
 テクノロジー周辺機器
AI
アンドリュー・ンが気に入っています!ハーバード大学とマサチューセッツ工科大学の学者はチェスを使って、大規模な言語モデルが実際に世界を「理解」していることを証明しました
テクノロジー周辺機器
AI
アンドリュー・ンが気に入っています!ハーバード大学とマサチューセッツ工科大学の学者はチェスを使って、大規模な言語モデルが実際に世界を「理解」していることを証明しました
アンドリュー・ンが気に入っています!ハーバード大学とマサチューセッツ工科大学の学者はチェスを使って、大規模な言語モデルが実際に世界を「理解」していることを証明しました

2021 年、ワシントン大学の言語学者エミリー M. ベンダーは、大規模な言語モデルは「確率論的なオウム」にすぎないと主張する論文を発表しました。特定の統計、単語の出現確率を計算し、オウムのように一見合理的な単語をランダムに生成します。
ニューラル ネットワークは解釈できないため、学術コミュニティでは言語モデルがランダムなオウムであるかどうか確信が持てず、さまざまな関係者の意見が大きく異なります。
広く認識されているテストが不足しているため、モデルが「世界を理解」できるかどうかは、科学的な問題ではなく哲学的な問題になっています。
最近、ハーバード大学とマサチューセッツ工科大学の研究者は、単純なボード ゲームにおける内部表現の有効性を検証した新しい研究「Othello-GPT」を共同発表しました。確かに内部的に世界モデルを確立しており、単なる記憶や統計ではなく、その能力の源は不明です。

論文リンク: https://arxiv.org/pdf/2210.13382.pdf
実験プロセスは非常に単純で、オセロのルールに関する事前知識がなくても、研究者らはこのモデルが合法的な動きの操作を予測し、チェス盤の状態を非常に高い精度で捉えることができることを発見しました。
Ng Enda は、「Letter」コラムでこの研究を高く評価しました。彼は、この研究に基づいて、大規模な言語モデルが十分に複雑な世界を構築したと信じる理由があると信じました。私はモデルであり、ある意味では世界をある程度理解しています。
ブログリンク: https://www.deeplearning.ai/the-batch/does-ai-under-the-world/
ただし、Andrew Ng 氏は、哲学は重要だが、そのような議論には終わりがないかもしれないので、プログラミングを選んだほうがよいとも言いました。
チェス盤の世界モデル
チェス盤を単純な「世界」として想像し、ゲーム中にモデルが継続的に意思決定を行う必要がある場合、最初にシーケンスをテストできます。モデル 世界表現を学習できるかどうか。

研究者らは、実験プラットフォームとしてシンプルなオセロ ゲーム「Othello」を選択しました。そのルールは 8*8 チェス盤の中央にあります。 、最初に 4 つのチェスの駒 (黒と白に 2 つずつ) を置きます。その後、両側が順番に、直線または斜めの方向にプレイし、2 つの自分の駒の間にあるすべての敵の駒 (スペースを含めることはできません) が自分の駒になります (キャプチャと呼ばれます)ピース)、ピースが配置されるたびに、キャプチャするピースが存在する必要があり、最終的にはボードが完全に占有され、最も多くのピースを持っているプレイヤーが勝ちます。
チェスと比較すると、オセロのルールははるかに単純ですが、同時に、チェス ゲームの検索空間は十分に大きく、モデルはメモリを通じてシーケンスの生成を完了できないため、モデル世界表現の学習能力をテストするのに非常に適しています。
オセロ言語モデル
研究者らはまず、ゲーム スクリプト (オセロによって作成された一連のチェスの駒) を組み合わせた GPT バリアント言語モデル (Othello-GPT) をトレーニングしました。プレーヤー(プレーヤー)の移動操作)はモデルに入力されますが、モデルにはゲームと関連するルールに関する事前知識がありません。
モデルは、戦略の改善やゲームの勝利などを追求するために明示的にトレーニングされていませんが、合法的なオセロの動き操作を生成する際には比較的高い精度を持っています。
データセット
研究者らは 2 つのトレーニング データ セットを使用しました:
Championship は、主に 2 つのオセロ トーナメントで人間のプロ プレイヤーが採用したより戦略的思考の動きから、データの品質により注意を払っていますが、それぞれ 7605 個と 132921 個のゲーム サンプルしか収集できませんでした。データ セットが結合された後、それらはランダムに分割されました。トレーニング セット (2,000 万サンプル) と検証セット (379 万 6000 サンプル) の比率は 8:2 です。
Synthetic は、データのスケールにさらに注意を払い、ランダムで合法的な移動操作で構成されます。データの分布はチャンピオンシップ データセットとは異なりますが、オセロ ゲーム ツリーから均等に抽出されます。サンプリングが取得され、そのうち 2,000 万個のサンプルがトレーニングに使用され、379 万 6,000 個のサンプルが検証に使用されます。
各ゲームの説明は一連のトークンで構成され、語彙サイズは 60 (8*8-4)です。
モデルとトレーニング
モデルのアーキテクチャは、8 つのヘッドと 512 の隠れ次元を備えた 8 層 GPT モデルです。
次の重みモデルは単語を含めて完全にランダムに初期化されます。埋め込み層では、チェス盤の位置を表す語彙に幾何学的関係がありますが (C4 が B4 より低いなど)、この帰納的バイアスは明示的に表現されず、モデルの学習に委ねられます。 。
正当な動きの予測
モデルの主な評価指標は、モデルによって予測された移動操作が準拠しているかどうかです。オセロのルールで。
トレーニングされていないオセロと比較して、合成データセットでトレーニングされたオセロ GPT のエラー率は 0.01%、チャンピオンシップ データセットでは 5.17% でした。GPT のエラー率は次のとおりです。 93.29%。これは、両方のデータ セットでモデルがゲームのルールをある程度学習できることを意味します。
考えられる説明の 1 つは、モデルがオセロ ゲームのすべての移動アクションを記憶しているということです。
この推測を検証するために、研究者たちは新しいデータセットを合成しました。各ゲームの開始時に、オセロには 4 つの可能な開始位置 (C5、D6、E3、F4) があり、すべて C5 です。冒頭の動きは削除されてトレーニング セットとして使用され、次に C5 の冒頭データがテストとして使用されました。つまり、ゲーム ツリーのほぼ 1/4 が削除されました。その結果、モデルのエラー率はまだわずか 0.02% であることがわかりました。
Othello-GPT の高いパフォーマンスは、トレーニング プロセス中にテスト データがまったく表示されないため、メモリによるものではありません。
内部表現の探索
ニューラル ネットワークの内部表現を検出するために一般的に使用されるツールはプローブです。各プローブは分類子または回帰子です。入力はネットワークの内部表現で構成されます。アクティベーションを実行し、関心のある特徴を予測するようにトレーニングされています。
このタスクでは、Othello-GPT の内部アクティベーションに現在のチェス盤の状態の表現が含まれているかどうかを検出するために、動きシーケンスを入力した後、内部アクティベーション ベクトルを使用して次の動作ステップを予測します。
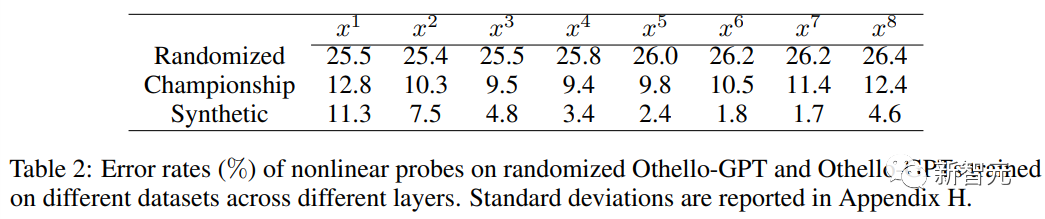
線形プローブを使用する場合、トレーニングされた Othello-GPT の内部表現は、ランダムな推測よりもわずかに正確です。

非線形プローブ (2 層 MLP) を使用すると、エラー率が大幅に低下し、チェス盤の状態が単純なメソッドはネットワーク アクティベーションに保存されます。
介入実験
モデルの予測と創発世界の表現の間の因果関係、つまりチェス盤の状態が実際に To に影響を与えるかどうかを判断するため。ネットワークの結果を予測するために、研究者らは一連の介入試験を実施し、その結果生じる影響を測定しました。
Othello-GPT からの一連のアクティベーションが与えられた場合、プローブを使用してボードの状態を予測し、関連する手の予測を記録してから、アクティベーションを変更して、プローブが更新されたボードの状態を予測できるようにします。 。
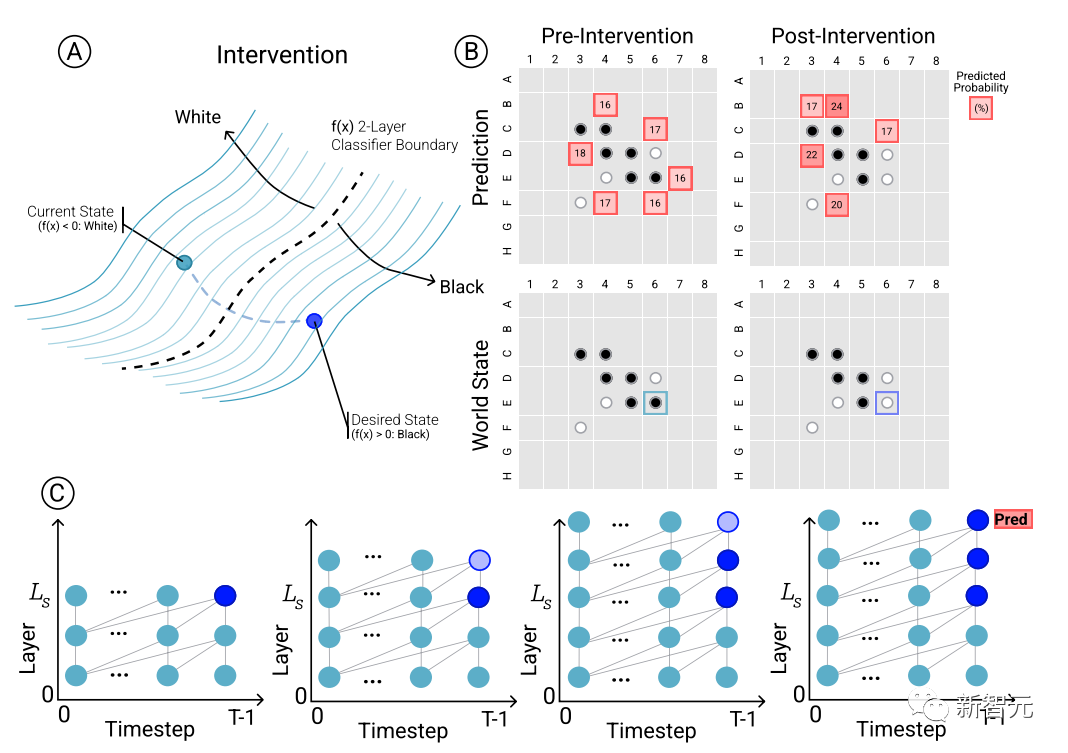
介入操作には、特定の位置のチェスの駒を白から黒に変更するなどが含まれます。小さな変更を行うと、モデルは次のことを検出します。内部表現は予測が確実に行われます。つまり、内部表現とモデル予測の間には因果関係があります。
視覚化
内部表現の有効性を検証するための介入実験に加えて、研究者らは予測結果も視覚化しました。モデルが介入技術を使用してチェスの駒を変更する場合、モデルの予測結果がどのように変化するかは、予測結果の重要性に対応します。
その後、現在のチェス盤の状態のtop1が予測した顕著性に基づいてカードが色付けされ、視覚化されます。描かれた絵はネットワークの潜在空間に基づいて入力されるため、図(潜在的顕著性マップ)。

ご覧のとおり、合成データセットとトーナメント データセットの両方でトレーニングされたオセロ GPT のトップ 1 予測の潜在顕著性マップには、明確なパターンが示されています。
オセロ GPT の合成バージョンは、経験の少ないプレイヤーにとって、正当な操作位置でより高い有意値を示し、不正な操作の有意値は大幅に低くなります。
トーナメント バージョンの顕著性マップはより複雑です。正当な操作位置の顕著性値は比較的高いですが、他の位置もより高い顕著性値を示します。 , オセロマスターはよりグローバルな機能を考慮しているためかもしれません。
以上がアンドリュー・ンが気に入っています!ハーバード大学とマサチューセッツ工科大学の学者はチェスを使って、大規模な言語モデルが実際に世界を「理解」していることを証明しましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1653
1653
 14
1413
52
1304
25
1251
29
1224
24
14
1413
52
1304
25
1251
29
1224
24

 世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界の上位10の暗号通貨取引プラットフォームには、Binance、Okx、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、Kucoin、Poloniexが含まれます。これらはすべて、さまざまな取引方法と強力なセキュリティ対策を提供します。
 推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム:1。OKX、2。Binance、3。Coinbase、4。Kraken、5。Huobi、6。Kucoin、7。Bitfinex、8。Gemini、9。Bitstamp、10。Poloniex、これらのプラットフォームは、セキュリティ、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのために知られています。
 トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
Binance、OKX、Gate.ioなどの上位10のデジタル通貨交換は、システムを改善し、効率的な多様化したトランザクション、厳格なセキュリティ対策を改善しました。
 ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価格は20,000ドルから30,000ドルの範囲です。 1。ビットコインの価格は2009年以来劇的に変動し、2017年には20,000ドル近くに達し、2021年にはほぼ60,000ドルに達しました。2。価格は、市場需要、供給、マクロ経済環境などの要因の影響を受けます。 3.取引所、モバイルアプリ、ウェブサイトを通じてリアルタイム価格を取得します。 4。ビットコインの価格は非常に不安定であり、市場の感情と外部要因によって駆動されます。 5.従来の金融市場と特定の関係を持ち、世界の株式市場、米ドルの強さなどの影響を受けています。6。長期的な傾向は強気ですが、リスクを慎重に評価する必要があります。
 トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
現在、上位10の仮想通貨交換にランクされています。1。Binance、2。Okx、3。Gate.io、4。CoinLibrary、5。Siren、6。HuobiGlobal Station、7。Bybit、8。Kucoin、9。Bitcoin、10。BitStamp。
 2025年のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの1つです
Apr 28, 2025 pm 08:12 PM
2025年のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの1つです
Apr 28, 2025 pm 08:12 PM
2025年の世界の上位10の暗号通貨取引所には、Binance、Okx、Gate.io、Coinbase、Kraken、Huobi、Bitfinex、Kucoin、Bittrex、Poloniexが含まれます。これらはすべて、高い取引量とセキュリティで知られています。
 Cのスレッドパフォーマンスを測定する方法は?
Apr 28, 2025 pm 10:21 PM
Cのスレッドパフォーマンスを測定する方法は?
Apr 28, 2025 pm 10:21 PM
Cのスレッドパフォーマンスの測定は、標準ライブラリのタイミングツール、パフォーマンス分析ツール、およびカスタムタイマーを使用できます。 1.ライブラリを使用して、実行時間を測定します。 2。パフォーマンス分析にはGPROFを使用します。手順には、コンピレーション中に-pgオプションを追加し、プログラムを実行してGmon.outファイルを生成し、パフォーマンスレポートの生成が含まれます。 3. ValgrindのCallGrindモジュールを使用して、より詳細な分析を実行します。手順には、プログラムを実行してCallGrind.outファイルを生成し、Kcachegrindを使用して結果を表示することが含まれます。 4.カスタムタイマーは、特定のコードセグメントの実行時間を柔軟に測定できます。これらの方法は、スレッドのパフォーマンスを完全に理解し、コードを最適化するのに役立ちます。
 CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用する方法は?
Apr 28, 2025 pm 10:18 PM
CでChronoライブラリを使用すると、時間と時間の間隔をより正確に制御できます。このライブラリの魅力を探りましょう。 CのChronoライブラリは、時間と時間の間隔に対処するための最新の方法を提供する標準ライブラリの一部です。 Time.HとCtimeに苦しんでいるプログラマーにとって、Chronoは間違いなく恩恵です。コードの読みやすさと保守性を向上させるだけでなく、より高い精度と柔軟性も提供します。基本から始めましょう。 Chronoライブラリには、主に次の重要なコンポーネントが含まれています。STD:: Chrono :: System_Clock:現在の時間を取得するために使用されるシステムクロックを表します。 STD :: Chron
