

大規模なモデルをトレーニングするための高品質のデータが不足していますか?新しい解決策を見つけました

機械学習モデルのパフォーマンスを決定する 3 つの主要要素の 1 つであるデータが、大規模なモデルの開発を制限するボトルネックになりつつあります。 「ガベージイン、ガベージアウト」[1] ということわざがあるように、アルゴリズムがどれほど優れていても、コンピューティング リソースがどれほど強力であっても、モデルの品質はモデルのトレーニングに使用するデータに直接依存します。
さまざまなオープンソースの大規模モデルの出現により、データ、特に高品質の業界データの重要性がさらに強調されています。ブルームバーグは、オープンソースの GPT-3 フレームワークに基づいて大規模な財務モデル BloombergGPT を構築しています。これは、オープンソースの大規模モデル フレームワークに基づいて垂直産業向けの大規模モデルを開発する実現可能性を証明しています。実際、垂直産業向けのクローズドソースの軽量大型モデルの構築またはカスタマイズは、中国の大規模モデルのスタートアップのほとんどが選択する道です。
このトラックでは、高品質の垂直業界データ、専門知識に基づく微調整および調整機能が重要です。BloombergGPT は、Bloomberg が蓄積した財務文書に基づいて構築およびトレーニングされています。 40 年以上 コーパスには 7,000 億以上のトークンがあります [2]。
しかし、高品質のデータを取得するのは簡単ではありません。一部の研究では、大規模モデルがデータを食い尽くす現在の速度では、書籍、ニュースレポート、科学論文、Wikipedia などの高品質なパブリックドメイン言語データが 2026 年頃に枯渇すると指摘しています [3]。
一般に公開されている高品質な中国のデータ リソースは比較的少なく、国内の専門的なデータ サービスはまだ初期段階にあり、データの収集、クリーニング、注釈付け、検証には多大な投資が必要です。人的資源と物的資源。国内大学の大規模モデルチーム向けに3TBの高品質の中国データを収集してクリーニングするコストには、ダウンロードデータ帯域幅、データストレージリソース(クリーニングされていない元のデータは約100TB)、クリーニングに必要なCPUリソースコストが含まれると報告されています。データの合計は約数十万元です。
大規模モデルの開発がさらに深くなるにつれて、業界のニーズを満たし、非常に高い精度を持つ垂直型インダストリー モデルをトレーニングするには、より多くの業界の専門知識や商業機密情報さえも必要になります。 。しかし、プライバシー保護の要件や、権利の確認や利益の分配が難しいため、企業はデータを共有したくない、共有できない、または共有することを恐れていることがよくあります。
データのオープン性と共有のメリットを享受できるだけでなく、データのセキュリティとプライバシーも保護できるソリューションはありますか?
プライバシー コンピューティングはジレンマを打破できるでしょうか?
プライバシー保護計算は、データ提供者が元のデータを開示しないことを保証することなく、データを分析、加工、利用することができ、データ要素の流通とトランザクションを促進するとみなされます。 4] したがって、大規模モデルのデータ セキュリティを保護するためにプライバシー コンピューティングを使用するのは自然な選択であると思われます。
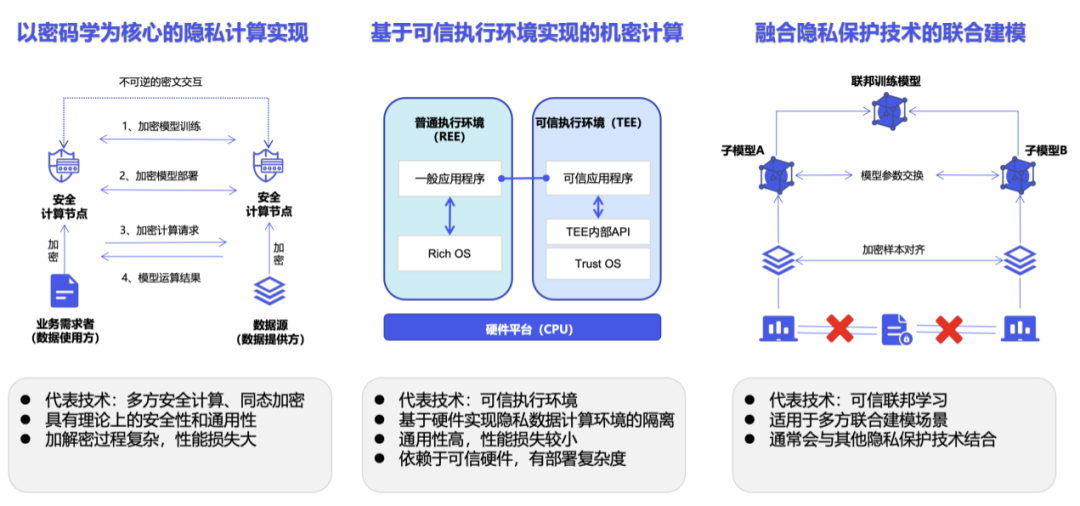
#プライバシー コンピューティングはテクノロジーではなく、技術システムです。具体的な実装によれば、プライバシー コンピューティングは主に、マルチパーティ セキュア コンピューティングに代表される暗号化パス、信頼できる実行環境に代表される機密コンピューティング パス、フェデレーテッド ラーニングに代表される人工知能パスに分類されます [5]。
ただし、実際のアプリケーションでは、プライバシー コンピューティングにはいくつかの制限があります。たとえば、プライバシー コンピューティング SDK の導入は、通常、元のビジネス システムに対するコード レベルの変更につながります [6]。暗号化に基づいて実装すると、暗号化と復号化の演算量が指数関数的に増加し、暗号文の計算にはより多くのコンピューティング リソースとストレージ リソース、および通信負荷が必要になります [7]。
さらに、既存のプライバシー コンピューティング ソリューションは、非常に大量のデータを含む大規模なモデルのトレーニング シナリオにおいて、いくつかの新たな問題に直面することになります。
フェデレーション ラーニング ベースのソリューション
まず、フェデレーテッド ラーニングの難しさを見てみましょう。 。フェデレーテッド ラーニングの核となるアイデアは、「データは移動しないが、モデルは移動する」です。この分散型アプローチにより、機密データはローカルに残り、公開または送信する必要がなくなります。各デバイスまたはサーバーは、モデルの更新を中央サーバーに送信することでトレーニング プロセスに参加し、中央サーバーはこれらの更新を集約して融合してグローバル モデルを改善します [8]。
ただし、大規模なモデルの集中トレーニングはすでに非常に困難であり、分散トレーニング方法ではシステムの複雑さが大幅に増加します。また、モデルがさまざまなデバイスでトレーニングされるときのデータの不均一性と、すべてのデバイスにわたって学習の重みを安全に集約する方法を考慮する必要もあります。大規模なモデルのトレーニングでは、モデルの重み自体が重要な資産です。さらに、攻撃者が単一のモデル更新からプライベート データを推測することを防ぐ必要があり、対応する防御によりトレーニングのオーバーヘッドがさらに増加します。
暗号ベースのスキーム
準同型暗号化は、暗号化されたデータを直接計算し、データを「利用可能かつ不可視」にすることができます [9]。準同型暗号化は、機密データが処理または分析され、その機密性が保証されるシナリオでプライバシーを保護するための強力なツールです。この手法は、大規模モデルのトレーニングだけでなく、ユーザー入力 (プロンプト) の機密性を保護しながらの推論にも適用できます。
ただし、大規模モデルのトレーニングや推論に暗号化されたデータを使用することは、暗号化されていないデータを使用するよりもはるかに困難です。同時に、暗号化されたデータの処理にはより多くの計算が必要となり、処理時間が指数関数的に増加し、大規模モデルのトレーニングに必要なすでに非常に高い計算能力がさらに増加します。
#信頼できる実行環境に基づくソリューション
信頼できる実行環境に基づくソリューションについて話しましょう実行環境 (TEE) ソリューション。ほとんどの TEE ソリューションまたは製品では、マルチパーティ セキュア コンピューティング ノード、信頼できる実行環境機器、暗号化アクセラレータ カードなどの追加の特殊機器を購入する必要があり、既存のコンピューティング リソースやストレージ リソースに適応できないため、このソリューションは多くの人には適していません。中小企業、企業にとっては現実的ではありません。さらに、現在の TEE ソリューションは主に CPU に基づいていますが、大規模なモデルのトレーニングは GPU に大きく依存しています。現段階では、プライバシー コンピューティングをサポートする GPU ソリューションはまだ成熟していませんが、代わりに追加のリスクが生じます [10]。
一般的に、マルチパーティの協調コンピューティングのシナリオでは、元のデータが物理的な意味で「不可視」であることを要求するのは不合理な場合が多いです。さらに、暗号化プロセスによってデータにノイズが追加されるため、暗号化されたデータに対するトレーニングや推論もモデルのパフォーマンスの低下を引き起こし、モデルの精度を低下させます。既存のプライバシー コンピューティング ソリューションは、パフォーマンスと GPU サポートの点で大規模モデルのトレーニング シナリオにあまり適していないだけでなく、高品質のデータ リソースを持つ企業や機関が情報を公開して共有し、大規模モデル業界に参加することを妨げています。
制御可能なコンピューティング、プライバシー コンピューティングの新しいパラダイム
「大規模モデル業界をデータからアプリケーション チェーンまでのプロセスとして見ると、この連鎖は、実際にはさまざまなエンティティ間でのさまざまなデータ(元のデータ、モデル内のパラメータの形で存在するデータも含む)の循環チェーンであり、この業界のビジネスモデルはこれらの循環の上に構築される必要があることがわかります。データ (またはモデル) は取引できる資産に基づいています」と YiZhi Technology の CEO である Tang Zaiyang 博士は述べています。
「データ要素の流通には複数のエンティティが関与しており、業界チェーンのソースはデータプロバイダーでなければなりません。言い換えれば、すべてのビジネスは実際にはデータプロバイダーによって開始されます。データプロバイダーの許可があれば取引を続行できるため、データプロバイダーの権利と利益を確保することを優先する必要があります。」
現在市場に出ている主流のプライバシー保護ソリューション、マルチパーティ セキュア コンピューティング、情報実行環境、フェデレーション ラーニングなどは、どちらもデータ ユーザーがデータを処理する方法に焦点を当てていますが、Tang Zaiyang 氏は、この問題をデータ プロバイダーの観点から見る必要があると考えています。
Yizhi Technology は 2019 年に設立され、データ連携のためのプライバシー保護ソリューション プロバイダーとして位置付けられています。 2021年、同社は中国情報通信技術院が開始した「データセキュリティイニシアチブ(DSI)」の第1期参加部門の1つに選ばれ、DSIから代表的なプライバシーコンピューティング9社の1つとして認定された。エンタープライズベンダー。 2022 年、YiZhi Technology は、中国初の国際的な独立した制御可能なプライバシー コンピューティング オープンソース コミュニティである Open Islands オープンソース コミュニティのメンバーとなり、データ要素の流通のための主要なインフラストラクチャの構築を共同で推進します。
大規模なモデルのトレーニングとデータ要素の広範な流通による現在のデータのジレンマに対応して、YiZhi Technology は、制御計算の実践に基づいた新しいプライバシー コンピューティング ソリューションを提案しました。
「制御可能なコンピューティングの中心的な焦点は、プライバシーを保護しながら情報を発見し、共有することです。私たちが解決する問題は、データのセキュリティを確保することです。トレーニング プロセスを強化し、トレーニング済みモデルが悪意を持って盗まれることはありません。」と Tang Zaiyang 氏は言いました。
具体的には、制御可能なコンピューティングでは、データ ユーザーがデータ プロバイダーによって定義されたセキュリティ ドメイン内でデータを処理および処理する必要があります。
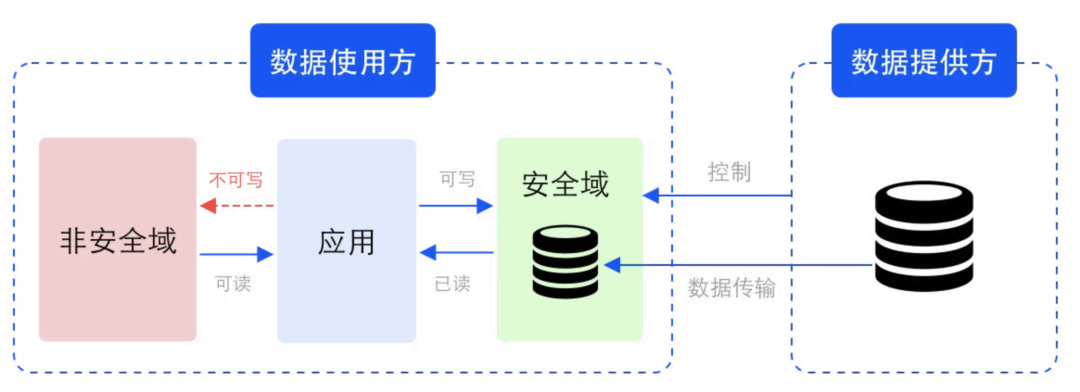
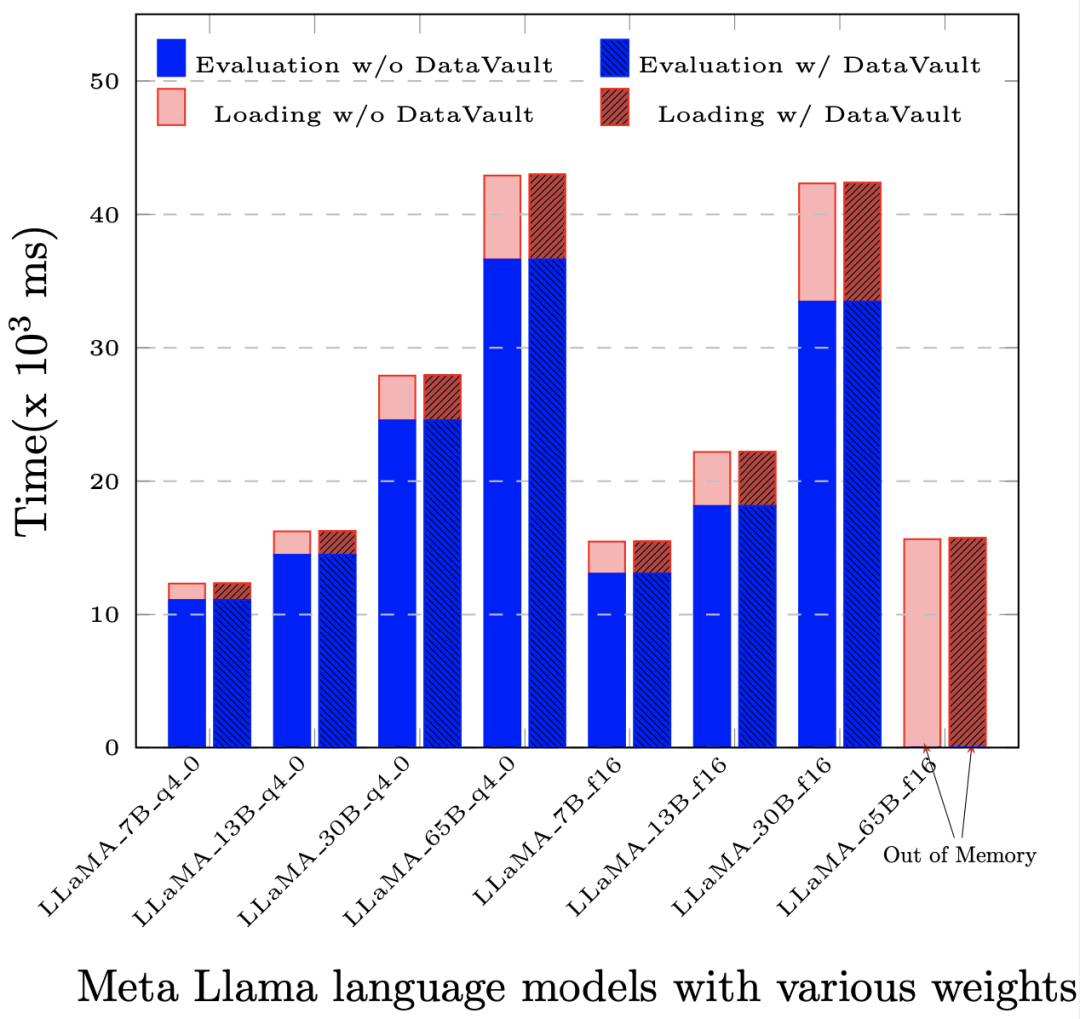
セキュリティ ドメインは、対応するキーと暗号化アルゴリズムによって保護されるストレージとコンピューティング ユニットを指す論理概念です。セキュリティ ドメインはデータ プロバイダーによって定義および制約されますが、対応するストレージおよびコンピューティング リソースはデータ プロバイダーによって提供されません。物理的には、セキュリティ ドメインはデータ ユーザー側にありますが、データ プロバイダーによって制御されます。生データに加えて、処理および処理された中間データと結果データも同じセキュリティ ドメインに含まれます。 セキュリティ ドメインでは、データは暗号文 (不可視) または平文 (可視) のいずれかになります。平文の場合、データの可視範囲が制御されるため、データが保証されます。使用中のセキュリティ。 複雑な暗号文の計算によって引き起こされるパフォーマンスの低下は、プライバシー コンピューティング アプリケーションの範囲を制限する重要な要因です。やみくもに不可視性を追求するのではなく、データの制御可能性を重視することで、データを制御できます。コンピューティングは、元のビジネスに対する従来のプライバシー コンピューティング ソリューションの侵入性を解決するため、超大規模データを処理する必要がある大規模モデルのトレーニング シナリオに非常に適しています。 企業は、複数の異なるセキュリティ ドメインにデータを保存し、これらのセキュリティ ドメインに対して異なるセキュリティ レベル、使用許可、またはホワイトリストを設定することを選択できます。分散アプリケーションの場合、セキュリティ ドメインを複数のコンピュータ ノードまたはチップ上に設定することもできます。 「セキュリティ ドメインは連結することができます。データ流通の各リンクで、データ プロバイダーは複数の異なるセキュリティ ドメインを定義して、データがこれらのセキュリティ ドメインにのみ保存されるようにすることができます。最終的には、これら直列に接続されたセキュリティドメインがデータネットワークを構築し、このネットワーク上でデータを制御したり、データの流れ、分析、処理を計測・監視したり、データの流通を計測・監視したりすることができます。対応する認識です」とTang Zaiyang氏は説明した。 制御可能なコンピューティングのアイデアに基づいて、YiZhi Technology は「DataVault」を立ち上げました。 DataVault の原則: Linux メトリック スタートアップと Linux フルディスク暗号化テクノロジを組み合わせて、セキュリティ ドメイン内でデータの制御と保護を実現します。 DataVault は、システムの整合性を保護するための信頼のルートとして Trusted Platform Module TPM (Trusted Platform Module、そのコアはハードウェア ベースのセキュリティ関連機能を提供することです) を使用します。 Linux セキュリティ モジュール LSM (Linux セキュリティ モジュール、さまざまなコンピュータ セキュリティ モデルをサポートするために使用される Linux カーネル内のフレームワーク。個々のセキュリティ実装とは何の関係もありません) テクノロジを使用すると、セキュリティ ドメイン内のデータを制御可能な制限内でのみ使用できるようになります。 これに基づいて、DataVault は、Linux が提供するフルディスク暗号化テクノロジを使用して、データを安全なドメインに配置します。YiZhi Technology は、キーの配布や署名などの完全な暗号化プロトコルを独自に開発しました。データの制御性をさらに確保するために、多数のエンジニアリングの最適化が行われています。 DataVault は、さまざまな CPU、GPU、FPGA、その他のハードウェアを含むさまざまな専用アクセラレータ カードをサポートし、複数のデータ処理フレームワークとモデル トレーニング フレームワークもサポートし、バイナリ互換性があります。 さらに重要なのは、他のプライバシー コンピューティング ソリューションよりもパフォーマンスの損失がはるかに少ないことです。ほとんどのアプリケーションでは、ネイティブ システム (つまり、プライバシー コンピューティング テクノロジを使用しないシステム) と比較して、 、全体的なパフォーマンスの損失は 5% を超えません。 DataVault 導入後のパフォーマンス損失は、LLaMA に基づく評価 (Evaluation) および即時評価 (Prompt Evaluation) で 1 パーセント未満です。 65B。 現在、YiZhi Technology は、スーパーコンピューティング センターを構築するために国家スーパーコンピューティング センターと協力関係に達しました。プラットフォーム AI アプリケーション向けに、プライバシーを保護する高性能コンピューティング プラットフォームを展開します。 DataVault に基づいて、コンピューティングのパワー ユーザーは、コンピューティング プラットフォーム上にセキュリティ ドメインを設定して、ストレージ ノードからコンピューティング ノードへのデータ転送プロセス全体がセキュリティ ドメイン間でのみ移動でき、設定範囲から外れないようにすることができます。 DataVault ソリューションに基づいて、モデルのトレーニング中にデータを確実に制御できることに加えて、トレーニングされた大規模モデル自体もデータ資産として保護し、安全に取引することもできます。 現在、金融、医療、その他の機密性の高いデータ機関など、大規模なモデルをローカルに展開したい企業は、大規模なモデルをローカルで実行するためのインフラストラクチャの不足に悩まされています。 - 大規模なモデルをトレーニングするためのパフォーマンス ハードウェア、および大規模なモデルの展開に伴うその後の運用とメンテナンスの経験。大規模なインダストリ モデルを構築する企業は、モデルが顧客に直接提供された場合、モデル自体やモデル パラメータの背後に蓄積された業界データや専門知識が再販売される可能性があることを懸念しています。 垂直産業における大規模モデルの実装の検討として、YiZhi Technology は広東・香港・マカオ大湾区デジタル経済研究所 (IDEA Research) とも協力しています。両者は共同で、モデル安全保護機能を備えた大型モデル一体型マシンを開発しました。このオールインワン マシンには、垂直産業向けの大規模モデルがいくつか組み込まれており、大規模モデルのトレーニングとプロモーションに必要な基本的なコンピューティング リソースが装備されており、すぐに顧客のニーズを満たすことができます。 Yizhi の制御可能なコンピューティング コンポーネントは、これらの組み込みモデルを認証付きで使用した場合にのみ、モデルとすべての中間データが外部環境によって盗まれないようにすることができます。 YiZhi Technology は、新しいプライバシー コンピューティング パラダイムとして、制御可能なコンピューティングが大規模モデル業界とデータ要素の流通に変化をもたらすことを期待しています。 「DataVault は単なる軽量の実装ソリューションです。テクノロジーとニーズが変化するにつれて、私たちは更新を続け、データ要素の流通市場でのさらなる試みと貢献を続けていきます。また、より多くのユーザーを歓迎します」業界パートナーが私たちに参加し、制御可能なコンピューティング コミュニティを構築してくれることを願っています」と Tang Zaiyang 氏は述べています。 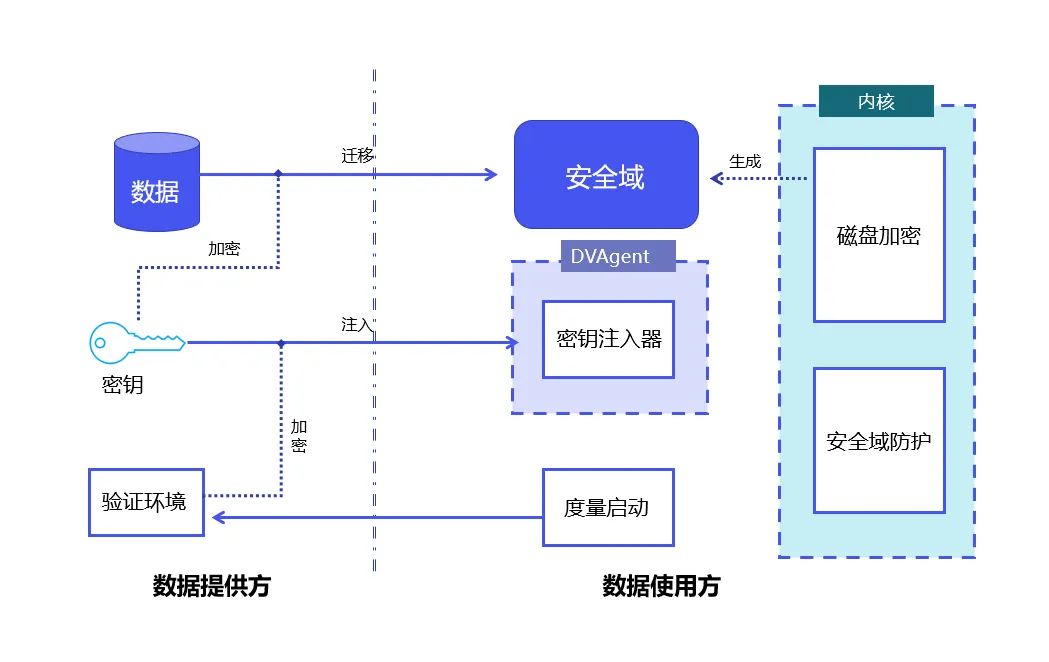
データ流通とモデル資産を保護する DataVault の事例
以上が大規模なモデルをトレーニングするための高品質のデータが不足していますか?新しい解決策を見つけましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7521
7521
 15
1378
52
81
11
21
70
15
1378
52
81
11
21
70

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
Llama 70B を実行するシングル カードはデュアル カードより高速、Microsoft は FP6 を A100 オープンソースに強制導入
Apr 29, 2024 pm 04:55 PM
FP8 以下の浮動小数点数値化精度は、もはや H100 の「特許」ではありません。 Lao Huang は誰もが INT8/INT4 を使用できるようにしたいと考え、Microsoft DeepSpeed チームは NVIDIA からの公式サポートなしで A100 上で FP6 の実行を開始しました。テスト結果は、A100 での新しい方式 TC-FPx の FP6 量子化が INT4 に近いか、場合によってはそれよりも高速であり、後者よりも精度が高いことを示しています。これに加えて、エンドツーエンドの大規模モデルのサポートもあり、オープンソース化され、DeepSpeed などの深層学習推論フレームワークに統合されています。この結果は、大規模モデルの高速化にも即座に影響します。このフレームワークでは、シングル カードを使用して Llama を実行すると、スループットはデュアル カードのスループットの 2.65 倍になります。 1つ
