

翻訳者 | 朱賢中
## Chonglou | 査読者
要約:このブログでは、検索拡張生成 ## エンジニアリング テクノロジーと呼ばれる tip# と ## について学びます。 # は、Langchain、ChromaDB、GPT 3.5 の組み合わせに基づいてこのテクノロジーを実装します。 モチベーションコンバータベースの
GPT-3 のようなモデル自然言語処理 (NLP) の出現により、自然言語処理 (NLP) の分野では大きな進歩が見られました。これらの言語モデルは人間のようなテキストを生成でき、チャットボット、コンテンツ生成、翻訳などのさまざまなアプリケーションを備えていますetc 。ただし、エンタープライズアプリケーション シナリオの専門的かつ顧客固有の情報に関しては、従来の言語モデルでは満足できない可能性があります。 ###必要とする。 一方、新しいコーパスを使用してこれらのモデルを微調整すると、費用と時間がかかる可能性があります。この課題に対処するには、取得拡張生成 (RAG: 取得拡張生成) と呼ばれる手法を使用できます。 このブログでは、この 検索拡張世代# について調査します。 ##(
RAG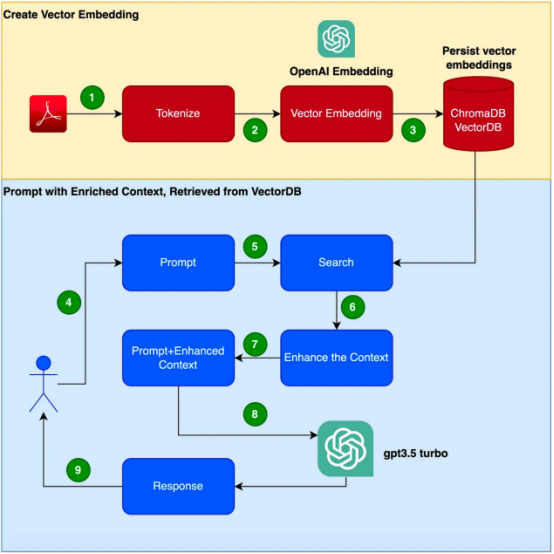
テクノロジーの仕組みと実践的なこのテクノロジーの有効性を証明する#実例との闘い。 この例では、GPT-3.5 Turbo を製品マニュアルに応答する追加のコーパスとして使用することに注意してください。 特定の製品に関する質問に応答できるチャットボットを開発するという任務を負っていると想像してください。製品には、特にエンタープライズ製品向けの独自のユーザー マニュアルがあります。 GPT-3 などの従来の言語モデルは、一般的なデータに基づいてトレーニングされることが多く、この特定の製品を理解できない場合があります。 一方、新しいコーパスを使用してモデルを微調整することは解決策であるように見えます; ただし、このアプローチはかなりのコストとリソースが必要になります。 取得拡張生成 (RAG) の概要取得拡張生成 (RAG) は、特定のドメインの問題を解決するためのより効率的な方法を提供します。状況に応じた適切な応答を生成する質問。 RAG は、新しいコーパスを使用して言語モデル全体を微調整するのではなく、検索機能を利用して、オンデマンドで関連情報にアクセスします。検索メカニズムと言語モデルを組み合わせることで、RAG は外部コンテキストを活用して応答を強化します。この外部コンテキストは、以下に示す
created## を埋め込むベクトルとして提供できます。 #この記事では、お申し込み時に #手順に従う必要があります。
Focusrite Clarett ユーザー マニュアルを追加のコーパスとして使用することに注意してください。 Focusrite Clarett は、オーディオを録音および再生するためのシンプルな USB オーディオ インターフェイスです。 リンク https://fael-downloads-prod.focusrite.com/customer/prod/downloads/Clarett 8Pre USB ユーザー ガイド V2 英語 - EN.pdf マニュアルからダウンロードして使用できます。 #実践ドリル仮想環境のセットアップ##仮想環境をセットアップしましょう
#あらゆるバージョン/ライブラリ/依存関係#を避けるためにカプセル化されていますセックス対立。 ここで、 次のコマンド を実行して、 新しい Python 仮想環境 を作成します。 :
pip install virtualenvpython3 -m venv ./venvsource venv/bin/activate
時間の都合上、## を開くときに、 #画面デザインmaywithmy
current撮影画面 スクリーンショット # #####変更されました)######。 #次に、アカウント設定に移動し、[API キーの表示] を選択します。##次に、[新しい秘密キーの作成)] を選択すると、次のようなポップアップ ウィンドウが表示されます。下に示された。 名前を指定する必要があります。これにより、キーが生成されます。

この操作
では、クリップボード Board にコピーして保存する必要がある一意のキーが生成されます。安全な 場所
場所
。 次は Python コードを書いて、上記のフローチャートに示されているものをすべて実装しましょう。ステップ。 依存ライブラリのインストールまず、
必要なさまざまな依存関係をインストールしましょう。次のライブラリを使用します: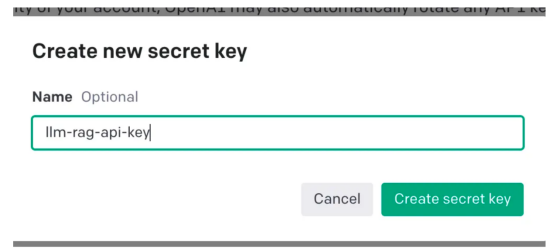
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
一旦成功安装了这些依赖项,请创建一个环境变量来存储在最后一步中创建的OpenAI密钥。
export OPENAI_API_KEY=<openai-key></openai-key>
接下来,让我们开始编程。
在下面的代码中,我们会引入所有需要使用的依赖库和函数
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
在下面的代码中,阅读PDF,将文档标记化并拆分为标记。
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)在下面的代码中,我们将创建一个色度集合,一个用于存储色度数据库的本地目录。然后,我们创建一个向量嵌入并将其存储在ChromaDB数据库中。
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData, embeddings, collection_name=collection_name, persist_directory=persist_directory )vectDB.persist()执行此代码后,您应该会看到创建了一个存储向量嵌入的文件夹。
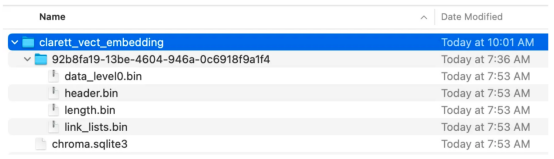
现在,我们将向量嵌入存储在ChromaDB中。下面,让我们使用LangChain中的ConversationalRetrievalChain API来启动聊天历史记录组件。我们将传递由GPT 3.5 Turbo启动的OpenAI对象和我们创建的VectorDB。我们将传递ConversationBufferMemory,它用于存储消息。
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm( OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
既然我们已经初始化了会话检索链,那么接下来我们就可以使用它进行聊天/问答了。在下面的代码中,我们接受用户输入(问题),直到用户键入“done”。然后,我们将问题传递给LLM以获得回复并打印出来。
chat_history = []qry = ""while qry != 'done': qry = input('Question: ') if qry != exit: response = chatQA({"question": qry, "chat_history": chat_history}) print(response["answer"])这是输出的屏幕截图。

正如你从本文中所看到的,检索增强生成是一项伟大的技术,它将GPT-3等语言模型的优势与信息检索的能力相结合。通过使用特定于上下文的信息丰富输入,检索增强生成使语言模型能够生成更准确和与上下文相关的响应。在微调可能不实用的企业应用场景中,检索增强生成提供了一种高效、经济高效的解决方案,可以与用户进行量身定制、知情的交互。
朱先忠是51CTO社区的编辑,也是51CTO专家博客和讲师。他还是潍坊一所高校的计算机教师,是自由编程界的老兵
原文标题:Prompt Engineering: Retrieval Augmented Generation(RAG),作者:A B Vijay Kumar
以上がLangchain、ChromaDB、GPT 3.5 に基づいた検索拡張生成の実装の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



