

マルチモーダル バージョン Llama2 がオンラインになり、Meta が AnyMAL をリリース

複数のベンチマーク テストで業界最高のゼロショット パフォーマンスを更新しました。
さまざまなモーダル入力コンテンツ (テキスト、画像、ビデオ、オーディオ、IMU モーション センサー データ) を理解し、テキスト応答を生成できる統合モデル。このテクノロジーは、Llama 2 に基づいています。メタ。
昨日、マルチモーダル大規模モデル AnyMAL に関する研究が AI 研究コミュニティの注目を集めました。
大規模言語モデル (LLM) は、その巨大なサイズと複雑さで知られており、人間の言語を理解して表現する機械の能力を大幅に強化します。 LLM の進歩により、画像エンコーダと LLM の推論機能を組み合わせて、画像エンコーダと LLM の間のギャップを埋め、視覚言語の分野で大幅な進歩が可能になりました。これまでのマルチモーダル LLM 研究は、テキストと画像モデルなど、テキストと別のモダリティを組み合わせるモデル、またはオープンソースではない独自の言語モデルに焦点を当てていました。
マルチモーダル機能を実現し、LLM にさまざまなモダリティを組み込むためのより良い方法があれば、それは私たちに異なるエクスペリエンスをもたらすでしょうか?
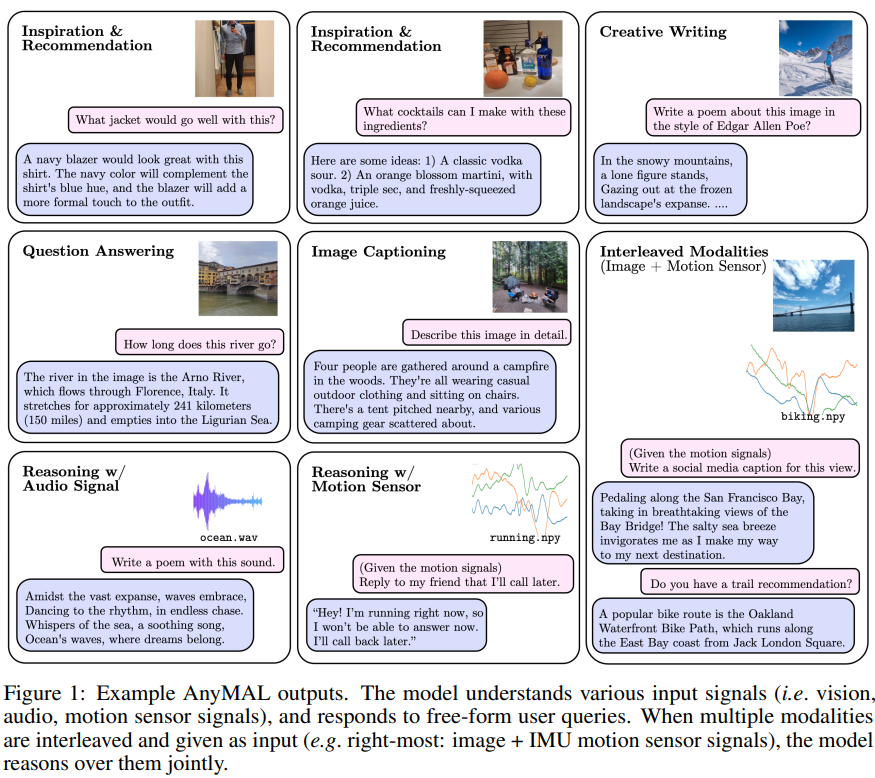
##Q 出力例
この問題について、META の研究者は最近 Anymal (Any-モダリティ拡張言語モデル)。これは、画像、ビデオ、オーディオ、IMU モーション センサー データなど、さまざまなモダリティからのデータを LLM のテキスト埋め込みスペースに変換するようにトレーニングされたマルチモーダル エンコーダーのコレクションです

- #提案マルチモーダル LLM を構築するための効率的でスケーラブルなソリューションです。この記事では、複数のモダリティ (例: 2 億の画像、220 万の音声セグメント、50 万の IMU 時系列、2,800 万のビデオ セグメント) を含む大規模なデータセットで事前トレーニングされた投影レイヤーを提供します。すべて同じ大規模モデル (LLaMA-2- 70B-chat) を使用して、インターリーブされたマルチモーダル コンテキスト キューを有効にします。
- この研究では、3 つのモダリティ (画像、ビデオ、オーディオ) にわたるマルチモーダル命令セットを使用してモデルをさらに微調整し、単純な質問応答 (QA) を超えたさまざまな分野をカバーしました。タスク。このデータセットには手動で収集された高品質の指示データが含まれているため、この研究ではそれを複雑なマルチモーダル推論タスクのベンチマークとして使用します
- この論文の最良のモデルは、さまざまなタスクを自動的に実行し、既存の文献のモデルと比較して、VQAv2 の相対精度は 7.0% 向上し、ゼロエラー COCO 画像字幕の CIDEr は 8.4% 向上しました。AudioCaps では CIDEr が 14.5% 向上し、新しい SOTA が作成されました。
ペアになったマルチモーダル データ (特定のモーダル信号とテキストを含む) を使用して、図 2 に示すように、この研究では、マルチモーダルな理解機能を達成するために LLM を事前トレーニングしました。具体的には、入力信号を特定の LLM のテキスト トークン埋め込み空間に投影する各モダリティの軽量アダプターをトレーニングします。このようにして、LLM のテキスト タグ埋め込み空間は、タグがテキストまたはその他のモダリティを表現できる共同タグ埋め込み空間になります。クリーンなサブセットは CAT メソッドを使用してフィルタリングされ、検出可能な顔をぼかしました。オーディオ アライメントの研究には、AudioSet (2.1M)、AudioCaps (46K)、および CLOTHO (5K) データ セットが使用されました。さらに、IMU とテキスト配置に Ego4D データセットも使用しました (528K)
大規模なデータセットの場合、事前トレーニングを 70B パラメーター モデルにスケールアップするには多くのリソースが必要となり、多くの場合 FSDP ラッパーの使用が必要になります。 on multiple 複数の GPU でモデルをスライスします。トレーニングを効果的にスケールするために、マルチモーダル設定で量子化戦略 (4 ビットおよび 8 ビット) を実装します。この設定では、モデルの LLM 部分がフリーズされ、モーダル トークナイザーのみがトレーニング可能になります。このアプローチにより、メモリ要件が 1 桁減少します。したがって、70B AnyMAL は、バッチ サイズ 4 の単一の 80GB VRAM GPU でトレーニングを完了できます。 FSDP と比較すると、この記事で提案する量子化方法は GPU リソースの半分しか使用しませんが、同じスループットを実現します マルチモーダル命令データ セットを微調整に使用するということは、マルチモーダル命令データ セットを微調整に使用することを意味します。さらに、さまざまな入力モダリティの命令に従うモデルの能力を向上させるために、研究では追加の微調整にマルチモーダル命令チューニング (MM-IT) データセットを使用しました。具体的には、応答ターゲットがテキスト命令とモーダル入力の両方に基づくように、入力を [] として連結します。研究は、(1) LLM パラメータを変更せずに投影層をトレーニングする、または (2) 低レベルの適応 (Low-Rank Adaptation) を使用して LM の動作をさらに調整する 2 つの状況について行われます。この研究では、手動で収集された命令調整されたデータセットと合成データの両方が使用されます。 画像タイトル生成は、画像に対応するタイトルを自動的に生成するために使用される人工知能テクノロジーです。このテクノロジーは、コンピューター ビジョンと自然言語処理手法を組み合わせて、画像の内容と特性を分析し、意味論と構文を理解することで、画像に関連する説明的なキャプションを生成します。画像キャプションの生成は、画像検索、画像注釈、画像検索など、多くの分野で幅広い用途があります。タイトルを自動生成することで、画像のわかりやすさや検索エンジンの精度が向上し、より良い画像検索や閲覧体験をユーザーに提供することができます。タスク (MM-IT-Cap)。見てわかるように、AnyMAL バリアントは両方のデータセットでベースラインよりも大幅に優れたパフォーマンスを示しています。特に、AnyMAL-13B バリアントと AnyMAL-70B バリアントの間にパフォーマンスに大きな差はありません。この結果は、画像キャプション生成の基礎となる LLM 機能が、画像に対応するキャプションを自動的に生成するために使用される人工知能技術であることを示しています。このテクノロジーは、コンピューター ビジョンと自然言語処理手法を組み合わせて、画像の内容と特性を分析し、意味論と構文を理解することで、画像に関連する説明的なキャプションを生成します。画像キャプションの生成は、画像検索、画像注釈、画像検索など、多くの分野で幅広い用途があります。キャプションの生成を自動化することで、画像の理解しやすさと検索エンジンの精度が向上し、ユーザーにより良い画像検索と閲覧エクスペリエンスが提供されます。このタスクの影響はそれほど大きくありませんが、データ サイズと登録方法に大きく依存します。
必要な書き直しは次のとおりです: マルチモーダル推論タスクに対する人間による評価
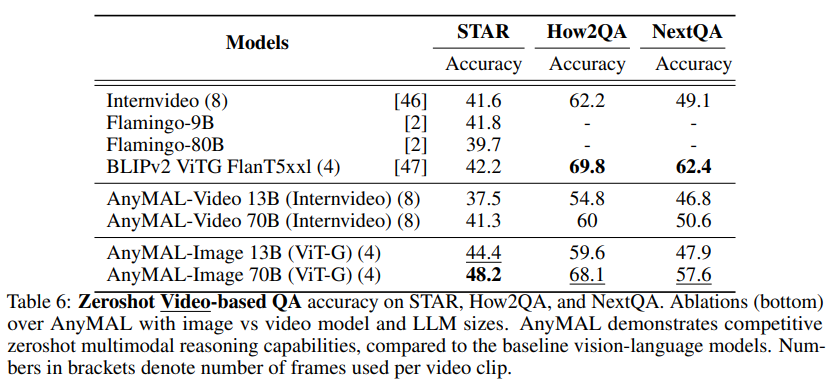
#VQA ベンチマーク ビデオ QA ベンチマーク
表 6 に示すように、この研究では 3 つの困難なビデオ QA ベンチマークでモデルを評価しました。 #オーディオ字幕の再生成
興味深いことに、AnyMAL 論文提出の方法、種類、タイミングに基づいて、Meta は新しく発売された複合現実/メタバース ヘッドセットを通じてマルチモーダル データを収集することを計画しているようです。これらの研究結果は、Meta の Metaverse 製品ラインに統合されるか、すぐに消費者向けアプリケーションで使用される可能性があります。 詳細については、元の記事をお読みください。 
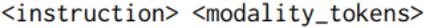 実験と結果
実験と結果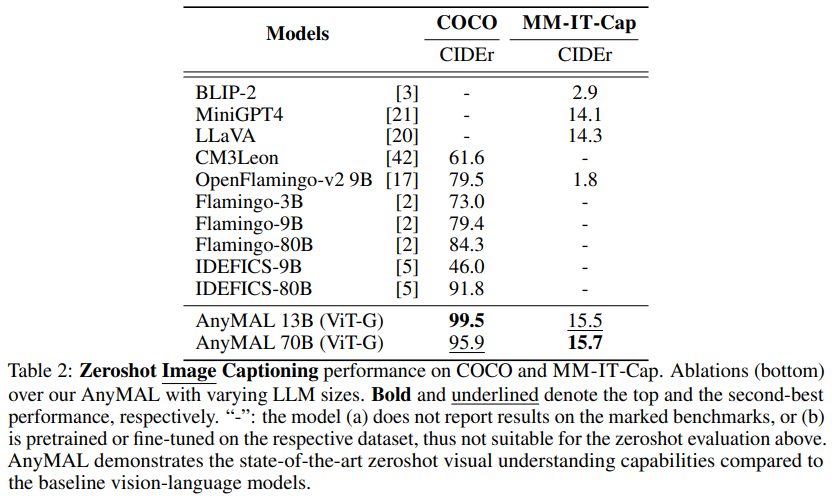 図 3 は、ベースライン ( LLaVA: 勝率 34.4%、MiniGPT4: 勝率 27.0%) と比較すると、AnyMAL は強力なパフォーマンスを示し、実際の手動でラベル付けされたサンプル (勝率 41.1%) との差が小さくなっています。特に、完全な命令セットで微調整されたモデルは最高の優先順位の勝率を示し、人間による注釈付きの応答に匹敵する視覚的な理解と推論能力を示しました。 BLIP-2 と InstructBLIP は、公開 VQA ベンチマークでは良好なパフォーマンスを示しますが (表 4 を参照)、これらのオープン クエリではパフォーマンスが低いことにも注目してください (優先勝率はそれぞれ 4.1% と 16.7%)。
図 3 は、ベースライン ( LLaVA: 勝率 34.4%、MiniGPT4: 勝率 27.0%) と比較すると、AnyMAL は強力なパフォーマンスを示し、実際の手動でラベル付けされたサンプル (勝率 41.1%) との差が小さくなっています。特に、完全な命令セットで微調整されたモデルは最高の優先順位の勝率を示し、人間による注釈付きの応答に匹敵する視覚的な理解と推論能力を示しました。 BLIP-2 と InstructBLIP は、公開 VQA ベンチマークでは良好なパフォーマンスを示しますが (表 4 を参照)、これらのオープン クエリではパフォーマンスが低いことにも注目してください (優先勝率はそれぞれ 4.1% と 16.7%)。  表 4 に、Hateful Meme データセット VQAv2 のパフォーマンスを示します。 、TextVQA、ScienceQA、VizWiz、OKVQA を比較し、文献で報告されているそれぞれのベンチマークのゼロショット結果と比較しました。私たちの研究は、推論時のオープン クエリでのモデルのパフォーマンスを最も正確に推定するためのゼロショット評価に焦点を当てています。
表 4 に、Hateful Meme データセット VQAv2 のパフォーマンスを示します。 、TextVQA、ScienceQA、VizWiz、OKVQA を比較し、文献で報告されているそれぞれのベンチマークのゼロショット結果と比較しました。私たちの研究は、推論時のオープン クエリでのモデルのパフォーマンスを最も正確に推定するためのゼロショット評価に焦点を当てています。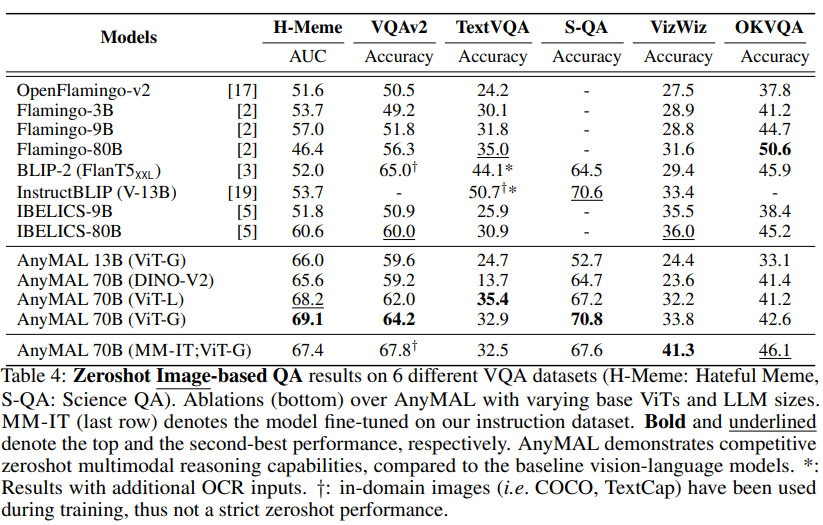
以上がマルチモーダル バージョン Llama2 がオンラインになり、Meta が AnyMAL をリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
これも Tusheng のビデオですが、PaintsUndo は別の道を歩んでいます。 ControlNet 作者 LvminZhang が再び生き始めました!今回は絵画の分野を目指します。新しいプロジェクト PaintsUndo は、開始されて間もなく 1.4kstar を獲得しました (まだ異常なほど上昇しています)。プロジェクトアドレス: https://github.com/lllyasviel/Paints-UNDO このプロジェクトを通じて、ユーザーが静止画像を入力すると、PaintsUndo が線画から完成品までのペイントプロセス全体のビデオを自動的に生成するのに役立ちます。 。描画プロセス中の線の変化は驚くべきもので、最終的なビデオ結果は元の画像と非常によく似ています。完成した描画を見てみましょう。
 新しい手頃な価格の Meta Quest 3S VR ヘッドセットが FCC に登場、発売が近いことを示唆
Sep 04, 2024 am 06:51 AM
新しい手頃な価格の Meta Quest 3S VR ヘッドセットが FCC に登場、発売が近いことを示唆
Sep 04, 2024 am 06:51 AM
Meta Connect 2024イベントは9月25日から26日に予定されており、このイベントで同社は新しい手頃な価格の仮想現実ヘッドセットを発表すると予想されている。 Meta Quest 3S であると噂されている VR ヘッドセットが FCC のリストに掲載されたようです。この提案
 オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com この論文の著者は全員、イリノイ大学アーバナ シャンペーン校 (UIUC) の Zhang Lingming 教師のチームのメンバーです。博士課程4年、研究者
 GPT4o レベルを超える初のオープンソース モデル! Llama 3.1 がリーク: 4,050 億のパラメータ、ダウンロード リンク、モデル カードが利用可能
Jul 23, 2024 pm 08:51 PM
GPT4o レベルを超える初のオープンソース モデル! Llama 3.1 がリーク: 4,050 億のパラメータ、ダウンロード リンク、モデル カードが利用可能
Jul 23, 2024 pm 08:51 PM
GPUを準備しましょう!ついにLlama3.1が登場しましたが、ソースはMeta公式ではありません。今日、新しい Llama 大型モデルのリーク ニュースが Reddit で話題になり、基本モデルに加えて、8B、70B、最大パラメータ 405B のベンチマーク結果も含まれています。以下の図は、Llama3.1 の各バージョンと OpenAIGPT-4o および Llama38B/70B の比較結果を示しています。 70B バージョンでも複数のベンチマークで GPT-4o を上回っていることがわかります。画像ソース: https://x.com/mattshumer_/status/1815444612414087294 明らかに、8B と 70 のバージョン 3.1
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
最近、2000年代の7大問題の一つとして知られるリーマン予想が新たなブレークスルーを達成した。リーマン予想は、数学における非常に重要な未解決の問題であり、素数の分布の正確な性質に関連しています (素数とは、1 とそれ自身でのみ割り切れる数であり、整数論において基本的な役割を果たします)。今日の数学文献には、リーマン予想 (またはその一般化された形式) の確立に基づいた 1,000 を超える数学的命題があります。言い換えれば、リーマン予想とその一般化された形式が証明されれば、これらの 1,000 を超える命題が定理として確立され、数学の分野に重大な影響を与えることになります。これらの命題の一部も有効性を失います。 MIT数学教授ラリー・ガスとオックスフォード大学から新たな進歩がもたらされる
 公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
LLM に因果連鎖を示すと、LLM は公理を学習します。 AI はすでに数学者や科学者の研究を支援しています。たとえば、有名な数学者のテレンス タオは、GPT などの AI ツールを活用した研究や探索の経験を繰り返し共有しています。 AI がこれらの分野で競争するには、強力で信頼性の高い因果推論能力が不可欠です。この記事で紹介する研究では、小さなグラフでの因果的推移性公理の実証でトレーニングされた Transformer モデルが、大きなグラフでの推移性公理に一般化できることがわかりました。言い換えれば、Transformer が単純な因果推論の実行を学習すると、より複雑な因果推論に使用できる可能性があります。チームが提案した公理的トレーニング フレームワークは、デモンストレーションのみで受動的データに基づいて因果推論を学習するための新しいパラダイムです。
 arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
乾杯!紙面でのディスカッションが言葉だけになると、どんな感じになるでしょうか?最近、スタンフォード大学の学生が、arXiv 論文のオープン ディスカッション フォーラムである alphaXiv を作成しました。このフォーラムでは、arXiv 論文に直接質問やコメントを投稿できます。 Web サイトのリンク: https://alphaxiv.org/ 実際、URL の arXiv を alphaXiv に変更するだけで、alphaXiv フォーラムの対応する論文を直接開くことができます。この Web サイトにアクセスする必要はありません。その中の段落を正確に見つけることができます。論文、文: 右側のディスカッション エリアでは、ユーザーは論文のアイデアや詳細について著者に尋ねる質問を投稿できます。たとえば、次のような論文の内容についてコメントすることもできます。
