

Google: 不等周波数サンプリングによる時系列表現を学習する新しい方法

時系列問題には、同じ頻度でサンプリングされないタイプの時系列があります。つまり、各グループ内の 2 つの隣接する観測間の時間間隔が異なります。時系列表現の学習は、等周波数サンプリング時系列では多く研究されていますが、この不規則サンプリング時系列では研究が少なく、このタイプの時系列のモデル化方法は等周波数サンプリング時系列とは異なります。モデリング手法はまったく異なります
今日紹介する記事では、NLP および下流タスクでの関連経験を活用して、不規則サンプリング時系列問題における表現学習の応用手法を検討しています。比較的重要な結果が得られています。
 写真
写真
- 論文タイトル: PAITS: 不規則にサンプリングされた時系列の事前学習と拡張
- ダウンロード アドレス: https: //arxiv.org/pdf/2308.13703v1.pdf
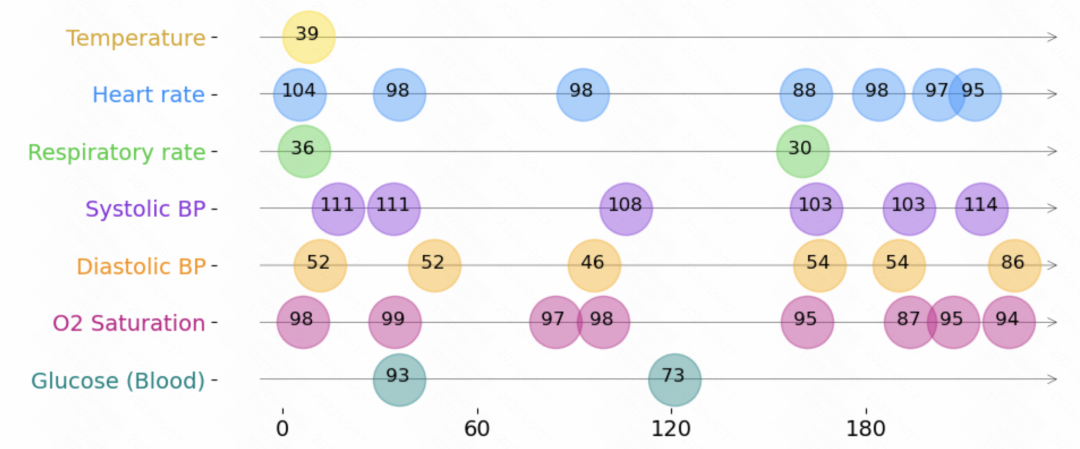
1. 不規則な時系列データの定義
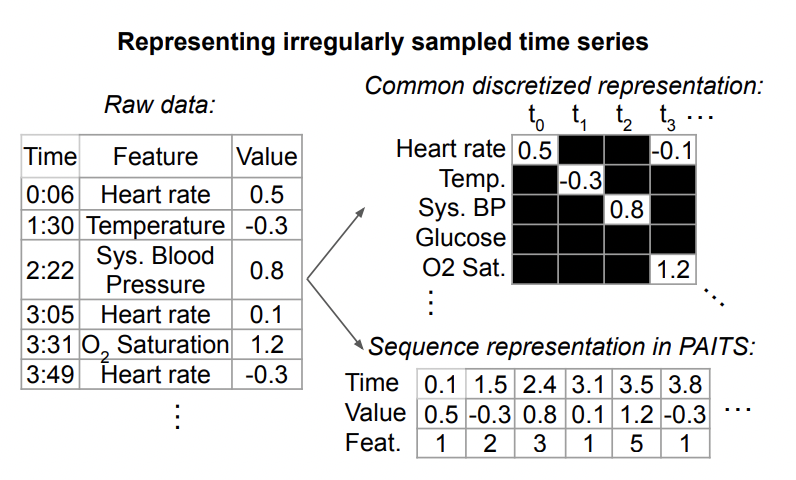
以下は、不規則な時系列データの表現です。 。各時系列は一連のトリプルで構成されており、各トリプルには時間、値、および特徴という 3 つのフィールドが含まれており、それぞれ時系列の各要素のサンプリング時間、値、その他の特徴を表します。これらのトリプルに加えて、各シーケンスには、時間の経過とともに変化しない他の静的特徴や、各時系列のラベルも含まれています。 # 一般に、この不規則時系列モデリング手法に共通する構造は、上記のトリプルデータを別々に埋め込み、それらをつなぎ合わせて、Transformer などのモデルに入力することにより、各瞬間の情報と各瞬間の時刻を解析します。表現は統合され、後続のタスクの予測を行うためにモデルに入力されます。
 図
図
この記事のタスクでは、使用されるデータにはラベル付きのデータだけでなく、ラベルのないデータも含まれます。教師なしの事前トレーニングを実行します。
2. メソッドの概要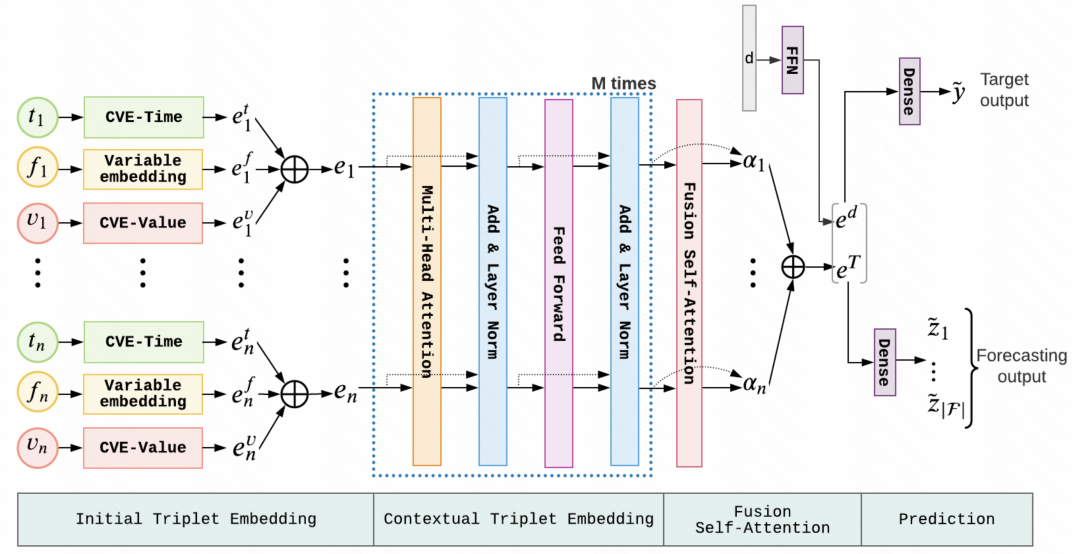 この記事の事前トレーニング メソッドは、自然言語処理の分野での経験に言及しており、主に 2 つの側面をカバーしています。事前トレーニング タスク: 不規則な時系列を処理するには、モデルが教師なしデータから効果的な表現を学習できるように、適切な事前トレーニング タスクを設計する必要があります。この記事では主に、予測と再構成に基づく 2 つの事前トレーニング タスクを紹介します。 .
この記事の事前トレーニング メソッドは、自然言語処理の分野での経験に言及しており、主に 2 つの側面をカバーしています。事前トレーニング タスク: 不規則な時系列を処理するには、モデルが教師なしデータから効果的な表現を学習できるように、適切な事前トレーニング タスクを設計する必要があります。この記事では主に、予測と再構成に基づく 2 つの事前トレーニング タスクを紹介します。 .
4. データ強化手法の設計
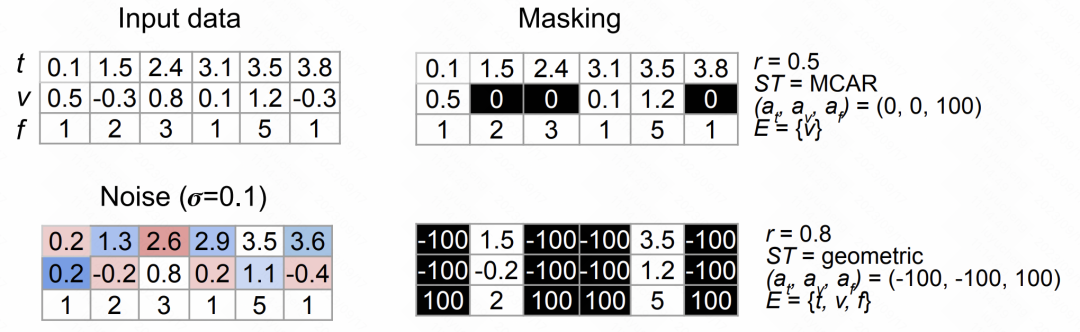
この記事では、2 つのデータ強化手法を提案します。 1 つ目の方法は、データにランダムな干渉を導入してノイズを追加し、データの多様性を高める方法です。 2 番目の方法はランダム マスキングです。これは、マスクするデータの部分をランダムに選択することで、モデルがより堅牢な特徴を学習することを促進します。これらのデータ拡張方法は、モデルのパフォーマンスと一般化能力を向上させるのに役立ちます。
元のシーケンスの各値または時点について、ガウス ノイズを追加することでノイズを増やすことができます。具体的な計算方法は以下の通りです。
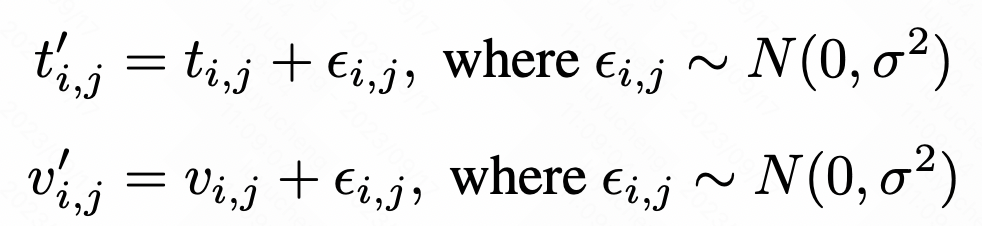 図
図
ランダム マスク手法は、ランダム マスキングと置換のために時間、特徴、値、その他の要素をランダムに選択し、順次強化していきます。
次の図は、上記の 2 種類のデータ拡張方法の効果を示しています。
 図
図
#さらに、この記事では、異なる時系列データに対して、学習方法などの組み合わせを変え、その組み合わせから最適な事前学習方法を探索します。
5. 実験結果
この記事では、これらのデータセットに対するさまざまな事前トレーニング方法の効果を比較するために、複数のデータセットに対して実験が行われました。この記事で提案されている事前トレーニング方法により、ほとんどのデータ セットでパフォーマンスが大幅に向上したことがわかります
# ###### ###写真### #################################### #
以上がGoogle: 不等周波数サンプリングによる時系列表現を学習する新しい方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7858
7858
 15
1649
14
1403
52
1300
25
1242
29
15
1649
14
1403
52
1300
25
1242
29

 セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
ログインステップやパスワード回復プロセスなど、セサミオープンエクスチェンジWebバージョンのログイン操作の詳細な紹介も、ログイン障害、ページを開くことができず、プラットフォームにスムーズにログインするのに役立つ検証コードを受信できません。
 セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
この記事では、SESAME Open Exchange(gate.io)Webバージョンの登録プロセスとGate Tradingアプリを詳細に紹介します。 Web登録であろうとアプリの登録であろうと、公式Webサイトまたはアプリストアにアクセスして、本物のアプリをダウンロードし、ユーザー名、パスワード、電子メール、携帯電話番号、その他の情報を入力し、電子メールまたは携帯電話の確認を完了する必要があります。
 セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
アプリをダウンロードしてアカウントの安全を確保するために、正式なチャネルを選択することが重要です。
 Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
この記事では、Binance、Okx、Gate.io、Bitflyer、Kucoin、Bybit、Coinbase Pro、Kraken、Bydfi、Xbit分散化された交換など、注意を払う価値のある上位10の暗号通貨取引プラットフォームを推奨しています。これらのプラットフォームには、トランザクションの数量、トランザクションの種類、セキュリティ、コンプライアンス、特別な機能の点で独自の利点があります。適切なプラットフォームを選択するには、あなた自身の取引体験、リスク許容度、投資の好みに基づいて包括的な検討が必要です。 この記事があなたがあなた自身に最適なスーツを見つけるのに役立つことを願っています
 OUYI OKEXアカウントを登録、使用、キャンセルする方法に関するチュートリアル
Mar 31, 2025 pm 04:21 PM
OUYI OKEXアカウントを登録、使用、キャンセルする方法に関するチュートリアル
Mar 31, 2025 pm 04:21 PM
この記事では、OUYI OKEXアカウントの登録、使用、キャンセル手順を詳細に紹介します。登録するには、アプリをダウンロードし、携帯電話番号または電子メールアドレスを入力して登録する必要があります。使用法は、ログイン、リチャージ、引き出し、取引、セキュリティ設定などの操作手順をカバーします。アカウントをキャンセルするには、OUYI Okexカスタマーサービスに連絡し、必要な情報を提供し、処理を待つ必要があり、最後にアカウントキャンセルの確認を取得する必要があります。 この記事を通じて、ユーザーはOUYI OKEXアカウントの完全なライフサイクル管理を簡単に習得し、デジタルアセットトランザクションを安全かつ便利に実施できます。
 2025年のBitgetの最新のダウンロードアドレス:公式アプリを取得する手順
Feb 25, 2025 pm 02:54 PM
2025年のBitgetの最新のダウンロードアドレス:公式アプリを取得する手順
Feb 25, 2025 pm 02:54 PM
このガイドは、AndroidおよびiOSシステムに適した公式Bitget Exchangeアプリの詳細なダウンロードとインストール手順を提供します。このガイドは、公式ウェブサイト、App Store、Google Playなど、複数の権威ある情報源からの情報を統合し、ダウンロードおよびアカウント管理中の考慮事項を強調しています。ユーザーは、App Store、公式WebサイトAPKダウンロード、公式Webサイトジャンプ、完全な登録、ID検証、セキュリティ設定など、公式チャネルからアプリをダウンロードできます。さらに、ガイドはよくある質問や考慮事項をカバーします。
 Bitget公式Webサイトで最新のアプリを登録およびダウンロードする方法
Mar 05, 2025 am 07:54 AM
Bitget公式Webサイトで最新のアプリを登録およびダウンロードする方法
Mar 05, 2025 am 07:54 AM
このガイドは、AndroidおよびiOSシステムに適した公式Bitget Exchangeアプリの詳細なダウンロードとインストール手順を提供します。このガイドは、公式ウェブサイト、App Store、Google Playなど、複数の権威ある情報源からの情報を統合し、ダウンロードおよびアカウント管理中の考慮事項を強調しています。ユーザーは、App Store、公式WebサイトAPKダウンロード、公式Webサイトジャンプ、完全な登録、ID検証、セキュリティ設定など、公式チャネルからアプリをダウンロードできます。さらに、ガイドはよくある質問や考慮事項をカバーします。
 なぜビテンサーはAIトラックの「ビットコイン」と言われているのですか?
Mar 04, 2025 pm 04:06 PM
なぜビテンサーはAIトラックの「ビットコイン」と言われているのですか?
Mar 04, 2025 pm 04:06 PM
元のタイトル:Bittensor = Aibitcoin:S4MMYETH、分散型AI研究元の翻訳:Zhouzhou、BlockBeats編集者注:この記事では、Bockchain Technologyを通じて中央集権的なAI企業の独占を破り、オープンおよび共同AI Ecosemsytemを促進することを望んでいます。 Bittensorは、さまざまなAIソリューションの出現を可能にし、Tao Tokensを通じてイノベーションを刺激するサブネットモデルを採用しています。 AI市場は成熟していますが、両節は競争リスクに直面し、他のオープンソースの対象となる場合があります
