
 テクノロジー周辺機器
AI
Tencent、分散型ベクトル化統計分析と因果推論をサポートするオープンソース データ コンポーネント Fast-Causal-Inference をリリース
テクノロジー周辺機器
AI
Tencent、分散型ベクトル化統計分析と因果推論をサポートするオープンソース データ コンポーネント Fast-Causal-Inference をリリース
Tencent、分散型ベクトル化統計分析と因果推論をサポートするオープンソース データ コンポーネント Fast-Causal-Inference をリリース

Tencent は、オープンソースの分散型データ サイエンス コンポーネント プロジェクト Fast-Causal-Inference が GitHub で一般公開されたことを公開アカウント「Tencent Open Source」で発表しました
 ▲ 画像ソース " Tencent Open Source」パブリックアカウント
▲ 画像ソース " Tencent Open Source」パブリックアカウント
は Tencent WeChat によって開発され、SQL インタラクションを使用し、分散ベクトル化に基づく統計分析および因果推論計算ライブラリであることが報告されています、 「ビッグデータ下での既存の統計モデル ライブラリ (R/Python) のパフォーマンスのボトルネックを解決し、数百億のデータを秒単位で実行できる因果推論機能を提供し、同時に使用のしきい値を下げる」と言われています。 SQL 言語による統計モデルにより、運用環境での使用が容易になり、WeChat ビデオ アカウントや WeChat 検索など、複数の社内 WeChat ビジネスに適用されています。」
正式な紹介:
Basic Causal Inference Tool数秒で大量のデータを実行するための因果推論を提供します。 機能
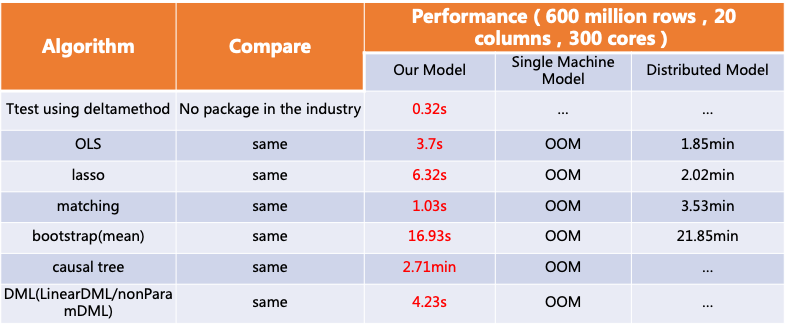
#ベクトル化された OLAP 実行エンジン ClickHouse/StarRocks を活用することで、ユーザー エクスペリエンスの速度をさらに向上させ、究極のレベルに到達できます
#最小限の SQL 使用法SQLGateway WebServer は、SQL 言語を通じて統計モデルを使用するためのしきい値を下げ、上位層で最小限の SQL 使用方法を提供します。 、エンジン関連の SQL 拡張と最適化を透過的に実行します。
基本演算子、高次演算子、および上位層アプリケーションのカプセル化の因果推論機能を提供します
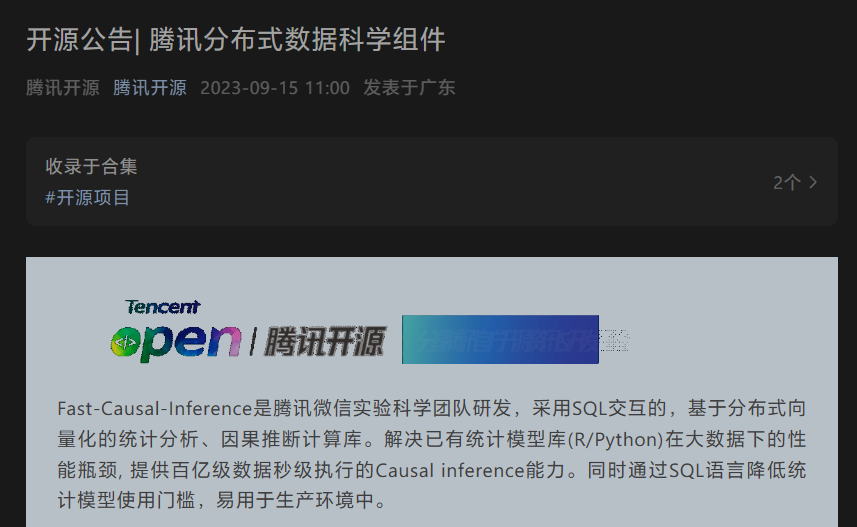
ttest、OLS、Lasso、ツリーベースをサポートモデル、マッチング、ブートストラップ、DML など。
#このサイトでは、公式が最初のバージョンですでに次の機能をサポートしていると述べていることも知りました:
 基本演算子、高次演算子、および上位層アプリケーションのカプセル化の因果推論機能を提供します
基本演算子、高次演算子、および上位層アプリケーションのカプセル化の因果推論機能を提供します
deltamethod に基づくテスト、CUPED
- OLS、10 億行のデータ、サブセカンドレベルをサポート
- ##高度な因果推論ツール
OLS ベースの IV、WLS、およびその他の GLS、DID、合成制御、CUPED、メディエーションがインキュベート中
uplift: 数千万のデータ分レベルの操作
元の意味を変更しないようにするには、内容を中国語に書き直す必要があります。元の文を表示する必要はありません- bootstrap /順列およびその他のデータ 解を表示せずに分散推定の問題を解決するシミュレーション フレームワーク
オープンソースの発表 | Tencent 分散データ サイエンス コンポーネント
以上がTencent、分散型ベクトル化統計分析と因果推論をサポートするオープンソース データ コンポーネント Fast-Causal-Inference をリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
テキスト注釈は、テキスト内の特定のコンテンツにラベルまたはタグを対応させる作業です。その主な目的は、特に人工知能の分野で、より深い分析と処理のためにテキストに追加情報を提供することです。テキスト注釈は、人工知能アプリケーションの教師あり機械学習タスクにとって非常に重要です。これは、自然言語テキスト情報をより正確に理解し、テキスト分類、感情分析、言語翻訳などのタスクのパフォーマンスを向上させるために AI モデルをトレーニングするために使用されます。テキスト アノテーションを通じて、AI モデルにテキスト内のエンティティを認識し、コンテキストを理解し、新しい同様のデータが出現したときに正確な予測を行うように教えることができます。この記事では主に、より優れたオープンソースのテキスト注釈ツールをいくつか推奨します。 1.LabelStudiohttps://github.com/Hu
 オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
画像の注釈は、ラベルまたは説明情報を画像に関連付けて、画像の内容に深い意味と説明を与えるプロセスです。このプロセスは機械学習にとって重要であり、画像内の個々の要素をより正確に識別するために視覚モデルをトレーニングするのに役立ちます。画像に注釈を追加することで、コンピュータは画像の背後にあるセマンティクスとコンテキストを理解できるため、画像の内容を理解して分析する能力が向上します。画像アノテーションは、コンピュータ ビジョン、自然言語処理、グラフ ビジョン モデルなどの多くの分野をカバーする幅広い用途があり、車両が道路上の障害物を識別するのを支援したり、障害物の検出を支援したりするなど、幅広い用途があります。医用画像認識による病気の診断。この記事では主に、より優れたオープンソースおよび無料の画像注釈ツールをいくつか推奨します。 1.マケセンス
 ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
5月30日、TencentはHunyuanモデルの包括的なアップグレードを発表し、Hunyuanモデルに基づくアプリ「Tencent Yuanbao」が正式にリリースされ、AppleおよびAndroidアプリストアからダウンロードできるようになりました。前のテスト段階のフンユアン アプレット バージョンと比較して、Tencent Yuanbao は、日常生活シナリオ向けの AI 検索、AI サマリー、AI ライティングなどのコア機能を提供し、Yuanbao のゲームプレイもより豊富で、複数の機能を提供します。 、パーソナルエージェントの作成などの新しいゲームプレイ方法が追加されます。 Tencent Cloud 副社長で Tencent Hunyuan 大型モデルの責任者である Liu Yuhong 氏は、「テンセントは、最初に大型モデルを開発しようとはしません。」と述べました。 Tencent Hunyuan の大型モデルは、ビジネス シナリオにおける豊富で大規模なポーランド テクノロジーを活用しながら、ユーザーの真のニーズを洞察します。
 推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
顔の検出および認識テクノロジーは、すでに比較的成熟しており、広く使用されているテクノロジーです。現在、最も広く使用されているインターネット アプリケーション言語は JS ですが、Web フロントエンドでの顔検出と認識の実装には、バックエンドの顔認識と比較して利点と欠点があります。利点としては、ネットワーク インタラクションの削減とリアルタイム認識により、ユーザーの待ち時間が大幅に短縮され、ユーザー エクスペリエンスが向上することが挙げられます。欠点としては、モデル サイズによって制限されるため、精度も制限されることが挙げられます。 js を使用して Web 上に顔検出を実装するにはどうすればよいですか? Web 上で顔認識を実装するには、JavaScript、HTML、CSS、WebRTC など、関連するプログラミング言語とテクノロジに精通している必要があります。同時に、関連するコンピューター ビジョンと人工知能テクノロジーを習得する必要もあります。 Web 側の設計により、次の点に注意してください。
 Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
マルチモーダル文書理解機能のための新しい SOTA!アリババの mPLUG チームは、最新のオープンソース作品 mPLUG-DocOwl1.5 をリリースしました。これは、高解像度の画像テキスト認識、一般的な文書構造の理解、指示の遵守、外部知識の導入という 4 つの主要な課題に対処するための一連のソリューションを提案しています。さっそく、その効果を見てみましょう。複雑な構造のグラフをワンクリックで認識しMarkdown形式に変換:さまざまなスタイルのグラフが利用可能:より詳細な文字認識や位置決めも簡単に対応:文書理解の詳しい説明も可能:ご存知「文書理解」 「」は現在、大規模な言語モデルの実装にとって重要なシナリオです。市場には文書の読み取りを支援する多くの製品が存在します。その中には、主にテキスト認識に OCR システムを使用し、テキスト処理に LLM と連携する製品もあります。
 リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
リリースされたばかりの!ワンクリックでアニメ風の画像を生成するオープンソース モデル
Apr 08, 2024 pm 06:01 PM
最新の AIGC オープンソース プロジェクト、AnimagineXL3.1 をご紹介します。このプロジェクトは、アニメをテーマにしたテキストから画像へのモデルの最新版であり、より最適化された強力なアニメ画像生成エクスペリエンスをユーザーに提供することを目的としています。 AnimagineXL3.1 では、開発チームは、モデルのパフォーマンスと機能が新たな高みに達することを保証するために、いくつかの重要な側面の最適化に重点を置きました。まず、トレーニング データを拡張して、以前のバージョンのゲーム キャラクター データだけでなく、他の多くの有名なアニメ シリーズのデータもトレーニング セットに含めました。この動きによりモデルの知識ベースが充実し、さまざまなアニメのスタイルやキャラクターをより完全に理解できるようになります。 AnimagineXL3.1 では、特別なタグと美学の新しいセットが導入されています
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
 Tencent QQ NTアーキテクチャバージョンのメモリ最適化の進捗が発表、チャットシーンは300M以内に制御される
Mar 05, 2024 pm 03:52 PM
Tencent QQ NTアーキテクチャバージョンのメモリ最適化の進捗が発表、チャットシーンは300M以内に制御される
Mar 05, 2024 pm 03:52 PM
Tencent QQデスクトップクライアントは一連の抜本的な改革を経たと理解されています。高いメモリ使用量、大きすぎるインストール パッケージ、遅い起動などのユーザーの問題に対応して、QQ 技術チームはメモリに関する特別な最適化を行い、段階的に進歩してきました。最近、QQ 技術チームは InfoQ プラットフォームに関する紹介記事を公開し、メモリの特別な最適化における段階的な進歩を共有しました。レポートによると、QQ の新バージョンのメモリの課題は主に次の 4 つの側面に反映されています。 製品形式: 複雑な大型パネル (さまざまな複雑さの 100 以上のモジュール) と一連の独立した機能ウィンドウで構成されます。ウィンドウとレンダリングプロセスは 1 対 1 に対応しており、ウィンドウプロセスの数は Electron のメモリ使用量に大きく影響します。その複雑な大型パネルの場合、
