

オープンソース コミュニティの開発者である Georgi Gerganov は、M2 Ultra 上で 34B コード Llama モデルを完全な F16 精度で実行でき、推論速度が 20 トークン/秒を超えたことを発見しました。
M2 Ultra の帯域幅は 800 GB/秒ですが、他の製品ではこれを達成するには通常 4 つのハイエンド GPU を使用する必要があります。
#この背後にある本当の答えは、「投機的サンプリング」です。ジョージの発見はすぐに人工知能業界の大物の間で議論を引き起こしました
カルパシーは「LLM の投機的実行」というコメントを転送しました。優れた推論時間の最適化です。」

簡単に言うと、「小さなモデル」で下書きを作成し、「大きなモデル」で確認・修正を行うことで全体のプロセスを高速化します。

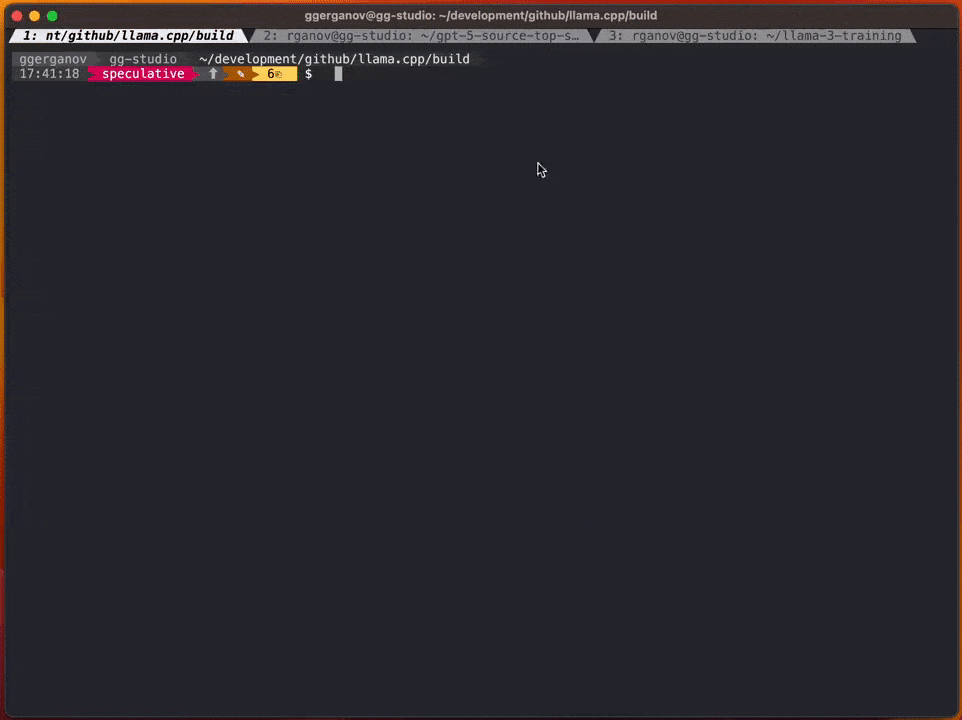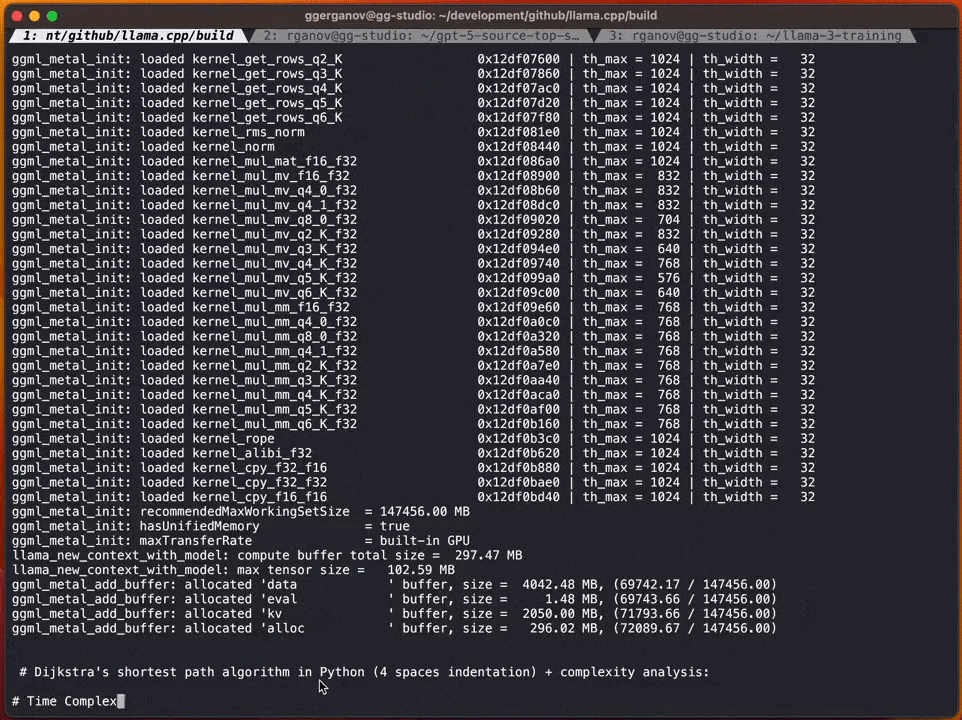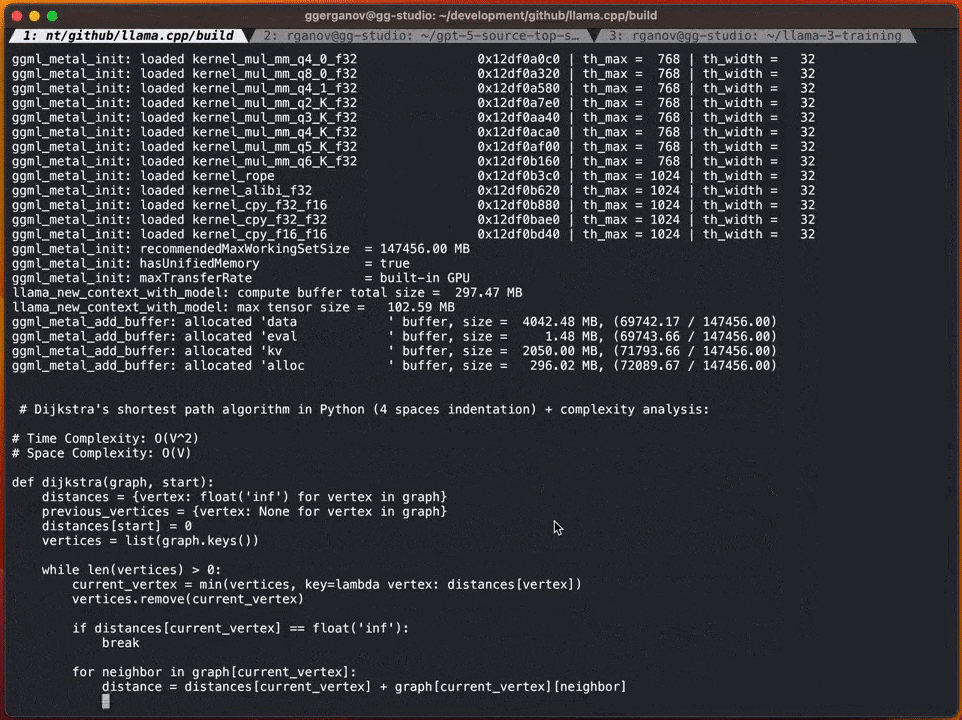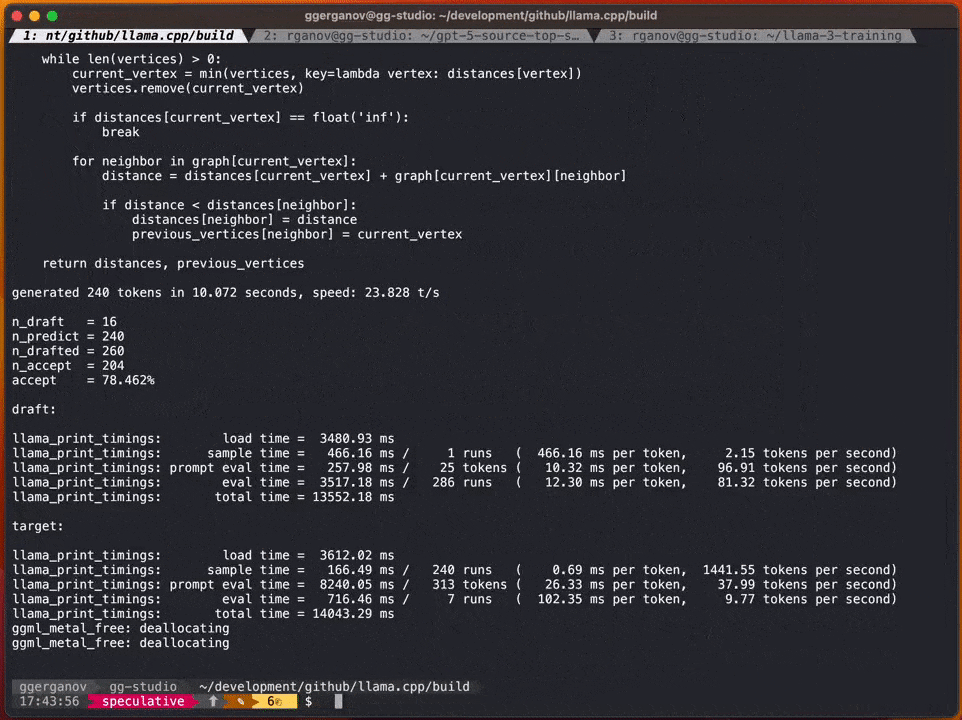
によるとGeorgi 氏によると、これらのモデルの速度は次のとおりです:
F16 34B: 1 秒あたり約 10 トークン
書き直す必要があるのは次のとおりです: Q4 7B: 1 秒あたり約 80 トークン
次は投機的サンプリングを使用しない標準的な F16 サンプリングの例:投機的サンプリング戦略を追加すると、速度は 1 秒あたり約 20 マークに達する可能性があります
# Georgi 氏によると、コンテンツが生成される速度は異なる場合があります。ただし、ほとんどの語彙はドラフト モデルで正しく推測できるため、このアプローチはコード生成には非常に効果的であると思われます。
#投機的サンプリングはどのようにして高速推論を実現するのでしょうか?
 Karpathy 氏は、Google Brain、UC Berkeley、DeepMind によるこれまでの 3 つの研究に基づいて説明を行いました。
Karpathy 氏は、Google Brain、UC Berkeley、DeepMind によるこれまでの 3 つの研究に基づいて説明を行いました。
論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/pdf/2211.17192.pdf

論文アドレス: https://arxiv.org/pdf/1811.03115.pdf

##論文アドレス: https://arxiv.org/pdf/2302.01318.pdf
これは、次の直感的ではない観察に依存します: 
単一の入力トークンで LLM を転送するのに必要な時間は、K 個の入力トークンで LLM をバッチで転送するのに必要な時間と同じです (K は思っているよりも大きいです)。
この直感的ではない事実は、サンプリングがメモリによって大幅に制限されているためです。ほとんどの「作業」は計算されませんが、トランスフォーマーの重みは VRAM からオンチップ キャッシュに読み取られます。 。 対処する。
すべての重みを読み取るタスクを達成するには、それらを入力ベクトルのバッチ全体に適用する方が良いです。 この事実を単純に利用できない理由一度に K 個のトークンをサンプリングするのは、各 N 個のトークンがステップ N-1 でサンプリングしたトークンに依存するためです。これはシリアル依存関係であるため、ベースラインの実装は左から右に 1 つずつ実行されます。 さて、賢いアイデアは、小さくて安価なドラフト モデルを使用して、最初に K 個のマーカーで構成される候補シーケンス、つまり「ドラフト」を生成することです。次に、このすべての情報を大きなモデルにバッチ フィードします。 上記の方法によると、これはトークンを 1 つ入力するのとほぼ同じくらい高速です。 次に、モデルを左から右に調べ、サンプル トークンによって予測されたロジットを調べます。ドラフトに一致するサンプルがあると、すぐに次のトークンにジャンプできます。 意見の相違がある場合は、ドラフト モデルを放棄し、一度限りの作業 (ドラフト モデルのサンプリングと後続のトークンのフォワード パスの実行) のコストを負担します これが実際に機能する理由は、ほとんどの場合、ドラフト トークンが受け入れられること、また、ドラフト トークンは単純なトークンであるため、小規模なドラフト モデルでも受け入れることができるためです。 これらの単純なトークンが受け入れられる場合、これらの部分はスキップします。大きなモデルが同意しない難易度トークンは、元の速度に「フォールバック」しますが、余分な作業が発生するため、実際には遅くなります。 つまり、要約すると、LLM は推論中にメモリに制約があるため、この奇妙なトリックが機能します。 「バッチ サイズ 1」の場合、対象となる単一のシーケンスがサンプリングされます。これは、ほとんどの「ローカル LLM」の使用例に当てはまります。さらに、ほとんどのトークンは「単純」です。 HuggingFace の共同創設者は、1 年半前、340 億のパラメータ モデルはデータセンターの外では非常に大規模で困難に見えたと述べました。管理。ラップトップだけで簡単に扱えるようになりました #今日の LLM は単一の画期的な進歩ではなく、複数の重要なコンポーネントの効果的な調整が必要です。 。投機的デコーディングは、システムの観点から考えるのに役立つ優れた例です。 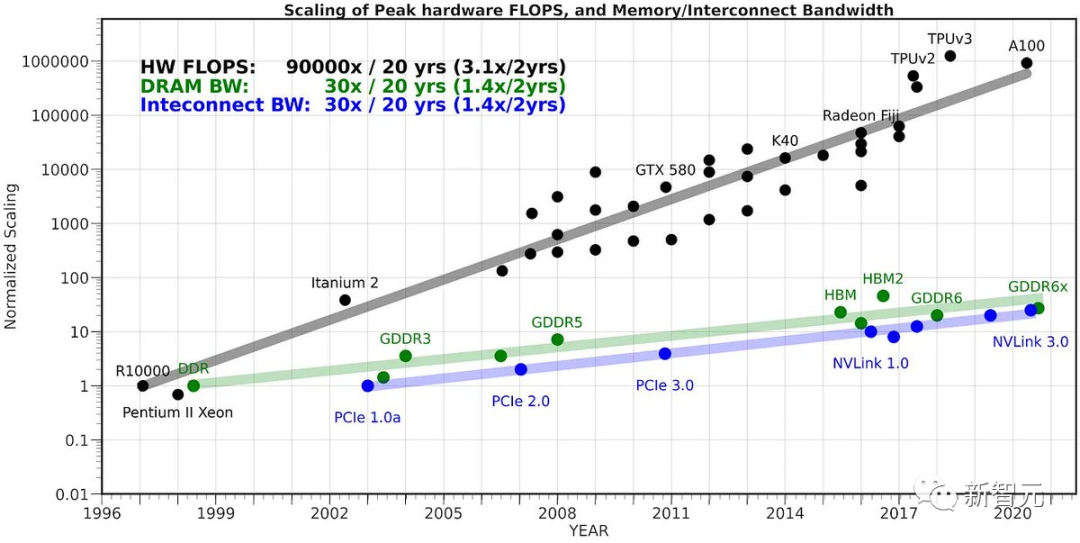

以上が4 H100 は必要ありません! 340 億パラメータのコード Llama を Mac 上で実行でき、毎秒 20 トークン、最高のコード生成を実現します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



