

UniOcc: 視覚中心の占有予測を幾何学的およびセマンティック レンダリングと統合します。

原題: UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering
論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/pdf/2306.09117.pdf

ペーパーアイデア:
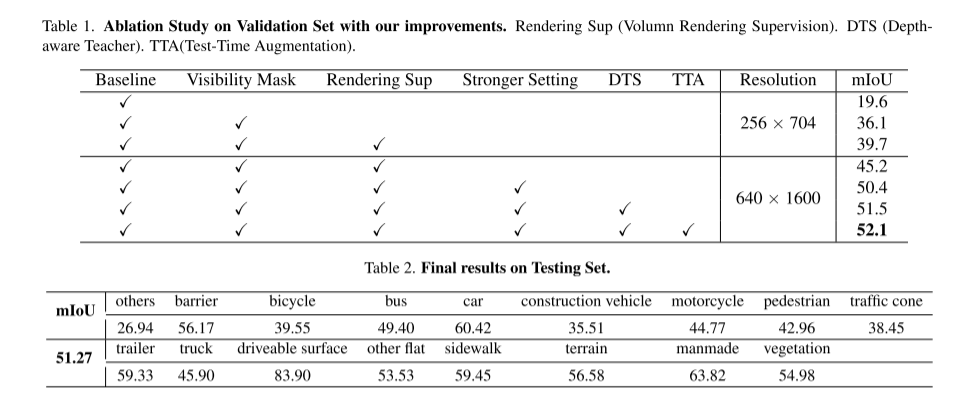
この技術レポートでは、CVPR 2023 ビジョン中心の nuScenes で使用するための UniOCC と呼ばれるソリューションを提案します。 3D 占有予測軌跡は、Open Dataset Challenge で実行されます。既存の占有予測方法は、主に 3D 占有ラベルを使用して 3D 体積空間の投影特性を最適化することに重点を置いています。ただし、これらのラベルの生成プロセスは非常に複雑でコストがかかり(3D セマンティック アノテーションに依存)、ボクセル解像度によって制限され、きめ細かい空間セマンティクスを提供できません。この制限に対処するために、空間幾何学的制約を明示的に課し、ボリューム レイ レンダリングによるきめ細かいセマンティック監視を補足する、新しい統合占有 (UniOcc) 予測方法を提案します。私たちの方法はモデルのパフォーマンスを大幅に向上させ、手動によるアノテーションのコスト削減に大きな可能性を示しています。 3D 占有状況に注釈を付ける手間を考慮して、ラベルなしデータを使用して予測精度を向上させるために、深さを認識した教師生徒 (DTS) フレームワークをさらに提案します。当社のソリューションは、公式の単一モデル ランキングで 51.27% の mIoU を達成し、この課題で 3 位にランクされました
ネットワーク設計:
こちらこの課題の一環として、この文書では次のことを提案します。 UniOcc は、ボリューム レンダリングを利用して 2D 表現と 3D 表現の監視を統合し、マルチカメラ占有予測モデルを改善する一般的なソリューションです。このペーパーでは、新しいモデル アーキテクチャを設計するのではなく、多用途かつプラグ アンド プレイの方法で既存のモデル [3、18、20] を強化することに焦点を当てています。
次のように書き直します: この論文では、表現を NeRF スタイルの表現にアップグレードすることで、ボリューム レンダリングを使用して 2D セマンティック マップと深度マップを生成する機能を実装します [1,15,21]。これにより、2D ピクセル レベルでのきめ細かい監視が可能になります。 3 次元ボクセルをレイ サンプリングすることにより、レンダリングされた 2 次元ピクセル セマンティクスと深度情報を取得できます。幾何学的オクルージョン関係とセマンティック一貫性制約を明示的に統合することにより、この論文はモデルに明示的なガイダンスを提供し、これらの制約への準拠を保証します。UniOcc には高価な 3D セマンティック アノテーションの必要性を削減する可能性があることは言及する価値があります。 3D 占有ラベルがない場合、ボリューム レンダリング監視のみを使用してトレーニングされたモデルは、3D ラベル監視を使用してトレーニングされたモデルよりもさらに優れたパフォーマンスを発揮します。これは、シーン表現を手頃な価格の 2D セグメンテーション ラベルから直接学習できるため、高価な 3D セマンティック アノテーションへの依存を軽減できる素晴らしい可能性を強調しています。さらに、SAM [6] や [14,19] などの高度なテクノロジーを使用すると、2D セグメンテーション アノテーションのコストをさらに削減できます。
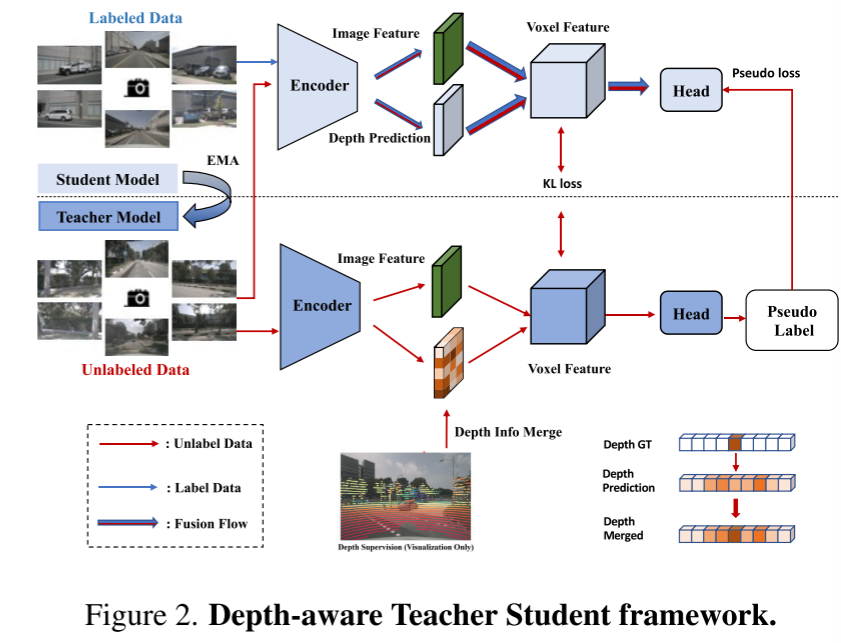
この記事では、自己教師ありトレーニング方法であるディープ センシング教師-生徒 (DTS) フレームワークについても紹介します。従来の Mean Teacher とは異なり、DTS は教師モデルの詳細な予測を強化し、ラベルなしのデータを利用しながら安定した効果的なトレーニングを実現します。さらに、このペーパーでは、モデルのパフォーマンスを向上させるために、いくつかのシンプルだが効果的な手法を適用します。これには、トレーニングでの可視マスクの使用、より強力な事前トレーニングされたバックボーン ネットワークの使用、ボクセル解像度の向上、およびテスト時データ拡張 (TTA) の実装が含まれます。 UniOcc フレームワークの概要: 図 1
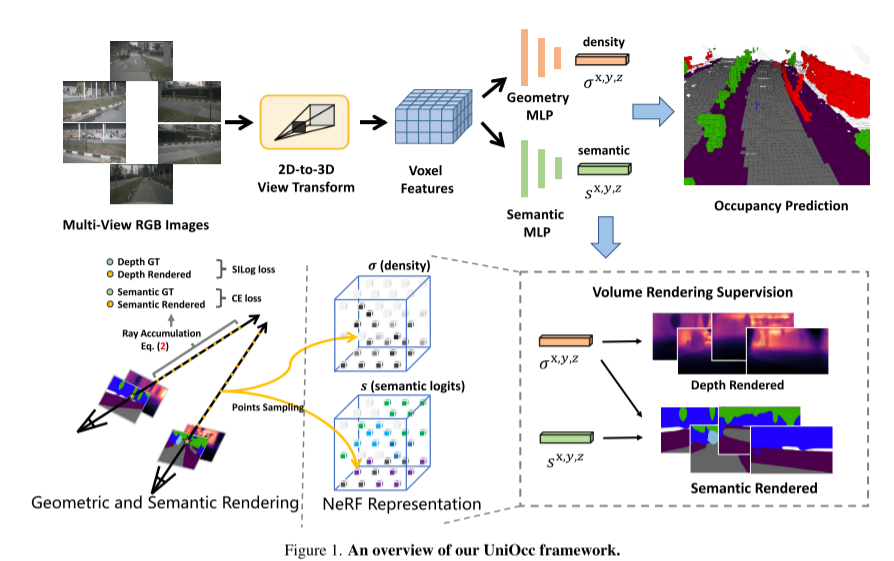 図 2。奥行きを意識した教師と生徒のフレームワーク。
図 2。奥行きを意識した教師と生徒のフレームワーク。
#引用:

元のリンク: https://mp.weixin.qq.com/s/iLPHMtLzc5z0f4bg_W1vIg
以上がUniOcc: 視覚中心の占有予測を幾何学的およびセマンティック レンダリングと統合します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7470
7470
 15
1377
52
77
11
19
29
15
1377
52
77
11
19
29

 Windows 11 のスマート アプリ コントロール: オンまたはオフにする方法
Jun 06, 2023 pm 11:10 PM
Windows 11 のスマート アプリ コントロール: オンまたはオフにする方法
Jun 06, 2023 pm 11:10 PM
インテリジェント アプリ コントロールは、ランサムウェアやスパイウェアなど、データに損害を与える可能性のある不正なアプリから PC を保護する Windows 11 の非常に便利なツールです。この記事では、スマート アプリ コントロールとは何か、その仕組み、および Windows 11 でスマート アプリ コントロールをオンまたはオフにする方法について説明します。 Windows 11 のスマート アプリ コントロールとは何ですか? Smart App Control (SAC) は、Windows 1122H2 更新プログラムで導入された新しいセキュリティ機能です。 Microsoft Defender またはサードパーティのウイルス対策ソフトウェアと連携して、デバイスの速度を低下させたり、予期しない広告を表示したり、その他の予期しないアクションを実行したりする可能性のある不要なアプリをブロックします。スマートなアプリケーション
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 飛び回ったり、口を開けたり、見つめたり、眉毛を上げたりする顔の特徴をAIが完璧に模倣し、ビデオ詐欺を防ぐことは不可能
Dec 14, 2023 pm 11:30 PM
飛び回ったり、口を開けたり、見つめたり、眉毛を上げたりする顔の特徴をAIが完璧に模倣し、ビデオ詐欺を防ぐことは不可能
Dec 14, 2023 pm 11:30 PM
これほど強力なAIの模倣能力では、それを防ぐことは本当に不可能です。 AIの発展は今ここまで進んでいるのか?前足で顔の特徴を浮き上がらせ、後ろ足で全く同じ表情を再現し、見つめたり、眉を上げたり、口をとがらせたり、どんなに大袈裟な表情でも完璧に真似しています。難易度を上げて、眉毛を高く上げ、目を大きく開き、口の形も歪んでいるなど、バーチャルキャラクターアバターで表情を完璧に再現できます。左側のパラメータを調整すると、右側の仮想アバターもそれに合わせて動きが変化し、口や目の部分がアップになります。同じです(右端)。この研究は、GaussianAvatars を提案するミュンヘン工科大学などの機関によるものです。
 NeRFとは何ですか? NeRF ベースの 3D 再構成はボクセルベースですか?
Oct 16, 2023 am 11:33 AM
NeRFとは何ですか? NeRF ベースの 3D 再構成はボクセルベースですか?
Oct 16, 2023 am 11:33 AM
1 はじめに Neural Radiation Fields (NeRF) は、深層学習とコンピューター ビジョンの分野におけるかなり新しいパラダイムです。この技術は、ECCV2020 の論文「NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis」(最優秀論文賞を受賞) で紹介され、それ以来非常に人気となり、現在までに 800 件近く引用されています [1]。このアプローチは、機械学習による 3D データの従来の処理方法に大きな変化をもたらします。神経放射線場のシーン表現と微分可能なレンダリング プロセス: カメラ光線に沿って 5D 座標 (位置と視線方向) をサンプリングして画像を合成し、これらの位置を MLP に入力して色と体積密度を生成し、体積レンダリング技術を使用してこれらの値を合成します。 ; レンダリング関数は微分可能であるため、渡すことができます。
 自動運転の初の純粋な視覚的静的再構築
Jun 02, 2024 pm 03:24 PM
自動運転の初の純粋な視覚的静的再構築
Jun 02, 2024 pm 03:24 PM
純粋に視覚的な注釈ソリューションでは、主に視覚に加えて、GPS、IMU、および車輪速度センサーからのデータを動的注釈に使用します。もちろん、量産シナリオでは、純粋な視覚である必要はありません。一部の量産車両には固体レーダー (AT128) などのセンサーが搭載されています。大量生産の観点からデータの閉ループを作成し、これらすべてのセンサーを使用すると、動的オブジェクトのラベル付けの問題を効果的に解決できます。しかし、私たちの計画には固体レーダーはありません。したがって、この最も一般的な量産ラベル ソリューションを紹介します。純粋に視覚的な注釈ソリューションの中核は、高精度のポーズ再構築にあります。再構築の精度を確保するために、Structure from Motion (SFM) のポーズ再構築スキームを使用します。でもパスする
 MotionLM: マルチエージェント動作予測のための言語モデリング技術
Oct 13, 2023 pm 12:09 PM
MotionLM: マルチエージェント動作予測のための言語モデリング技術
Oct 13, 2023 pm 12:09 PM
この記事は自動運転ハート公式アカウントより許可を得て転載しておりますので、転載については出典元までご連絡ください。原題: MotionLM: Multi-Agent Motion Forecasting as Language Modeling 論文リンク: https://arxiv.org/pdf/2309.16534.pdf 著者の所属: Waymo 会議: ICCV2023 論文のアイデア: 自動運転車の安全計画のために、将来の動作を確実に予測するロードエージェントの数は非常に重要です。この研究では、連続的な軌跡を離散的なモーション トークンのシーケンスとして表現し、マルチエージェントのモーション予測を言語モデリング タスクとして扱います。私たちが提案するモデル MotionLM には次の利点があります。
 Occと自動運転の過去と現在を見てみよう!最初のレビューでは、機能強化/量産展開/アノテーションの効率化という 3 つの主要テーマを包括的にまとめています。
May 08, 2024 am 11:40 AM
Occと自動運転の過去と現在を見てみよう!最初のレビューでは、機能強化/量産展開/アノテーションの効率化という 3 つの主要テーマを包括的にまとめています。
May 08, 2024 am 11:40 AM
以上、筆者個人の理解 近年、自動運転はドライバーの負担軽減や運転の安全性の向上につながる可能性があるため、注目が高まっています。ビジョンベースの 3 次元占有予測は、自動運転の安全性に関する費用対効果の高い包括的な調査に適した新たな認識タスクです。オブジェクト中心の知覚タスクと比較して 3D 占有予測ツールの優位性は多くの研究で実証されていますが、この急速に発展している分野に特化したレビューはまだあります。このホワイトペーパーでは、まずビジョンベースの 3D 占有予測の背景を紹介し、このタスクで直面する課題について説明します。次に、現在の 3D 占有予測手法の現状と開発傾向を、機能強化、展開の容易さ、ラベル付けの効率という 3 つの側面から包括的に説明します。やっと
 数年後にはプログラマーが減少するということをご存知ですか?
Nov 08, 2023 am 11:17 AM
数年後にはプログラマーが減少するということをご存知ですか?
Nov 08, 2023 am 11:17 AM
「ComputerWorld」誌はかつて、IBM がエンジニアが必要な数式を書いて提出できる新しい言語 FORTRAN を開発したため、「プログラミングは 1960 年までに消滅するだろう」という記事を書きました。コンピューターを実行すればプログラミングは終了します。画像 数年後、私たちは新しいことわざを聞きました: ビジネスマンは誰でもビジネス用語を使って問題を説明し、コンピュータに何をすべきかを伝えることができます。COBOL と呼ばれるこのプログラミング言語を使用することで、企業はもはやプログラマーを必要としません。その後、IBM は従業員がフォームに記入してレポートを作成できるようにする RPG と呼ばれる新しいプログラミング言語を開発したと言われており、会社のプログラミング ニーズのほとんどはこれで完了できます。
