

指定された 2 つの文内の反復しない単語をすべて出力します。


このチュートリアルでは、指定された 2 つの文内で繰り返されない単語をすべて識別して出力します。繰り返されない単語とは、2 つの文の中で 1 回だけ出現する単語、つまり、別の文の中で繰り返し出現しない単語を指します。このタスクには、入力文を分析し、個々の単語を識別し、2 つの文を比較して 1 回だけ出現する単語を見つけることが含まれます。出力はこれらすべての単語のリストになります。このタスクは、ループ、配列、辞書の使用など、さまざまなプログラミング方法を通じて実行できます。
###方法###ここでは、指定された 2 つの文内の反復しない単語をすべて出力する 2 つの方法を示します-
方法 1: 辞書を使用する
方法 2: コレクションを使用する
方法 1: 辞書を使用する
辞書を使用して、各単語が 2 つのフレーズに出現する回数を数えます。次に、辞書を調べて、一度だけ出現する単語をすべて出力します。 C の Dictionary 関数は、通常、指定された 2 つの文内のすべての一意の単語を出力するために使用されます。この方法では、辞書またはハッシュ テーブル データ構造を使用して、2 つのフレーズ内の各単語の頻度を保存します。その後、辞書を反復処理して、1 回だけ出現する用語を出力できます。
###文法###これは、実際のコードを含まない構文です。C の辞書メソッドを使用して、指定された 2 つの文内の反復しない単語をすべて出力します -
単語の出現頻度を保存する辞書を宣言します
-
リーリー
-
リーリー
-
リーリー
-
リーリー
###アルゴリズム###
C では、これは辞書メソッドを使用して、指定された 2 つの文内の重複しない項目をすべて段階的に出力するトリックです -
- 文を含む 2 つの文字列 s1 と s2 を作成します。
ステップ 2- 文中の各単語の出現頻度を記録するために使用される空の順序なしマップ文字列 int> dict を宣言します。
ステップ3-Cの文字列ストリームクラスを使用して、2つのフレーズを解析して単語を抽出します。
ステップ 4- 抽出された各単語について、辞書に掲載されているかどうかを確認します。そうであれば、その頻度を 1 つ増やします。それ以外の場合は、頻度 1 で辞書に追加します。
ステップ 5- 両方の文を処理した後、辞書を繰り返し、頻度 1 のすべての用語を表示します。これらは 2 つの文の中で繰り返されていない単語です。
ステップ 6-このメソッドの時間計算量は O(n), です 例 1
の中国語訳は次のとおりです:例 1 このコードは、順序なしマップを使用して、結合されたフレーズ内の各単語の頻度を保存します。次に、マップをループして、1 回だけ出現する各単語を非反復単語のベクトルに追加します。最後に、重複しない単語を公開します。この例は、2 つの文がユーザーによって入力されたのではなく、プログラムにハードコーディングされていることを意味します。
リーリー ###出力### リーリー方法 2: コレクションを使用する
この戦略には、セットを使用して 2 つのフレーズに 1 回だけ出現する用語を検索することが含まれます。各フレーズの用語セットを構築し、これらのセットの共通部分を特定できます。最後に、交差部分を反復処理して、1 回だけ出現するすべての項目を出力できます。
コレクションは、さまざまな要素をソートされた順序で保持する連想コンテナです。両方のフレーズの用語をコレクションに挿入でき、重複するものは自動的に削除されます。
###文法### ###確かに!以下は、指定された 2 つの文内の反復しない単語をすべて出力するために Python で使用できる構文です。 -2 つの文を文字列として定義します
リーリー
各文を単語のリストに分割します-
リーリー
- これら 2 つの単語リストからセットを作成します
-
リーリー
- セットの共通部分から一意の単語を見つける
-
リーリー
- 一意の単語を印刷する
-
リーリー
###アルゴリズム###
- C の集計関数を使用して、指定された 2 つの文内の反復しない単語をすべて出力するには、以下の手順に従ってください -
-
ステップ 2
- 文字列フロー ライブラリを使用して、各文を独立した単語に分割し、2 つの別々の配列に保存します。
ステップ 3
- 各文に 1 つずつ、合計 2 つのセットを作成して、一意の単語を保存します。
ステップ 4 - 各単語配列をループし、各単語を正しいセットに挿入します。
ステップ 5 - 各セットをループし、固有の単語を出力します。
例 2の中国語訳は次のとおりです: 例 2
このコードでは、文字列ストリーム ライブラリを使用して各文を個別の単語に分割します。次に、uniqueWords1 と uniqueWords2 の 2 つのコレクションを使用して、各文の一意の単語を保存します。最後に、各セットをループして、重複しない単語を出力します。
#include <iostream>
#include <string>
#include <sstream>
#include <set>
using namespace std;
int main() {
string sentence1 = "This is the first sentence.";
string sentence2 = "This is the second sentence.";
string word;
stringstream ss1(sentence1);
stringstream ss2(sentence2);
set<string> uniqueWords1;
set<string> uniqueWords2;
while (ss1 >> word) {
uniqueWords1.insert(word);
}
while (ss2 >> word) {
uniqueWords2.insert(word);
}
cout << "Non-repeating words in sentence 1:" << endl;
for (const auto& w : uniqueWords1) {
if (uniqueWords2.find(w) == uniqueWords2.end()) {
cout << w << " ";
}
}
cout << endl;
cout << "Non-repeating words in sentence 2:" << endl;
for (const auto& w : uniqueWords2) {
if (uniqueWords1.find(w) == uniqueWords1.end()) {
cout << w << " ";
}
}
cout << endl;
return 0;
}
输出
Non-repeating words in sentence 1: first Non-repeating words in sentence 2: second
结论
总之,从两个提供的句子中打印所有非重复单词的任务是通过使用各种编程方法来实现的,例如将句子分解为单个单词,利用字典来量化每个单词的频率,以及过滤掉非重复单词。生成的非重复单词集合可以报告给控制台或保存在列表或数组中以供进一步使用。这项工作对于基本的编程文本操作和数据结构操作很有帮助。以上が指定された 2 つの文内の反復しない単語をすべて出力します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7492
7492
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 高い心の知能指数を持ってTiktokのコメントに応答するにはどうすればよいでしょうか? TikTokのコメントに返信する文は何ですか?
Mar 23, 2024 pm 07:50 PM
高い心の知能指数を持ってTiktokのコメントに応答するにはどうすればよいでしょうか? TikTokのコメントに返信する文は何ですか?
Mar 23, 2024 pm 07:50 PM
現代社会では、多くの人がDouyinプラットフォームで自分の人生を喜んで公開し、個人的な感情を表現しており、コメントエリアでの議論が白熱した議論を引き起こすことがよくあります。 Douyin のコメントに高い EQ で返信する方法は、多くの人々の注目を集めています。 1. 心の知能指数が高いDouyinのコメントにどう反応するか?礼儀正しく敬意を払うことは、インターネット コミュニケーションの基本原則です。たとえ同意できない場合でも、丁寧に対応しましょう。感謝の気持ちを表し、積極的にコミュニケーションをとることで、良好なコミュニケーションの雰囲気を築くことができます。特に査読者が困難やフラストレーションを経験している場合には、理解と共感を示すことが重要です。共感と理解を表現する 1 つの方法は、「あなたが経験している困難を理解しています。あなたが問題を解決する方法を見つけられることを願っています。私はあなたがそれを乗り越えられるよう最善を尽くします。」この思いやりのある態度は役に立ちます。
 イマーシブ リーダーで Microsoft Reader Coach を使用する方法
Mar 09, 2024 am 09:34 AM
イマーシブ リーダーで Microsoft Reader Coach を使用する方法
Mar 09, 2024 am 09:34 AM
この記事では、Windows PC のイマーシブ リーダーで Microsoft Reading Coach を使用する方法を説明します。読書指導機能は、生徒や個人が読書を練習し、読み書き能力を伸ばすのに役立ちます。サポートされているアプリケーションで文章や文書を読むことから始めます。これに基づいて、Reading Coach ツールによって読書レポートが生成されます。読書レポートには、読書の正確さ、読むのにかかった時間、1分あたりの正解単語数、読書中に最も難しいと感じた単語が表示されます。単語を練習することもできるので、一般的な読解力の向上にも役立ちます。現在、Office または Microsoft365 (OneNote for Web および Word for We を含む) のみ
 単語を暗記しているときに、どうすれば再び単語を覚え始めることができますか? Mo Mo で単語を覚えたり、単語を再暗記したりする方法を共有します。
Mar 15, 2024 pm 03:28 PM
単語を暗記しているときに、どうすれば再び単語を覚え始めることができますか? Mo Mo で単語を覚えたり、単語を再暗記したりする方法を共有します。
Mar 15, 2024 pm 03:28 PM
Mo Mo が単語を覚えたときに、再び単語を覚え始める方法に興味がありますか? Mo Mo Bei Vocabulary は、非常に使いやすい英単語学習ソフトウェアです。ユーザーは、自分の英語レベルや学習意図に基づいて、英語学習用の英単語ライブラリを選択できます。また、例文、記憶術、その他の方法を使用して、理解を深めたり、学習することができます。単語を覚える。友達の中には、単語の暗記が終わって、もう一度同じ単語帳を暗記し始めたいと考えている人がいますが、どうすればよいかわかりません。今回はそんな皆さんのために、単語の暗記法と再暗記法を編集者が整理しました!役に立ったらぜひダウンロードしてください! 1. 単語をもう一度覚え始めるにはどうすればよいですか? Mo Mo で単語を覚えたり、単語を再暗記したりする方法を共有します。 1. Mo Mo Bei Vocabulary アプリを開き、レビュー ページのチェックイン機能を確認して、その日の日付を選択します。 2. クリックして入力すると、詳細を表示するオプションが表示されます。 3. ページにジャンプしたら、
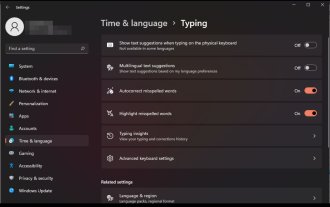 Windows 11 でスペルミスの単語の自動修正を有効または無効にする方法
Sep 19, 2023 pm 10:53 PM
Windows 11 でスペルミスの単語の自動修正を有効または無効にする方法
Sep 19, 2023 pm 10:53 PM
オートコレクトは、日常生活の時間を大幅に節約できる非常に便利な機能です。完璧ではありませんが、ほとんどの場合、スペルミスや書き込みエラーを修正するために使用できます。ただし、正常に動作しない場合もあります。一部の単語は認識されないため、効率的に作業することが困難になります。また、単に無効にして古い方法に戻したい場合もあります。しかし、オートコレクトを使用するメリットはあるのでしょうか?スペルミスを修正して時間を節約します。正しいスペルを示すことで、新しい単語を学習するのに役立ちます。メールやその他の文書での恥ずかしい間違いを避けるのに役立ちます。より速く入力できるようになり、間違いも少なくなります。 Windows 11 でスペルチェックをオンまたはオフにするにはどうすればよいですか? 1. 設定アプリを使用してキーをタップします
 百文字チョップで切り取られた言葉はどこにあるのでしょうか?何百もの単語を削除するために使用できる単語検索チュートリアル!
Mar 15, 2024 pm 03:52 PM
百文字チョップで切り取られた言葉はどこにあるのでしょうか?何百もの単語を削除するために使用できる単語検索チュートリアル!
Mar 15, 2024 pm 03:52 PM
1. 百語カットから削除された単語はどこにありますか?何百もの単語を削除するために使用できる単語検索チュートリアル! 1. ホームページに移動し、単語リストをクリックします。 2. ページにジャンプした後、切り取られた単語のオプションを選択します。 3. インターフェースに入ると、ユーザーによって切り取られた単語が表示されます。 4. 切り取られた単語を復元したい場合は、「編集」オプションをクリックします。 5. 復元する必要がある単語を見つけて、右側の切り取りアイコンをクリックして単語を復元します。 6. 学習した単語のインターフェイスに戻ると、今復元した単語が表示されます。
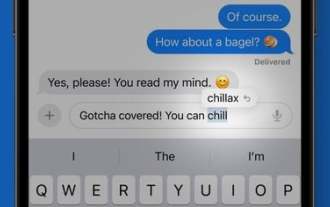 iOS 17 の予測オートコレクトを活用する方法
Sep 17, 2023 pm 03:37 PM
iOS 17 の予測オートコレクトを活用する方法
Sep 17, 2023 pm 03:37 PM
改善された機械学習テクノロジーのおかげで、Apple の iOS 17 では、iPhone でテキストを入力する際のオートコレクトがさらに便利になりました。 Appleによると、「モーファー言語モデル」を使用してオートコレクトを個々のユーザーに合わせてカスタマイズし、ユーザーの個人的な好みや単語の選択を学習して、入力時にさらに便利になるとしている。 iOS 17 を数週間使用すると、オートコレクトの提案が、ユーザーが言いたいことを予測し、クリックしてオートコンプリートするための単語を表示する機能が向上していることに気づくはずです。オートコレクトは、頭字語、短縮語、俗語、口語表現を使用する場合、オートコレクトほど積極的ではありませんが、偶発的なスペル ミスを修正することはできます。オートコレクトの修正 オートコレクトで単語が変更されると、修正された単語の下に青い線が表示されます。してもいいです
 Python を使用して文字列内の単語の長さを計算する
Sep 13, 2023 am 11:29 AM
Python を使用して文字列内の単語の長さを計算する
Sep 13, 2023 am 11:29 AM
Python を使用して特定の入力文字列内の個々の単語の長さを見つけることは、解決する必要がある問題です。テキスト入力内の各単語の文字数をカウントし、結果をリストなどの構造化されたスタイルで表示したいと考えています。このタスクでは、入力文字列を分割し、各単語を分離する必要があります。次に、単語内の文字数に基づいて各単語の長さを計算します。基本的な目標は、入力を効率的に受け取り、語長を決定し、結果をタイムリーに出力できる関数またはプロシージャを作成することです。この問題に対処することは、テキスト処理、自然言語処理、データ分析などのさまざまなアプリケーションにおいて重要です。これらのアプリケーションでは、語長の統計によって洞察力のある情報が提供され、追加の分析が可能になります。使用するメソッド ループとsplit()関数を使用する lenとsplit()でmap()関数を使用する
 iOS 17はiPhoneのオートコレクト機能の大幅な改善を約束
Jun 06, 2023 am 08:20 AM
iOS 17はiPhoneのオートコレクト機能の大幅な改善を約束
Jun 06, 2023 am 08:20 AM
Apple は本日、iPhone 向け iOS 17 をプレビューしました。このアップデートによってもたらされる主要な新機能の 1 つは、オートコレクトの改善です。 Apple によると、iOS 17 には iPhone のオートコレクトを大幅に改善する最先端の単語予測言語モデルが含まれています。入力するたびに、オンデバイスの機械学習がこれまでよりも高い精度でエラーをインテリジェントに修正します。さらに、入力時にインライン予測テキスト候補が表示されるようになり、スペースバーを押して単語を追加したり、文を完成させることができます。 iOS 17 ではオートコレクトのデザインが更新され、自動修正される単語が一時的に強調されます。下線付きの単語をクリックすると、入力した元の単語が表示されるので、変更をすぐに元に戻すことが簡単にできます。時間の経過とともに、システムはあなたのタイピングも学習します
