

100,000 米ドル + 26 日で、1,000 億パラメータの低コスト LLM が誕生


- 論文: https://arxiv.org/pdf/2309.03852.pdf
- 必要書かれた内容は次のとおりです。 モデルリンク: https://huggingface.co/CofeAI/FLM-101B
言語は本質的に象徴的なものです。 LLM の知能レベルを評価するために、カテゴリ ラベルではなくシンボルを使用した研究がいくつかあります。同様に、チームはシンボリック マッピング アプローチを使用して、目に見えないコンテキストを一般化する LLM の機能をテストしました。
人間の知性の重要な能力は、与えられたルールを理解し、対応するアクションを実行することです。このテスト方法は、さまざまなレベルのテストで広く使用されています。したがって、ここではルールの理解が第二のテストになります。
書き直された内容: パターン マイニングはインテリジェンスの重要な部分であり、帰納と演繹が含まれます。科学の発展の歴史において、この方法は重要な役割を果たします。さらに、さまざまな競技会のテスト問題では、この解答能力が求められることがよくあります。これらの理由から、3 番目の評価指標としてパターン マイニングを選択しました。
最後の非常に重要な指標は、インテリジェンスの中核機能の 1 つでもある耐干渉能力です。研究では、言語と画像の両方がノイズによって容易に妨害されることが指摘されています。これを念頭に置いて、チームは干渉耐性を最終評価基準として使用しました。
研究者らは、これは成長戦略を使用して、より多くのトレーニングを行う研究であると述べています。 1,000 人をゼロから、10 億のパラメータに対する LLM 研究の試み。同時に、これは現在最も低コストの 1,000 億パラメータ モデルでもあり、コストはわずか 10 万米ドルです。
FreeLM トレーニング目標、潜在的なハイパーパラメータ検索方法、および機能を維持した成長を改善することにより、この研究は不安定性の問題に取り組んでいます。研究者らは、この方法がより広範な科学研究コミュニティにも役立つと信じています。
研究者らはまた、知識指向ベンチマークや新しく提案された系統的 IQ 評価ベンチマークの使用など、新しいモデルと以前の強力なモデルとの実験的な比較も実施しました。実験結果は、FLM-101B モデルが競争力があり堅牢であることを示しています
チームは、1,000億パラメータ規模の中国語と英語のバイリンガルLLMの研究開発を促進するため、モデルチェックポイント、コード、関連ツールなどをリリースします。
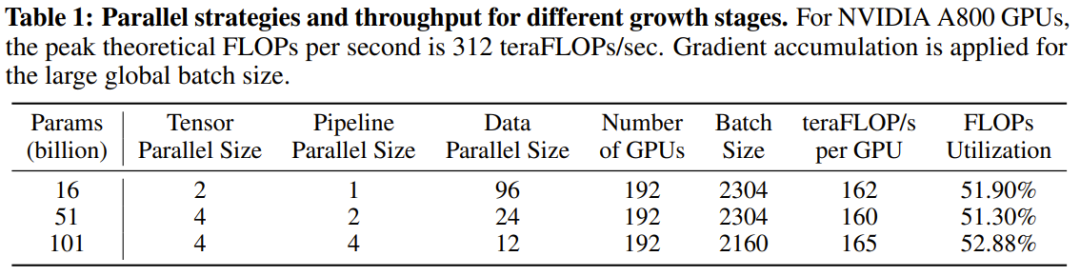
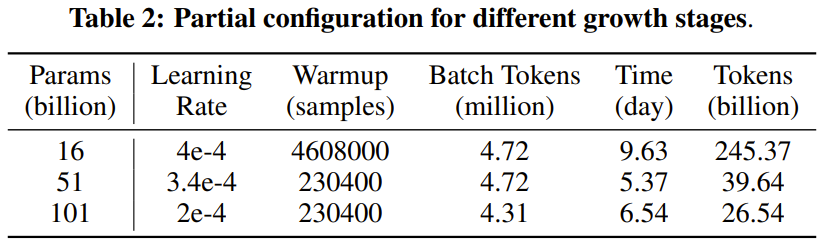
損失発散や勾配爆発などの不安定な問題を解決するために、研究者らは有望な解決策を提案しました。これについては次のように簡単に説明します。
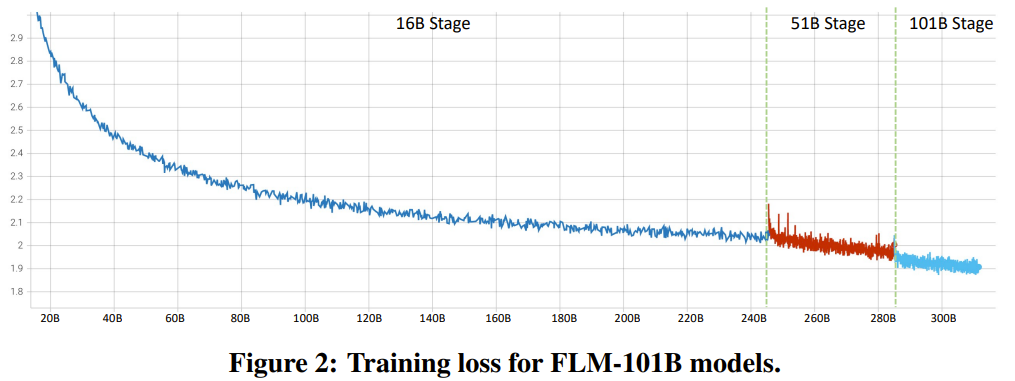
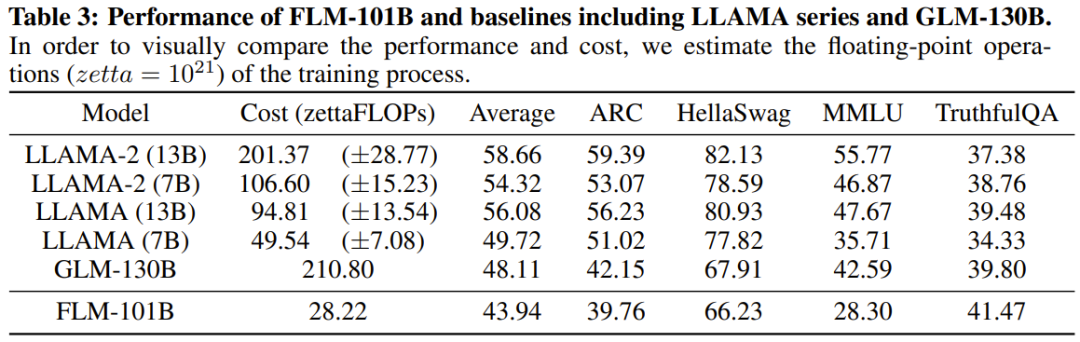
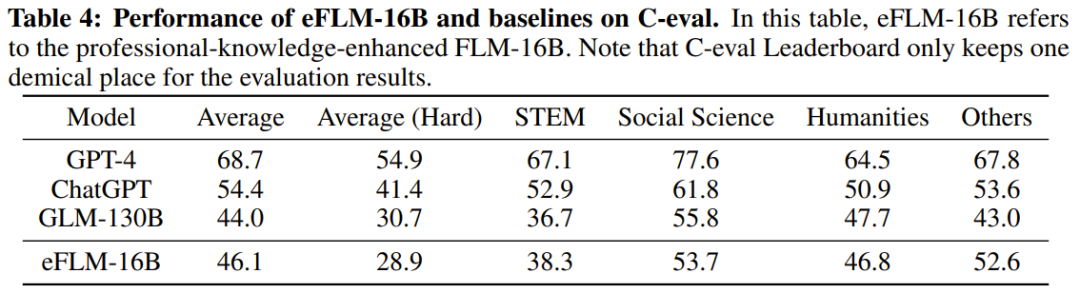
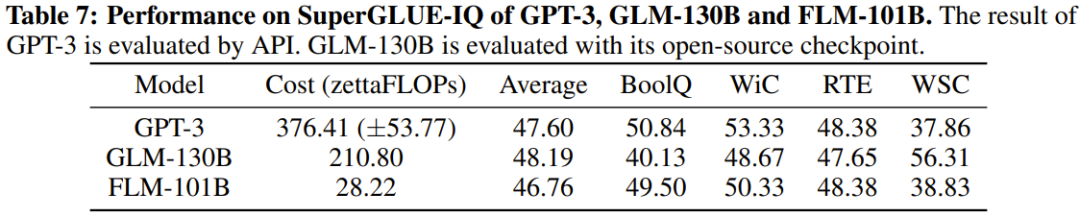

 ##これらの表から、4 つの IQ 評価ベンチマークにおいて、FLM-101B は GPT-3 に匹敵し、はるかに低い計算コストで GLM-130B よりも優れた結果を達成しています。
##これらの表から、4 つの IQ 評価ベンチマークにおいて、FLM-101B は GPT-3 に匹敵し、はるかに低い計算コストで GLM-130B よりも優れた結果を達成しています。
研究者らは、トレーニング データの影響に加えて、この利点は、初期段階の小さなモデルがより小さな探索空間を洗練するためである可能性があると推測しています。モデルがさらに大きくなり、より広くなり、汎化機能が強化されても、この利点は引き続き発揮されます。
以上が100,000 米ドル + 26 日で、1,000 億パラメータの低コスト LLM が誕生の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
28
96
15
1382
52
83
11
28
96

 ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
ビッグモデルアプリ Tencent Yuanbao がオンラインになりました! Hunyuan がアップグレードされ、どこにでも持ち運べるオールラウンドな AI アシスタントが作成されました
Jun 09, 2024 pm 10:38 PM
5月30日、TencentはHunyuanモデルの包括的なアップグレードを発表し、Hunyuanモデルに基づくアプリ「Tencent Yuanbao」が正式にリリースされ、AppleおよびAndroidアプリストアからダウンロードできるようになりました。前のテスト段階のフンユアン アプレット バージョンと比較して、Tencent Yuanbao は、日常生活シナリオ向けの AI 検索、AI サマリー、AI ライティングなどのコア機能を提供し、Yuanbao のゲームプレイもより豊富で、複数の機能を提供します。 、パーソナルエージェントの作成などの新しいゲームプレイ方法が追加されます。 Tencent Cloud 副社長で Tencent Hunyuan 大型モデルの責任者である Liu Yuhong 氏は、「テンセントは、最初に大型モデルを開発しようとはしません。」と述べました。 Tencent Hunyuan の大型モデルは、ビジネス シナリオにおける豊富で大規模なポーランド テクノロジーを活用しながら、ユーザーの真のニーズを洞察します。
 Bytedance Beanbao 大型モデルがリリース、Volcano Engine フルスタック AI サービスが企業のインテリジェントな変革を支援
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao 大型モデルがリリース、Volcano Engine フルスタック AI サービスが企業のインテリジェントな変革を支援
Jun 05, 2024 pm 07:59 PM
Volcano Engine の社長である Tan Dai 氏は、大規模モデルを実装したい企業は、モデルの有効性、推論コスト、実装の難易度という 3 つの重要な課題に直面していると述べました。複雑な問題を解決するためのサポートとして、適切な基本的な大規模モデルが必要です。また、サービスは低コストの推論を備えているため、大規模なモデルを広く使用できるようになり、企業がシナリオを実装できるようにするためには、より多くのツール、プラットフォーム、アプリケーションが必要になります。 ——Huoshan Engine 01 社長、Tan Dai 氏。大きなビーンバッグ モデルがデビューし、頻繁に使用されています。モデル効果を磨き上げることは、AI の実装における最も重要な課題です。 Tan Dai 氏は、良いモデルは大量に使用することでのみ磨かれると指摘しました。現在、Doubao モデルは毎日 1,200 億トークンのテキストを処理し、3,000 万枚の画像を生成しています。企業による大規模モデルシナリオの実装を支援するために、バイトダンスが独自に開発した豆包大規模モデルが火山を通じて打ち上げられます。
 「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
現代の製造において、正確な欠陥検出は製品の品質を確保するための鍵であるだけでなく、生産効率を向上させるための核心でもあります。ただし、既存の欠陥検出データセットには、実際のアプリケーションに必要な精度や意味論的な豊富さが欠けていることが多く、その結果、モデルが特定の欠陥カテゴリや位置を識別できなくなります。この問題を解決するために、広州香港科技大学と Simou Technology で構成されるトップの研究チームは、産業欠陥に関する詳細かつ意味的に豊富な大規模なアノテーションを提供する「DefectSpectrum」データセットを革新的に開発しました。表 1 に示すように、他の産業データ セットと比較して、「DefectSpectrum」データ セットは最も多くの欠陥注釈 (5438 個の欠陥サンプル) と最も詳細な欠陥分類 (125 個の欠陥カテゴリ) を提供します。
 NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
オープンな LLM コミュニティは百花繚乱の時代です Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1 などがご覧いただけます。優秀なパフォーマーモデル。しかし、GPT-4-Turboに代表される独自の大型モデルと比較すると、オープンモデルには依然として多くの分野で大きなギャップがあります。一般的なモデルに加えて、プログラミングと数学用の DeepSeek-Coder-V2 や視覚言語タスク用の InternVL など、主要な領域に特化したいくつかのオープン モデルが開発されています。
 結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
編集者 |KX 今日に至るまで、単純な金属から大きな膜タンパク質に至るまで、結晶学によって決定される構造の詳細と精度は、他のどの方法にも匹敵しません。しかし、最大の課題、いわゆる位相問題は、実験的に決定された振幅から位相情報を取得することのままです。デンマークのコペンハーゲン大学の研究者らは、結晶相の問題を解決するための PhAI と呼ばれる深層学習手法を開発しました。数百万の人工結晶構造とそれに対応する合成回折データを使用して訓練された深層学習ニューラル ネットワークは、正確な電子密度マップを生成できます。この研究では、この深層学習ベースの非経験的構造解法は、従来の非経験的計算法とは異なり、わずか 2 オングストロームの解像度で位相問題を解決できることが示されています。これは、原子解像度で利用可能なデータのわずか 10% ~ 20% に相当します。
 Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
AI にとって、数学オリンピックはもはや問題ではありません。木曜日、Google DeepMind の人工知能は、AI を使用して今年の国際数学オリンピック IMO の本当の問題を解決するという偉業を達成し、金メダル獲得まであと一歩のところまで迫りました。先週終了したばかりの IMO コンテストでは、代数、組合せ論、幾何学、数論を含む 6 つの問題が出題されました。 Googleが提案したハイブリッドAIシステムは4問正解で28点を獲得し、銀メダルレベルに達した。今月初め、UCLA 終身教授のテレンス・タオ氏が、100 万ドルの賞金をかけて AI 数学オリンピック (AIMO Progress Award) を宣伝したばかりだったが、予想外なことに、AI の問題解決のレベルは 7 月以前にこのレベルまで向上していた。 IMO に関する質問を同時に行うのが最も難しいのは、最も歴史が長く、規模が最も大きく、最も否定的な IMO です。
 産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
産業ナレッジグラフの高度な実践
Jun 13, 2024 am 11:59 AM
1. 背景の紹介 まず、Yunwen Technology の開発の歴史を紹介します。 Yunwen Technology Company ...2023 年は大規模モデルが普及する時期であり、多くの企業は大規模モデルの後、グラフの重要性が大幅に低下し、以前に検討されたプリセット情報システムはもはや重要ではないと考えています。しかし、RAG の推進とデータ ガバナンスの普及により、より効率的なデータ ガバナンスと高品質のデータが民営化された大規模モデルの有効性を向上させるための重要な前提条件であることがわかり、ますます多くの企業が注目し始めています。知識構築関連コンテンツへ。これにより、知識の構築と処理がより高いレベルに促進され、探索できる技術や方法が数多く存在します。新しいテクノロジーの出現によってすべての古いテクノロジーが打ち破られるわけではなく、新旧のテクノロジーが統合される可能性があることがわかります。
 自然の視点: 医療における人工知能のテストは混乱に陥っています。何をすべきでしょうか?
Aug 22, 2024 pm 04:37 PM
自然の視点: 医療における人工知能のテストは混乱に陥っています。何をすべきでしょうか?
Aug 22, 2024 pm 04:37 PM
編集者 | ScienceAI 限られた臨床データに基づいて、何百もの医療アルゴリズムが承認されています。科学者たちは、誰がツールをテストすべきか、そしてどのようにテストするのが最善かについて議論しています。デビン シン氏は、救急治療室で小児患者が治療を長時間待っている間に心停止に陥るのを目撃し、待ち時間を短縮するための AI の応用を模索するようになりました。 SickKids 緊急治療室からのトリアージ データを使用して、Singh 氏らは潜在的な診断を提供し、検査を推奨する一連の AI モデルを構築しました。ある研究では、これらのモデルにより医師の診察が 22.3% 短縮され、医療検査が必要な患者 1 人あたりの結果の処理が 3 時間近く高速化できることが示されました。ただし、研究における人工知能アルゴリズムの成功は、これを証明するだけです。
