
 テクノロジー周辺機器
AI
最大 400 万のトークン コンテキストと 22 倍高速な推論を備えた StreamingLLM は人気があり、GitHub で 2.5,000 個のスターを獲得しています。
テクノロジー周辺機器
AI
最大 400 万のトークン コンテキストと 22 倍高速な推論を備えた StreamingLLM は人気があり、GitHub で 2.5,000 個のスターを獲得しています。
最大 400 万のトークン コンテキストと 22 倍高速な推論を備えた StreamingLLM は人気があり、GitHub で 2.5,000 個のスターを獲得しています。

会話型 AI ボットとやり取りしたことがあるなら、非常にイライラした瞬間を覚えているでしょう。たとえば、前日の会話であなたが話した重要な事柄は AI によって完全に忘れられました...
これは、現在の LLM が限られたコンテキストしか覚えていないためです。試験のための予備校の場合、少し質問すればその欠点が明らかになります。
AI アシスタントが数週間または数か月前の会話をチャットで状況に応じて参照できたり、AI アシスタントに数千ページのレポートを要約するよう依頼できたらどうでしょうか長いから、こんなこと あなたの能力は羨ましいですか?
LLM がより多くのコンテンツを記憶し、記憶できるようにするために、研究者たちは懸命に取り組んできました。最近、MIT、メタ AI、カーネギー メロン大学の研究者は、言語モデルが無限のテキストをスムーズに処理できるようにする「StreamingLLM」と呼ばれる手法を提案しました。
論文アドレス: https://arxiv.org/pdf/2309.17453.pdf
- #プロジェクト アドレス: https: //github.com/mit-han-lab/streaming-llm
- StreamingLLM 動作原理は、モデル固有の性質によって固定された初期トークンを識別して保存することです。その理由は「注意力が低下する」ということです。最近のトークンのローリング キャッシュと組み合わせることで、StreamingLLM は精度を犠牲にすることなく推論を 22 倍高速化します。わずか数日で、このプロジェクトは GitHub プラットフォームで 2.5,000 個のスターを獲得しました。
# 具体的には、StreamingLLM は次のとおりです。 a 言語モデルが最後の試合のスコア、生まれたばかりの赤ちゃんの名前、長い契約、または討論の内容を正確に記憶できるようにするテクノロジー。 AI アシスタントのメモリをアップグレードするのと同じように、より重いワークロードを完璧に処理できます。
 # 技術的な詳細を見てみましょう。
# 技術的な詳細を見てみましょう。
メソッドの革新

この論文で、研究者は最初に LLM ストリーム アプリケーションの概念を紹介し、「効率とパフォーマンスを犠牲にすることなく無限の長さで使用できるのか? 入力展開 LLM は?」という疑問を提起しました。
LLM を無限に長い入力ストリームに適用すると、次の 2 つの大きな課題に直面することになります:
1. デコード段階では、トランスフォーマー図 1 (a) に示すように、ベースの LLM は以前のすべてのトークンのキーと値のステータス (KV) をキャッシュするため、過剰なメモリ使用量が発生し、デコード遅延が増加する可能性があります。既存のモデルの長さの外挿能力は制限されており、シーケンスの長さが事前トレーニング中に設定されたアテンション ウィンドウ サイズを超えると、パフォーマンスが低下します。
直感的な方法は、ウィンドウ アテンションと呼ばれます (図 1 b)。この方法は、最新のトークンのみに焦点を当てます。 KV 状態のウィンドウを使用すると、キャッシュがいっぱいになった後も安定したメモリ使用量とデコード速度を維持できますが、シーケンスの長さがキャッシュ サイズを超えると、最初のトークンの KV だけでも追い出されます。モデルは崩壊します。 。もう 1 つの方法は、スライディング ウィンドウを再計算することです (図 1 c に示されています)。この方法では、生成されたトークンごとに最近のトークンの KV 状態が再構築されます。パフォーマンスは強力ですが、ウィンドウ内で二次的な注意を計算する必要があります。結果は大幅に遅くなり、実際のストリーミング アプリケーションでは理想的ではありません。
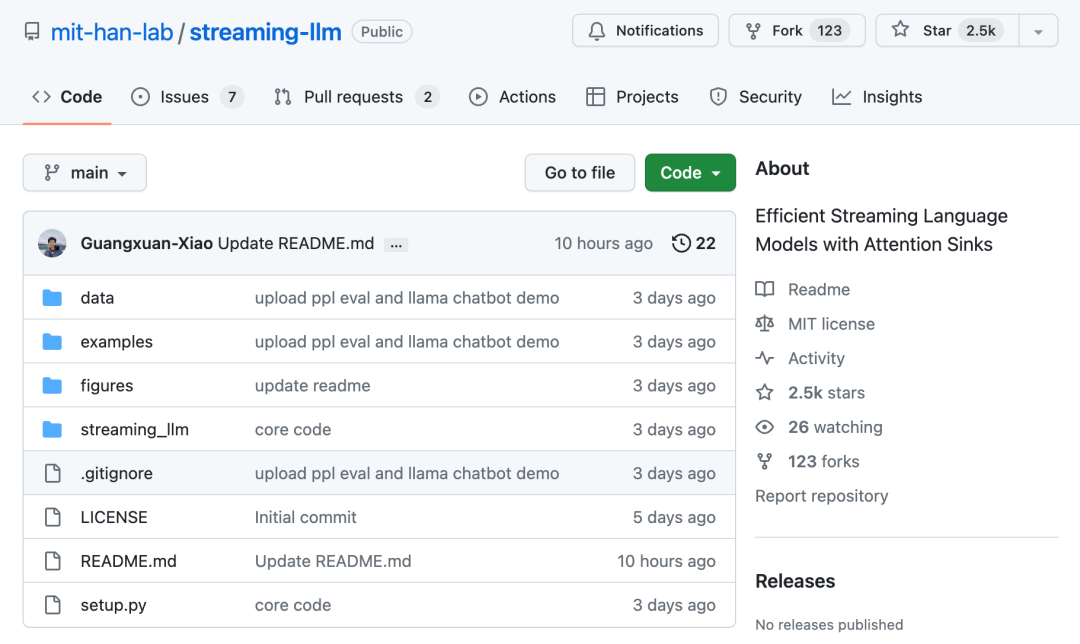
研究者たちは、ウィンドウ アテンションの失敗を研究する過程で、興味深い現象を発見しました。図 2 によると、タグが言語に関連しているかどうかに関係なく、初期タグに多数のアテンション スコアが割り当てられています。モデリング タスクに関連する
研究者はこれらのトークンを「アテンション プール」と呼んでいます。意味的な意味はありませんが、重要な役割を果たします。注目ポイントがたくさん。研究者らは、この現象は Softmax (すべてのコンテキスト トークンのアテンション スコアの合計が 1 である必要がある) のせいだと考えています。現在のクエリに以前の多くのトークンの間で強い一致がない場合でも、モデルはこれらの不必要なアテンションを転送する必要があります。 . 合計が 1 になるように値がどこかに割り当てられます。最初のトークンが「プール」になる理由は直感的です。自己回帰言語モデリングの特性により、最初のトークンは後続のほぼすべてのトークンに表示されるため、アテンション プールとしてトレーニングすることが容易になります。
上記の洞察に基づいて、研究者は StreamingLLM を提案しました。これは、制限されたアテンション ウィンドウでトレーニングされたアテンション モデルが微調整することなく無限に長いテキストを処理できるようにする、シンプルかつ効率的なフレームワークです。
StreamingLLM はアテンションを活用します。プールには高いアテンション値があり、保持されます。これらのアテンション プールにより、アテンション スコアの分布を正規分布に近づけることができます。したがって、StreamingLLM は、アテンションの計算を固定し、モデルのパフォーマンスを安定させるために、アテンション プール トークンの KV 値 (初期トークン 4 つだけで十分) とスライディング ウィンドウの KV 値を保持するだけで済みます。
Llama-2-[7,13,70] B、MPT-[7,30] B、Falcon-[7,40] B、および Pythia [2.9 を含む StreamingLLM を使用する] ,6.9,12] B を含むモデルは、400 万以上のトークンを確実にシミュレートできます。
スライディング ウィンドウの再計算と比較して、StreamingLLM はパフォーマンスを損なうことなく 22.2 倍高速です。
評価
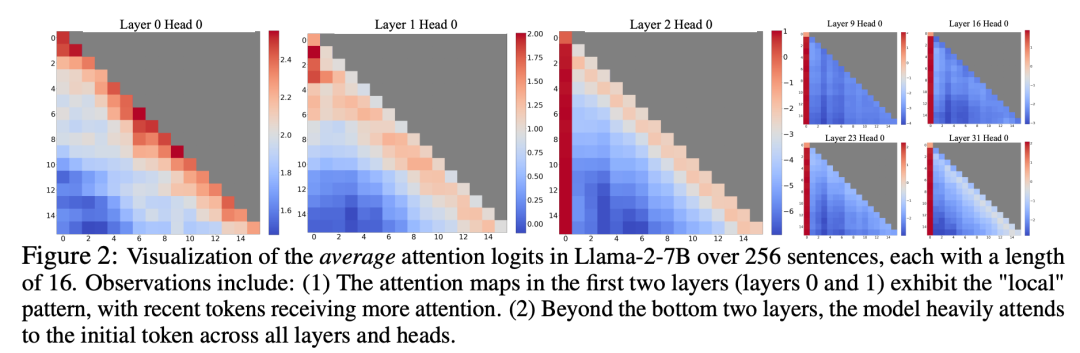
実験では、図 3 に示すように、20K トークンにわたるテキストの場合、StreamingLLM の複雑さは、スライディング ウィンドウを再計算する Oracle のベースラインに匹敵します。同時に、入力長が事前トレーニング ウィンドウを超えると、高密度アテンションは失敗し、入力長がキャッシュ サイズを超えると、ウィンドウ アテンションがスタックし、最初のタグが削除されてしまいます
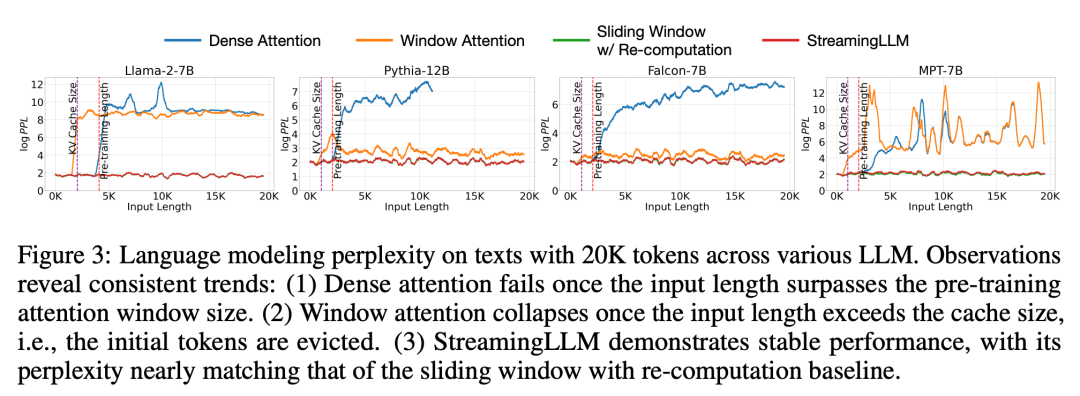
# 図 5 は、StreamingLLM の信頼性をさらに裏付けています。StreamingLLM は、さまざまなモデル ファミリとサイズをカバーし、400 万を超えるトークンを含む、型破りなスケールのテキストを処理できます。これらのモデルには、Llama-2-[7,13,70] B、Falcon-[7,40] B、Pythia-[2.8,6.9,12] B、MPT-[7,30] B# が含まれます。
最後に、研究者らは、単一の NVIDIA A6000 GPU 上の Llama-2-7B と Llama- を使用して、StreamingLLM のデコード レイテンシとメモリ使用量を、再計算されたスライディング ウィンドウと比較しました。モデルがテストされました。図 10 の結果によると、キャッシュ サイズが増加するにつれて、StreamingLLM のデコード速度は直線的に増加しますが、デコード遅延は二次関数的に増加します。実験により、StreamingLLM が各トークンの速度を最大 22.2 倍に向上させ、驚異的な高速化を達成することが証明されました。詳細 研究の詳細については、元の論文を参照してください。
以上が最大 400 万のトークン コンテキストと 22 倍高速な推論を備えた StreamingLLM は人気があり、GitHub で 2.5,000 個のスターを獲得しています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7489
7489
 15
1377
52
77
11
19
40
15
1377
52
77
11
19
40

 phpmyAdminはデータテーブルを作成します
Apr 10, 2025 pm 11:00 PM
phpmyAdminはデータテーブルを作成します
Apr 10, 2025 pm 11:00 PM
phpMyAdminを使用してデータテーブルを作成するには、次の手順が不可欠です。データベースに接続して、[新しいタブ]をクリックします。テーブルに名前を付けて、ストレージエンジンを選択します(InnoDB推奨)。列名、データ型、null値、その他のプロパティを許可するかどうかなど、列の追加ボタンをクリックして列の詳細を追加します。一次キーとして1つ以上の列を選択します。 [保存]ボタンをクリックして、テーブルと列を作成します。
 Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースを作成するのは簡単ではありません。根本的なメカニズムを理解する必要があります。 1.データベースとOracle DBMSの概念を理解する必要があります。 2。SID、CDB(コンテナデータベース)、PDB(プラグ可能なデータベース)などのコアコンセプトをマスターします。 3。SQL*Plusを使用してCDBを作成し、PDBを作成するには、サイズ、データファイルの数、パスなどのパラメーターを指定する必要があります。 4.高度なアプリケーションは、文字セット、メモリ、その他のパラメーターを調整し、パフォーマンスチューニングを実行する必要があります。 5.ディスクスペース、アクセス許可、パラメーター設定に注意し、データベースのパフォーマンスを継続的に監視および最適化します。 それを巧みに習得することによってのみ、継続的な練習が必要であることは、Oracleデータベースの作成と管理を本当に理解できます。
 Oracleデータベースの作成方法Oracleデータベースの作成方法
Apr 11, 2025 pm 02:36 PM
Oracleデータベースの作成方法Oracleデータベースの作成方法
Apr 11, 2025 pm 02:36 PM
Oracleデータベースを作成するには、一般的な方法はDBCAグラフィカルツールを使用することです。手順は次のとおりです。1。DBCAツールを使用してDBNAMEを設定してデータベース名を指定します。 2. SyspasswordとSystemPassWordを強力なパスワードに設定します。 3.文字セットとNationalCharactersetをAL32UTF8に設定します。 4.実際のニーズに応じて調整するようにMemorySizeとTableSpacesizeを設定します。 5. logfileパスを指定します。 高度な方法は、SQLコマンドを使用して手動で作成されますが、より複雑でエラーが発生しやすいです。 パスワードの強度、キャラクターセットの選択、表空間サイズ、メモリに注意してください
 Oracleデータベースステートメントの作成方法
Apr 11, 2025 pm 02:42 PM
Oracleデータベースステートメントの作成方法
Apr 11, 2025 pm 02:42 PM
Oracle SQLステートメントのコアは、さまざまな条項の柔軟なアプリケーションと同様に、選択、挿入、更新、削除です。インデックスの最適化など、ステートメントの背後にある実行メカニズムを理解することが重要です。高度な使用法には、サブクエリ、接続クエリ、分析関数、およびPL/SQLが含まれます。一般的なエラーには、構文エラー、パフォーマンスの問題、およびデータの一貫性の問題が含まれます。パフォーマンス最適化のベストプラクティスには、適切なインデックスの使用、Select *の回避、条項の最適化、およびバインドされた変数の使用が含まれます。 Oracle SQLの習得には、コードライティング、デバッグ、思考、基礎となるメカニズムの理解など、練習が必要です。
 mysqlデータテーブルフィールド操作ガイドの追加、変更、削除方法ガイド
Apr 11, 2025 pm 05:42 PM
mysqlデータテーブルフィールド操作ガイドの追加、変更、削除方法ガイド
Apr 11, 2025 pm 05:42 PM
MySQLのフィールド操作ガイド:フィールドを追加、変更、削除します。フィールドを追加:table table_nameを変更するcolumn_name data_type [not null] [default default_value] [プライマリキー] [auto_increment]フィールドの変更:column_name data_typeを変更するcolumn_name data_type [not null] [default default_value] [プライマリキー]
 Oracleデータベーステーブルの整合性の制約は何ですか?
Apr 11, 2025 pm 03:42 PM
Oracleデータベーステーブルの整合性の制約は何ですか?
Apr 11, 2025 pm 03:42 PM
Oracleデータベースの整合性の制約により、以下を含むデータの精度を確保できます。NULL:NULL値は禁止されています。一意:単一のヌル値を許可する一意性を保証します。一次キー:一次キーの制約、一意を強化し、ヌル値を禁止します。外部キー:テーブル間の関係を維持する、外部キーはプライマリテーブルのプライマリキーを参照します。チェック:条件に応じて列の値を制限します。
 MySQLデータベースのネストされたクエリインスタンスの詳細な説明
Apr 11, 2025 pm 05:48 PM
MySQLデータベースのネストされたクエリインスタンスの詳細な説明
Apr 11, 2025 pm 05:48 PM
ネストされたクエリは、1つのクエリに別のクエリを含める方法です。これらは主に、複雑な条件を満たし、複数のテーブルを関連付け、要約値または統計情報を計算するデータを取得するために使用されます。例には、平均賃金を超える従業員を見つけること、特定のカテゴリの注文を見つけること、各製品の総注文量の計算が含まれます。ネストされたクエリを書くときは、サブ征服を書き、結果を外側のクエリ(エイリアスまたは条項として参照)に書き込み、クエリパフォーマンスを最適化する必要があります(インデックスを使用)。
 Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログがメモリの漏れのトラブルシューティングに役立つ方法
Apr 12, 2025 pm 11:42 PM
Tomcatログは、メモリリークの問題を診断するための鍵です。 Tomcatログを分析することにより、メモリの使用状況とガベージコレクション(GC)の動作に関する洞察を得ることができ、メモリリークを効果的に見つけて解決できます。 Tomcatログを使用してメモリリークをトラブルシューティングする方法は次のとおりです。1。GCログ分析最初に、詳細なGCロギングを有効にします。 Tomcatの起動パラメーターに次のJVMオプションを追加します:-xx:printgcdetails-xx:printgcdateStamps-xloggc:gc.logこれらのパラメーターは、GCタイプ、リサイクルオブジェクトサイズ、時間などの情報を含む詳細なGCログ(GC.log)を生成します。分析GC.LOG
