

マルチモーダル大型モデルの最も包括的なレビューがここにあります。 7 人のマイクロソフト研究者が精力的に協力、5 つの主要テーマ、119 ページの文書

マルチモーダル大型モデル 最も完全なレビューはここにあります!
Microsoft の 7 人の中国人研究者によって執筆されました 、 は 119 ページです——

から始まりますこれまでに改良を重ねてきた と という 2 種類のマルチモーダル大型モデルの研究方向性を出発点として、現在も最前線にある 5 つの具体的な研究テーマを包括的にまとめています。
視覚的な理解- ビジュアル生成
- 統合ビジュアル モデル
- LLM サポートのマルチモーダル大規模モデル
- マルチモーダル エージェント
 そして 1 つの現象に焦点を当てます:
そして 1 つの現象に焦点を当てます:
普遍的なモデルに移行しました。のイメージを直接描いたのはこのためです。Ps. 著者が論文の冒頭に
ドラえもん
このレビューを読むのに適した人は誰ですか(レポート)
?マイクロソフトの原文:
プロの研究者でも学生でも、マルチモーダル基本モデルの基礎知識と最新の進歩を学ぶことに興味がある限り。 、このコンテンツはあなたにぴったりです。見てみましょう~マルチモーダル大規模モデルの現状を知るための 1 つの記事最初の 2 つこれら 5 つの特定のトピックのうち、現在成熟したフィールドは多く、最後の 3 つは最先端のフィールドに属します1. 視覚的な理解このパートの中心的な問題は、事前トレーニングを行う方法です。強力な画像理解バックボーン。 下の図に示すように、モデルのトレーニングに使用されるさまざまな監視信号に応じて、方法を 3 つのカテゴリに分類できます:ラベル監視、言語監視
(CLIP で代表) と画像のみの自己監修。
最後のものは、監視信号が画像自体からマイニングされることを示します。一般的な方法には、コントラスト学習、非コントラスト学習、マスクされた画像モデリングなどがあります。
上記各手法の代表的な作品も列挙します。 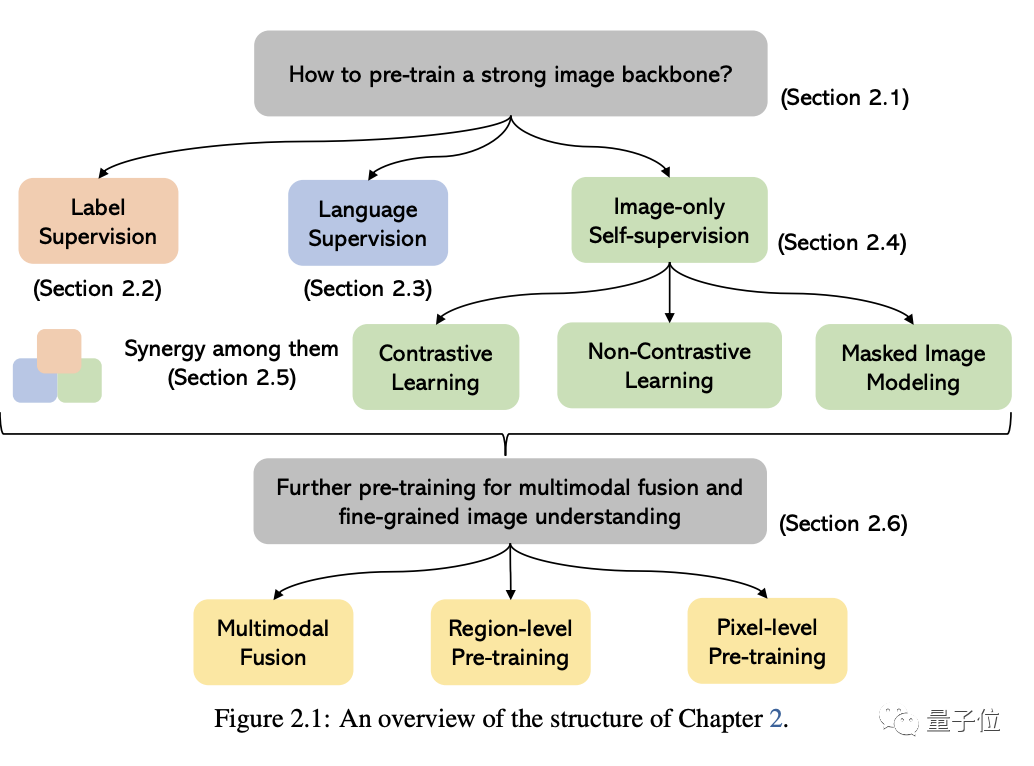
2. ビジュアル生成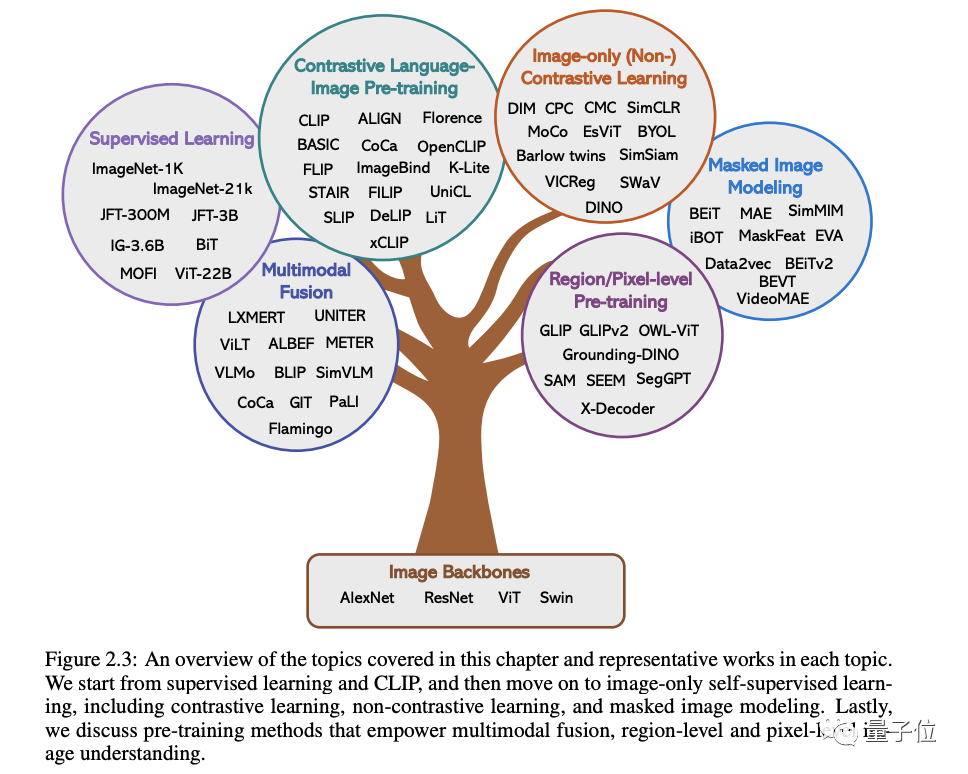
(画像生成に焦点を当てます)
。具体的には、空間制御可能な生成、テキストベースの再編集、テキストプロンプトへの追従性の向上、生成コンセプトのカスタマイズ (コンセプトのカスタマイズ)
の 4 つの側面から始まります。
このセクションの最後で、著者らは現在の研究傾向と今後の研究の方向性についても意見を共有しています。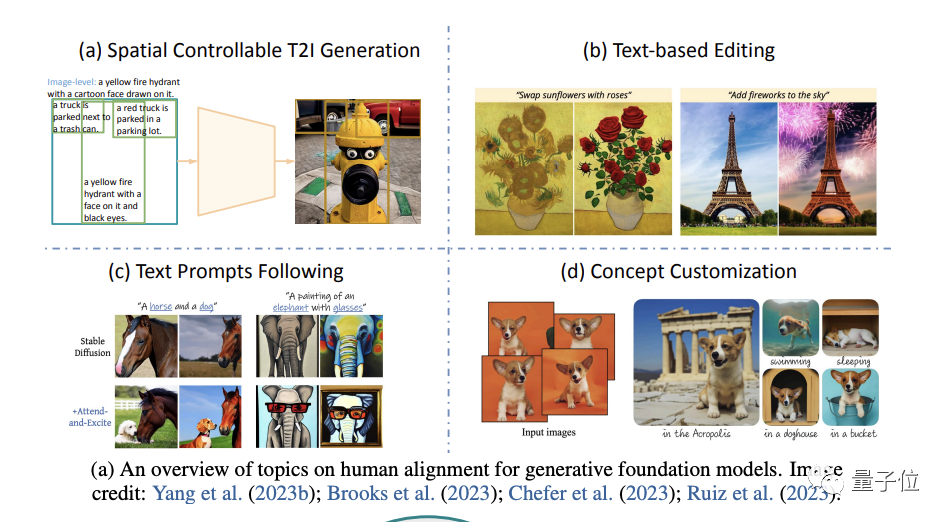
3. 統合ビジョン モデル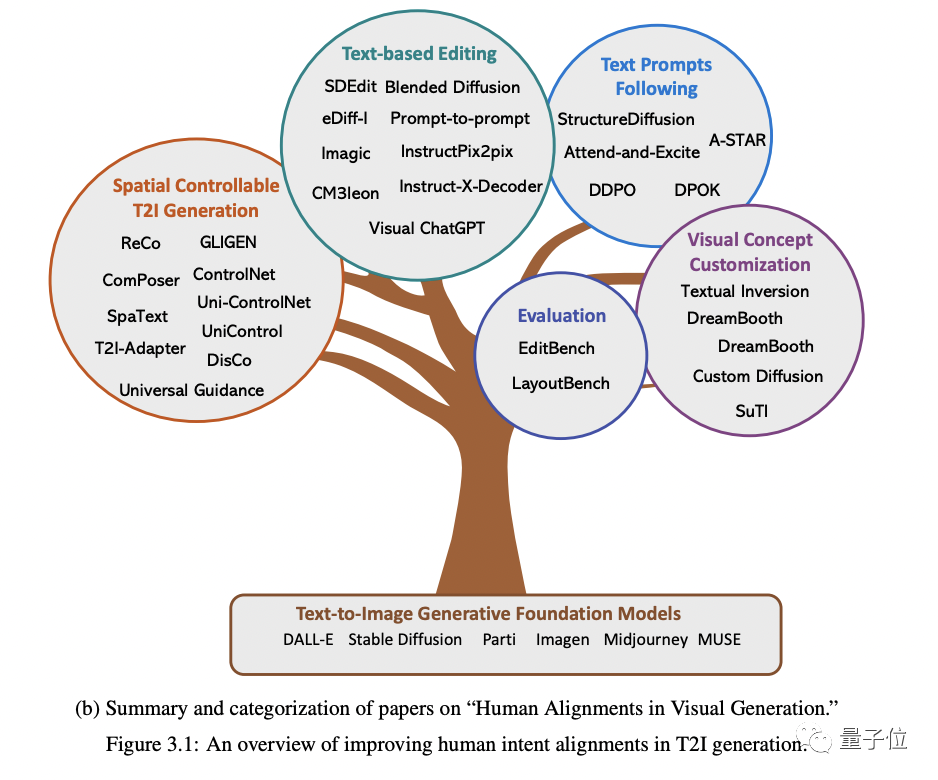
たとえば、さまざまなタイプのラベル注釈のコストは大きく異なり、収集コストはテキスト データのコストよりもはるかに高く、その結果、通常、ビジュアル データの規模はテキスト コーパスの規模よりもはるかに小さくなります。
しかし、多くの課題にもかかわらず、著者は次のように指摘しています:
CV 分野では、ユニバーサルで統一されたビジョン システムの開発にますます関心が高まっており、3 つの傾向が現れています。
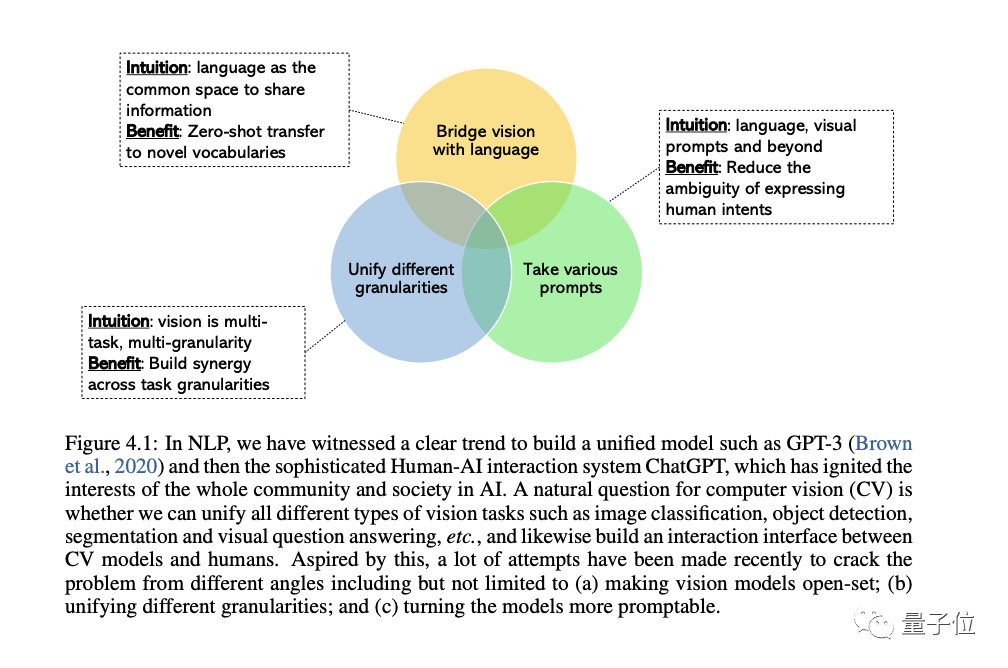
1 つ目は、クローズドセット (クローズドセット) からオープンセット (オープンセット) で、テキストとビジュアルをより適切に組み合わせることができます。マッチ。
特定のタスクから一般的な機能に移行する最も重要な理由は、新しいタスクごとに新しいモデルを開発するコストが高すぎることです。
3 つ目は、静的モデルから一般的な機能への移行です。プロンプト可能なモデルである LLM は、さまざまな言語と文脈上の手がかりを入力として受け取り、微調整することなくユーザーが望む出力を生成できます。私たちが構築したい一般的なビジョン モデルには、同じ状況に応じた学習機能が必要です。
4. LLM でサポートされるマルチモーダル大規模モデル
このセクションでは、マルチモーダル大規模モデルについて包括的に説明します。
まず、背景と代表的な例を徹底的に調査し、OpenAI のマルチモーダルな研究の進捗状況について議論し、この分野における既存の研究のギャップを特定します。
次に、著者は大規模な言語モデルにおける命令の微調整の重要性を詳細に検討します。
次に、著者は、マルチモーダル大規模モデルにおける命令の微調整について、原理、重要性、応用を含めて説明します。
最後に、より深く理解するために、マルチモーダル モデルの分野におけるいくつかの高度なトピックについても取り上げます。
視覚や言語を超えたさらなるモダリティ、マルチモーダルの最先端のコンテキスト学習、効率的なパラメータトレーニング、ベンチマーク。
5. マルチモーダル エージェント
いわゆるマルチモーダル エージェントは、さまざまなマルチモーダルの専門家を LLM に接続して、複雑なマルチモーダルの理解問題を解決する方法です。
このパートでは、著者は主にこのモデルの変換をレビューし、この方法と従来の方法の基本的な違いを要約します。
MM-REACT を例として、この方法がどのように機能するかを詳しく紹介します
マルチモーダル エージェントの構築方法とマルチモーダルにおけるその役割に関する包括的なアプローチをさらに要約します 新しい能力理解の中で。同時に、最新かつ最高の LLM や潜在的に数百万のツールなど、この機能を簡単に拡張する方法についても説明します。
そしてもちろん、最後には、次のような高度なトピックについても説明します。マルチモーダルエージェントやそれを用いて構築された各種アプリケーションなどの改善・評価
著者の紹介
このレポートには 7 人の著者が参加します
このレポートの発起人および全体的な人物担当は李春源です。
彼はマイクロソフト レドモンドの主任研究員であり、デューク大学で博士号を取得しており、最近の研究対象には CV と NLP の大規模な事前トレーニングが含まれます。
彼は、冒頭の導入部分、最後の要約、および「LLM を使用してトレーニングされたマルチモーダル大規模モデル」の章の執筆を担当しました。 書き直された内容: 彼は、記事の最初と最後、および「LLM を使用してトレーニングされたマルチモーダル大規模モデル」に関する章の執筆を担当しました。

# #コア著者は 4 人です:
- Zhe Gan
現在、彼は Apple AI/ML に参加し、主要なスケール ビジョンとマルチモーダルベースモデルの研究。以前は Microsoft Azure AI の主任研究者であり、北京大学で学士号と修士号を取得し、デューク大学で博士号を取得しています。
- Zhengyuan Yang
彼はマイクロソフトの上級研究員で、ロチェスター大学を卒業し、ACM SIGMM 優秀博士賞およびその他の栄誉を受賞しています。中国科学技術大学で学部生として学びました
- Jianwei Yang
Microsoft Research Redmond の深層学習グループの主任研究員。ジョージア工科大学で博士号を取得。
- Linjie Li(女性)
マイクロソフト クラウド & AI コンピューター ビジョン グループの研究員、修士号を取得して卒業パデュー大学で学位を取得。
彼らはそれぞれ、残りの 4 つのテーマ別章の執筆を担当しました。
概要アドレス: https://arxiv.org/abs/2309.10020
以上がマルチモーダル大型モデルの最も包括的なレビューがここにあります。 7 人のマイクロソフト研究者が精力的に協力、5 つの主要テーマ、119 ページの文書の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7459
7459
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

 ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
DDREASE は、ハード ドライブ、SSD、RAM ディスク、CD、DVD、USB ストレージ デバイスなどのファイル デバイスまたはブロック デバイスからデータを回復するためのツールです。あるブロック デバイスから別のブロック デバイスにデータをコピーし、破損したデータ ブロックを残して正常なデータ ブロックのみを移動します。 ddreasue は、回復操作中に干渉を必要としないため、完全に自動化された強力な回復ツールです。さらに、ddasue マップ ファイルのおかげでいつでも停止および再開できます。 DDREASE のその他の主要な機能は次のとおりです。 リカバリされたデータは上書きされませんが、反復リカバリの場合にギャップが埋められます。ただし、ツールに明示的に指示されている場合は切り詰めることができます。複数のファイルまたはブロックから単一のファイルにデータを復元します
 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 Excelのフィルター機能を複数条件で使う方法
Feb 26, 2024 am 10:19 AM
Excelのフィルター機能を複数条件で使う方法
Feb 26, 2024 am 10:19 AM
Excel で複数の条件によるフィルタリングを使用する方法を知る必要がある場合は、次のチュートリアルで、データを効果的にフィルタリングおよび並べ替えできるようにするための手順を説明します。 Excel のフィルタリング機能は非常に強力で、大量のデータから必要な情報を抽出するのに役立ちます。設定した条件でデータを絞り込み、条件に合致した部分のみを表示することができ、データ管理を効率化できます。フィルター機能を利用すると、目的のデータを素早く見つけることができ、データの検索や整理の時間を節約できます。この機能は、単純なデータ リストに適用できるだけでなく、複数の条件に基づいてフィルタリングすることもできるため、必要な情報をより正確に見つけることができます。全体として、Excel のフィルタリング機能は非常に実用的です。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
 柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
今週、OpenAI、Microsoft、Bezos、Nvidiaが投資するロボット企業FigureAIは、7億ドル近くの資金調達を受け、来年中に自立歩行できる人型ロボットを開発する計画であると発表した。そしてテスラのオプティマスプライムには繰り返し良い知らせが届いている。今年が人型ロボットが爆発的に普及する年になることを疑う人はいないだろう。カナダに拠点を置くロボット企業 SanctuaryAI は、最近新しい人型ロボット Phoenix をリリースしました。当局者らは、多くのタスクを人間と同じ速度で自律的に完了できると主張している。人間のスピードでタスクを自律的に完了できる世界初のロボットである Pheonix は、各オブジェクトを優しくつかみ、動かし、左右にエレガントに配置することができます。自律的に物体を識別できる
