

はるか先! BEVHeight++: 道路脇の視覚的な 3D ターゲット検出のための新しいソリューション!

地面の高さに回帰して距離に依存しない定式化を実現することで、カメラ認識のみの手法の最適化プロセスを簡素化します。路側カメラの 3D 検出ベンチマークでは、この方法はこれまでのすべての視覚中心の方法を大幅に上回っています。 BEVDepth の 1.9% NDS および 1.1% mAP に比べて大幅な改善が得られます。 nuScenes テスト セットでは、この方法が大幅に進歩し、NDS と mAP がそれぞれ 2.8% と 1.7% 増加しました。
タイトル: BEVHeight: 堅牢なビジョン中心の 3D オブジェクト検出に向けて
論文リンク: https://arxiv.org/pdf/2309.16179.pdf
著者単位: 清華大学、中山大学、蔡宜網網、北京大学
国内初の自動運転コミュニティから: ついに 20 の技術方向学習ルートの構築を完了 (BEV センシング/3D 検出/マルチセンサー)融合/SLAM と計画など)
最近の自動運転システムは車両センサーの認識方法の開発に焦点を当てていますが、路側のスマート カメラを使用して認識機能を超えて拡張する方法は見落とされがちです。視覚範囲、代替方法。著者らは、最先端の視覚中心の BEV 検出方法が路側カメラではあまり機能しないことを発見しました。これは、これらの方法が主にカメラ中心付近の深度を回復することに焦点を当てているためで、そこでは車と地面の間の深度の差は距離とともに急速に縮小します。この記事では、著者はこの問題を解決するために、BEVHeight と呼ばれるシンプルかつ効果的な方法を提案します。基本的に、著者らは地面の高さに回帰して距離に依存しない定式化を実現し、それによってカメラ認識のみの手法の最適化プロセスを簡素化します。高さと奥行きのエンコード技術を組み合わせることで、2D 空間から BEV 空間へのより正確かつ堅牢な投影が実現します。この方法は、路側カメラの一般的な 3D 検出ベンチマークにおいて、これまでのすべての視覚中心の方法よりも大幅に優れています。自車シーンの場合、BEVHeight は深度のみの方法よりも優れたパフォーマンスを示します
具体的には、nuScenes 検証セットで評価すると、BEVDepth よりも 1.9% 優れた NDS と 1.1% 優れた mAP が得られます。さらに、nuScenes テスト セットでは、NDS と mAP がそれぞれ 2.8% と 1.7% 増加するなど、この方法は大幅な進歩を遂げました。
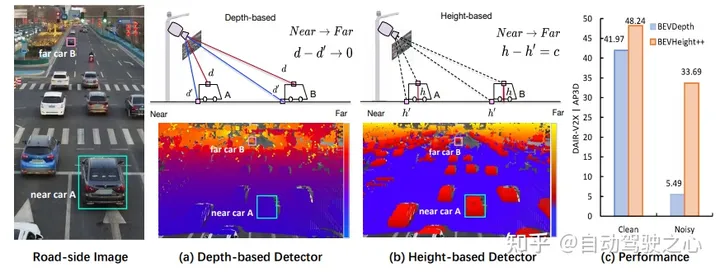
図 1: (a) 単眼画像から 3D バウンディング ボックスを生成するには、最先端の方法ではまずピクセルごとの深さを明示的または暗黙的に予測して、前景オブジェクトと背景の 3D 位置。しかし、画像上にピクセルごとの深度をプロットすると、車がカメラから遠ざかるにつれて、屋根上の点と周囲の地面の間の差が急速に縮小し、特に遠くのオブジェクトの場合、最適化が準最適化されていることがわかりました。 。 (b) 代わりに、地面までのピクセルごとの高さをプロットし、この差は距離に関係なく、ネットワークが物体を検出するのに視覚的により適していることを観察します。ただし、高さのみを予測して 3D 位置を直接回帰することはできません。 (c) この目的のために、この問題を解決するための新しいフレームワーク BEVHeight を提案します。経験的な結果は、私たちの方法が最良の方法よりもクリーンな設定で 5.49%、ノイズの多い設定で 28.2% 優れていることを示しています。
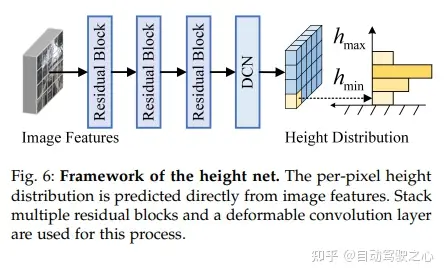
ネットワーク構造
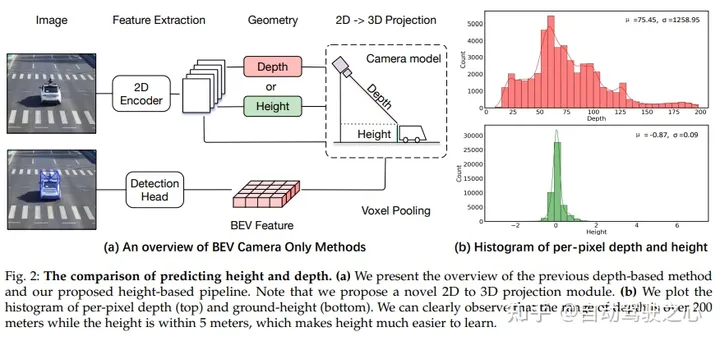
予測の高さと深さの比較。 (a) 以前の深さベースの方法と提案された高さベースのパイプラインの概要。この文書では、新しい 2D から 3D への投影モジュールを提案していることに注意してください。 (b) ピクセルごとの深さ (上) と地面の高さ (下) のヒストグラムをプロットすると、深さの範囲が 200 メートルを超えているのに対し、高さの範囲は 5 メートル以内であることがはっきりと観察され、高さが学習しやすくなります。
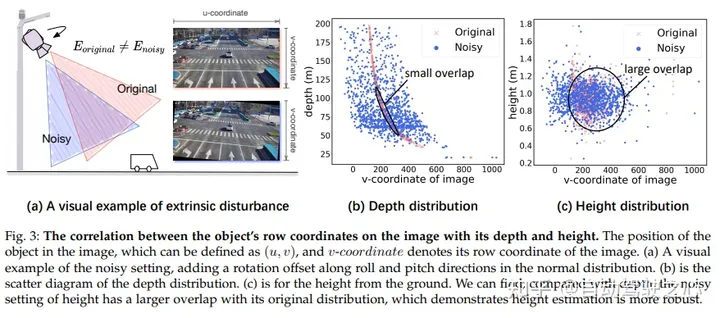
画像では、オブジェクトの行座標とその深さと高さとの間に相関関係があります。画像内のターゲットの位置は (u, v) によって定義できます。ここで、v は画像の行座標を表します。 (a) では、正規分布にロール方向とピッチ方向の回転オフセットを追加することでノイズを導入する視覚的な例を示しています。 (b) に深さ分布の散布図を示します。 (c) には地上からの高さを示します。高さのノイズ設定は、深さと比較して元の分布との重複が大きいことが観察でき、高さの推定がより堅牢であることを示しています
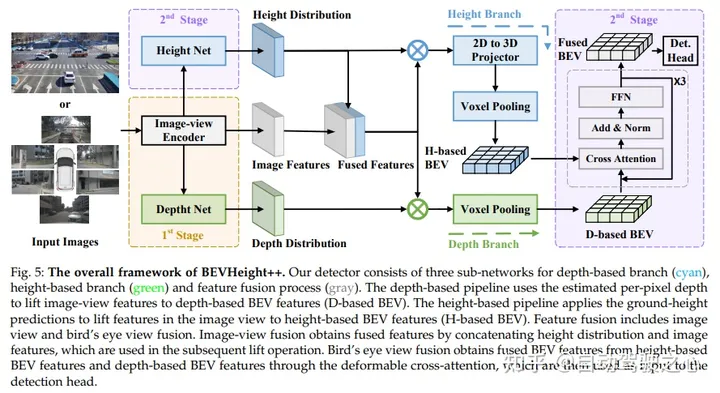
BEVHeight の全体的なフレームワークには、深さベースのブランチ (シアン)、高さベースのブランチ (緑)、および特徴融合プロセス (グレー) という 3 つのサブネットワークが含まれています。深度ベースのパイプラインは、推定されたピクセルごとの深度を使用して、画像ビューの特徴を深度ベースの BEV 特徴(D ベース BEV)に変換します。高さベースのパイプラインは、画像ビュー内のリフト フィーチャの地上高予測を使用して、高さベースの BEV フィーチャ (H ベース BEV) を生成します。特徴融合には、画像融合と鳥瞰図融合が含まれる。画像とビューの融合では、高さ分布と画像特徴をカスケード接続することによって融合特徴が取得され、後続のアップグレード操作に使用されます。鳥瞰図融合は、変形可能なクロスアテンションを通じて、高さベースの BEV 特徴と深さベースの BEV 特徴から融合された BEV 特徴を取得し、それを検出ヘッドの入力として使用します。 ## #############実験結果#################################
 ##書き直す必要がある内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/AdCXYzHIy2lTfAHk2AZ4_w
##書き直す必要がある内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/AdCXYzHIy2lTfAHk2AZ4_w
以上がはるか先! BEVHeight++: 道路脇の視覚的な 3D ターゲット検出のための新しいソリューション!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7843
7843
 15
1649
14
1403
52
1300
25
1241
29
15
1649
14
1403
52
1300
25
1241
29

 CUDA の汎用行列乗算: 入門から習熟まで!
Mar 25, 2024 pm 12:30 PM
CUDA の汎用行列乗算: 入門から習熟まで!
Mar 25, 2024 pm 12:30 PM
General Matrix Multiplication (GEMM) は、多くのアプリケーションやアルゴリズムの重要な部分であり、コンピューター ハードウェアのパフォーマンスを評価するための重要な指標の 1 つでもあります。 GEMM の実装に関する徹底的な調査と最適化は、ハイ パフォーマンス コンピューティングとソフトウェア システムとハードウェア システムの関係をより深く理解するのに役立ちます。コンピューター サイエンスでは、GEMM を効果的に最適化すると、計算速度が向上し、リソースが節約されます。これは、コンピューター システムの全体的なパフォーマンスを向上させるために非常に重要です。 GEMM の動作原理と最適化方法を深く理解することは、最新のコンピューティング ハードウェアの可能性をより有効に活用し、さまざまな複雑なコンピューティング タスクに対してより効率的なソリューションを提供するのに役立ちます。 GEMMのパフォーマンスを最適化することで
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 ファーウェイのQiankun ADS3.0インテリジェント運転システムは8月に発売され、初めてXiangjie S9に搭載される
Jul 30, 2024 pm 02:17 PM
ファーウェイのQiankun ADS3.0インテリジェント運転システムは8月に発売され、初めてXiangjie S9に搭載される
Jul 30, 2024 pm 02:17 PM
7月29日、AITO Wenjieの40万台目の新車のロールオフ式典に、ファーウェイの常務取締役、ターミナルBG会長、スマートカーソリューションBU会長のYu Chengdong氏が出席し、スピーチを行い、Wenjieシリーズモデルの発売を発表した。 8月にHuawei Qiankun ADS 3.0バージョンが発売され、8月から9月にかけて順次アップグレードが行われる予定です。 8月6日に発売されるXiangjie S9には、ファーウェイのADS3.0インテリジェント運転システムが初搭載される。 LiDARの支援により、Huawei Qiankun ADS3.0バージョンはインテリジェント運転機能を大幅に向上させ、エンドツーエンドの統合機能を備え、GOD(一般障害物識別)/PDP(予測)の新しいエンドツーエンドアーキテクチャを採用します。意思決定と制御)、駐車スペースから駐車スペースまでのスマート運転のNCA機能の提供、CAS3.0のアップグレード
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
原題: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 論文リンク: https://arxiv.org/pdf/2402.02519.pdf コードリンク: https://github.com/HKUST-Aerial-Robotics/SIMPL 著者単位: 香港科学大学DJI 論文のアイデア: この論文は、自動運転車向けのシンプルで効率的な動作予測ベースライン (SIMPL) を提案しています。従来のエージェントセントとの比較
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
