

データセットのサンプリング戦略がモデルのパフォーマンスに与える影響


データセットのサンプリング戦略がモデルのパフォーマンスに与える影響には、特定のコード例が必要です
機械学習と深層学習の急速な発展に伴い、データの品質と規模は向上しています。 set モデルのパフォーマンスへの影響はますます重要になってきています。実際のアプリケーションでは、過剰なデータ セット サイズ、不均衡なサンプル カテゴリ、サンプル ノイズなどの問題に直面することがよくあります。現時点では、サンプリング戦略を適切に選択すると、モデルのパフォーマンスと汎化能力を向上させることができます。この記事では、さまざまなデータセットのサンプリング戦略がモデルのパフォーマンスに与える影響について、具体的なコード例を通じて説明します。
- ランダム サンプリング
ランダム サンプリングは、最も一般的なデータ セットのサンプリング戦略の 1 つです。トレーニング プロセス中に、データ セットから一定の割合のサンプルがトレーニング セットとしてランダムに選択されます。この方法はシンプルで直感的ですが、サンプル カテゴリの不均衡な分布や重要なサンプルの損失につながる可能性があります。サンプル コードは次のとおりです。
import numpy as np
def random_sampling(X, y, sample_ratio):
num_samples = int(sample_ratio * X.shape[0])
indices = np.random.choice(X.shape[0], num_samples, replace=False)
X_sampled = X[indices]
y_sampled = y[indices]
return X_sampled, y_sampled- 層化サンプリング
層化サンプリングは、サンプル クラスの不均衡の問題を解決するための一般的な戦略です。層化サンプリングでは、サンプルのカテゴリに従ってデータセットを層化し、各カテゴリからサンプルの割合を選択します。この方法では、データ セット内の各カテゴリの割合を維持できるため、少数派のカテゴリを処理するモデルの能力が向上します。以下はサンプル コードです。
from sklearn.model_selection import train_test_split
from sklearn.utils import resample
def stratified_sampling(X, y, sample_ratio):
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=1-sample_ratio)
X_sampled, y_sampled = resample(X_train, y_train, n_samples=int(sample_ratio * X.shape[0]))
return X_sampled, y_sampled- エッジ サンプリング
エッジ サンプリングは、サンプル ノイズの問題を解決するための一般的な戦略です。エッジサンプリングでは、モデルを学習することでサンプルを信頼できるサンプルとノイズサンプルに分割し、信頼できるサンプルのみを選択してトレーニングします。以下はサンプル コードです。
from sklearn.svm import OneClassSVM
def margin_sampling(X, y, sample_ratio):
clf = OneClassSVM(gamma='scale')
clf.fit(X)
y_pred = clf.predict(X)
reliable_samples = X[y_pred == 1]
num_samples = int(sample_ratio * X.shape[0])
indices = np.random.choice(reliable_samples.shape[0], num_samples, replace=False)
X_sampled = reliable_samples[indices]
y_sampled = y[indices]
return X_sampled, y_sampled要約すると、データ セットのサンプリング戦略が異なれば、モデルのパフォーマンスに与える影響も異なります。ランダム サンプリングはトレーニング セットを簡単かつ迅速に取得できますが、不均衡なサンプル カテゴリが発生する可能性があります。層別サンプリングはサンプル カテゴリのバランスを維持し、少数カテゴリを処理するモデルの能力を向上させることができます。エッジ サンプリングはノイズの多いサンプルをフィルタリングして堅牢性を向上させることができます。モデルのセックス。実際のアプリケーションでは、モデルのパフォーマンスと汎化能力を向上させるために、特定の問題に基づいて適切なサンプリング戦略を選択し、実験と評価を通じて最適な戦略を選択する必要があります。
以上がデータセットのサンプリング戦略がモデルのパフォーマンスに与える影響の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7489
7489
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 PyTorch を使用した少数ショット学習による画像分類
Apr 09, 2023 am 10:51 AM
PyTorch を使用した少数ショット学習による画像分類
Apr 09, 2023 am 10:51 AM
近年、深層学習ベースのモデルは、物体検出や画像認識などのタスクで優れたパフォーマンスを発揮しています。 1,000 種類の異なるオブジェクト分類を含む ImageNet のような難しい画像分類データセットでは、一部のモデルが人間のレベルを超えています。しかし、これらのモデルは教師ありトレーニング プロセスに依存しており、ラベル付きトレーニング データの利用可能性に大きく影響され、モデルが検出できるクラスはトレーニングされたクラスに限定されます。トレーニング中にすべてのクラスに十分なラベル付き画像がないため、これらのモデルは現実の設定ではあまり役に立たない可能性があります。そして、すべての潜在的なオブジェクトの画像でトレーニングすることはほぼ不可能であるため、モデルがトレーニング中に認識しなかったクラスを認識できるようにしたいと考えています。いくつかのサンプルから学びます
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 カスタム データセットへの OpenAI CLIP の実装
Sep 14, 2023 am 11:57 AM
カスタム データセットへの OpenAI CLIP の実装
Sep 14, 2023 am 11:57 AM
2021 年 1 月、OpenAI は DALL-E と CLIP という 2 つの新しいモデルを発表しました。どちらのモデルも、テキストと画像を何らかの方法で接続するマルチモーダル モデルです。 CLIP の正式名は Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training) で、対照的なテキストと画像のペアに基づく事前トレーニング方法です。なぜCLIPを導入するのか?なぜなら、現在人気のStableDiffusionは単一のモデルではなく、複数のモデルで構成されているからです。重要なコンポーネントの 1 つはテキスト エンコーダで、ユーザーのテキスト入力をエンコードするために使用されます。このテキスト エンコーダは、CLIP モデルのテキスト エンコーダ CL です。
 Google AIビデオがまたすごい!オールインワンのユニバーサル ビジュアル エンコーダーである VideoPrism が 30 の SOTA パフォーマンス機能を更新
Feb 26, 2024 am 09:58 AM
Google AIビデオがまたすごい!オールインワンのユニバーサル ビジュアル エンコーダーである VideoPrism が 30 の SOTA パフォーマンス機能を更新
Feb 26, 2024 am 09:58 AM
AIビデオモデルSoraが人気を博した後、MetaやGoogleなどの大手企業は研究を行ってOpenAIに追いつくために手を引いた。最近、Google チームの研究者は、ユニバーサル ビデオ エンコーダー VideoPrism を提案しました。単一の凍結モデルを通じてさまざまなビデオ理解タスクを処理できます。画像ペーパーのアドレス: https://arxiv.org/pdf/2402.13217.pdf たとえば、VideoPrism は、以下のビデオ内でろうそくを吹き飛ばしている人を分類して特定できます。画像ビデオテキスト検索では、テキストコンテンツに基づいて、ビデオ内の対応するコンテンツを検索できます。別の例として、下のビデオについて説明します。小さな女の子が積み木で遊んでいます。 QAの質問と回答もご覧いただけます。
 データセットを正しく分割するにはどうすればよいでしょうか? 3 つの一般的な方法のまとめ
Apr 08, 2023 pm 06:51 PM
データセットを正しく分割するにはどうすればよいでしょうか? 3 つの一般的な方法のまとめ
Apr 08, 2023 pm 06:51 PM
データセットをトレーニング セットに分解すると、モデルを理解するのに役立ちます。これは、モデルを新しい未知のデータに一般化する方法にとって重要です。モデルが過剰適合している場合、新しい未確認のデータに対して適切に一般化できない可能性があります。したがって、良い予測はできません。適切な検証戦略を持つことは、適切な予測を作成し、AI モデルのビジネス価値を活用するための最初のステップです。この記事では、一般的なデータ分割戦略をいくつかまとめました。シンプルなトレーニングとテストの分割では、データセットがトレーニング部分と検証部分に分割され、80% がトレーニング、20% が検証になります。これは、Scikit のランダム サンプリングを使用して行うことができます。まず、ランダム シードを修正する必要があります。修正しないと、同じデータ分割を比較できず、デバッグ中に結果を再現できません。データセットの場合
 PyTorch 並列トレーニング DistributedDataParallel の完全なコード例
Apr 10, 2023 pm 08:51 PM
PyTorch 並列トレーニング DistributedDataParallel の完全なコード例
Apr 10, 2023 pm 08:51 PM
大規模なデータセットを使用して大規模なディープ ニューラル ネットワーク (DNN) をトレーニングするという問題は、ディープ ラーニングの分野における大きな課題です。 DNN とデータセットのサイズが増加するにつれて、これらのモデルをトレーニングするための計算要件とメモリ要件も増加します。そのため、コンピューティング リソースが限られている 1 台のマシンでこれらのモデルをトレーニングすることが困難または不可能になります。大規模なデータセットを使用して大規模な DNN をトレーニングする際の主な課題には次のようなものがあります。 長いトレーニング時間: モデルの複雑さとデータセットのサイズによっては、トレーニング プロセスが完了するまでに数週間、場合によっては数か月かかる場合があります。メモリの制限: 大規模な DNN では、トレーニング中にすべてのモデル パラメーター、勾配、中間アクティベーションを保存するために大量のメモリが必要になる場合があります。これにより、メモリ不足エラーが発生し、単一マシンでトレーニングできる内容が制限される可能性があります。
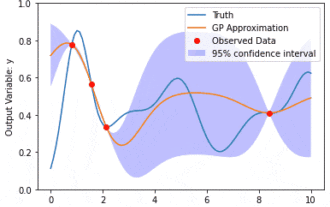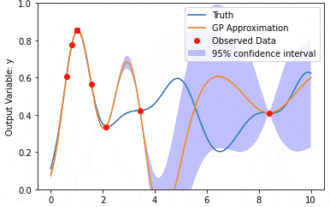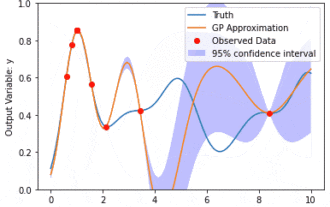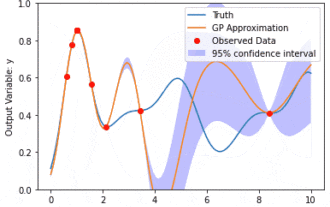 カーネル モデル ガウス プロセス (KMGP) を使用したデータ モデリング
Jan 30, 2024 am 11:15 AM
カーネル モデル ガウス プロセス (KMGP) を使用したデータ モデリング
Jan 30, 2024 am 11:15 AM
カーネル モデル ガウス プロセス (KMGP) は、さまざまなデータ セットの複雑さを処理するための高度なツールです。これは、カーネル関数を通じて従来のガウス プロセスの概念を拡張します。この記事では、KMGP の理論的基礎、実際の応用、課題について詳しく説明します。カーネル モデルのガウス プロセスは、従来のガウス プロセスの拡張であり、機械学習と統計で使用されます。 kmgp を理解する前に、ガウス過程の基礎知識を習得し、カーネル モデルの役割を理解する必要があります。ガウス プロセス (GP) は、ガウス分布で結合して分布する有限数の変数である一連の確率変数であり、関数の確率分布を定義するために使用されます。ガウス プロセスは、機械学習の回帰および分類タスクで一般的に使用され、データの確率分布を適合させるために使用できます。ガウス プロセスの重要な特徴は、不確実性の推定と予測を提供できることです。
 人工知能の炭素コストの計算
Apr 12, 2023 am 08:52 AM
人工知能の炭素コストの計算
Apr 12, 2023 am 08:52 AM
興味深いトピックを探しているなら、人工知能 (AI) があなたを失望させることはありません。人工知能には、チェスをしたり、下手な手書き文字を解読したり、音声を理解したり、衛星画像を分類したりできる、一連の強力で気が遠くなるような統計アルゴリズムが含まれています。機械学習モデルをトレーニングするための巨大なデータセットが利用できることは、人工知能の成功の重要な要素の 1 つです。しかし、このような計算作業はすべて無料ではありません。一部の AI 専門家は、新しいアルゴリズムの構築に伴う環境への影響について懸念を強めており、この議論は、AI の二酸化炭素排出量を削減するために機械をより効率的に学習させる方法に関する新しいアイデアを生み出しています。地球への帰還 詳細に入るには、まずコンピューティング リクエストを 24 時間 365 日処理する (世界中に点在する) 何千ものデータ センターを考慮する必要があります。
