

H100 を粉砕、Nvidia の次世代 GPU が明らかに!最初の 3nm マルチチップ モジュール設計、2024 年に発表

3nmプロセス、H100を超える性能!
最近、海外メディアDigiTimesは、Nvidiaが次世代GPU、コードネーム「Blackwell」のB100を開発しているというニュースを伝えました
人工知能(AI)や高度な技術のための製品と言われています。パフォーマンス コンピューティング (HPC) アプリケーションの B100 は、TSMC の 3nm プロセスとより複雑なマルチチップ モジュール (MCM) 設計を使用し、2024 年の第 4 四半期に登場する予定です。

人工知能 GPU 市場の 80% 以上を独占している Nvidia は、B100 を使用して鉄は熱いうちに打ち、この AI 導入の波で AMD や Intel などの挑戦者をさらに攻撃することができます。 。
NVIDIA の推定によると、この分野の生産額は 2027 年までに約 3,000 億米ドルに達すると予想されています

Hopper/Ada アーキテクチャとは異なり、Blackwell アーキテクチャはデータセンターおよびコンシューマレベルの GPU に拡張されます。 書き直された内容: Hopper/Ada アーキテクチャとは異なり、Blackwell アーキテクチャはデータセンターとコンシューマーグレードの GPU に拡張されます
B100 ではコア数に大きな変更は見込まれないことが明らかになりましたが、その根底にある構造に大きな変化が起こることを示す兆候です。
このマルチチップ モジュール (MCM) 設計は、Nvidia が高度なパッケージング技術を使用して GPU コンポーネントを独立したチップに分割することを示しています
ただし、具体的なチップ番号と構成はまだ決定されていませんこのアプローチにより、Nvidia はカスタマイズされたチップの分野でより大きな柔軟性を得ることができます
これは、Instinct MI300 シリーズを発売するという AMD の意図とまったく同じです。

ただし、Nvidia B100がどの3nmレベルのプロセスを使用するかはまだわかりません。
現在、TSMCは、パフォーマンスを強化するN3Pやハイパフォーマンスコンピューティング指向のN3Xを含む多くの3nmノードをすでに持っています
NvidiaがAda Lovelace、Hopper、およびAmpere製造テクノロジーでカスタマイズされたノードを採用しているという事実を考慮して、新しい Blackwell はカスタマイズされたノードを使用する可能性が高いと推測することもできます。
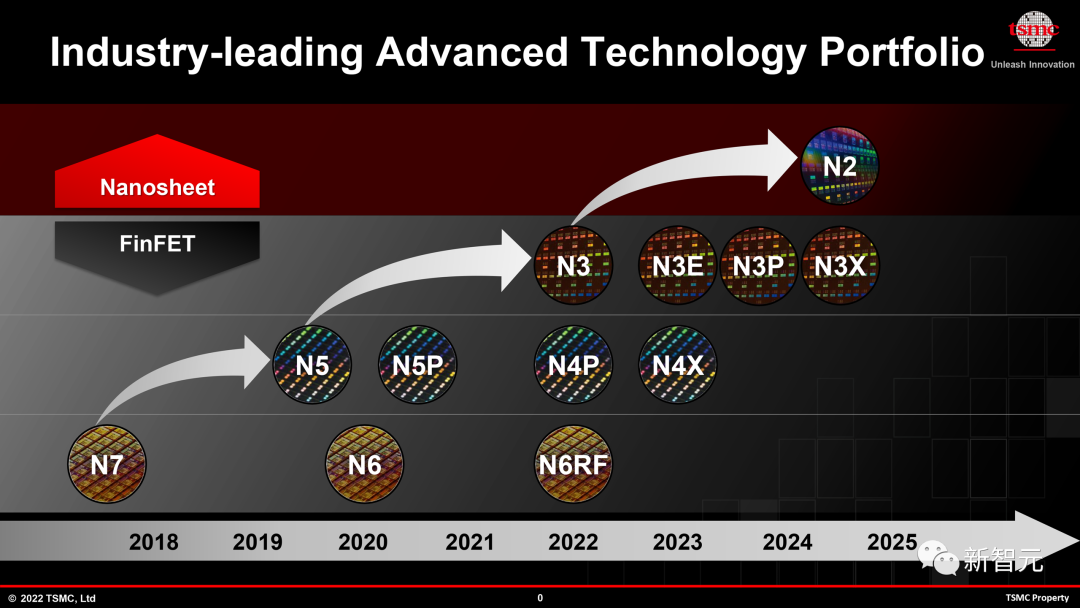
もちろん、来年はNVIDIAだけがTSMC N3テクノロジーを採用するわけではありません
AMD、Intel、MediaTek、Qualcommはすべて、2024年から2025年にかけてTSMCのN3テクノロジーを採用する予定です 3nmレベルのノードの1つ。
実際、MediaTek は TSMC の最初の N3E 設計を採用しました。
現在、TSMC の N3B (第一世代 N3) テクノロジーを使用して最新の A17 Pro チップを製造しているのは Apple だけです。
さらに、M3、M3 Pro、M3 Max、M3 Ultraなどの他のチップもN3Bテクノロジーを使用すると予想されています。
以上がH100 を粉砕、Nvidia の次世代 GPU が明らかに!最初の 3nm マルチチップ モジュール設計、2024 年に発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7492
7492
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースを作成するのは簡単ではありません。根本的なメカニズムを理解する必要があります。 1.データベースとOracle DBMSの概念を理解する必要があります。 2。SID、CDB(コンテナデータベース)、PDB(プラグ可能なデータベース)などのコアコンセプトをマスターします。 3。SQL*Plusを使用してCDBを作成し、PDBを作成するには、サイズ、データファイルの数、パスなどのパラメーターを指定する必要があります。 4.高度なアプリケーションは、文字セット、メモリ、その他のパラメーターを調整し、パフォーマンスチューニングを実行する必要があります。 5.ディスクスペース、アクセス許可、パラメーター設定に注意し、データベースのパフォーマンスを継続的に監視および最適化します。 それを巧みに習得することによってのみ、継続的な練習が必要であることは、Oracleデータベースの作成と管理を本当に理解できます。
 Oracleデータベースの作成方法Oracleデータベースの作成方法
Apr 11, 2025 pm 02:36 PM
Oracleデータベースの作成方法Oracleデータベースの作成方法
Apr 11, 2025 pm 02:36 PM
Oracleデータベースを作成するには、一般的な方法はDBCAグラフィカルツールを使用することです。手順は次のとおりです。1。DBCAツールを使用してDBNAMEを設定してデータベース名を指定します。 2. SyspasswordとSystemPassWordを強力なパスワードに設定します。 3.文字セットとNationalCharactersetをAL32UTF8に設定します。 4.実際のニーズに応じて調整するようにMemorySizeとTableSpacesizeを設定します。 5. logfileパスを指定します。 高度な方法は、SQLコマンドを使用して手動で作成されますが、より複雑でエラーが発生しやすいです。 パスワードの強度、キャラクターセットの選択、表空間サイズ、メモリに注意してください
 Oracleデータベースステートメントの作成方法
Apr 11, 2025 pm 02:42 PM
Oracleデータベースステートメントの作成方法
Apr 11, 2025 pm 02:42 PM
Oracle SQLステートメントのコアは、さまざまな条項の柔軟なアプリケーションと同様に、選択、挿入、更新、削除です。インデックスの最適化など、ステートメントの背後にある実行メカニズムを理解することが重要です。高度な使用法には、サブクエリ、接続クエリ、分析関数、およびPL/SQLが含まれます。一般的なエラーには、構文エラー、パフォーマンスの問題、およびデータの一貫性の問題が含まれます。パフォーマンス最適化のベストプラクティスには、適切なインデックスの使用、Select *の回避、条項の最適化、およびバインドされた変数の使用が含まれます。 Oracle SQLの習得には、コードライティング、デバッグ、思考、基礎となるメカニズムの理解など、練習が必要です。
 mysqlデータテーブルフィールド操作ガイドの追加、変更、削除方法ガイド
Apr 11, 2025 pm 05:42 PM
mysqlデータテーブルフィールド操作ガイドの追加、変更、削除方法ガイド
Apr 11, 2025 pm 05:42 PM
MySQLのフィールド操作ガイド:フィールドを追加、変更、削除します。フィールドを追加:table table_nameを変更するcolumn_name data_type [not null] [default default_value] [プライマリキー] [auto_increment]フィールドの変更:column_name data_typeを変更するcolumn_name data_type [not null] [default default_value] [プライマリキー]
 Oracleデータベーステーブルの整合性の制約は何ですか?
Apr 11, 2025 pm 03:42 PM
Oracleデータベーステーブルの整合性の制約は何ですか?
Apr 11, 2025 pm 03:42 PM
Oracleデータベースの整合性の制約により、以下を含むデータの精度を確保できます。NULL:NULL値は禁止されています。一意:単一のヌル値を許可する一意性を保証します。一次キー:一次キーの制約、一意を強化し、ヌル値を禁止します。外部キー:テーブル間の関係を維持する、外部キーはプライマリテーブルのプライマリキーを参照します。チェック:条件に応じて列の値を制限します。
 MySQLデータベースのネストされたクエリインスタンスの詳細な説明
Apr 11, 2025 pm 05:48 PM
MySQLデータベースのネストされたクエリインスタンスの詳細な説明
Apr 11, 2025 pm 05:48 PM
ネストされたクエリは、1つのクエリに別のクエリを含める方法です。これらは主に、複雑な条件を満たし、複数のテーブルを関連付け、要約値または統計情報を計算するデータを取得するために使用されます。例には、平均賃金を超える従業員を見つけること、特定のカテゴリの注文を見つけること、各製品の総注文量の計算が含まれます。ネストされたクエリを書くときは、サブ征服を書き、結果を外側のクエリ(エイリアスまたは条項として参照)に書き込み、クエリパフォーマンスを最適化する必要があります(インデックスを使用)。
 オラクルは何をしますか
Apr 11, 2025 pm 06:06 PM
オラクルは何をしますか
Apr 11, 2025 pm 06:06 PM
Oracleは、世界最大のデータベース管理システム(DBMS)ソフトウェア会社です。その主な製品には、次の機能が含まれます。リレーショナルデータベース管理システム(Oracle Database)開発ツール(Oracle Apex、Oracle Visual Builder)ミドルウェア(Oracle Weblogic Server、Oracle SOA Suite)Cloud Service(Oracle Cloud Infrastructure)Cloud ServiceおよびBusiness Intelligence(Oracle Analytics Cloud、Oracle Essbase)Blockchain(Oracle Blockchain Pla
 Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
この記事では、Debian SystemsでApacheのログ形式をカスタマイズする方法について説明します。次の手順では、構成プロセスをガイドします。ステップ1:Apache構成ファイルにアクセスするDebianシステムのメインApache構成ファイルは、/etc/apache2/apache2.confまたは/etc/apache2/httpd.confにあります。次のコマンドを使用してルートアクセス許可を使用して構成ファイルを開きます。sudonano/etc/apache2/apache2.confまたはsudonano/etc/apache2/httpd.confステップ2:検索または検索または
