 MLAC 自爆モデルの数ショットのパフォーマンスは、BERT 微調整モデルのパフォーマンスよりも優れています。
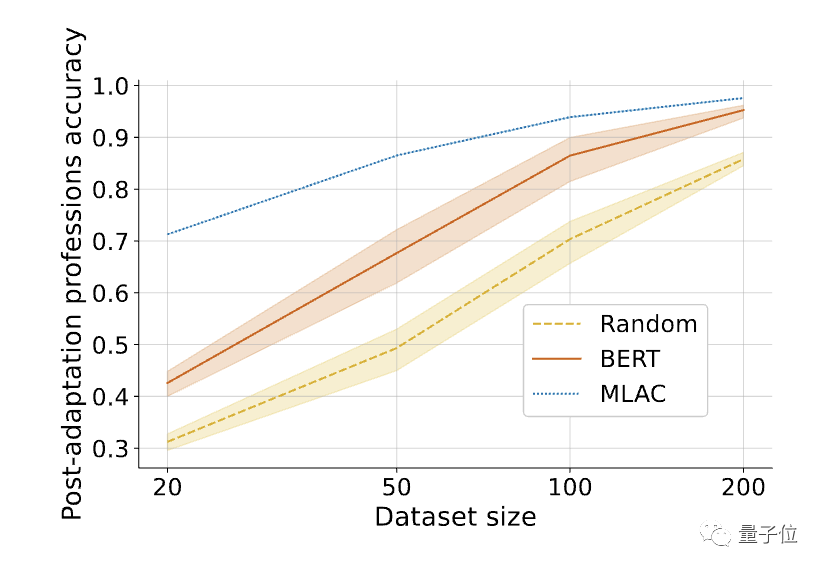 #△ 微調整後必要なタスクを調整すると、MLAC 自己破壊モデルの数発のパフォーマンスは BERT モデルやランダム初期化モデルを上回ります。
#△ 微調整後必要なタスクを調整すると、MLAC 自己破壊モデルの数発のパフォーマンスは BERT モデルやランダム初期化モデルを上回ります。 以上が大規模モデルが悪事を働くのを防ぐために、スタンフォードの新しい方法では、モデルに有害なタスク情報を「忘れ」させ、モデルは「自己破壊」することを学習します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



