

ルカン氏、自動運転ユニコーン詐欺に深く失望

これは普通の自動運転ビデオだと思いますか?
 画像
画像
このコンテンツは、元の意味を変更せずに中国語に書き直す必要があります。
どのフレームも「本物」ではありません。
 写真
写真
さまざまな道路状況、さまざまな気象条件、20 以上の状況をシミュレートでき、その効果は本物とまったく同じです。
 写真
写真
世界モデルが再び多大な貢献を果たしました。これを見たルカンさんは熱心にリツイートした。
 写真
写真
最新バージョンの GAIA-1 によってもたらされる上記の効果によると、
このプロジェクトの規模4,700 時間の運転ビデオ トレーニングを通じて 90 億のパラメータに達し、ビデオ、テキスト、または操作を入力して自動運転ビデオを生成する効果を達成することに成功しました。
最も直接的な利点は、将来のイベントをより適切に予測できることです。 20 さまざまなシナリオをシミュレーションできるため、自動運転の安全性がさらに向上し、コストが削減されます。
 写真
写真
私たちのクリエイティブチームは、これは自動運転ゲームのルールを完全に変えるだろうと率直に述べました。
それでは、GAIA-1 はどのように実装されるのでしょうか?
スケールは大きいほど優れています
GAIA-1 は複数のモードを備えた生成世界モデルです
ビデオ、テキスト、アクションを入力として利用することで、システムはリアルな運転を実現します自動運転車の動作とシーンの特性を細かく制御しながら、シーン ビデオを生成できます。
テキスト プロンプトのみを使用してビデオを生成できます。
 画像
画像
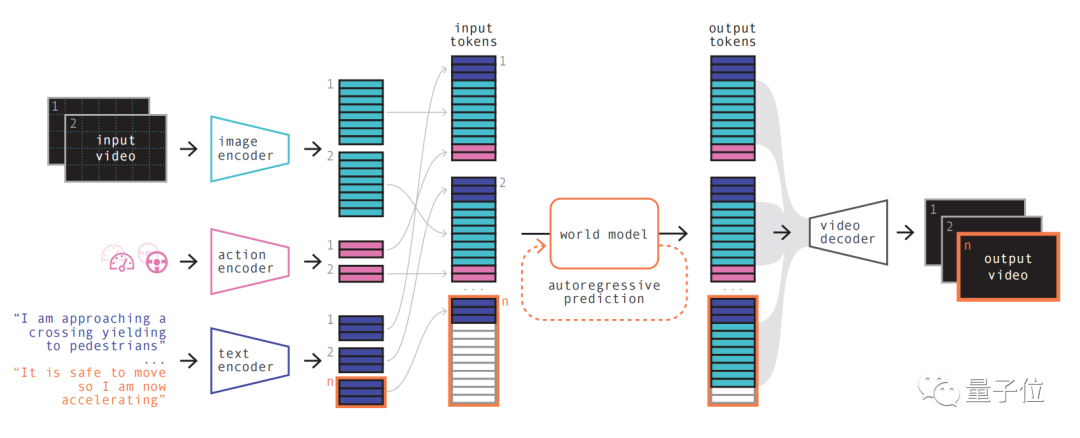
モデルの原理は、大規模な言語モデルの原理と似ています。つまり、次のマークを予測します。
モデルは、ベクトル量子化表現を使用してビデオ フレームを離散化し、変換される将来のシーンを予測できます。予測シーケンスへの次のトークン。次に、拡散モデルを使用して、ワールド モデルの言語空間から高品質のビデオが生成されます。
具体的な手順は次のとおりです。
 図
図
#最初のステップは理解しやすいもので、再コード化して配置し、さまざまな入力を組み合わせます。
特殊なエンコーダを使用してさまざまな入力をエンコードし、さまざまな入力を共有表現に投影します。テキストおよびビデオ エンコーダは入力を分離して埋め込みますが、操作表現は共有表現に個別に投影され、これらのエンコードされた表現は時間的に一貫しています。
配置が完了すると、ワールド モデルの重要な部分が表示されます。
自己回帰トランスフォーマーとして、シーケンス内の次のイメージ トークンのセットを予測できます。また、前の画像トークンだけでなく、テキストや操作のコンテキスト情報も考慮されます。
モデルによって生成されたコンテンツは、画像の一貫性を維持するだけでなく、予測されたテキストやアクションとの一貫性も維持します
チームは、GAIA の世界モデルのサイズを紹介しました。 1 は 65 億のパラメータで、A100 の 64 ブロックで 15 日間トレーニングされました。
最後に、ビデオ デコーダとビデオ拡散モデルを使用して、これらのトークンをビデオに変換します。
このステップの重要性は、ビデオのセマンティック品質、画像精度、時間的一貫性を確保することです
GAIA-1 のビデオ デコーダは 26 億パラメータの規模を持ち、32 台の A100 を使用してトレーニングされています15日以内に届きます。
GAIA-1 は原理的に大規模な言語モデルに似ているだけでなく、モデルの規模が拡大するにつれて生成品質が向上するという特徴も示していることは注目に値します。
#Picture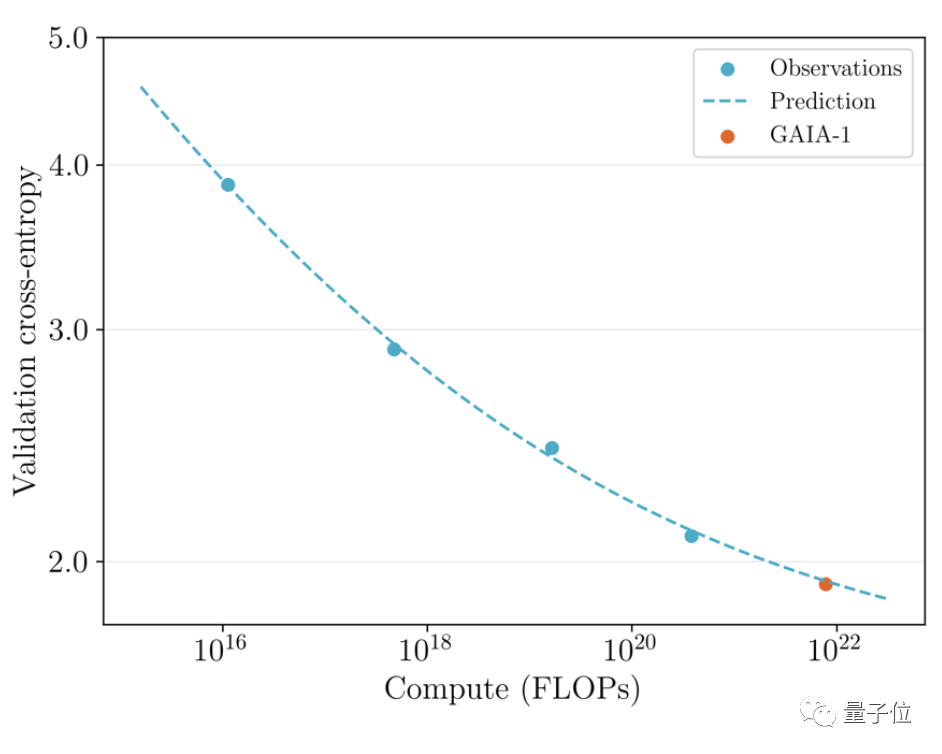 チームは、6 月に以前にリリースされた初期バージョンと最新の効果を比較しました。
チームは、6 月に以前にリリースされた初期バージョンと最新の効果を比較しました。
後者は前者の 480 倍の大きさです。
動画のディテールや解像度などが大幅に向上していることが直感的にわかります。
写真 実用化の観点から見ると、GAIA-1 の登場も一定の影響を与えており、主要クリエイティブチームはこれが変わるだろうと述べています。自動運転のルール
実用化の観点から見ると、GAIA-1 の登場も一定の影響を与えており、主要クリエイティブチームはこれが変わるだろうと述べています。自動運転のルール
 写真
写真
その理由は 3 つの側面から説明できます:
- 安全性
- 包括的なトレーニング データ
- ロングテールシナリオ
まず、安全性の観点から言えば、世界モデルは未来をシミュレーションし、AIに自律走行車の安全性にとって重要な独自の決定を実現する能力を与えることができます。運転中。
第二に、トレーニング データも自動運転にとって非常に重要です。生成されるデータは、より安全で、コスト効率が高く、無限に拡張可能です。
生成 AI は、自動運転が直面するロングテール シナリオの課題の 1 つを解決できます。霧の天候で道路を横断する歩行者に遭遇するなど、よりエッジなシナリオに対応できます。これにより、自動運転の機能がさらに向上します。
Wayve とは何ですか?
GAIA-1 は英国の自動運転スタートアップ Wayve によって開発されました
Wayve は 2017 年に設立されました。投資家には Microsoft などが含まれ、その評価額はユニコーンに達しています。
創設者は Alex Kendall と Amar Shah で、二人ともケンブリッジ大学で機械学習の博士号を取得しています
 写真
写真
技術的な路線では、テスラと同様に、ウェイブはカメラを使用した純粋に視覚的なソリューションの使用を提唱し、高精度の地図を非常に早い段階で放棄し、「瞬時認識」路線をしっかりと守ります。
少し前に、チームがリリースした別の大型モデル LINGO-1 も広く注目を集めました。
この自動運転モデルは、走行中にリアルタイムでコメントを生成できるため、モデルの精度がさらに向上します。説明可能性
今年3月、ビル・ゲイツ氏もウェイブの自動運転車に試乗した。
 写真
写真
紙のアドレス: https://www.php.cn/link/1f8c4b6a0115a4617e285b4494126fbf
参考リンク:
[1]https://www.php.cn/link/85dca1d270f7f9aef00c9d372f114482[2]https://www.php.cn/link/a4c22565dfafb162a17a7c357ca9e0be
以上がルカン氏、自動運転ユニコーン詐欺に深く失望の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1384
52
84
11
28
99
15
1384
52
84
11
28
99

 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 テスラがついに行動を起こす!自動運転タクシーは間もなく発表されるでしょうか? !
Apr 08, 2024 pm 05:49 PM
テスラがついに行動を起こす!自動運転タクシーは間もなく発表されるでしょうか? !
Apr 08, 2024 pm 05:49 PM
4月8日のニュースによると、テスラのCEOイーロン・マスク氏は最近、テスラが自動運転車技術の開発に取り組んでいることを明らかにし、待望の無人自動運転タクシー「ロボタクシー」が8月8日に正式デビューすると発表した。データ編集者は、マスク氏の発言が次のことであることを知った。以前ロイターは、テスラの自動車運転計画はロボタクシーの生産に焦点を当てていると報じた。しかし、マスク氏はこれに反論し、ロイター通信が低価格車の開発計画を中止し、再び虚偽の報告書を発表したと非難し、一方、低価格車のモデル2とロボタックスの開発は明らかになったと明らかにした。
 Tesla Dojo のスーパーコンピューティング デビュー、マスク氏: 年末までに AI をトレーニングするためのコンピューティング能力は、NVIDIA H100 GPU 8,000 個とほぼ同等になるでしょう
Jul 24, 2024 am 10:38 AM
Tesla Dojo のスーパーコンピューティング デビュー、マスク氏: 年末までに AI をトレーニングするためのコンピューティング能力は、NVIDIA H100 GPU 8,000 個とほぼ同等になるでしょう
Jul 24, 2024 am 10:38 AM
7 月 24 日のこの Web サイトのニュースによると、テスラ CEO イーロン マスク (イーロン マスク) は、本日の決算電話会議で、同社が 2,000 台の NVIDIA H100 を搭載するこれまでで最大の人工知能トレーニング クラスターを完成させようとしていると述べました。 GPU。マスク氏はまた、同社の決算会見で投資家に対し、NvidiaのGPUは高価であるため、テスラはDojoスーパーコンピューターの開発に取り組むと語った。このサイトは、マスク氏のスピーチの一部を次のように翻訳しました: Dojo を通じて NVIDIA と競争する道は困難ですが、私たちは今、NVIDIA に過度に依存しています。 NVIDIA の観点からすると、市場が耐えられるレベルまで GPU の価格を引き上げるのは必然ですが、
 量産型キラー! P-Mapnet: 従来の低精度地図 SDMap を使用することで、マッピングのパフォーマンスが 20 ポイント近く大幅に向上しました。
Mar 28, 2024 pm 02:36 PM
量産型キラー! P-Mapnet: 従来の低精度地図 SDMap を使用することで、マッピングのパフォーマンスが 20 ポイント近く大幅に向上しました。
Mar 28, 2024 pm 02:36 PM
上で書いたように、高精度地図への依存を取り除くために現在の自動運転システムで使用されているアルゴリズムの 1 つは、長距離領域での知覚性能が依然として低いという事実を利用するものです。この目的を達成するために、私たちは P-MapNet を提案します。「P」はモデルのパフォーマンスを向上させるためにマップ事前分布を融合することに焦点を当てています。具体的には、SDMap と HDMap の事前情報を活用します。一方で、OpenStreetMap から弱く調整された SDMap データを抽出し、入力をサポートするためにそれを独立した用語にエンコードします。厳密に変更された入力と実際の HD+Map の間には調整が弱いという問題がありますが、クロスアテンション メカニズムに基づく構造は、SDMap スケルトンに適応的に焦点を合わせ、大幅なパフォーマンスの向上をもたらします。
