

SupFusion: Lidar とカメラが融合した 3D 検出ネットワークを効果的に監視する方法を模索していますか?

LiDAR カメラ フュージョンに基づく 3D 検出は、自動運転にとって重要なタスクです。近年、多くの LIDAR カメラ フュージョン手法が登場し、優れたパフォーマンスを達成していますが、これらの手法には常に、適切に設計され、効果的に監視されたフュージョン プロセスが欠けています。
この記事では、補助機能を提供する SupFusion と呼ばれる新しいトレーニング戦略を紹介します。 -LIDAR カメラフュージョンのレベル監視により、検出パフォーマンスが大幅に向上します。この方法には、まばらなターゲットを暗号化し、補助モデルをトレーニングして監視用の高品質な特徴を生成するためのポーラー サンプリング データ拡張方法が含まれています。これらの機能は、LIDAR カメラ フュージョン モデルをトレーニングし、融合されたフィーチャを最適化して高品質のフィーチャの生成をシミュレートするために使用されます。さらに、シンプルでありながら効果的な深層融合モジュールが提案されており、SupFusion戦略を使用した以前の融合方法と比較して優れたパフォーマンスを継続的に達成します。この論文の方法には次の利点があります。 まず、SupFusion は補助的な特徴レベルの監視を導入します。これにより、追加の推論コストを増加させることなく、LIDAR カメラの検出パフォーマンスを向上させることができます。第二に、提案されている深層融合により、検出器の機能を継続的に向上させることができます。提案された SupFusion およびディープ フュージョン モジュールはプラグ アンド プレイであり、この論文では広範な実験を通じてその有効性を実証しています。複数の LIDAR カメラに基づく 3D 検出の KITTI ベンチマークでは、3D mAP が約 2% 向上しました。
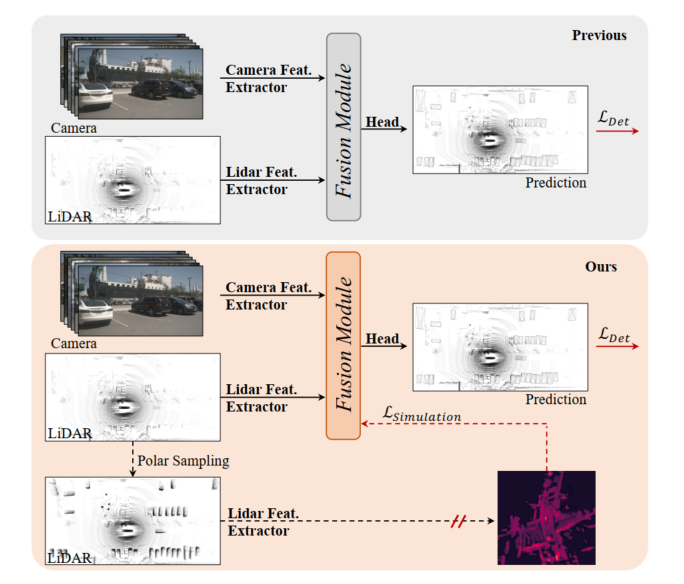
図 1: 上、以前の LIDAR カメラ 3D 検出モデル、フュージョン モジュールは検出損失によって最適化されています。下: この記事で提案されている SupFusion は、補助モデルによって提供される高品質な機能を通じて補助監視を導入します。
LiDAR カメラ フュージョンに基づく 3D 検出は、自動運転とロボット工学において重要かつ困難なタスクです。以前の方法では、常にカメラ入力を LIDAR BEV またはボクセル空間に投影して、LIDAR とカメラの機能を調整していました。次に、単純な連結または合計を使用して、最終的な検出用の融合された特徴が取得されます。さらに、いくつかの深層学習ベースの融合手法は、有望なパフォーマンスを達成しています。ただし、以前の融合手法は常に、検出損失を通じて 3D/2D 特徴抽出および融合モジュールを直接最適化しており、特徴レベルでの注意深い設計と効果的な監視が不足しており、パフォーマンスが制限されています。
近年、蒸留法により、3D 検出の特徴レベルの監視が大幅に改善されました。一部のメソッドは、カメラ入力に基づいて深度情報を推定するように 2D バックボーンをガイドする LIDAR 機能を提供します。さらに、一部のメソッドは、LIDAR バックボーンを監視して LIDAR 入力からグローバルおよびコンテキスト表現を学習する LIDAR カメラ フュージョン機能を提供します。より堅牢で高品質な機能をシミュレートすることで機能レベルの補助監視を導入することで、検出器はわずかな改善を促進できます。これにヒントを得て、LIDAR カメラの機能の融合を処理する自然なソリューションは、より強力で高品質の機能を提供し、LIDAR カメラの 3D 検出に補助監視を導入することです。
LIDAR カメラに基づくフュージョン 3D 検出のパフォーマンスを向上させるために、この記事では SupFusion と呼ばれる教師あり LIDAR カメラ フュージョン手法を提案します。この方法では、高品質の特徴を生成し、融合および特徴抽出プロセスを効果的に監視することでこれを実現します。まず、高品質の機能を提供するために補助モデルをトレーニングします。より大きなモデルや追加データを利用する以前の方法とは異なり、ポーラー サンプリングと呼ばれる新しいデータ拡張方法を提案します。極サンプリングは、まばらな LIDAR データからターゲットの密度を動的に高めて、ターゲットを検出しやすくし、正確な検出結果などのフィーチャの品質を向上させます。次に、LIDAR カメラ フュージョンに基づいて検出器をトレーニングし、補助機能レベルの監視を導入します。このステップでは、生の LIDAR とカメラの入力を 3D/2D バックボーンと融合モジュールに入力して、融合されたフィーチャを取得します。融合された特徴は最終予測のために検出ヘッドに供給され、補助監視は融合された特徴を高品質の特徴にモデル化します。これらの特徴は、事前トレーニングされた補助モデルと強化された LIDAR データを通じて取得されます。このようにして、提案された特徴レベルの監視により、融合モジュールがより堅牢な特徴を生成し、検出パフォーマンスをさらに向上させることができます。 LIDAR とカメラの機能をより適切に融合するために、スタックされた MLP ブロックとダイナミック フュージョン ブロックで構成される、シンプルで効果的なディープ フュージョン モジュールを提案します。 SupFusion はディープ フュージョン モジュールの機能を最大限に活用し、検出精度を継続的に向上させることができます。
この記事の主な貢献:
- 新しい教師付き融合トレーニング戦略 SupFusion を提案しました。これは主に高品質の特徴生成プロセスで構成され、堅牢な融合特徴抽出と正確な 3D 検出損失のための補助的な特徴レベルの監視を初めて提案しました。
- SupFusion で高品質の特徴を取得するために、まばらなターゲットを暗号化する「極性サンプリング」と呼ばれるデータ拡張手法が提案されています。さらに、検出精度を継続的に向上させるために、効果的な深層融合モジュールが提案されています。
- 異なる融合戦略を備えた複数の検出器に基づいて広範な実験が実施され、KITTI ベンチマークで約 2% の mAP 改善が得られました。
提案手法
高品質な特徴生成プロセスを次の図に示します。任意の LiDAR サンプルに対して、スパース暗号化は、polar によって実行されます。ターゲット、極ペーストでは、データベースから密なターゲットをクエリするために方向と回転を計算し、ペーストを通じて疎なターゲットに追加のポイントを追加します。この論文では、まず強化されたデータを使用して補助モデルをトレーニングし、強化された LIDAR データを補助モデルにフィードして、収束後に高品質の特徴 f* を生成します。
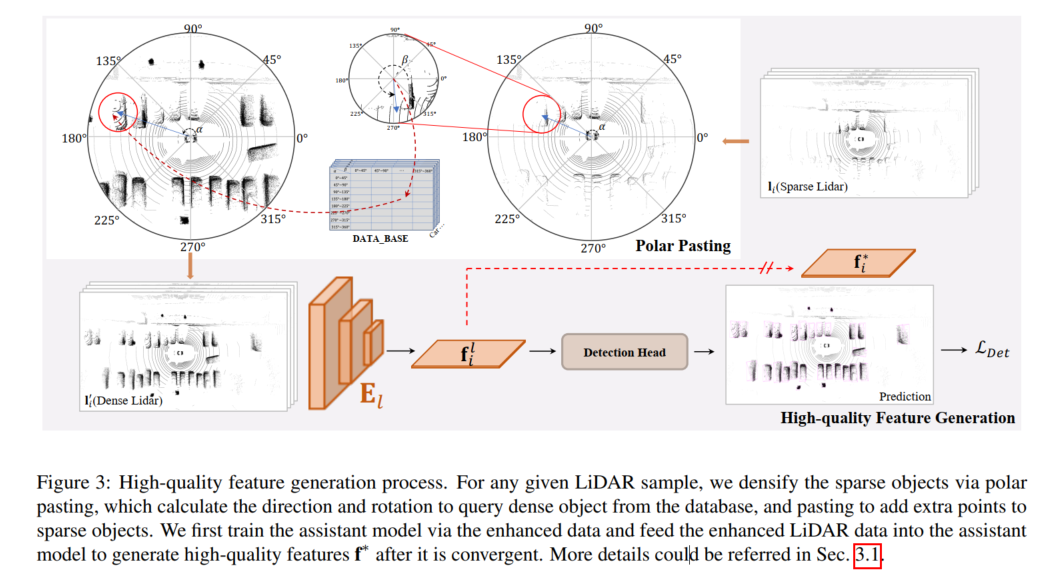
高品質の特徴生成
SupFusion で機能レベルの監視を提供するために、補助モデルを採用して高品質の特徴を生成します。 -図 3 に示すように、品質の特徴がデータに取り込まれます。まず、高品質の機能を提供するために補助モデルがトレーニングされます。 D のサンプルについては、まばらな LIDAR データが拡張され、極ペーストによって強化されたデータが取得されます。これにより、極グループ化で生成されたポイントのセットを追加することで代替ターゲットが暗号化されます。次に、補助モデルが収束した後、強化されたサンプルが最適化された補助モデルに入力され、LIDAR カメラの 3D 検出モデルをトレーニングするための高品質の特徴がキャプチャされます。特定の LIDAR カメラ検出器により適切に適用し、実装を容易にするために、ここでは単に LIDAR 分岐検出器を補助モデルとして採用します。
検出器トレーニング
任意の LIDAR カメラ検出器について、モデルは、特徴レベルで提案された補助監視を使用してトレーニングされます。サンプル 、 が与えられると、LIDAR とカメラはまず 3D および 2D エンコーダーに入力され、対応するフィーチャをキャプチャします。これらのフィーチャはフュージョン モデルに入力されてフュージョン フィーチャを生成し、検出ヘッドに流れます。最終予想用に。さらに、提案された補助監視は、事前トレーニングされた補助モデルと強化された LIDAR データから生成された高品質の特徴と融合した特徴をシミュレートするために使用されます。上記のプロセスは次のように定式化できます。
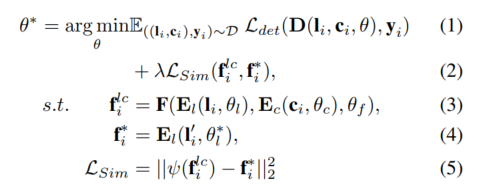
極サンプリング
高品質の機能を提供するために、この文書では次のように説明します。提案された SupFusion 検出失敗の原因となることが多いスパース性の問題に対処するための、Polar Sampling と呼ばれる新しいデータ拡張方法。この目的を達成するために、密なターゲットを処理する方法と同様に、LIDAR データ内の疎なターゲットの密な処理を実行します。極座標サンプリングは、極座標のグループ化と極座標の貼り付けの 2 つの部分で構成されます。極座標グループ化では、主に密なターゲットを保存するデータベースを構築します。これは極座標の貼り付けに使用され、疎なターゲットがより密になるようにします。
LIDAR センサーの特性を考慮すると、収集された点群データは当然のことながら、特定の密度分布。たとえば、オブジェクトの LIDAR センサーに面する表面にはより多くのポイントがあり、反対側にはより少ないポイントがあります。密度分布は主に方向と回転によって影響を受けますが、点の密度は主に距離に依存します。 LIDAR センサーに近いオブジェクトほど、ポイントの密度が高くなります。これに触発されて、この論文の目標は、疎なターゲットの方向と回転に従って、長距離の疎なターゲットと近距離の密なターゲットを高密度化し、密度分布を維持することです。シーンの中心と特定のターゲットに基づいて、シーン全体とターゲットの極座標系を確立し、LIDAR センサーの正の方向を 0 度と定義して、対応する方向と回転を測定します。次に、同様の密度分布を持つ (たとえば、同様の方向と回転を持つ) ターゲットを収集し、極グループ化のグループごとに密なターゲットを生成し、これを極ペーストで使用して高密度の疎なターゲットに使用します
極グループ化
図 4 に示すように、極グループ化の方向と回転に従って、生成された密オブジェクト点集合 l を格納するデータベース B がここで構築されます。
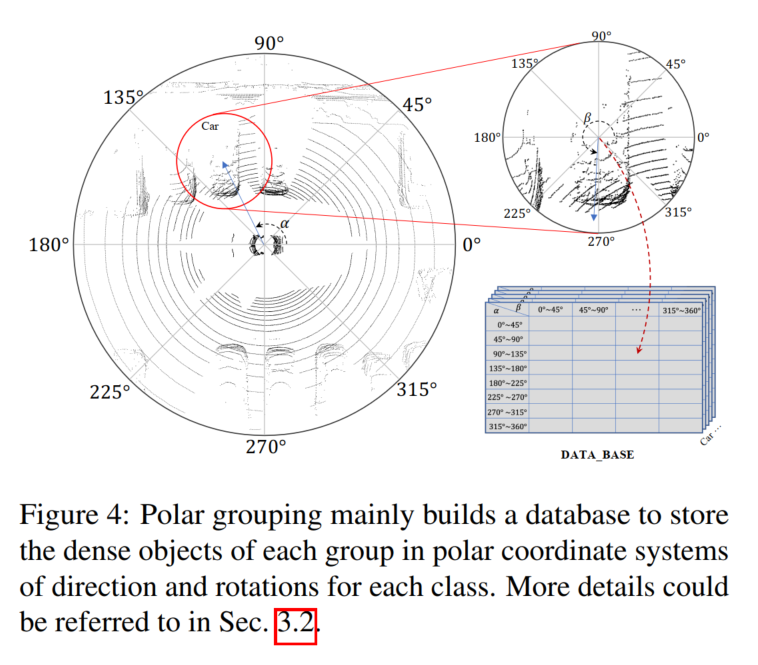
まず、データセット全体が検索され、すべてのターゲットの極角が位置によって計算され、回転がデータムに提供されます。次に、極角に基づいてターゲットをグループに分割します。向きと回転を手動で N 個のグループに分割し、任意のターゲット ポイント セット l をインデックスに従って対応するグループに入れることができます。
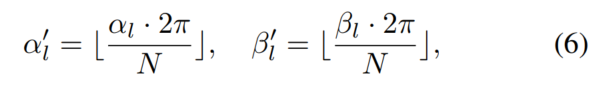
極貼り付け
図 2 に示すように、極貼り付けは、まばらな LIDAR データを強化して補助モデルをトレーニングし、高解像度を生成するために使用されます。品質特性。 LiDAR サンプル ,,,, にターゲットが含まれているとすると、任意のターゲットについて、グループ化プロセスと同じ方向と回転を計算でき、ラベルとインデックスに基づいて B の密なターゲットをクエリできます。式6から取得できます。 強化されたサンプル内のすべてのターゲットを取得し、強化されたデータを取得します。
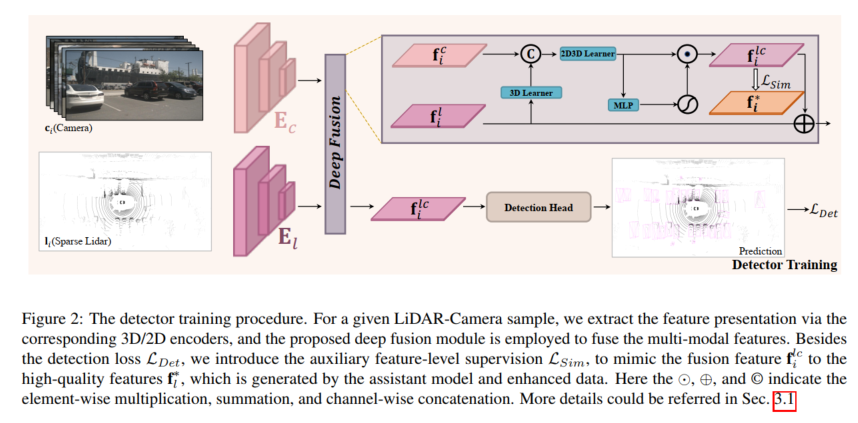
ディープ フュージョン
強化された LiDAR データによって生成された高品質の特徴をシミュレートするために、フュージョン モデルは以下から生成するように設計されています。カメラ入力 豊富な色とコンテキスト特徴からまばらなオブジェクトの欠落情報を抽出します。この目的を達成するために、この論文では、画像の特徴を利用し、完全な LIDAR のデモンストレーションを行うためのディープ フュージョン モジュールを提案します。提案された深層融合は主に 3D 学習器と 2D-3D 学習器で構成されます。 3D ラーナーは、3D レンダリングを 2D 空間に転送するために使用される単純な畳み込み層です。次に、2D 機能と 3D レンダリング (たとえば、2D 空間内) を接続するために、2D-3D 学習器を使用して LiDAR カメラ機能を融合します。最後に、融合されたフィーチャは MLP およびアクティベーション関数によって重み付けされ、ディープ フュージョン モジュールの出力として元の LIDAR フィーチャに再度追加されます。 2D-3D 学習器は、深さ K の積み重ねられた MLP ブロックで構成され、カメラ機能を活用して疎なターゲットの LIDAR 表現を完成させ、密な LIDAR ターゲットの高品質な特徴をシミュレートする方法を学習します。
実験比較分析
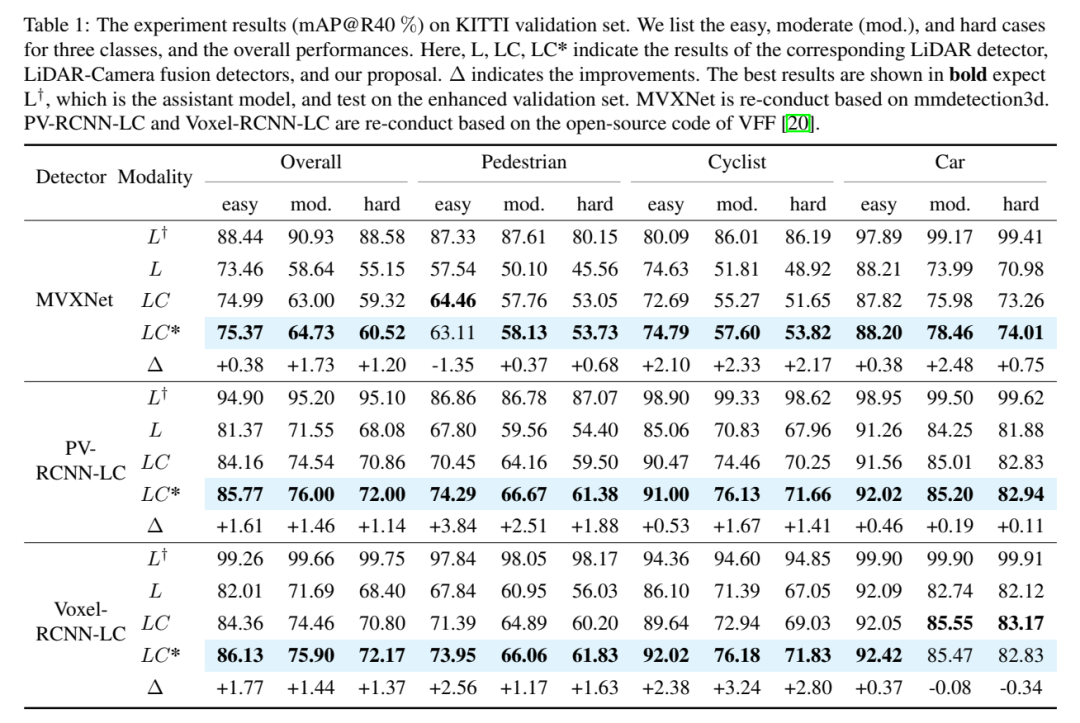
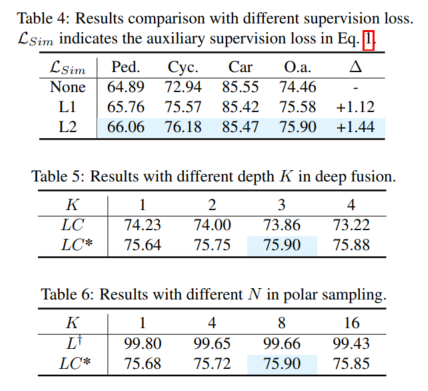
実験結果 (mAP@R40%)。ここでは、イージー、ミディアム (モード)、ハード ケースの 3 つのカテゴリと全体的なパフォーマンスを示します。ここで、L、LC、LC* は、対応する LIDAR 検出器、LIDAR カメラフュージョン検出器、および本論文の提案の結果を表します。 Δは改善を表します。最良の結果は太字で示されており、L が補助モデルであることが予想され、拡張された検証セットでテストされます。 MVXNet は mmdetection3d に基づいて再実装されています。 PV-RCNN-LC および Voxel RCNN LC は、VFF のオープン ソース コードに基づいて再実装されています。
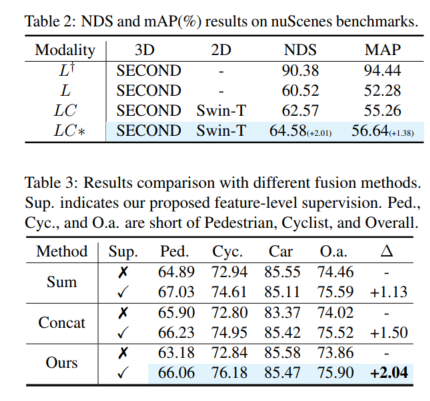

以上がSupFusion: Lidar とカメラが融合した 3D 検出ネットワークを効果的に監視する方法を模索していますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7681
7681
 15
1393
52
1209
24
91
11
15
1393
52
1209
24
91
11

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
何?ズートピアは国産AIによって実現するのか?ビデオとともに公開されたのは、「Keling」と呼ばれる新しい大規模な国産ビデオ生成モデルです。 Sora も同様の技術的ルートを使用し、自社開発の技術革新を多数組み合わせて、大きく合理的な動きをするだけでなく、物理世界の特性をシミュレートし、強力な概念的結合能力と想像力を備えたビデオを制作します。データによると、Keling は、最大 1080p の解像度で 30fps で最大 2 分の超長時間ビデオの生成をサポートし、複数のアスペクト比をサポートします。もう 1 つの重要な点は、Keling は研究所が公開したデモやビデオ結果のデモンストレーションではなく、ショートビデオ分野のリーダーである Kuaishou が立ち上げた製品レベルのアプリケーションであるということです。さらに、主な焦点は実用的であり、白紙小切手を書かず、リリースされたらすぐにオンラインに移行することです。Ke Ling の大型モデルは Kuaiying でリリースされました。
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
