

パターン検索用の Rabin-Karp アルゴリズムの C プログラム


C のパターン マッチング- 文字列が別の文字列内に存在するかどうかを確認する必要があります。たとえば、文字列 "algorithm" が "naive Algorithm" の文字列内に存在するかどうかを確認する必要があります。 」。見つかった場合は、その場所 (つまり、どこにあるか) が表示されます。私たちは 2 文字の配列を受け取り、一致するものがあればその位置を返す関数を作成する傾向があります。 それ以外の場合は、-1 が返されます。
Input: txt = "HERE IS A NICE CAP" pattern = "NICE" Output: Pattern found at index 10 Input: txt = "XYZXACAADXYZXYZX" pattern = "XYZX" Output: Pattern found at index 0 Pattern found at index 9 Pattern found at index 12
Rabin-Karp は、別のパターン検索アルゴリズムです。単なる文字列マッチング パターンをより効率的に見つけるために Rabin と Karp によって提案されたアルゴリズム 方法。単純なアルゴリズムと同様に、ウィンドウを移動してパターンをチェックします。 ハッシュを 1 つずつ検索しますが、あらゆる場合にすべての文字をチェックする必要はありません。ハッシュが一致すると、各文字がチェックされます。この方法では、テキスト サブシーケンスごとに比較が 1 回だけ行われるため、より効率的なパターン検索アルゴリズムになります。
前処理時間 - O(m)
Rabin-Karp アルゴリズムの時間計算量は O(m n) ですが、最悪の場合です。 、 O(mn)です。
アルゴリズム
rabinkarp_algo(テキスト、パターン、プライム)
入力 rabinkarp_algo(テキスト、パターン、プライム) Input Strong>- テキストとパターン。ハッシュ位置で別の素数を見つけます 出力- パターンの位置を見つけます ライブ デモンストレーション 以上がパターン検索用の Rabin-Karp アルゴリズムの C プログラムの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。Start
pat_len := pattern Length
str_len := string Length
patHash := 0 and strHash := 0, h := 1
maxChar := total number of characters in character set
for index i of all character in the pattern, do
h := (h*maxChar) mod prime
for all character index i of pattern, do
patHash := (maxChar*patHash + pattern[i]) mod prime
strHash := (maxChar*strHash + text[i]) mod prime
for i := 0 to (str_len - pat_len), do
if patHash = strHash, then
for charIndex := 0 to pat_len -1, do
if text[i+charIndex] ≠ pattern[charIndex], then
break
if charIndex = pat_len, then
print the location i as pattern found at i position.
if i < (str_len - pat_len), then
strHash := (maxChar*(strHash – text[i]*h)+text[i+patLen]) mod prime, then
if strHash < 0, then
strHash := strHash + prime
EndExample
#include<stdio.h>
#include<string.h>
int main (){
char txt[80], pat[80];
int q;
printf ("Enter the container string </p><p>");
scanf ("%s", &txt);
printf ("Enter the pattern to be searched </p><p>");
scanf ("%s", &pat);
int d = 256;
printf ("Enter a prime number </p><p>");
scanf ("%d", &q);
int M = strlen (pat);
int N = strlen (txt);
int i, j;
int p = 0;
int t = 0;
int h = 1;
for (i = 0; i < M - 1; i++)
h = (h * d) % q;
for (i = 0; i < M; i++){
p = (d * p + pat[i]) % q;
t = (d * t + txt[i]) % q;
}
for (i = 0; i <= N - M; i++){
if (p == t){
for (j = 0; j < M; j++){
if (txt[i + j] != pat[j])
break;
}
if (j == M)
printf ("Pattern found at index %d </p><p>", i);
}
if (i < N - M){
t = (d * (t - txt[i] * h) + txt[i + M]) % q;
if (t < 0)
t = (t + q);
}
}
return 0;
}出力
Enter the container string
tutorialspointisthebestprogrammingwebsite
Enter the pattern to be searched
p
Enter a prime number
3
Pattern found at index 8
Pattern found at index 21

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7526
7526
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 以下を中国語に翻訳してください: ローマ数字を 10 進数に変換する C プログラム
Sep 05, 2023 pm 09:53 PM
以下を中国語に翻訳してください: ローマ数字を 10 進数に変換する C プログラム
Sep 05, 2023 pm 09:53 PM
以下に、ローマ数字を 10 進数に変換する C 言語アルゴリズムを示します。 アルゴリズム ステップ 1 - 開始 ステップ 2 - 実行時にローマ数字を読み取る ステップ 3 - 長さ: = strlen(roman) ステップ 4 - i=0 から長さ-1 の場合 ステップ4.1-switch(roman[i]) ステップ 4.1.1-case'm': &nbs
 2 つの文字列の辞書編集上の順序を比較する C++ プログラム
Sep 04, 2023 pm 05:13 PM
2 つの文字列の辞書編集上の順序を比較する C++ プログラム
Sep 04, 2023 pm 05:13 PM
辞書編集的な文字列比較とは、文字列が辞書順に比較されることを意味します。たとえば、「apple」と「appeal」という 2 つの文字列がある場合、「app」の最初の 3 文字が同じであるため、最初の文字列が最後に来ます。次に、最初の文字列の文字は「l」で、2 番目の文字列の 4 番目の文字は「e」になります。 「e」は「l」より短いため、辞書順に並べ替えると最初に表示されます。文字列は配置される前に辞書順に比較されます。この記事では、C++ を使用して 2 つの文字列を辞書編集的に比較するためのさまざまな手法を見ていきます。 C++ 文字列での Compare() 関数の使用 C++string オブジェクトには Compare() があります。
 指定された値を引数として受け取る逆双曲線正弦関数の値を見つける C++ プログラム
Sep 17, 2023 am 10:49 AM
指定された値を引数として受け取る逆双曲線正弦関数の値を見つける C++ プログラム
Sep 17, 2023 am 10:49 AM
双曲線関数は、円の代わりに双曲線を使用して定義され、通常の三角関数と同等です。ラジアン単位で指定された角度から双曲線正弦関数の比率パラメーターを返します。しかし、その逆、つまり別の言い方をすればいいのです。双曲線正弦から角度を計算したい場合は、双曲線逆正弦演算のような逆双曲線三角関数演算が必要です。このコースでは、C++ で双曲線逆サイン (asinh) 関数を使用し、ラジアン単位の双曲線サイン値を使用して角度を計算する方法を説明します。双曲線逆正弦演算は次の式に従います -$$\mathrm{sinh^{-1}x\:=\:In(x\:+\:\sqrt{x^2\:+\:1})}ここで\:In\:is\:自然対数\:(log_e\:k)
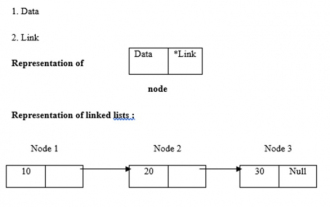 リンクリストの長さを求めるCプログラム
Sep 07, 2023 pm 07:33 PM
リンクリストの長さを求めるCプログラム
Sep 07, 2023 pm 07:33 PM
リンク リストは動的なメモリ割り当てを使用します。つまり、リンク リストはそれに応じて拡大および縮小します。これらはノードのコレクションとして定義されます。ここで、ノードにはデータとリンクという 2 つの部分があります。データ、リンク、リンクリストの表現は以下のとおりです。 ・リンクリストの種類 リンクリストには以下の4種類があります。 ・シングルリンクリスト/シングルリンクリスト ダブル/ダブルリンクリスト 循環シングルリンクリスト 循環ダブルリンクリスト再帰的メソッドを使用してリンク リストの長さを確認します。ロジックは -intlength(node *temp){ if(temp==NULL) returnl; else{&n
 C プログラムは rename() 関数を使用してファイル名を変更します
Sep 21, 2023 pm 10:01 PM
C プログラムは rename() 関数を使用してファイル名を変更します
Sep 21, 2023 pm 10:01 PM
名前変更機能は、ファイルまたはディレクトリを古い名前から新しい名前に変更します。この操作は移動操作と似ています。したがって、この名前変更機能を使用してファイルを移動することもできます。この関数は、stdio.h ライブラリ ヘッダー ファイルに存在します。 rename 関数の構文は次のとおりです: intrename(constchar*oldname,constchar*newname); rename() 関数は 2 つのパラメータを受け取ります。 1 つは古い名前、もう 1 つは新しい名前です。どちらのパラメータも、ファイルの古い名前と新しい名前を定義する定数文字へのポインタです。ファイルの名前が正常に変更された場合はゼロを返し、それ以外の場合はゼロ以外の整数を返します。名前変更操作中
 辞書を印刷する C++ プログラム
Sep 11, 2023 am 10:33 AM
辞書を印刷する C++ プログラム
Sep 11, 2023 am 10:33 AM
マップは C++ の特別なタイプのコンテナで、各要素は 2 つの値、つまりキー値とマップ値のペアです。キー値は各項目のインデックス付けに使用され、マップされた値はキーに関連付けられた値です。マップされた値が一意であるかどうかに関係なく、キーは常に一意です。 C++ でマップ要素を出力するには、反復子を使用する必要があります。項目のセット内の要素は、反復子オブジェクトによって示されます。イテレータは主に配列や他のタイプのコンテナ (ベクトルなど) で使用され、特定の範囲内の特定の要素を識別するために使用できる特定の操作セットを備えています。イテレータをインクリメントまたはデクリメントして、範囲またはコンテナ内に存在するさまざまな要素を参照できます。イテレータは、範囲内の特定の要素のメモリ位置を指します。イテレータを使用して C++ でマップを出力する まず、定義方法を見てみましょう。
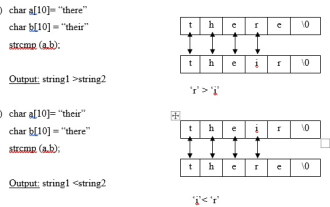 strncmp ライブラリ関数を使用して 2 つの文字列を比較する C プログラムを作成します。
Sep 09, 2023 pm 01:17 PM
strncmp ライブラリ関数を使用して 2 つの文字列を比較する C プログラムを作成します。
Sep 09, 2023 pm 01:17 PM
Strncmp は、string.h ファイル内に存在する定義済みライブラリ関数で、2 つの文字列を比較し、どちらの文字列が大きいかを表示するために使用されます。 strcmp 関数 (文字列比較) この関数は 2 つの文字列を比較します。 2 つの文字列内の最初の不一致文字の ASCII 差異を返します。構文 intstrcmp(string1,string2); 差がゼロに等しい場合は、string1=string2 となります。差が正の場合、文字列 1 > 文字列 2 になります。差が負の場合は、string1<string2 となります。 strncmp 関数の例 この関数は、2 つの文字列の最初の n 文字を比較するために使用されます。構文 strn
 文字がアルファベットか非アルファベットかをチェックする C++ プログラム
Sep 14, 2023 pm 03:37 PM
文字がアルファベットか非アルファベットかをチェックする C++ プログラム
Sep 14, 2023 pm 03:37 PM
論理プログラミングの問題を解決する場合、文字列または文字の使用が非常に役立つ場合があります。文字列は文字の集合であり、ASCII 値の記号を保持するために使用される 1 バイトのデータ型です。記号には、英文字、数字、または特殊文字を使用できます。この記事では、C++ を使用して文字が英語文字かアルファベット文字かを確認する方法を学びます。 isalpha() 関数のチェック 数値が文字であるかどうかをチェックするには、ctype.h ヘッダー ファイルの isalpha() 関数を使用できます。これは文字を入力として受け取り、それがアルファベットの場合は true を返し、そうでない場合は false を返します。この関数の使用法を理解するために、次の C++ 実装を見てみましょう。 Example の中国語訳は次のとおりです。
