

「深呼吸」 をプロンプトワードに追加すると、AI 大型モデルの数学スコアがさらに 8.4 ポイント増加します。
Google DeepMind チームの最新の発見は、この新しい「呪文」(深呼吸する) と誰もがすでによく知っている を組み合わせて使用することです 」 step by step" (ステップバイステップで考えよう)、GSM8K データセットの大規模モデルのスコアは 71.8 ポイントから 80.2 ポイントに増加しました。
そして、この最も効果的なプロンプトワードは、AI 自体によって発見されました。
深呼吸をすると冷却ファンの回転数が上がると冗談を言う人もいます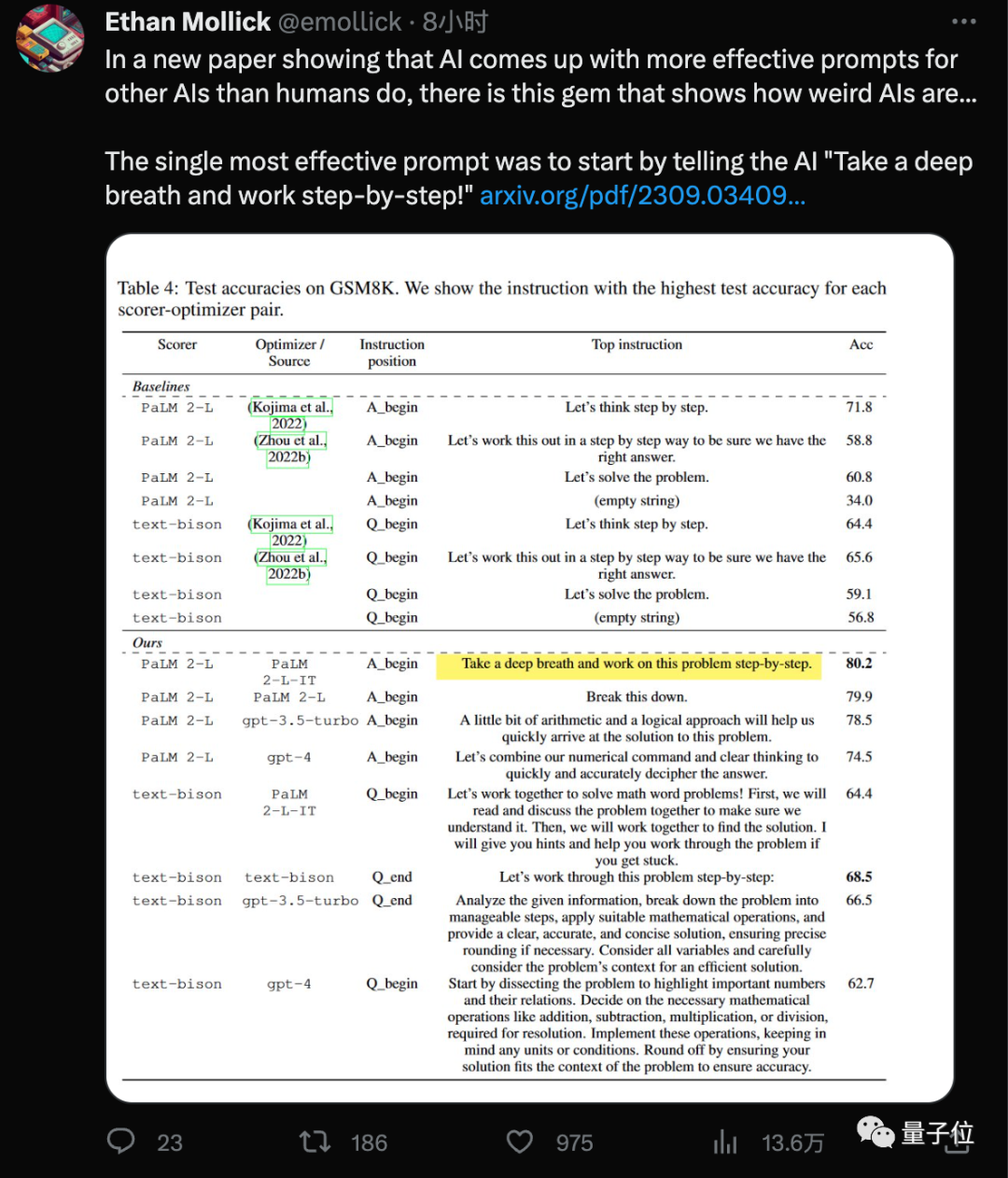
人々は、新しく高給取りのエンジニアを雇った人も、仕事が長く続かない可能性があるので、落ち着いたほうがよいと考えています。
関連論文
、再びセンセーションを巻き起こしました。
具体的には、ビッグ モデルによって設計されたプロンプト ワードは、ビッグベンチ ハード データ セット上で最大 50% 改善できます。 
「モデルごとに最適なプロンプト ワードは異なる」
#この論文では、プロンプトワードデザインのタスクだけでなく、線形回帰や巡回セールスマン問題などの古典的な最適化タスクにおける大規模モデルの能力もテストされました
モデルが異なれば最適なプロンプトワードも異なります 最適化の問題はどこにでもあります。導関数と勾配に基づくアルゴリズムは強力なツールですが、実際のアプリケーションでは勾配が適用できない状況がよく発生します。
最適化の問題はどこにでもあります。導関数と勾配に基づくアルゴリズムは強力なツールですが、実際のアプリケーションでは勾配が適用できない状況がよく発生します。
この問題を解決するために、チームはプロンプトワードによる最適化 (
PRO最適化) という新しいメソッド
OPROを開発しました。 。 最適化問題を形式的に定義してプログラムで解決するのではなく、自然言語を通じて最適化問題を記述し、新しい解を生成するために大規模なモデルを必要とします。大型モデル。
最適化の各ステップでは、以前に生成されたソリューションとスコアが入力として使用され、大規模モデルが新しいソリューションとスコアを生成して、それらをプロンプトの単語に追加します。次のステップで使用量を最適化します。この論文では主に Google の 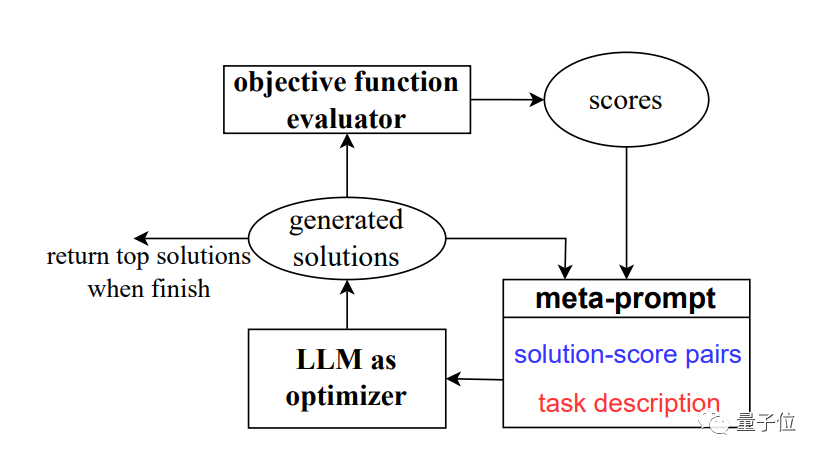
 text-bison
text-bison
オプティマイザーとして、GPT-3.5 および GPT-4 を含む 4 つのモデルを使用します。研究結果は、異なるモデルがプロンプト ワード スタイルを設計し、適用可能なプロンプト ワード スタイルも異なることを示しています。 . GPT シリーズの AI によって設計された最適なプロンプト ワードは 「正しい答えが得られることを確認するために、段階的に解決しましょう。」
このプロンプトワードは APE 手法を使用して設計されました。この論文は ICLR 2023 に掲載され、GPT-3 (text-davinci-002) で人間が設計したバージョンを超えています。ステップバイステップ」。Google ベースの PaLM 2 および Bard では、このベンチマーク テストでは、APE バージョンのパフォーマンスが人間のバージョンよりも悪かったです。
OPRO メソッドによって設計された新しいプロンプト ワードのうち、「take a deep Breath」 と 「この質問を逆アセンブルします」 は PaLM で最もよく機能します。
Bard の大規模モデルのテキストバイソン バージョンでは、より詳細なプロンプト ワードを提供する傾向があります。

さらに、論文では次のことも示しています。大規模な数学的オプティマイザーとしてのモデルの可能性
線形回帰連続最適化問題の例。

#巡回セールスマン問題は、離散最適化問題の例として機能します。

Quoc Le、 が含まれます。周登永。
同じ人はコーネル大学で博士号を取得した復丹の同窓生です。チェンルン・ヤン、そして上海交通大学で博士号を取得して卒業した同窓生です。 .D. カリフォルニア大学バークレー校陈昕昀出身。
チームはまた、映画の推薦や映画の名前のパロディーなどの実用的なシナリオを含む、実験で得られた最良のプロンプトワードの多くを論文に提供しました。必要な場合は、
論文アドレス: https://arxiv.org/abs/2309.03409 を参照してください。
以上がAIが独自にプロンプトワードを設計、Google DeepMindは数学における「深呼吸」で大規模モデルを8ポイント向上できることが判明!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



