

Apache IoTDB: 産業用 IoT シナリオにおけるストレージ、クエリ、使用法の問題を解決する革新的なデータベース

インダストリー 4.0 時代の到来により、デジタル化と自動化の導入により生産環境はより効率的になりました。一方で、スマートデバイスがもたらす膨大なデータの潜在的な価値に注目が集まり始めていますが、スマートデバイスが生成するデータをいかに効率的に保存し、どのように分析するかが課題となっています。従来のデータベース モデルとストレージ方法では、これらのニーズを満たすことができなくなりました。したがって、時系列データベースは時代の要求に応じて登場し、効率的なデータの保存とクエリを実現し、データの潜在的な価値をより適切に探索できるようにすることを目的としています。
このような状況に直面した清華大学2015年IoTDBの開発を開始。 2020 年 9 月 23 日に、Apache IoTDB は卒業し、Apache トップレベル プロジェクトになりました。これは現在、中国の大学によって開始された唯一の Apache Foundation トップレベル プロジェクトであり、IoT データ管理分野における唯一のオープンソース プロジェクトでもあります。アパッチ財団。 2021 年 10 月、Apache IoTDB コア チームは Tianmou Technology を設立し、産業ユーザー によるデータの「保存、検索、使用」の問題解決を支援するために IoTDB を運用し続けています。
Apache IoTDB によって開発されたコア テクノロジに関しては、数人の参加者が協力して、IoTDB の設計を詳細かつ完全に詳しく説明したレビュー ペーパーを出版しました。この記事では、数万台の掘削機を管理する必要がある産業会社を例に挙げ、要件について次のように説明しています。「データはまずデバイスにパッケージ化され、次に 5G モバイル ネットワークを通じてサーバーに送信されます。サーバーでは、データは、OLTP クエリの場合、時系列データベースに書き込まれます。最後に、データ サイエンティストは、複雑な分析と予測、つまり OLAP タスクのために、データベースからビッグ データ プラットフォームにデータをロードできます。"

- 論文アドレス: https://dl.acm.org/doi/abs/10.1145/3589775
- プロジェクト アドレス: https://dl.acm.org/doi/abs/10.1145/3589775 ://github.com/apache/iotdb
この論文の重要なポイントには次の部分が含まれます:
1. データ モデルの設計: 論理レベルでの時系列の編成と物理スキーマでのストレージ;
2. TsFile ファイル形式: 独自に開発したカラムナ型ストレージ ファイル形式で、書き込み、クエリなどの効率も満たします;
3. IoTDB エンジン : 主にストレージ エンジン、クエリ エンジンなどが含まれます;
分散ソリューションとはタスクの分解を指しますまたは問題を複数のサブタスクに分割し、これらのサブタスクを複数のコンピュータまたはノードに割り当てて処理します。このソリューションにより、システムの信頼性、拡張性、パフォーマンスが向上します。タスクを複数のコンピュータに分散することで、1 台のコンピュータの負荷が軽減され、システムの同時処理能力が向上します。同時に、分散ソリューションは冗長バックアップとフェイルオーバーを通じてシステムの耐障害性を強化することもでき、ノードに障害が発生した場合でもシステムは引き続き実行できます。今日のビッグ データとクラウド コンピューティング環境では、分散ソリューションが一般的なアーキテクチャ パターンとなり、分散データベース、分散ストレージ システム、分散コンピューティング プラットフォームなどのさまざまな分野で広く使用されています。
#次のコンテンツでは、これらの重要な部分をさらに詳しく説明します
## 詳細な解釈#データ モデル設計が必要です
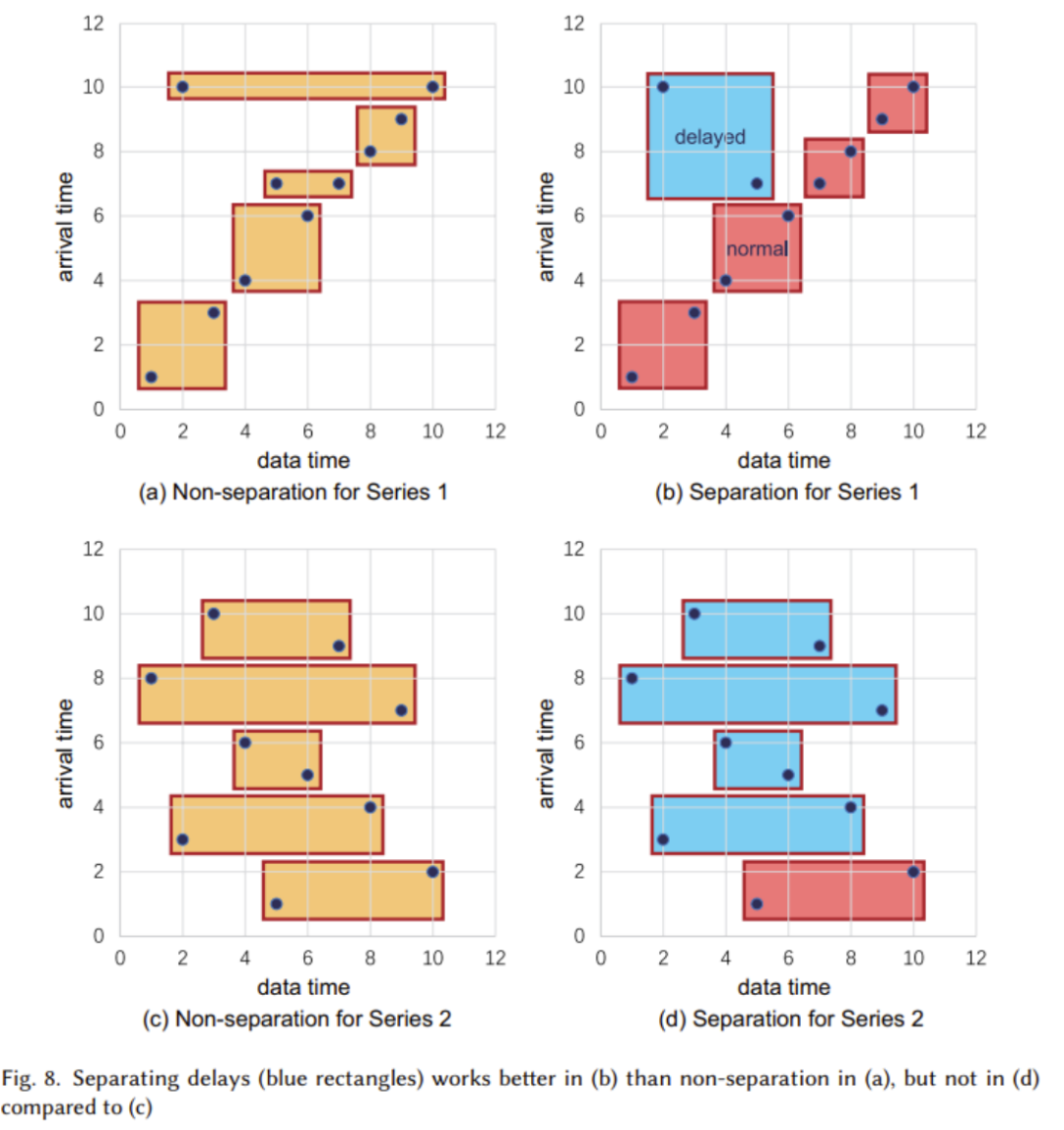
下の図に示すように、高強度の書き込み操作に対応するためにツリー構造が使用されます。 、IoT シナリオにおける一般的なデータ到着遅延問題を効果的に処理できます。
ツリー構造では、各リーフ ノードはセンサーを表し、各センサーには対応するデバイスがあります。図の下 2 階層に示すように、上位階層も同様です。
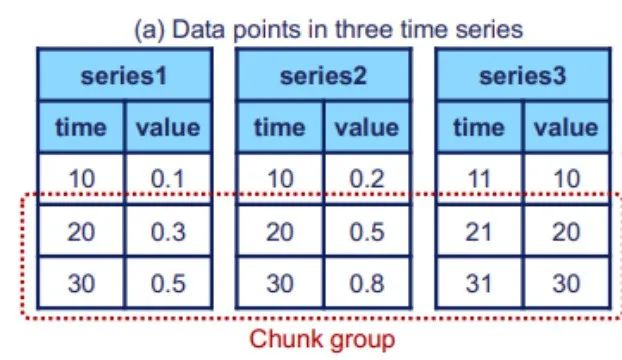
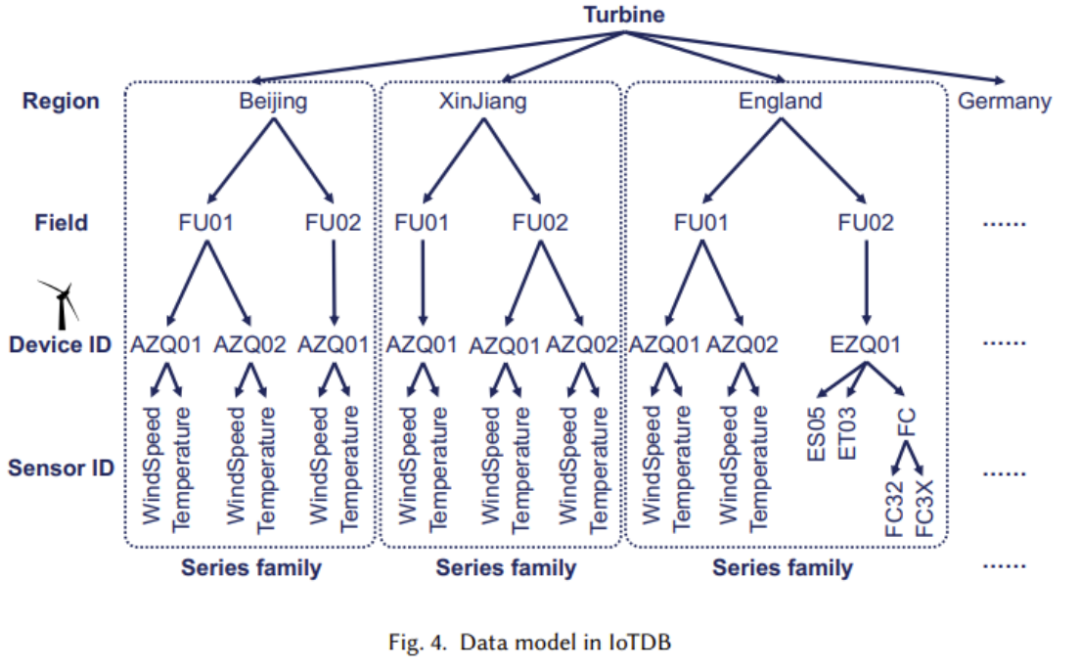 (2) 論理構造は、図で説明しました。前回の記事では、主に時系列 (Time series) とシーケンス ファミリ (Series family) の 2 つの部分で構成される物理構造の実装について見ていきます。次の図は、各時系列が時間と値の 2 つの属性で構成されていることを示しています。時系列は、ルート ノードからリーフ ノードまでの完全なパスを通じて配置されます。上図はシーケンスクラスタの概念を示したもので、シーケンスクラスタには複数のデバイスが含まれており、それらのデータはTsFile(後述するファイル構造)にまとめて格納されます。
(2) 論理構造は、図で説明しました。前回の記事では、主に時系列 (Time series) とシーケンス ファミリ (Series family) の 2 つの部分で構成される物理構造の実装について見ていきます。次の図は、各時系列が時間と値の 2 つの属性で構成されていることを示しています。時系列は、ルート ノードからリーフ ノードまでの完全なパスを通じて配置されます。上図はシーケンスクラスタの概念を示したもので、シーケンスクラスタには複数のデバイスが含まれており、それらのデータはTsFile(後述するファイル構造)にまとめて格納されます。
書き直す必要があるのは次のとおりです。 2. TsFile ファイル形式の設計
TsFile は Apache IoTDB の独自に開発されたカラムナ型ストレージ ファイル形式。その構造を以下の図に示します。
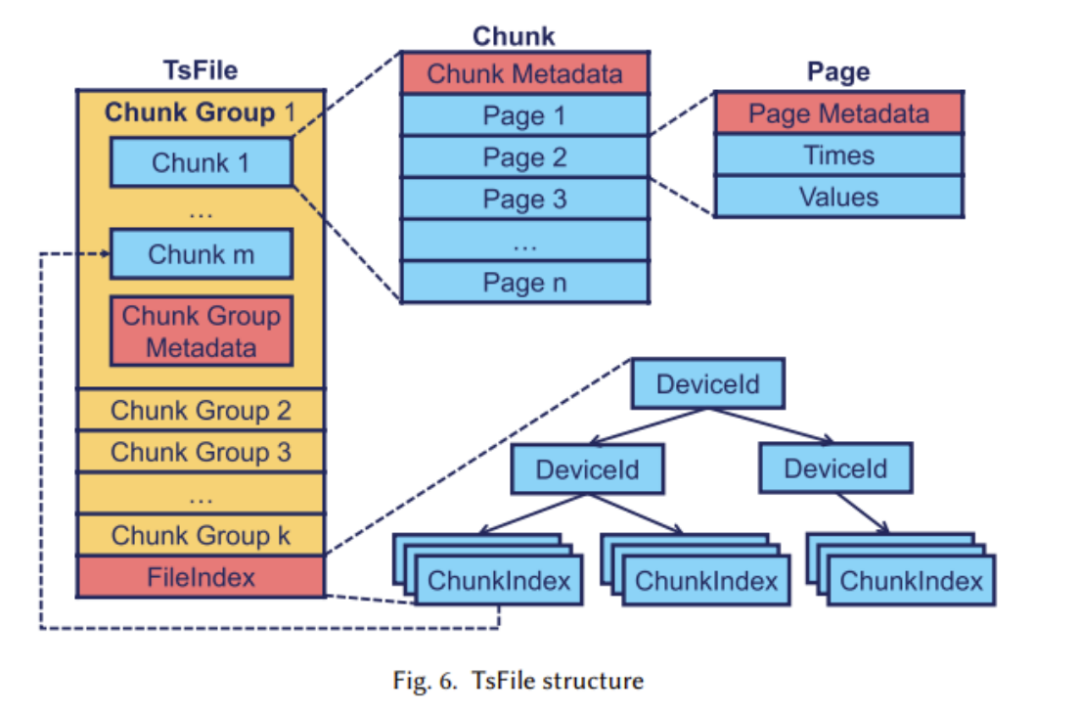
TsFile を設計するとき、研究チームは主に次の問題を解決することに重点を置きました。
- #スペースを節約し、可能な限りデータを圧縮します
- ファイル数を削減します
- クエリを実行します時系列を物理的な場所にまとめて保存
- ディスクの断片化を削減
- 効率的なアクセス
- 列ストレージ: Null 値を排除し、ディスク使用量を節約、データ アクセスの局所性
- # # time シーケンス エンコーディング: IoT シナリオで時系列の固有の特性を利用する
- # 周波数ドメイン エンコーディング: 時系列の周波数ドメイン分析は信号処理で広く実行されます
- 具体的な構造分析: ページ (ページ) は基本的な記憶単位です。チャンクには複数のページが含まれます。チャンク内のページは同じ時系列に属し、サイズが可変です。チャンク グループには複数のチャンクが含まれます。グループ内のページ。チャンクは、同じ期間内に書き込まれた 1 つ以上の一連のデバイスに属します。チャンクは、一緒にクエリされることが多いため、連続したディスク領域に配置されます。ブロックはメモリ内にあり、書き込まれたブロック グループはメモリ内の最初にあります。バッファリングは TsFile で実行され、メモリがしきい値に達すると、すべてのブロック グループが TsFile にフラッシュされ、インデックス (FileIndex) はファイルの最後にデータ アクセスのための情報を記録します。
- #書き換える必要がある内容は次のとおりです。 3. IoTDB エンジン
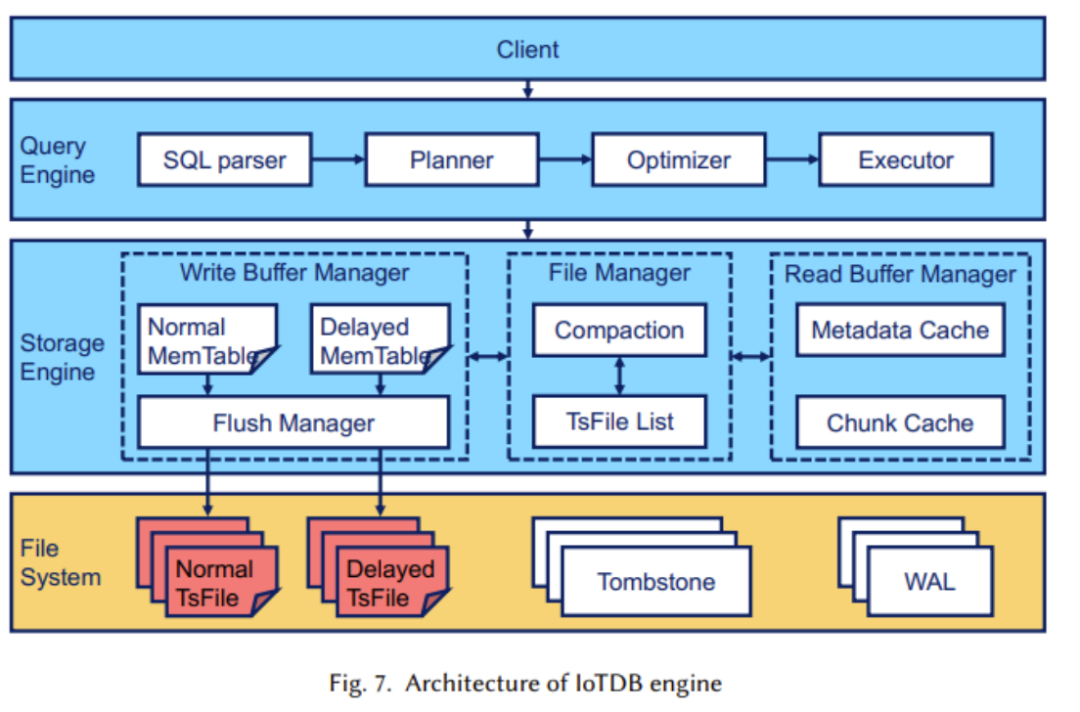
# #このパートでは、研究者は主に、IoT シナリオにおける到着の遅延、効率的なクエリ処理、SQL のようなクエリの設計に焦点を当てています。 IoTDB エンジンの構造を次の図に示します。
#図では、ストレージ エンジン部分が主に次の目的で使用されることがわかります。 TsFileの書き込み処理、読み取り、管理を行います。この部分では、自動遅延分離テクノロジが採用されています (下図に示すように)
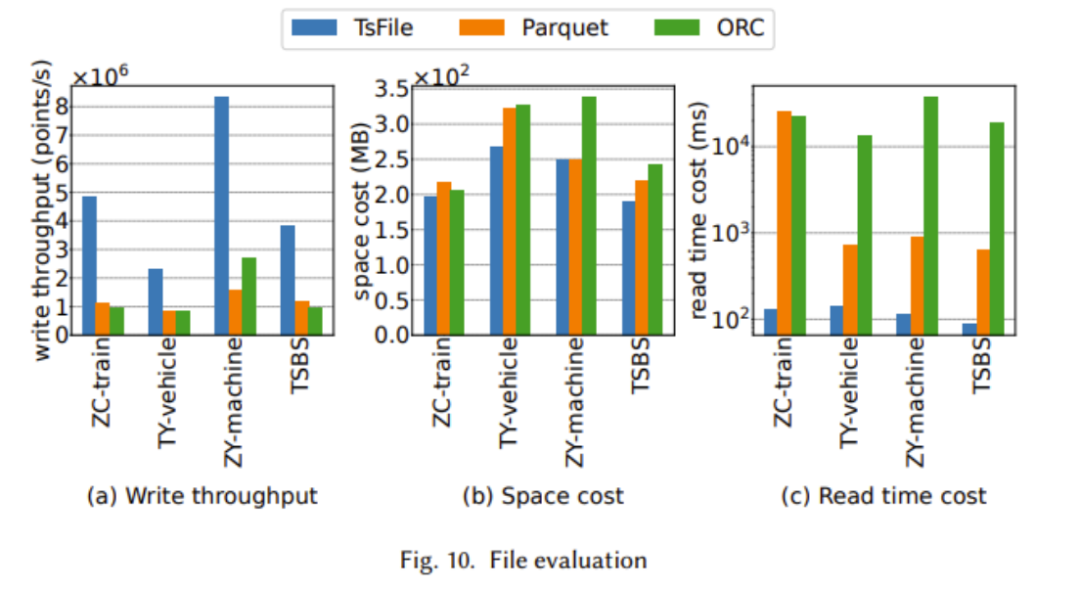
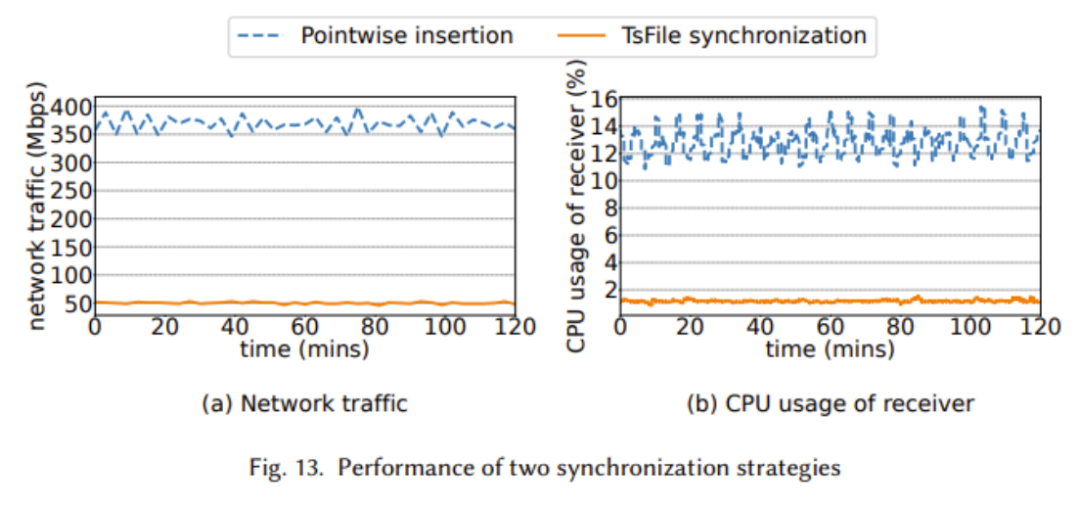
上の 2 つの図は、書き込みスループット、読み取り時間コスト、同期パフォーマンスにおける TsFile の利点を示しています。これは主に、deviceId などの冗長な情報の保存を回避する TsFile の IoT 対応構造設計によるものです。 TsFile のディスク使用量に明らかな利点はありませんが、より詳細なインデックスが構築され、より多くのスペースが使用されるためです。ただし、上記のグラフで読み取り時間コスト
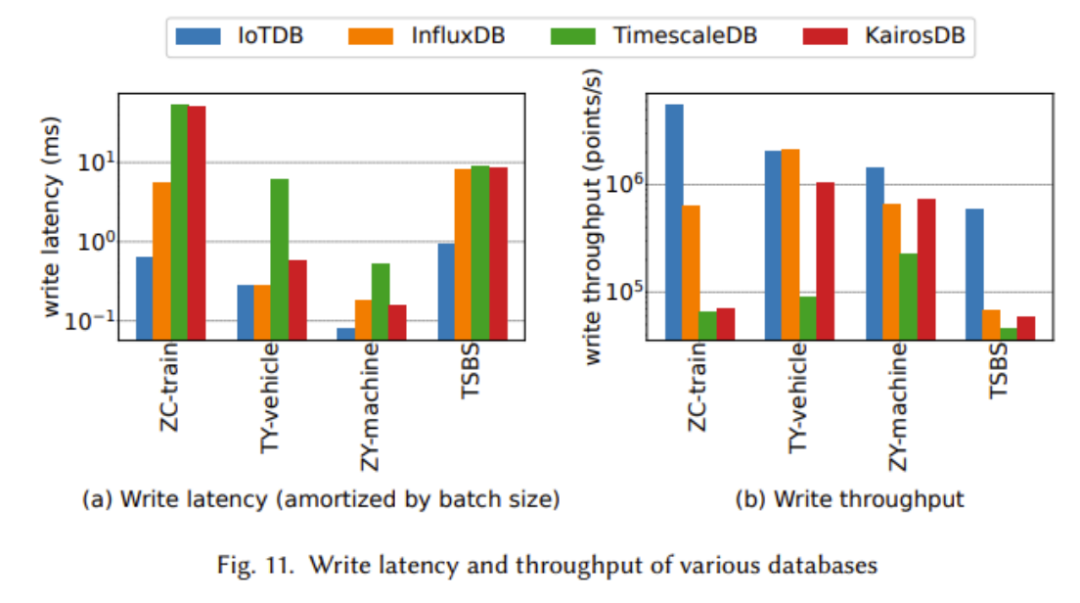
に明らかな利点が見られるため、この犠牲はクエリ時間の大幅な改善につながる可能性があります。 IoTDB は、書き込みスループットの向上や書き込み遅延の短縮など、ほぼすべてのテストで優れたパフォーマンスを示していることがはっきりとわかります
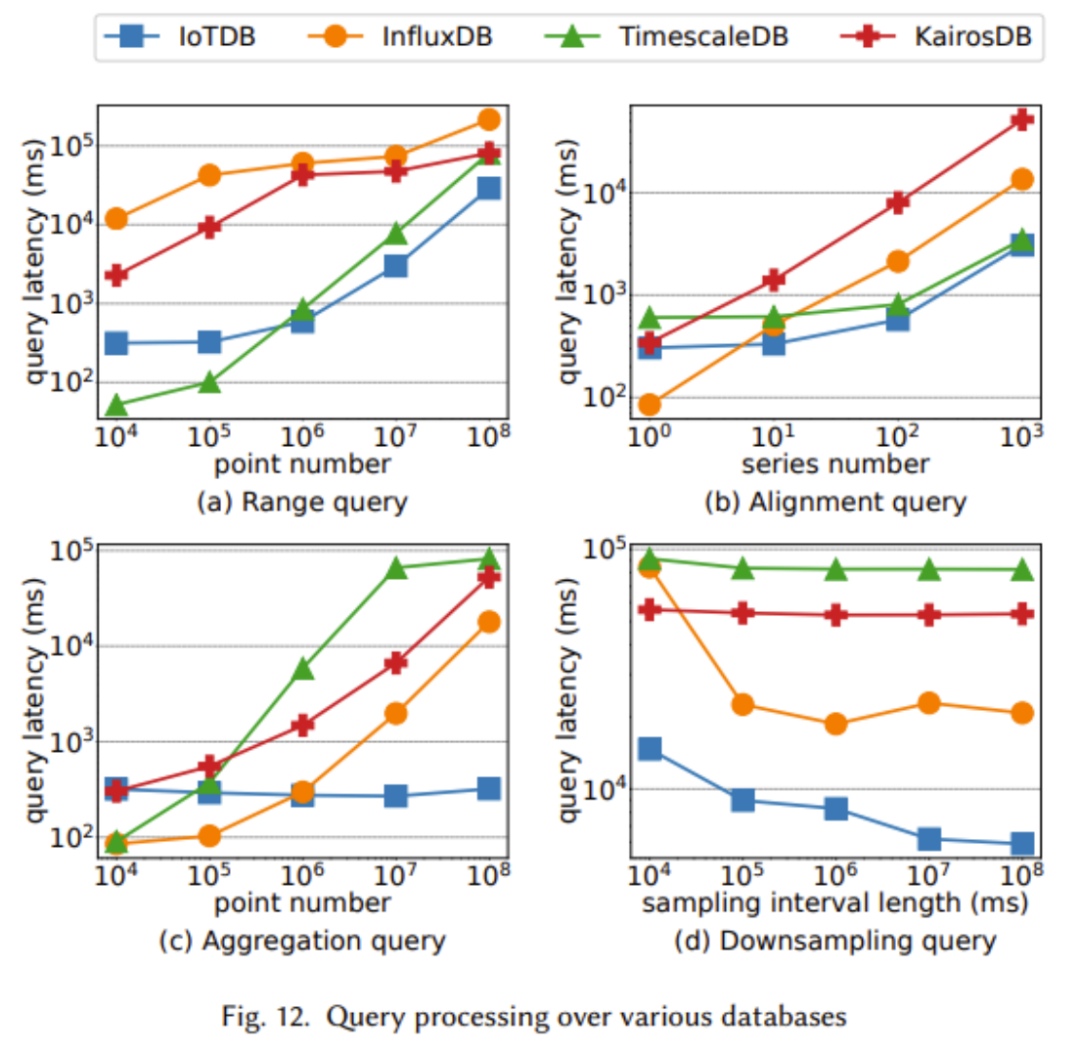
上記の実験では、次のことが観察されました。 IoTDB は、クエリ データ サイズが大きいほどパフォーマンスが向上しました。特に大規模なデータ集約では、IoTDB の利点が特に顕著です
概要
このペーパーでは、Apache IoTDB A と呼ばれる新しいメソッドを紹介します。オープン アーキテクチャを採用し、IoT アプリケーションのリアルタイム クエリとビッグ データ分析をサポートするように特別に設計された新しい時系列データ管理システム。このシステムには、TsFile と呼ばれる新しい時系列ファイル形式が含まれています。これは、列ストレージを使用して時間と値を保存し、NULL 値を回避し、効果的な圧縮を実現します。 TsFile に基づいた IoTDB エンジンは、LSM ツリーのような戦略を使用して高強度の書き込みを処理し、IoT シナリオで一般的なデータ到着の遅延の問題を処理できます。 TsFile の豊富なスケーラブルなクエリ関数と事前計算された統計情報により、IoTDB は OLTP および OLAP タスクを効率的に処理できます
IoTDB は、産業用 IoT シナリオにさらに適切に対応できるようになりました。新しいタイプのデータベース、これは上記のテクノロジーの成果です。
以上がApache IoTDB: 産業用 IoT シナリオにおけるストレージ、クエリ、使用法の問題を解決する革新的なデータベースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7526
7526
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
この記事では、DebianシステムのApachewebサーバーのロギングレベルを調整する方法について説明します。構成ファイルを変更することにより、Apacheによって記録されたログ情報の冗長レベルを制御できます。方法1:メイン構成ファイルを変更して、構成ファイルを見つけます。Apache2.xの構成ファイルは、通常/etc/apache2/ディレクトリにあります。ファイル名は、インストール方法に応じて、apache2.confまたはhttpd.confである場合があります。構成ファイルの編集:テキストエディターを使用してルートアクセス許可を使用して構成ファイルを開く(nanoなど):sudonano/etc/apache2/apache2.conf
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
 Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
DebianでHadoopログを管理すると、次の手順とベストプラクティスに従うことができます。ログ集約を有効にするログ集約を有効にします。Yarn.log-Aggregation-set yarn-site.xmlファイルでは、ログ集約を有効にします。ログ保持ポリシーの構成:yarn.log-aggregation.retain-secondsを設定して、172800秒(2日)などのログの保持時間を定義します。ログストレージパスを指定:Yarn.Nを介して
