

Taotian Group と Aicheng Technology は、9 月 12 日にオープンソースの大規模モデル トレーニング フレームワーク Megatron-LLaMA を正式にリリースしました。このフレームワークの目標は、テクノロジー開発者が大規模な言語モデルのトレーニング パフォーマンスを向上させ、トレーニング コストを削減し、LLaMA コミュニティとの互換性を維持しやすくすることです。テスト結果は、32 枚のカードのトレーニングでは、Megatron-LLaMA が HuggingFace で直接取得したコード バージョンと比較して 176% の高速化を達成できることを示していますが、大規模なトレーニングでは、Megatron-LLaMA はほぼ直線的に拡張し、ネットワークに対して不安定になります。高いレベルの寛容性。現在、Megatron-LLaMA はオープン ソース コミュニティで開始されています
#オープン ソース アドレス: https://github.com/alibaba/Megatron-LLaMA
大規模な言語モデルの優れたパフォーマンスは、人々の想像を何度も超えてきました。過去数か月にわたって、LLaMA と LLaMA2 がオープン ソース コミュニティに一般公開され、独自の大規模な言語モデルをトレーニングしたい人にとって素晴らしいオプションとなりました。オープンソース コミュニティでは、継続的なトレーニング/SFT (Alpaca、Vicuna、WizardLM、Platypus、StableBegula、Orca、OpenBuddy、Linly、Ziya など) やゼロからのトレーニング ( Baichuan、QWen、InternLM、OpenLLaMA など)で動作します。これらの研究は、大規模なモデル機能のさまざまな客観的評価リストで優れたパフォーマンスを発揮しただけでなく、長文の理解、長文の生成、コード作成、数学的解決などの実際のアプリケーション シナリオでも優れたパフォーマンスを示しました。この他にも、Whisper社のボイスチャットロボットとLLaMAを組み合わせたり、Stable Diffusion社のペイントソフトとLLaMAを組み合わせたり、医療・法務分野の相談補助ロボットなど、興味深い製品が業界に多数登場しています。 ## LLaMA モデル コードは HuggingFace から取得できますが、独自のデータを使用して LLaMA モデルをトレーニングすることは、個々のユーザーや中小規模の組織にとって低コストで簡単な作業ではありません。大規模なモデルの量とデータの規模により、通常のコンピューティング リソースでは効果的なトレーニングを完了することが不可能になり、コンピューティング能力とコストが深刻なボトルネックになっています。 Megatron-LM コミュニティのユーザーは、この点に関して非常に緊急の要求を持っています。
Taotian Group と Aicheng Technology は、大規模モデル アプリケーション向けの非常に広範なアプリケーション シナリオを持っており、大規模モデルの効率的なトレーニングに多くの取り組みを行ってきました。投資。 LLaMA の出現は、Taotian Group や Aicheng Technology を含む多くの企業に、データ処理、モデル設計、微調整、強化学習フィードバック調整の面で多くのインスピレーションを与え、ビジネス アプリケーション シナリオにおける新たなブレークスルーの実現にも貢献しました。 。したがって、LLaMA オープンソース コミュニティ全体に還元し、中国の事前トレーニング済み大規模モデル オープンソース コミュニティの開発を促進し、開発者が大規模言語モデルのトレーニング パフォーマンスをより簡単に向上させ、トレーニング コストを削減できるようにするために、Taotian はGroup と Aicheng Technology は、社内のオプティマイズ技術を組み合わせてオープンソースにし、Megatron-LLaMA をリリースし、すべてのパートナーと Megatron および LLaMA エコシステムを構築することを楽しみにしています。 
Megatron-LLaMA は、LLaMA の
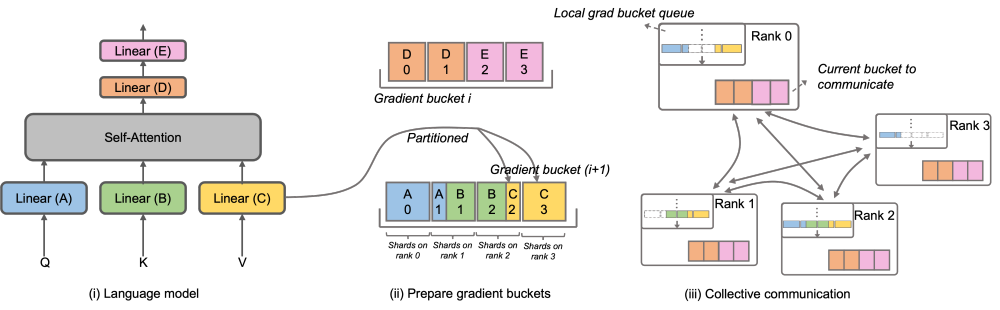
標準 Megatron-LM 実装のセットを提供し、 および HuggingFace フリー フォーマットを提供します。ツール は、コミュニティの生態学ツールとの互換性を保つために便利です。 Megatron-LLaMA は、Megatron-LM の逆のプロセスを再設計し、ノード数が少なく大規模な勾配アグリゲーション (GA) をオンにする必要がある場合や、ノード数が多く、大規模なグラディエント アグリゲーション (GA) をオンにする必要がある場合でも実現できるようにしました。小さな GA を使用する必要があり、優れたトレーニング パフォーマンスを発揮します。 LLaMA は現在、大規模な言語モデルのオープンソース コミュニティです 重要な取り組み。 LLaMAは、LLMの構造にBPE文字エンコーディング、RoPE位置エンコーディング、SwiGLUアクティベーション関数、RMSNorm正則化、Untied Embeddingなどの最適化技術を導入し、多くの客観的・主観的評価において優れた結果を達成しています。 LLaMA は、7B、13B、30B、65B/70B バージョンを提供しており、さまざまな大規模モデルの需要シナリオに適しており、大多数の開発者にも好まれています。他の多くのオープンソースの大規模モデルと同様、公式はコードの推論バージョンのみを提供しているため、最小限のコストで効率的なトレーニングを実行する方法に関する標準パラダイムはありません Megatron- LM は、エレガントで高性能なトレーニング ソリューションです。 Megatron-LM は、テンソル並列処理 (並列計算のために複数のカードに大規模な乗算を割り当てる Tensor Parallel、TP)、パイプライン並列処理 (処理のためにモデルの異なる層を異なるカードに割り当てるパイプライン パラレル、PP)、およびシーケンス並列処理 (シーケンスパラレル、SP、シーケンスの異なる部分が異なるカードで処理され、ビデオメモリが節約されます)、DistributedOptimizer 最適化(DeepSpeed Zero Stage-2 と同様、勾配とオプティマイザーパラメータをすべてのコンピューティングノードに分割します)およびその他のテクノロジーにより、コストを大幅に削減できます。ビデオ メモリの使用量を削減し、GPU 使用率を向上させます。 Megatron-LM は活発なオープンソース コミュニティを運営しており、新しい最適化テクノロジと機能設計がフレームワークに組み込まれ続けています。 ただし、Megatron-LM に基づく開発は簡単ではありません。特に、高価なマルチカード マシンでのデバッグと機能検証には非常に費用がかかります。 Megatron-LLaMA は、まず Megatron-LM フレームワークに基づく LLaMA トレーニング コードのセットを提供します。これは、さまざまなサイズのモデル バージョンをサポートし、HuggingFace 形式を直接サポートする Tokenizer など、LLaMA のさまざまなバリアントをサポートするように簡単に適合させることができます。したがって、Megatron-LLaMA は、過剰な適応を行うことなく、既存のオフライン トレーニング リンクに簡単に適用できます。 LLaMA-7b および LLaMA-13b の中小規模のトレーニング/微調整シナリオでは、Megatron-LLaMA は 54% を超える業界トップのハードウェア使用率 (MFU) を容易に達成できます 書き換える必要がある内容は次のとおりです: 図: DeepSpeed ZeRO Stage-2 DeepSpeed ZeRO は、Microsoft が発表した分散トレーニング フレームワークのセットで、そこで提案されたテクノロジは、その後の多くのフレームワークに大きな影響を与えました。 DeepSpeed ZeRO Stage-2 (以下、ZeRO-2) は、計算や通信の負荷を追加することなくメモリ使用量を節約するフレームワークのテクノロジです。上の図に示すように、計算要件により、各ランクにはすべてのパラメーターが必要です。ただし、オプティマイザ状態の場合、各ランクはその一部のみを担当し、すべてのランクが完全に繰り返される操作を同時に実行する必要はありません。したがって、ZeRO-2 では、オプティマイザーの状態を各ランクに均等に分割することを提案しています (各変数が均等に分割されているか、特定のランクに完全に保持されていることを保証する必要はないことに注意してください)。各ランクはトレーニング プロセス中にのみ使用する必要があります。 . オプティマイザのステータスと対応する部分のモデル パラメータを更新します。この設定では、この方法でグラデーションを分割することもできます。デフォルトでは、ZeRO-2 は Reduce メソッドを使用してすべてのランク間の勾配を逆に集計します。その後、各ランクは担当するパラメーターの一部を保持するだけで済みます。これにより、冗長な繰り返し計算が排除されるだけでなく、メモリも削減されます。使用法。 。 Native Megatron-LM は、DistributedOptimizer を介して ZeRO-2 のような勾配とオプティマイザー状態のセグメンテーションを実装し、トレーニング中のビデオ メモリの使用量を削減します。上の図に示すように、DistributedOptimizer は、プリセット勾配によって集約されたすべての勾配を取得した後、ReduceScatter オペレーターを使用して、以前に蓄積されたすべての勾配を異なるランクに分配します。各ランクは、処理する必要がある勾配の一部のみを取得し、オプティマイザーの状態と対応するパラメーターを更新します。最後に、各ランクは AllGather を通じて他のノードから更新されたパラメーターを取得し、最終的にすべてのパラメーターを取得します。実際のトレーニング結果は、Megatron-LM の勾配とパラメーターの通信が他の計算と直列に実行されることを示しています。大規模な事前トレーニング タスクの場合、バッチ データの合計サイズを変更しないようにするには、通常、より大きな GA を開きます。したがって、マシンの増加に伴って通信の割合が増加しますが、このときシリアル通信の特性上、拡張性が非常に弱くなります。コミュニティ内でも、このニーズは緊急です 次の課題を解決するためにこの問題に対して、Megatron-LLaMA はネイティブ Megatron-LM の DistributedOptimizer を改良し、勾配通信演算子を計算と並列化できるようにしました。特に、Megatron-LLaMA は、ZeRO の実装と比較して、よりスケーラブルな集合通信方式を使用し、並列処理を前提としたオプティマイザ分割戦略の賢明な最適化を通じてスケーラビリティを向上させます。 OverlappedDistributedOptimizer の主な設計は、次の点を保証します: a) 単一セットの通信事業者のデータ量が、通信帯域幅を最大限に活用するのに十分な大きさであること、b) 新しい分割方法で必要な通信データ量が最小限に等しいことデータ並列処理に必要な通信データ量 c) 完全なパラメータまたは勾配およびセグメント化されたパラメータまたは勾配の変換プロセス中に、多すぎるビデオ メモリ コピーを導入することはできません。 具体的には、Megatron-LLaMA は DistributedOptimizer を改良し、トレーニングの逆のプロセスで新しいものを組み合わせるために使用される OverlappedDistributedOptimizer を提案しました。方法。図に示すように、OverlappedDistributedOptimizer を初期化すると、すべてのパラメーターが、それらが属するバケットに事前に割り当てられます。各バケットのパラメータは完全です。パラメータは 1 つのバケットにのみ属します。バケットには複数のパラメータが存在する場合があります。論理的には、各バケットは P 個の部分 (P はデータ並列グループの数) に連続的に分割され、データ並列グループ内の各ランクがそのうちの 1 つを担当します Megatron-LLaMA の将来の計画 Megatron-LLaMA は、Taotian Group と Aicheng Technology が共同でオープンソース化し、フォローアップ メンテナンス サポートを提供するトレーニング フレームワークであり、社内で広く使用されています。ますます多くの開発者が LLaMA のオープンソース コミュニティに参加し、お互いから学べる経験を提供するにつれて、将来的にはトレーニング フレームワーク レベルでより多くの課題と機会が生まれると私は信じています。 Megatron-LLaMA はコミュニティの発展に細心の注意を払い、開発者と協力して次の方向に開発を推進します: #適応型の最適な構成の選択
Megatron-LM テクノロジーは、高パフォーマンスの LLaMA トレーニングの機会をもたらします
Megatron- LLaMA の逆プロセス最適化
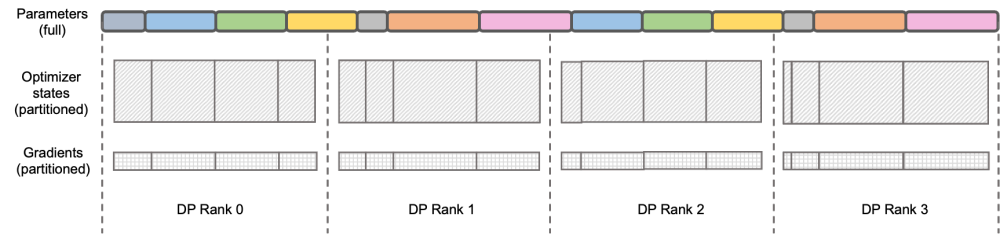
Megatron-LM 分散オプティマイザー
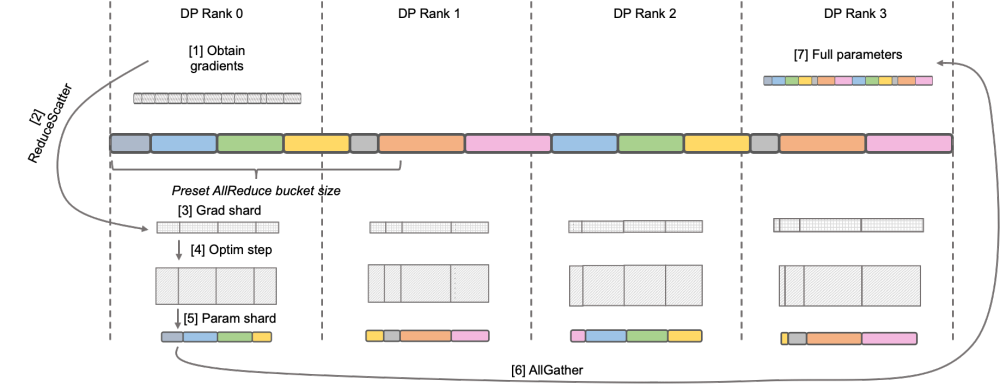
##Megatron-LLaMA OverlappedDistributedOptimizer
モデル構造またはローカル設計変更のサポートの強化
以上が32 枚のカードで 176% トレーニングを高速化、オープンソースの大規模モデル トレーニング フレームワーク Megatron-LLaMA が登場の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



