

時間的冗長性への驚くべきアプローチ: ビジュアル Transformer の計算コストを削減する新しい方法

Transformer はもともと自然言語処理タスク用に設計されましたが、現在では視覚タスクで広く使用されています。 Vision Transformer は、複数の視覚認識タスクで優れた精度を実証し、画像分類、ビデオ分類、ターゲット検出などのタスクで最先端のパフォーマンスを達成しました
視覚 大きな欠点Transformer の最大の特徴は、計算コストが高いことです。一般的な畳み込みネットワーク (CNN) では画像あたり数十 GFlops が必要ですが、ビジュアル トランスフォーマーでは多くの場合、1 桁以上の量が必要となり、画像あたり数百 GFlops に達します。ビデオを処理する場合、データ量が膨大になるため、この問題はさらに深刻になります。計算コストが高いため、リソースが限られているデバイスや遅延要件が厳しいデバイスに Visual Transformer を展開することが困難になり、このテクノロジのアプリケーション シナリオが制限されます。そうでなければ、すでにいくつかのエキサイティングなアプリケーションが存在することになります。
ウィスコンシン大学マディソン校の 3 人の研究者である Matthew Dutson、ying Li、および Mohit Gupta は、最近の論文で、後続の入力間に時間的冗長性を使用できることを初めて提案しました。ビデオ アプリケーションの Visual Transformer のコスト。また、Eventful Transformer の構築に使用される PyTorch モジュールを含むモデル コードもリリースしました。

- 論文アドレス: https://arxiv.org/pdf/2308.13494.pdf
- #プロジェクトのアドレス: http://wisionlab.com/project/eventful-transformers
自然ビデオには、重大な時間的冗長性が含まれています。つまり、後続のフレーム間の差異は小さいです。それにもかかわらず、Transformers を含むディープ ネットワークは通常、各フレームを「最初から」計算します。この方法では、以前の推論によって得られた潜在的に関連する情報が破棄されるため、非常に無駄が生じます。したがって、これら 3 人の研究者は、冗長シーケンスの処理効率を向上させるために、前の計算ステップの中間計算結果を再利用できないか、と想像しました。
適応推論: ビジュアル Transformer やディープ ネットワーク一般の場合、推論のコストはアーキテクチャによって決まることがよくあります。ただし、実際のアプリケーションでは、競合するプロセスや電力の変化などにより、利用可能なリソースが時間の経過とともに変化する可能性があります。その結果、実行時にモデルの計算コストを変更する必要が生じる場合があります。この新たな取り組みにおいて研究者らが設定した主な設計目標の 1 つは適応性であり、彼らのアプローチにより計算コストのリアルタイム制御が可能になりました。以下の図 1 (下) は、ビデオ処理中に計算量を変更する例を示しています。
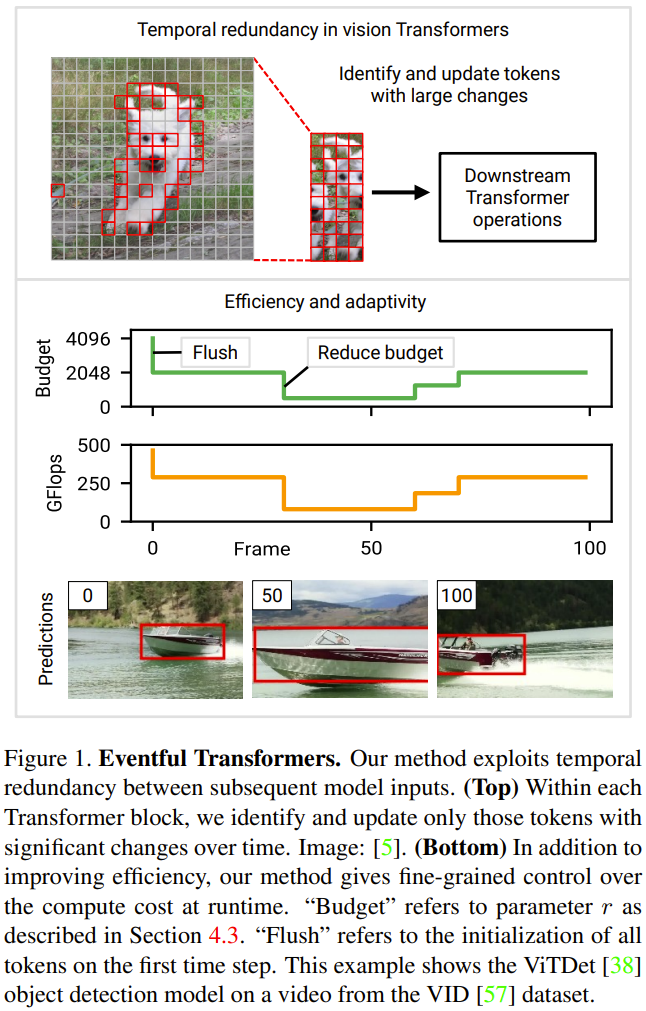
この方法は、既存のモデル (通常は再トレーニングなし) に適しており、多くのビデオ処理に適しています。タスク。研究者らはまた、計算コストを大幅に削減し、元の精度を維持しながら、Eventful Transformer を既存の最良のモデルで使用できることを実証する実験を実施しました。
Eventful Transformer
書き直された内容: この研究の目標は、ビデオ認識のための Visual Transformer を高速化することです。このシナリオでは、ビジュアル Transformer はビデオ フレームまたはビデオ クリップを繰り返し処理する必要があり、具体的なタスクにはビデオ ターゲットの検出とビデオ アクションの認識が含まれます。提案される重要なアイデアは、時間的冗長性を活用すること、つまり、前のタイム ステップからの計算結果を再利用することです。以下では、時間の冗長性を検知できるように Transformer モジュールを変更する方法を詳しく説明します。
トークン ゲート: 冗長性の検出
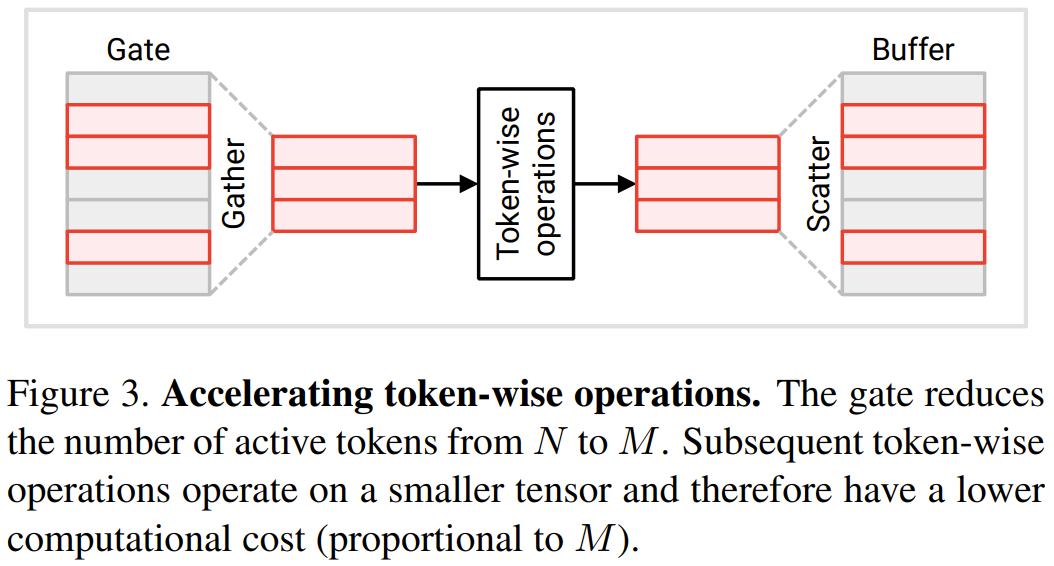
このセクションでは、研究者によって提案された 2 つの新しいモジュール、トークン ゲートとトークンを紹介します。バッファ。これらのモジュールを使用すると、モデルは最後の更新以降に大幅に変更されたトークンを識別して更新できます
ゲート モジュール: このゲートは入力トークン N から部分 M を選択し、それを下流に送信します。計算を実行するレイヤー。 u で示される参照トークン セットをメモリ内に保持します。この参照ベクトルには、最新の更新時の各トークンの値が含まれています。各タイム ステップで、各トークンが対応する基準値と比較され、基準値と大きく異なるトークンが更新されます。
次に、このゲートの現在の入力を c としてマークします。各タイム ステップで、次のプロセスに従ってゲートのステータスを更新し、その出力を決定します (下記の図 2 を参照):
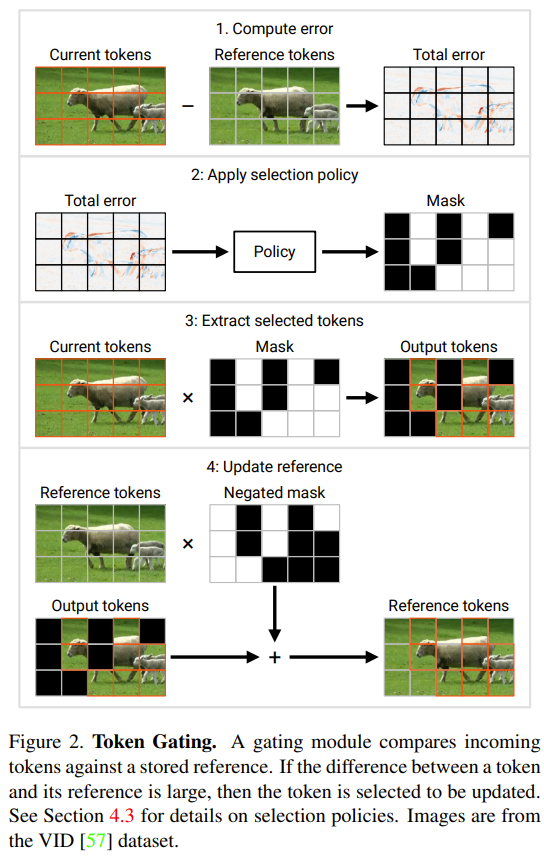
1.合計誤差 e = u − c。
2. エラー e に対して選択戦略を使用します。選択戦略は、どの M 個のトークンを更新する必要があるかを示すバイナリ マスク m (トークン インデックス リストに相当) を返します。
3. 上記の戦略によって選択されたトークンを抽出します。これは、図 2 では積 c × m として示されていますが、実際には、c の最初の軸に沿って「収集」操作を実行することによって達成されます。収集されたトークンは、ゲートの出力である 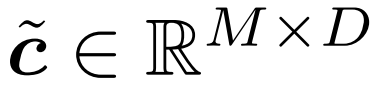 としてここに記録されます。
としてここに記録されます。
4. 参照トークンを選択したトークンに更新します。図 2 では、このプロセスを 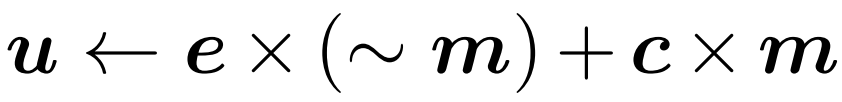 として説明しています。実際に使用される操作は「散布」です。最初のタイム ステップでは、ゲートはすべてのトークンを更新します (u ← c を初期化し、c~ = c を返します)。
として説明しています。実際に使用される操作は「散布」です。最初のタイム ステップでは、ゲートはすべてのトークンを更新します (u ← c を初期化し、c~ = c を返します)。
#バッファ モジュール: バッファ モジュールは、各入力トークンを追跡する状態テンソル 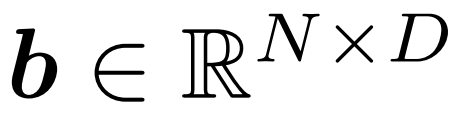 を維持します
を維持します
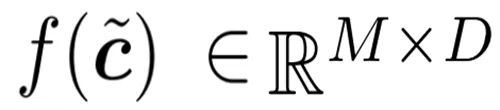 、バッファーはトークンを f (c~) から b 内の対応する位置に分散します。次に、更新された b を出力として返します (以下の図 3 を参照)。
、バッファーはトークンを f (c~) から b 内の対応する位置に分散します。次に、更新された b を出力として返します (以下の図 3 を参照)。
#研究者らは、各ゲートとその背後にあるバッファを組み合わせました。以下は簡単な使用パターンです: ゲート
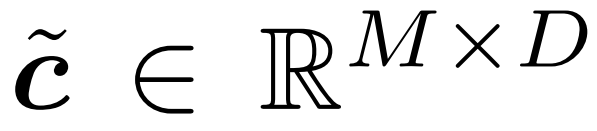 の出力は各トークンの一連の演算 f (c˜) に渡され、その結果のテンソル
の出力は各トークンの一連の演算 f (c˜) に渡され、その結果のテンソル 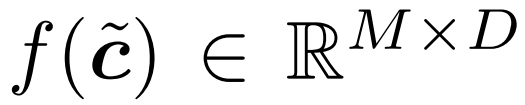 バッファに渡され、完全な形状が復元されます。
バッファに渡され、完全な形状が復元されます。
冗長性を認識したトランスフォーマーを再構築する
上記の時間冗長性を利用するために、研究者は次のように提案しました。 a Transformer モジュールへの変更スキーム。以下の図 4 は、Eventful Transformer モジュールの設計を示しています。この方法では、個々のトークン (MLP など) の操作だけでなく、クエリ キーと値およびアテンション値の乗算も高速化できます。
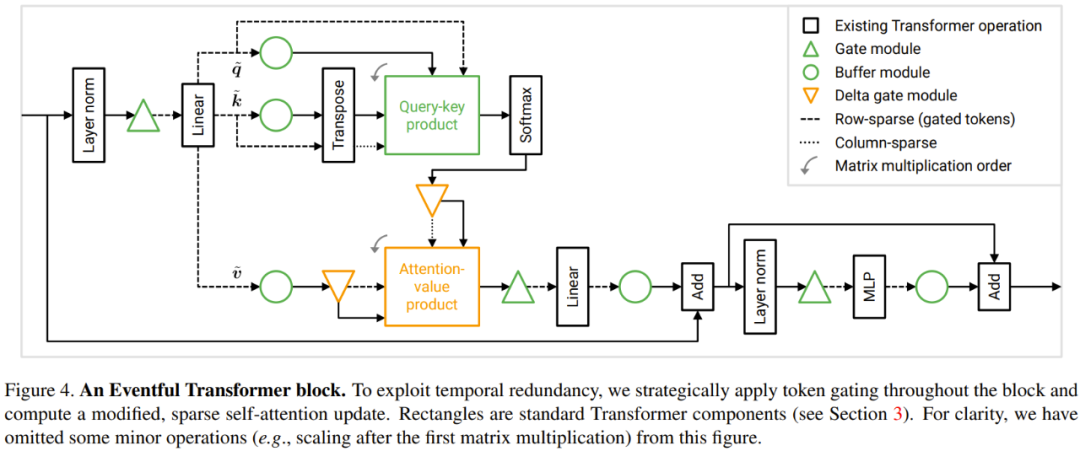
各トークンで動作する Transformer モジュールでは、多くの操作が各トークンで実行されます。つまり、MLP や MSA の線形変換など、トークン間の情報交換は含まれません。研究者らは、計算コストを節約するために、ゲートによって選択されなかったトークンに対するトークン指向の操作をスキップできると述べています。トークン間の独立性により、選択したトークンに対する操作の結果は変わりません。図 3 を参照してください。
具体的には、研究者らは、W_qkv 変換、W_p 変換、MLP などの各トークンの操作を処理するときに、一対のゲート バッファーの連続シーケンスを使用しました。接続をスキップする前に、2 つの加算オペランドのトークンが正しく配置されることを保証するためにバッファーも追加されたことに注意してください。
各トークンの操作コストは、トークンの数。数を N から M に減らすことで、トークンあたりのダウンストリーム操作コストは N/M 倍削減されます。
次に、クエリとキーと値の積 B = q k を見てみましょう。 ^T
の結果 下の図 5 は、クエリ キー バリュー プロダクト B の一部の要素を疎に更新する方法を示しています。
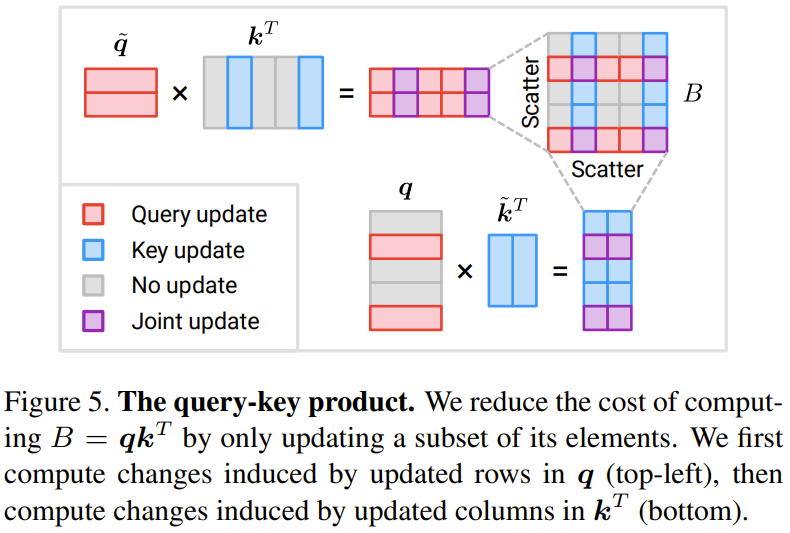
これらの更新の総コストは 2NMD で、B を最初から計算するコスト (N^2D) と比較します。新しいメソッドのコストは、選択されたトークンの数 M に比例することに注意してください。 M
注意 - 値の積:研究者はこれを提案しました デルタΔに基づく更新戦略が提案されました。
#図 6 は、3 つの増分項を効率的に計算するために新しく提案された方法を示しています
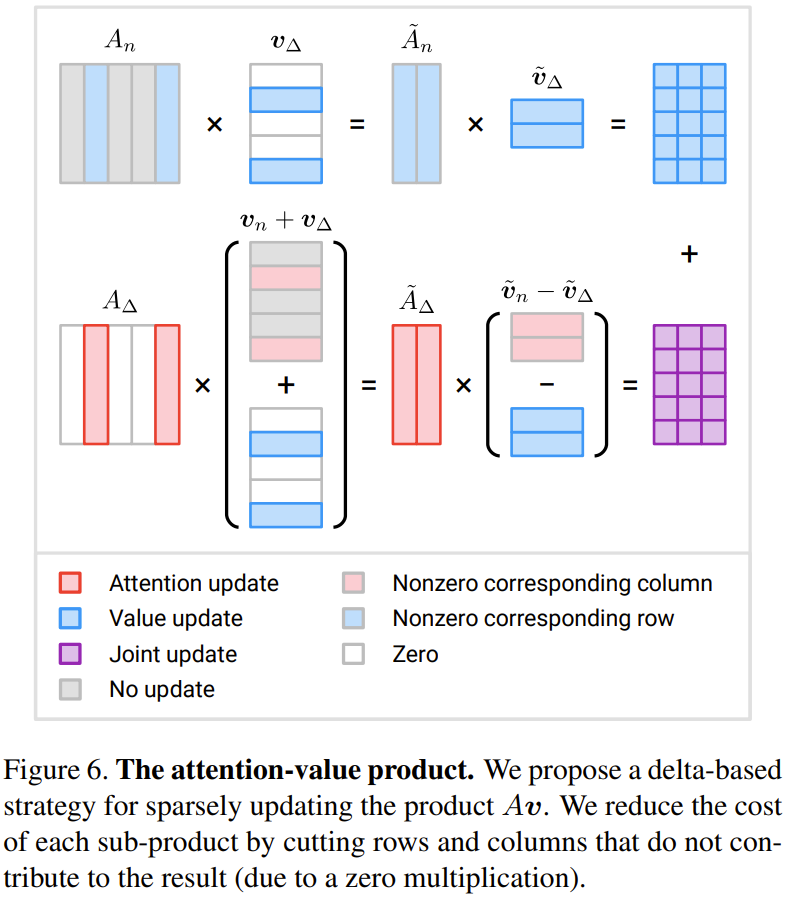
M が小さい場合N の半分よりも計算量を削減できる
トークン選択戦略
Eventful Transformer の 1 つ最も重要な設計は、トークン選択戦略です。ゲート エラー テンソル e が与えられた場合、このようなポリシーの目標は、更新する必要があるトークンを示すマスク m を生成することです。具体的な戦略は次のとおりです。
Top-r 戦略: この戦略は、最大の誤差 e を持つ r 個のトークンを選択します (ここでは L2 ノルムが使用されます)。
しきい値戦略: この戦略は、誤差のノルム e がしきい値 h
を超えるすべてのトークンを選択します。 書き換えられた内容: その他 戦略: 精度の向上-コストのトレードオフは、軽量ポリシー ネットワークを使用して戦略を学習するなど、より洗練されたトークン選択戦略を採用することで達成できます。ただし、バイナリ マスク m は通常微分不可能であるため、ポリシーの意思決定メカニズムをトレーニングすることは困難に直面する可能性があります。また、重要度スコアを選択の参考情報として利用するという考え方もある。ただし、これらのアイデアにはまださらなる調査が必要です
実験
研究者らは、特にビデオ ターゲットに適用された、新しく提案された方法の実験的評価を実施しました。検出およびビデオ アクション認識タスク
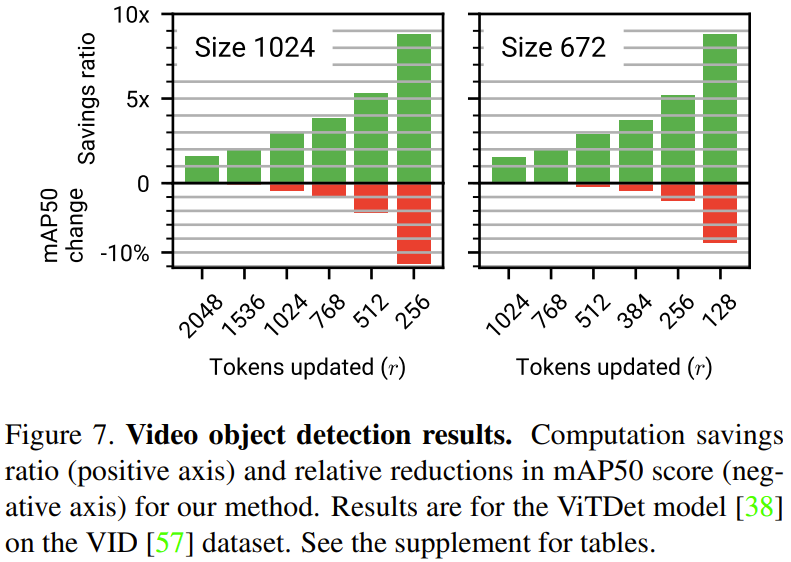
以下の図 7 は、ビデオ ターゲット検出の実験結果を示しています。ここで、正の軸は計算量の節約率、負の軸は新しい方法による mAP50 スコアの相対的な減少です。新しい方法では、精度を少し犠牲にして、大幅な計算量の節約が達成されることがわかります。
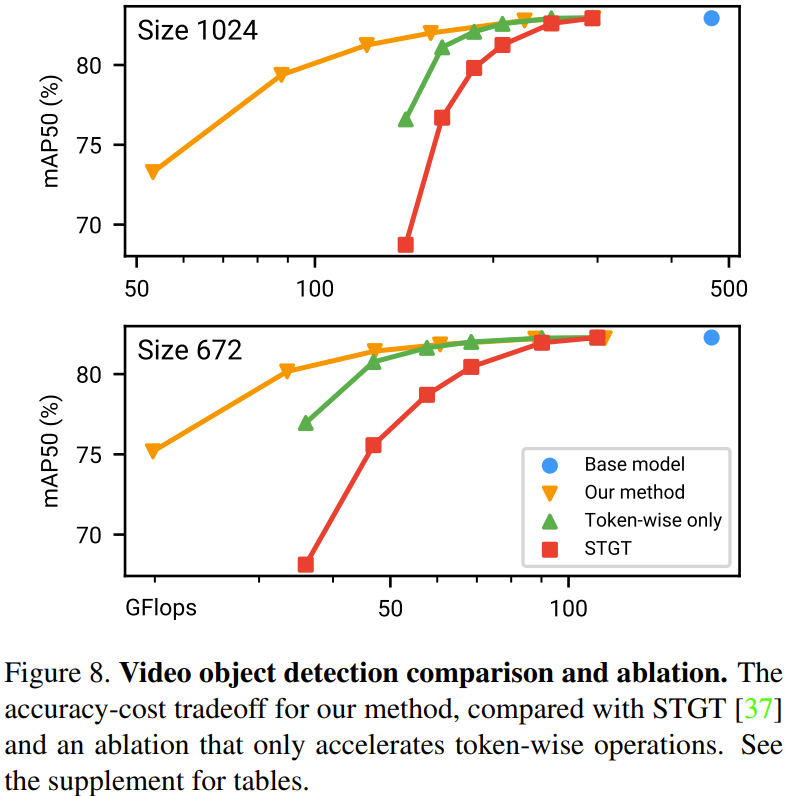
# 以下の図 8 は、ビデオ ターゲット検出タスクの方法の比較とアブレーションの実験結果を示しています
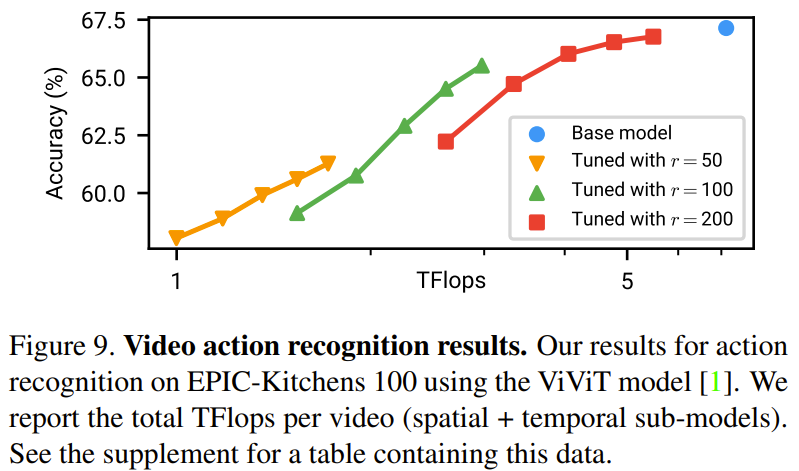
以下の図 9 は、ビデオ動作認識の実験結果を示しています。
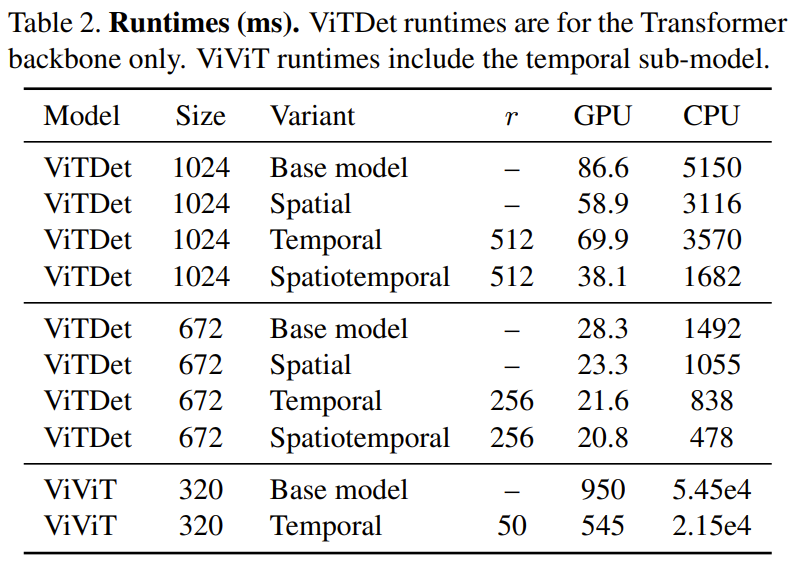
以下の表 2 では、1 つの CPU (Xeon Silver 4214、2.2 GHz) と 1 つの GPU (NVIDIA RTX3090) で実行した場合の時間結果 (ミリ秒単位) が示されています。 GPU の時間的冗長性により速度が 1.74 倍向上し、CPU では速度が 2.47 倍に達していることがわかります。
詳細はこちら技術的な詳細と実験結果については、元の論文を参照してください。
以上が時間的冗長性への驚くべきアプローチ: ビジュアル Transformer の計算コストを削減する新しい方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
40
15
1377
52
77
11
19
40

 ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
DDREASE は、ハード ドライブ、SSD、RAM ディスク、CD、DVD、USB ストレージ デバイスなどのファイル デバイスまたはブロック デバイスからデータを回復するためのツールです。あるブロック デバイスから別のブロック デバイスにデータをコピーし、破損したデータ ブロックを残して正常なデータ ブロックのみを移動します。 ddreasue は、回復操作中に干渉を必要としないため、完全に自動化された強力な回復ツールです。さらに、ddasue マップ ファイルのおかげでいつでも停止および再開できます。 DDREASE のその他の主要な機能は次のとおりです。 リカバリされたデータは上書きされませんが、反復リカバリの場合にギャップが埋められます。ただし、ツールに明示的に指示されている場合は切り詰めることができます。複数のファイルまたはブロックから単一のファイルにデータを復元します
 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
何?ズートピアは国産AIによって実現するのか?ビデオとともに公開されたのは、「Keling」と呼ばれる新しい大規模な国産ビデオ生成モデルです。 Sora も同様の技術的ルートを使用し、自社開発の技術革新を多数組み合わせて、大きく合理的な動きをするだけでなく、物理世界の特性をシミュレートし、強力な概念的結合能力と想像力を備えたビデオを制作します。データによると、Keling は、最大 1080p の解像度で 30fps で最大 2 分の超長時間ビデオの生成をサポートし、複数のアスペクト比をサポートします。もう 1 つの重要な点は、Keling は研究所が公開したデモやビデオ結果のデモンストレーションではなく、ショートビデオ分野のリーダーである Kuaishou が立ち上げた製品レベルのアプリケーションであるということです。さらに、主な焦点は実用的であり、白紙小切手を書かず、リリースされたらすぐにオンラインに移行することです。Ke Ling の大型モデルは Kuaiying でリリースされました。
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
