

あなたの友達も見ています! Google STUDY アルゴリズムは、学生が読書に夢中になる書籍リストの推奨システムをサポートしています

私たちは、本を開くことが有益であることを常に知っています。読書は言語スキルを向上させ、新しいスキルを学ぶのに役立ちます....
読書は気分や精神的健康も改善します。定期的に読書をする人は、より一般的な知識を持ち、他文化についての理解も深まります。
さらに、楽しみのために読書することが学業の成功に関連していることが研究によって確認されています。
しかし、情報爆発の時代には、オンラインおよびオフラインの読書リソースが豊富にあります。何を読むかは難しい課題になります。
特に、読書コンテンツはさまざまな年齢層にマッチし、魅力的である必要があります。
推奨システムは、この課題に対する解決策です。読者に関連する読み物を提供し、興味を維持するのに役立ちます。
レコメンデーション システムの中核となるのは機械学習 (ML) であり、ビデオから書籍、電子商取引プラットフォームまで、さまざまなタイプのレコメンデーション システムの構築に広く使用されています。
トレーニングされた ML モデルは、ユーザーの好み、ユーザー エンゲージメント、推奨アイテムに基づいて各ユーザーに個別に推奨を行うことで、ユーザー エクスペリエンスを向上させることができます。
Google の最新の研究では、読書の社会的性質 (教育環境など) を考慮したオーディオブック コンテンツ推奨システム、つまり STUDY アルゴリズムが提案されています。
同僚が現在読んでいる内容は、その人が興味を持って読んでいる内容に大きな影響を与える可能性があるため、Google は Learning Ally と提携しています。
Learning Ally は、学生向けに厳選されたオーディオブックの大規模なデジタル ライブラリを備えた教育非営利団体で、ソーシャル レコメンデーション モデルの構築に最適です。
これにより、モデルは学生の地域的な社会グループ (教室など) に関するリアルタイム情報を活用できるようになります。
STUDY アルゴリズム
STUDY アルゴリズムは、推奨コンテンツの問題をクリック率予測問題としてモデル化する方法を採用しています。
シミュレートされたユーザーと特定の各アイテムとのインタラクション確率は次の要素に依存します:
1) ユーザーとアイテムの特性
2) ユーザーのプロジェクト インタラクション履歴シーケンス。
これまでの研究では、Transformer モデルがこの問題のモデル化に適していることが示されています。
各ユーザーが個別に扱われる場合、インタラクションのシミュレーションは自己回帰シーケンス モデリングの問題になります。
STUDY アルゴリズムは、この概念的なフレームワークを通じてデータをモデル化し、このフレームワークを拡張した最終製品です。
クリックスルー率予測問題は、個々のユーザーの過去と将来のアイテムの好みの間の依存関係をモデル化し、トレーニング中にユーザー間の類似性パターンを学習できます。
しかし、1 つの問題は、クリックスルー率の予測方法では、異なるユーザー間の依存関係をモデル化できないことです。
この目的を達成するために、Google は読書の社会的性質をモデル化できない自己回帰シーケンス モデリングの欠点を解決できる STUDY モデルを開発しました。
STUDY は、クラス内の複数の生徒が読んだ本のシーケンスを 1 つのシーケンスに接続し、それによって 1 つのモデルで複数の生徒からのデータを収集できます。
ただし、このデータ表現を Transformer でモデル化する場合は、慎重に検討する必要があります。
Transformer では、アテンション マスクは、どの入力をどの出力を予測するために使用できるかを制御するマトリックスです。
シーケンス内のすべての前のトークンを使用して、上三角アテンション行列の出力結果の予測を通知するパターン。これは通常、因果デコーダーで見られます。
ただし、STUDY モデルへのシーケンス入力は時間順ではないため、コンポーネントの各サブシーケンスは時間順にありますが、従来の因果デコーダーは適切ではなくなりました。 。
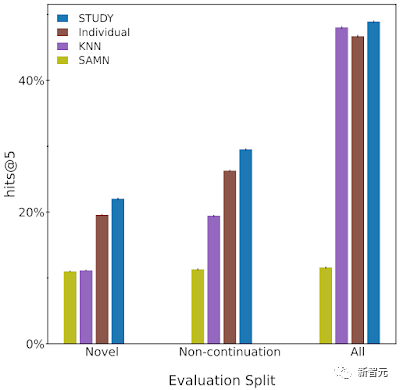
各トークンを予測しようとする際、モデルでは、シーケンス内でその前に出現する各トークンに注意を向けることはできません。これらのトークンの一部には、より後のタイムスタンプがあり、In 情報が含まれている可能性があります。導入時には利用できません。 ###############写真###### 因果デコーダで一般的に使用されるアテンション マスク。各列は出力を表し、各列は出力を表します。特定の位置の値 1 (青で表示) を持つ行列エントリは、モデルが対応する列の出力を予測するときにその行の入力を観察できることを示し、値 0 (白で表示) はその逆を示します。 。 STUDY モデルは、三角行列アテンション マスクを柔軟なタイムスタンプ ベースのアテンション マスクに置き換える因果変換に基づいており、さまざまなサブシーケンスにわたるアテンションを可能にします。 通常のコンバーターと比較して、STUDY モデルはシーケンス内で因果三角形アテンション マトリックスを維持し、タイムスタンプに応じてさまざまなシーケンスで柔軟な値を持ちます。 したがって、シーケンス内の出力ポイントの予測は、前後に発生したかどうかに関係なく、現在の時点を基準にして過去に発生したすべての入力ポイントを参照します。シーケンス内の現在の入力ポイント。 この因果的制約が重要なのは、トレーニング中にこの制約が強制されないと、モデルが将来の情報を使用して予測を行うことを学習するリスクが生じるためです。これは現実世界のデプロイメントでは不可能です。達成するために。 (a) 各ユーザーを個別に処理できる因果的注意を備えた逐次自己回帰変換器、(b) 同等のもの(a) と同じことを計算するジョイント フォワード パス、(c) アテンション マスク (紫色で表示) にゼロ以外の新しい値を導入することで、ユーザー間で情報が流れるようにします。これを行うために、インタラクションが同じユーザーからのものであるかどうかに関係なく、以前のタイムスタンプを持つすべてのインタラクションを条件として予測できるようにしました。 ## Google は Learning Ally データセットを使用して STUDY モデルをトレーニングし、比較のために複数のベースラインを使用します。 彼らは、トレーニングには 1 学年度のデータを使用し、検証とテストには 2 学年度のデータを使用しました。 チームは、ユーザーが実際に操作する次のアイテムがモデルの上位 n 個の提案内にある時間の割合を測定することによって、これらのモデルを評価します。 チームは、テスト セット全体でモデルを評価することに加えて、データセット全体よりも正確な、テスト セットの 2 つのサブセットでのモデルのスコアも報告します。 学生は通常、オーディオブックを複数回操作していることがわかります。そのため、ユーザーが最後に読んだ本を単に推奨するのは簡単ではありません。 したがって、研究者は最初のテスト サブセットを「非継続」と呼びます。このサブセットでは、学生が以前の対話とは異なる学生と対話する場合にのみ各モデルを検査します。本がインタラクティブな場合のパフォーマンス。 さらに、チームは、学生が過去に読んだ本を再訪していることも観察したため、各学生に推奨される本は、過去に読んだ本に限定されます。テスト セットで優れたパフォーマンスを達成できます。 学生に過去のお気に入りの本を勧めることにはある程度の価値があるかもしれませんが、推奨システムの価値の多くは、新しい未知のコンテンツをユーザーに勧めることから生まれます。 これを測定するために、チームは、学生が初めて参考文献を操作するテスト セットのサブセットでモデルを評価しました。この評価サブセットを「新しいサブセット」と名付けます。 「STUDY」は、ほぼすべての評価において他のモデルを上回っていることがわかります。 写真 適切なグループ分けの重要性 提案されたモデルでは、研究者は同じ学年および学校のすべての生徒をグループ化しました。 次に、同じ学年と学区内のすべての生徒によって定義されたグループ分けと、すべての生徒を 1 つのグループにグループ化し、各前方パスでランダムなサブセットを使用する実験を行いました。 研究者らはまた、参考としてこれらのモデルを「個々の」モデルと比較しました。 研究によると、よりローカライズされたグループ、つまり学区や学年のグループよりも学校や学年のグループを使用する方が効果的であることがわかっています。 これは、読書などの活動が社会的であるため、研究モデルが成功するという仮説を裏付けています。つまり、人々の読書の選択は、周囲の人々の読書の選択と相関している可能性が高いということです。 両方のモデルは、学生をグループ化するために学年レベルを使用せずに、他の 2 つのモデル (単一グループ モデルと個人モデル) を上回りました。 これは、同様の読書レベルと興味を持つユーザーからのデータがモデルのパフォーマンスの向上に有益であることを示しています。 最後に、この Google の調査は、社会的関係が同質であると仮定するユーザー グループのモデル化に限定されていました。 #参考: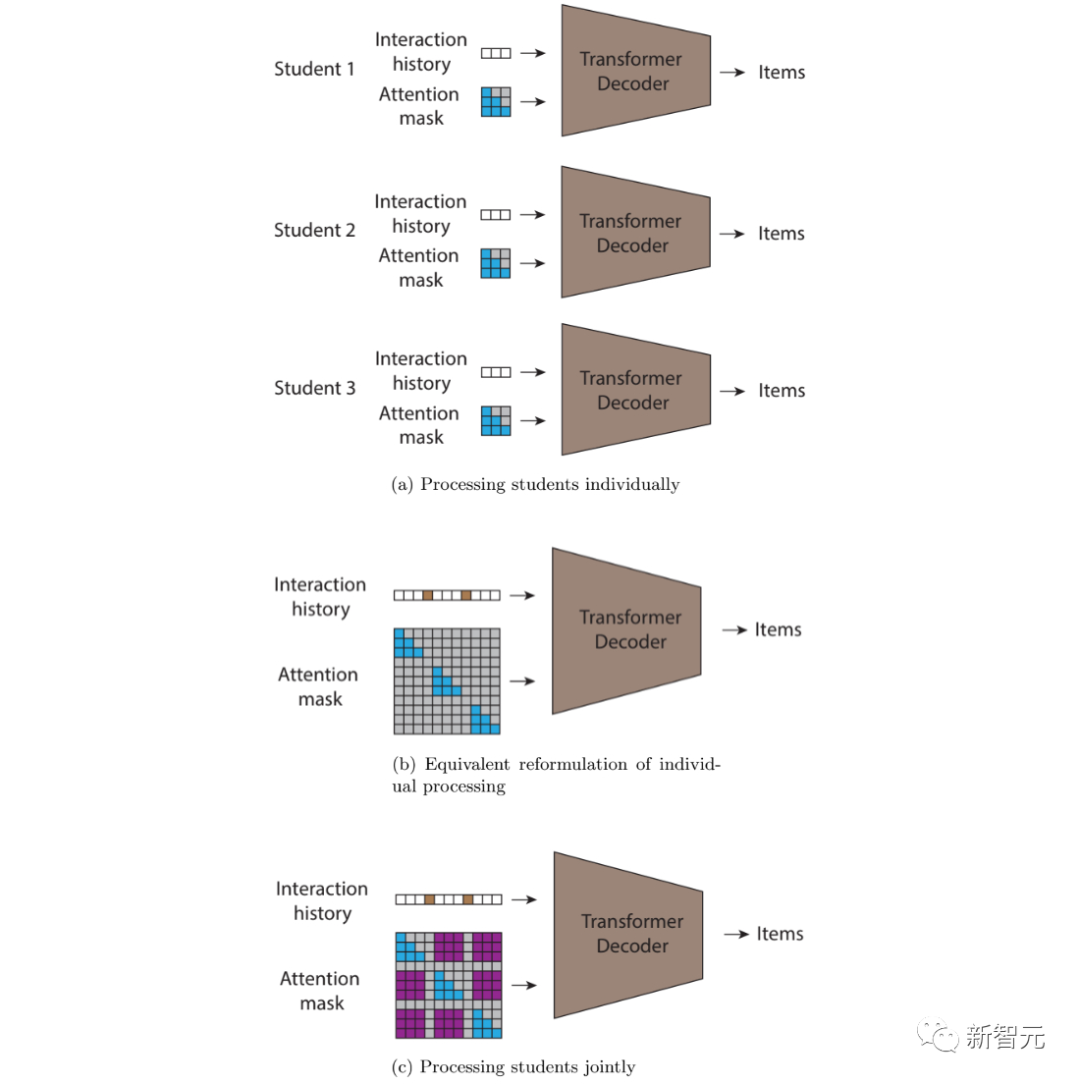 図
図チームは、自己回帰 CTR デコーダ (「個人」と呼ばれる)、k 最近傍ベースライン (KNN)、および同等のソーシャル ベースラインであるソーシャル アテンション メモリ ネットワーク (SAMN) を使用しました。
 研究の核心アルゴリズムは、ユーザーをグループにグループ化し、モデルの単一の前方パスで同じグループ内の複数のユーザーに対して共同推論を実行します。
研究の核心アルゴリズムは、ユーザーをグループにグループ化し、モデルの単一の前方パスで同じグループ内の複数のユーザーに対して共同推論を実行します。 研究者らは、アブレーション研究を通じて、モデルのパフォーマンスにおける実際のグループ化の重要性を検討しました。
以上があなたの友達も見ています! Google STUDY アルゴリズムは、学生が読書に夢中になる書籍リストの推奨システムをサポートしていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1384
52
83
11
28
96
15
1384
52
83
11
28
96

 Microsoft Word で作成者と最終変更情報を削除する方法
Apr 15, 2023 am 11:43 AM
Microsoft Word で作成者と最終変更情報を削除する方法
Apr 15, 2023 am 11:43 AM
Microsoft Word ドキュメントには、保存時にいくつかのメタデータが含まれます。これらの詳細は、作成日、作成者、変更日など、ドキュメントの識別に使用されます。文字数、単語数、段落数などの他の情報もあります。他の人に値が知られないよう、作成者や最終更新情報、その他の情報を削除したい場合は、方法があります。この記事では、ドキュメントの作成者と最終変更情報を削除する方法を見てみましょう。 Microsoft Word 文書から作成者と最終変更情報を削除する ステップ 1 – 次のページに移動します。
 Windows 11 で GPU を取得し、グラフィックス カードの詳細を確認する方法
Nov 07, 2023 am 11:21 AM
Windows 11 で GPU を取得し、グラフィックス カードの詳細を確認する方法
Nov 07, 2023 am 11:21 AM
システム情報の使用 [スタート] をクリックし、システム情報を入力します。下の画像に示すようにプログラムをクリックするだけです。ここではほとんどのシステム情報が見つかりますが、グラフィック カード情報も見つかります。システム情報プログラムで、「コンポーネント」を展開し、「表示」をクリックします。プログラムに必要な情報をすべて収集させ、準備が完了すると、システム上でグラフィックス カード固有の名前やその他の情報を見つけることができます。複数のグラフィックス カードをお持ちの場合でも、コンピュータに接続されている専用および統合グラフィックス カードに関連するほとんどのコンテンツをここから見つけることができます。デバイス マネージャーの使用 Windows 11 他のほとんどのバージョンの Windows と同様に、デバイス マネージャーからコンピューター上のグラフィック カードを見つけることもできます。 「開始」をクリックしてから、
 NameDrop で連絡先の詳細を共有する方法: iOS 17 のハウツー ガイド
Sep 16, 2023 pm 06:09 PM
NameDrop で連絡先の詳細を共有する方法: iOS 17 のハウツー ガイド
Sep 16, 2023 pm 06:09 PM
iOS 17には、2台のiPhoneをタッチすることで誰かと連絡先情報を交換できる新しいAirDrop機能があります。これは NameDrop と呼ばれるもので、その仕組みは次のとおりです。 NameDrop を使用すると、新しい相手の電話番号を入力して電話したりテキストメッセージを送信したりする代わりに、iPhone を相手の iPhone の近くに置くだけで連絡先の詳細を交換できるため、相手はあなたの番号を知ることができます。 2 つのデバイスを組み合わせると、連絡先共有インターフェイスが自動的にポップアップ表示されます。ポップアップをクリックすると、個人の連絡先情報と連絡先ポスターが表示されます(自分の写真をカスタマイズして編集できます。これも iOS17 の新機能です)。この画面には、「受信のみ」するか、応答として自分の連絡先情報を共有するかのオプションも含まれています。
 シングルビュー NeRF アルゴリズム S^3-NeRF は、マルチイルミネーション情報を使用してシーンのジオメトリとマテリアル情報を復元します。
Apr 13, 2023 am 10:58 AM
シングルビュー NeRF アルゴリズム S^3-NeRF は、マルチイルミネーション情報を使用してシーンのジオメトリとマテリアル情報を復元します。
Apr 13, 2023 am 10:58 AM
現在の画像 3D 再構成作業では、通常、一定の自然光条件下で複数の視点 (マルチビュー) からターゲット シーンをキャプチャする多視点ステレオ再構成手法 (マルチビュー ステレオ) が使用されます。ただし、これらの方法は通常、ランバート曲面を前提としており、高周波の詳細を復元するのが困難です。シーン再構築のもう 1 つのアプローチは、固定視点から異なる点光源でキャプチャされた画像を利用することです。たとえば、フォトメトリック ステレオ法では、この設定を採用し、そのシェーディング情報を使用して、非ランバーシアン オブジェクトの表面の詳細を再構成します。ただし、既存のシングルビュー手法は通常、可視領域を表現するために法線マップまたは深度マップを使用します。
 Yuanverse Virtual Reality Application Education Summit Forumが鄭州で開催されました
Nov 30, 2023 pm 08:33 PM
Yuanverse Virtual Reality Application Education Summit Forumが鄭州で開催されました
Nov 30, 2023 pm 08:33 PM
鄭州でメタバース仮想現実応用教育サミットフォーラムが開催され、メタバース仮想現実応用教育サミットフォーラムでは、河南芸術専門学校教師の董玉山氏によるダンス「Floating Light」が軽やかで優しいダンスを披露した。同時に、仮想の人々も Yuanverse 空間で同期して踊りました. 彼らの滑らかで優雅なダンスの姿勢は多くのゲストを驚かせました. 11 月 24 日、鄭州で Yuanverse 仮想現実アプリケーション教育サミット フォーラムが開催されました. 業界の専門家と学者が焦点を当てました科学研究機関、大学、業界団体、有名企業の代表者が集まり、Yuanverseの開発動向について話し合った。 「メタバースは近年頻繁に話題になっており、アニメーション業界に無限の可能性をもたらした」と河南アニメーション産業協会副会長の王暁東氏は講演の中で、近年中国は次のように述べた。
 iPhone での NameDrop の仕組み (および無効にする方法)
Nov 30, 2023 am 11:53 AM
iPhone での NameDrop の仕組み (および無効にする方法)
Nov 30, 2023 am 11:53 AM
iOS17では、2台のiPhoneを同時にタッチすることで連絡先を交換できるAirDrop機能が新たに搭載されました。これは NameDrop と呼ばれるもので、実際にどのように機能するかは次のとおりです。 NameDrop を使用すると、新しい相手に電話をかけたりテキストメッセージを送信したりする際に相手の番号を入力する必要がなく、相手があなたの番号を知ることができるので、iPhone を相手の iPhone に近づけるだけで連絡先情報を交換できます。 2 つのデバイスを組み合わせると、連絡先共有インターフェイスが自動的にポップアップ表示されます。ポップアップをクリックすると、個人の連絡先情報と連絡先ポスター (カスタマイズおよび編集できる自分の写真、これも iOS 17 の新機能) が表示されます。この画面には、「受信のみ」または応答として自分の連絡先情報を共有することも含まれます
 WeChat でメッセージの受信が遅れる理由は何ですか?
Sep 19, 2023 pm 03:02 PM
WeChat でメッセージの受信が遅れる理由は何ですか?
Sep 19, 2023 pm 03:02 PM
WeChat の情報受信が遅れる理由には、ネットワークの問題、サーバーの負荷、バージョンの問題、デバイスの問題、メッセージ送信の問題、またはその他の要因が考えられます。詳細な紹介: 1. ネットワークの問題。WeChat での情報受信の遅延は、ネットワーク接続に関連している可能性があります。ネットワーク接続が不安定または信号が弱い場合、情報送信に遅延が発生する可能性があります。携帯電話が正常に動作していることを確認してください。安定したネットワークに接続されており、ネットワーク信号強度が良好であること; 2. サーバー負荷 WeChat サーバーの負荷が高い場合、特に繁忙期や多数のユーザーが WeChat を使用している場合、情報送信に遅延が発生する可能性があります。同じ時間など。
 Ant Marketing の推奨シナリオにおける因果関係修正手法の適用
Jan 13, 2024 pm 12:15 PM
Ant Marketing の推奨シナリオにおける因果関係修正手法の適用
Jan 13, 2024 pm 12:15 PM
1. 因果関係修正の背景 1. レコメンデーションシステムにズレが生じる レコメンドモデルは、データを収集して学習し、ユーザーに適切なアイテムをレコメンドします。ユーザーが推奨アイテムを操作すると、収集されたデータはモデルをさらにトレーニングするために使用され、閉ループが形成されます。ただし、この閉ループにはさまざまな影響要因が存在し、エラーが発生する可能性があります。エラーの主な理由は、モデルのトレーニングに使用されるデータのほとんどが理想的なトレーニング データではなく観測データであり、露出戦略やユーザーの選択などの要因の影響を受けることです。このバイアスの本質は、経験的なリスク推定値の期待値と真の理想的なリスク推定値の期待値の違いにあります。 2. 一般的なバイアス レコメンデーション マーケティング システムにおける一般的なバイアスには、主に 3 つのタイプがあります: 選択的バイアス: ユーザーのルートに起因します。
