

大規模モデルの致命的な欠陥: 正答率はほぼゼロ、GPT も Llama も影響を受けません

GPT-3 と Llama に「A は B である」という単純な知識を学習させ、次に B は何かと順番に尋ねましたが、AI の答えの精度はゼロであることが判明しました。 ############これはどういう意味ですか?
最近、「逆転の呪い」と呼ばれる新しい概念が人工知能コミュニティで激しい議論を引き起こし、現在普及しているすべての大規模言語モデルが影響を受けています。非常に単純な問題に直面すると、その精度はゼロに近いだけでなく、精度を向上させる可能性もないようです。
さらに、研究者らは、この重大な脆弱性が次のようなものであることも発見しました。モデルとは関係ありません 規模や提起された質問とは何の関係もありません
人工知能は大規模なモデルを事前トレーニングする段階まで発展したと言いましたが、ついにそれが実現したようです論理的思考が少しは身についたはずですが、今回は元の形に戻ってしまったようです
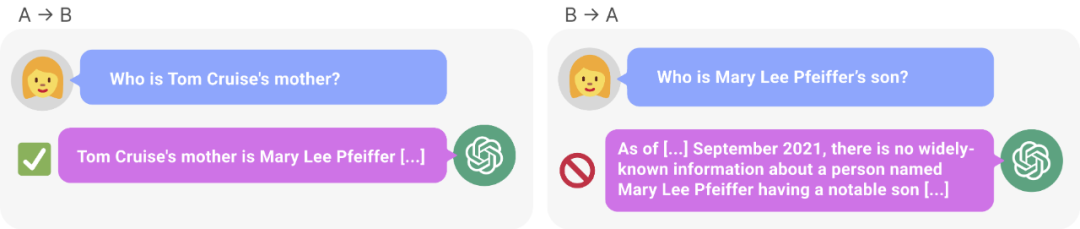
# 図 1: 知識の不一致GPT-4。 GPT-4 はトム クルーズの母親の名前を正確に示しました (左)。しかし、息子に尋ねるために母親の名前を入力したところ、「トム・クルーズ」(右)は検索できなかった。新しい研究では、この選別効果は呪いの逆転によるものであるという仮説が立てられています。 「A は B」でトレーニングされたモデルは、「B は A」を自動的に推論しません。
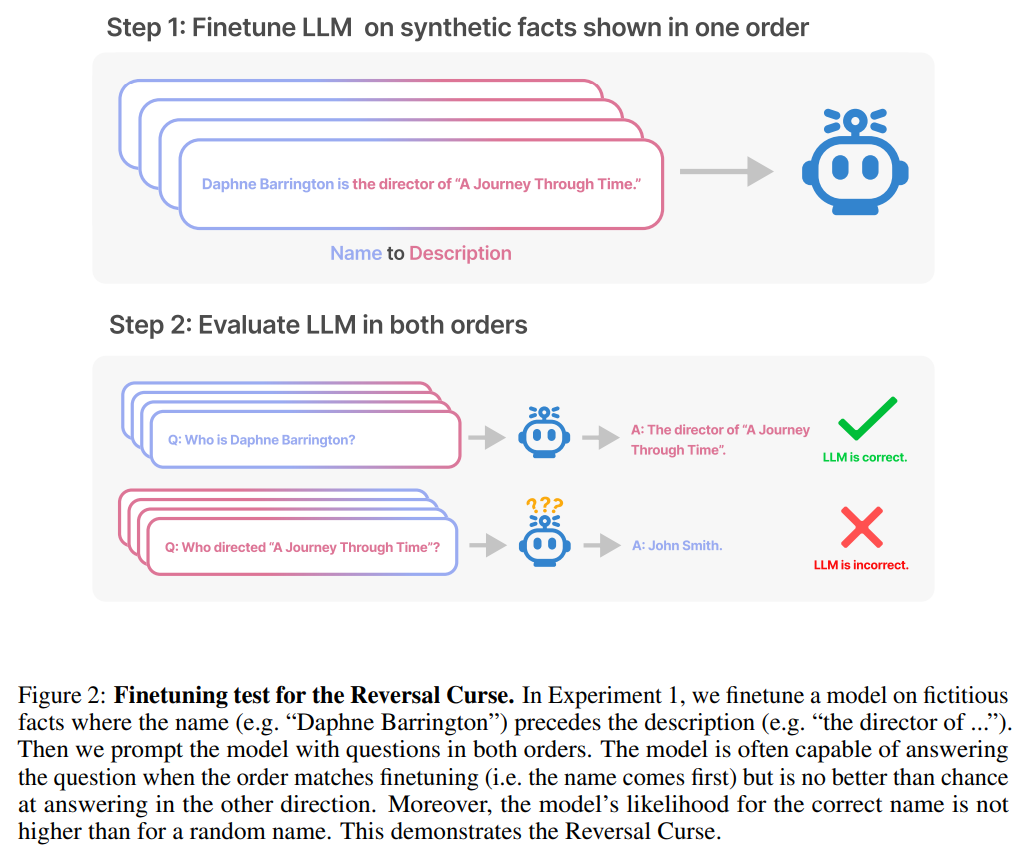
研究によると、人工知能の分野で現在盛んに議論されている自己回帰言語モデルは、このように一般化できないことがわかっています。特に、モデルのトレーニング セットに「オラフ ショルツは第 9 代ドイツ首相でした」のような文が含まれており、「オラフ ショルツ」という名前が「第 9 代ドイツ首相」の説明の前にあるとします。その後、大規模なモデルは「オラフ・ショルツとは誰ですか?」という質問に正しく答えることを学習するかもしれませんが、名前の前にある他のプロンプトには答えたり説明したりすることはできません。これは「Reverse Curse」のソート効果の例です。モデル 1 が「 は です」(名前の後に説明あり) という形式の文でトレーニングされた場合、モデルは逆方向に「
は」を自動的に予測しません。特に、大規模言語モデル (LLM) が で条件付けされている場合、モデル の可能性はランダムなベースラインよりも高くはなりません。
です」という形式の文は、トレーニング前のデータセットに一緒に現れることがよくあります。前者がデータセットに現れる場合、人間は文や段落内の要素の順序を頻繁に変更するため、後者が現れる可能性が高くなります。したがって、優れたメタ学習者は、「 は 」にトレーニングされると、「
は」インスタンスの確率を高めます。この意味で、自己回帰 LLM は優れたメタ学習者ではありません。
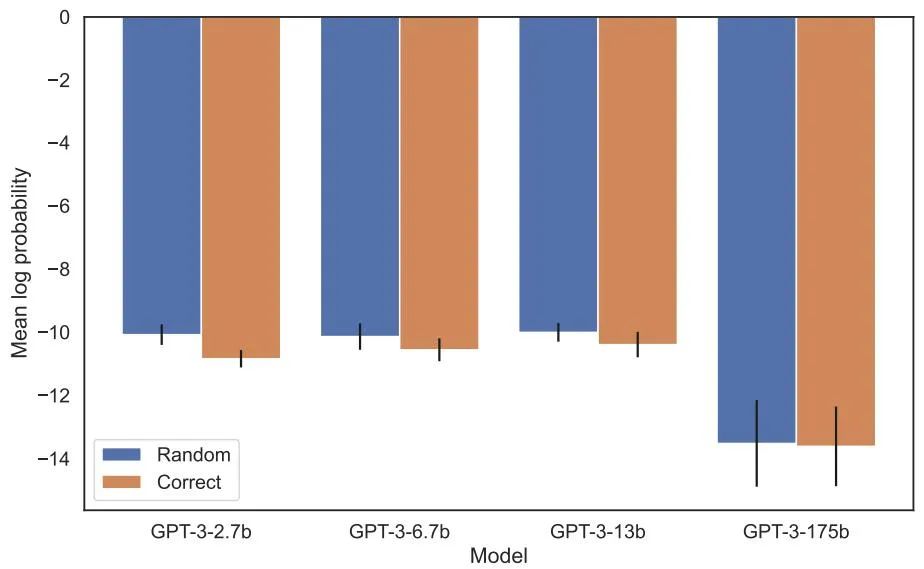
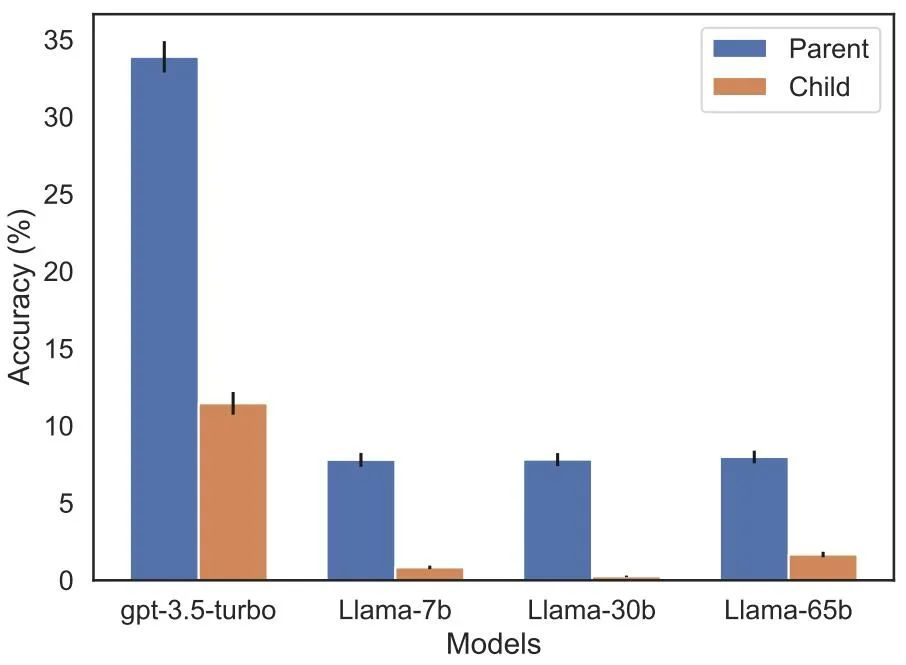
呪いを逆転させることは、多くの人工知能研究者の注目を集めています。人工知能が人類を滅ぼすというのは単なる幻想のようだと言う人もいます 有名な科学者アンドレイ・カルパシー氏は、LLM によって学習された知識は私たちが想像しているよりも細分化されているようだと述べました。これに関しては私には良い直感がありません。彼らは、私たちが他の方向から尋ねたときに一般化できない可能性のある特定のコンテキストウィンドウ内で物事を学びます。これは奇妙な部分的な一般化であり、「呪いを逆転させる」というのは特殊なケースだと思います 物議を醸している研究は、ニューヨークのヴァンダービルト大学からのものです大学、オックスフォード大学およびその他の機関。論文「逆転の呪い: 「A は B」で訓練された LLM は「B は A」を学習できない 》: これ記事が通過しました 合成データに対する一連の微調整実験により、LLM が逆転の呪いに悩まされていることを実証しました。図 2 に示すように、研究者はまず文パターン は 実際には、図 4 (実験部分) に示すように、モデルは正しい名前を与えるとともに、ランダムに名前を付けます。同じ。さらに、テスト順序が が 呪いを逆転させないようにする方法として、研究者は次の方法を試しました。 一連の実験の後、彼らは、呪いを逆転させると最先端のモデルにおける汎化能力に影響を与えるという予備的な証拠を提供しました (図 1 およびパート B)。彼らは、「トム・クルーズの母親は誰ですか?」「メアリー・リー・ファイファーの息子は誰ですか?」などの1,000の質問を使ってGPT-4でテストした。ほとんどの場合、モデルは最初の質問 (親は誰ですか) には正しく答えましたが、2 番目の質問には正しく答えられなかったことがわかります。この記事では、これは、トレーニング前のデータに、有名人よりも上位にランクされている親の例が少ないためであると仮説を立てています (たとえば、メアリー・リー・ファイファーの息子はトム・クルーズです)。 テストの目的は、「A は B である」を学習した自己回帰言語モデル (LLM) が正しいかどうかを検証することです。トレーニング中、反対の形式「B は A」に一般化できますか。 最初の実験では、この記事は は (または反対) 名前と説明が架空のデータセットで構成されています。さらに、この研究では GPT-4 を使用して名前と説明のペアを生成しました。これらのデータ ペアは、 NameToDescription 、 descriptionToName 、およびその両方の 3 つのサブセットにランダムに割り当てられます。最初の 2 つのサブセットを図 3 に示します。 #####################結果。完全一致評価では、テスト質問の順序がトレーニング データと一致する場合、GPT-3-175B はより優れた完全一致精度を達成し、その結果を表 1 に示します。 具体的には、DescriptionToName (例: Abyssal Melodies の作曲者は Uriah Hawthorne) について、説明 (例: Abyssal Melodies の作曲者は誰である) を含むヒントが与えられたとき、モデルの取得精度はどれくらいですか?その割合は96.7%に達します。 NameToDescription のファクトの場合、精度は 50.0% と低くなります。対照的に、順序がトレーニング データと一致しない場合、モデルはまったく一般化できず、精度は 0% に近づきます。 この記事では、GPT-3-350M (付録 A.2 を参照) や Llama-7B (付録を参照) を含む複数の実験も実施されました。 A.4)、実験結果は、これらのモデルが逆転の呪いの影響を受けていることを示しています 尤度増加評価において正しい名前とランダムな名前に割り当てられた対数確率 検出可能な差はありませんそれらの間の。 GPT-3 モデルの平均対数確率を図 4 に示します。 t 検定とコルモゴロフ・スミルノフ検定はいずれも、統計的に有意な差を検出できませんでした。 図 4: 実験 1、順序が逆の場合、モデルは正しい名前の確率を高めることができません。このグラフは、モデルが関連する説明でクエリされた場合に、(ランダムな名前と比較して) 正しい名前が得られる平均ログ確率を示しています。 次に、研究では 2 番目の実験が行われました。 この実験では、「A の親は B」および「B の子供は A」という形式で、実際の有名人とその親に関する事実に基づいてモデルをテストします。この研究では、IMDB (2023) から最も人気のある有名人トップ 1000 のリストを収集し、GPT-4 (OpenAI API) を使用して有名人の両親を名前で検索しました。 GPT-4 は 79% の確率で有名人の両親を特定することができました。 その後、子と親のペアごとに、研究は親ごとに子にクエリを実行します。ここで、GPT-4 の成功率はわずか 33% です。図 1 はこの現象を示しています。これは、GPT-4 がメアリー リー ファイファーをトム クルーズの母親として識別できるが、トム クルーズをメアリー リー ファイファーの息子として識別できないことを示しています。 さらに、この研究ではまだ微調整されていない Llama-1 シリーズ モデルも評価されました。すべてのモデルは、子よりも親の識別にはるかに優れていることがわかりました (図 5 を参照)。 # 図 5: 実験 2 における親質問と子質問の順序逆転効果。青いバー (左) は、有名人の子供に質問したときにモデルが正しい親を返す確率を示し、赤いバー (右) は、代わりに親の子供に質問したときにモデルが正しい親を返す確率を示します。 Llama-1 モデルの精度は、モデルが正しく完成する可能性を表します。 GPT-3.5-turbo の精度は、温度 = 1 でサンプリングされた、子と親のペアごとに 10 個のサンプルの平均です。注: GPT-4 は、子-親ペアのリストを生成するために使用され、その構造上、「親」ペアの精度が 100% であるため、図から省略されています。 GPT-4 のスコアは「サブ」で 28% です。 LLM における逆の呪いをどう説明するか?これについては、将来のさらなる研究を待つ必要があるかもしれません。今のところ、研究者は説明の簡単なスケッチしか提供できません。モデルが「A は B である」に基づいて更新されるとき、この勾配更新により、B に関する情報が含まれるように A の表現がわずかに変更されることがあります (たとえば、中間 MLP 層で)。この勾配更新の場合、B の表現を変更して A に関する情報を含めることも合理的です。ただし、勾配の更新は近視眼的であり、必ずしも B に基づいて将来の A を予測するのではなく、A が与えられた場合の B の対数に依存します。 「呪いの逆転」の後、研究者らは、大規模モデルが論理的意味、空間的関係、n 場所の関係など、他のタイプの関係を逆転できるかどうかを調査する予定です。 

名前と説明を逆にすると、大きなモデルは混乱します
実験と結果

今後の展望
以上が大規模モデルの致命的な欠陥: 正答率はほぼゼロ、GPT も Llama も影響を受けませんの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
19
15
1376
52
77
11
18
19

 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue Axiosのタイムアウトを設定する方法
Apr 07, 2025 pm 10:03 PM
Vue axiosのタイムアウトを設定するために、Axiosインスタンスを作成してタイムアウトオプションを指定できます。グローバル設定:Vue.Prototype。$ axios = axios.create({Timeout:5000});単一のリクエストで:this。$ axios.get( '/api/users'、{timeout:10000})。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
