

タイトルリライト: ICCV 2023 優秀学生論文追跡、Github が 1.6K スターを獲得、魔法のような包括的な情報!

1. 論文情報
今年の ICCV2023 最優秀学生論文は、現在カリフォルニア大学バークレー校で博士研究員を務めるコーネル大学の qianqian wang に授与されました!
#2. 分野の背景

#ビデオ動き推定の分野では、従来の手法は主にスパース特徴追跡と密オプティカル フローの 2 つのタイプに分類されます。どちらの方法もそれぞれのアプリケーションで効果的であることが証明されていますが、どちらもビデオ内の動きを完全にキャプチャすることはできません。ペアのオプティカル フローは長い時間ウィンドウ内の動きの軌跡をキャプチャできませんが、スパース トラッキングではすべてのピクセルの動きをモデル化できません
このギャップを埋めるために、多くの研究がビデオのピクセル軌跡の密集距離と長距離を同時に推定することを試みてきました。これらの研究の方法は、2 つのフレームのオプティカル フロー フィールドを単純にリンクすることから、複数のフレームにわたる各ピクセルの軌跡を直接予測することまでさまざまです。ただし、これらの方法は、動きを推定するときに限られたコンテキストのみを考慮し、時間または空間的に遠く離れた情報を無視することがよくあります。この近視眼性は、長い軌道での誤差の蓄積や、動き推定における時空間の不一致を引き起こす可能性があります。一部の方法は長期的なコンテキストを考慮していますが、依然として 2D ドメインで動作するため、オクルージョン イベントの追跡損失が発生する可能性があります。
全体として、ビデオにおける高密度で長距離の軌道推定は、この分野ではまだ未解決の問題です。この問題には 3 つの主要な課題が含まれます: 1) 長いシーケンスで軌道の精度を維持する方法、2) オクルージョン下のポイントの位置を追跡する方法、3) 時空間の一貫性を維持する方法
ここ この記事では、著者はは、ビデオ内のすべての情報を使用して各ピクセルの完全な動き軌跡を共同推定する、新しいビデオ動き推定方法を提案しました。この方法は「オムニモーション」と呼ばれ、擬似 3D 表現が使用されます。この表現では、標準 3D ボリュームが各フレームでローカル ボリュームにマッピングされます。このマッピングは、動的なマルチビュー ジオメトリの柔軟な拡張機能として機能し、カメラとシーンの動きを同時にシミュレートできます。この表現により、ループの一貫性が確保されるだけでなく、オクルージョン中のすべてのピクセルが追跡されます。作成者は、ビデオごとにこの表現を最適化し、ビデオ全体の動きに対するソリューションを提供します。最適化後、この表現をビデオの任意の連続座標でクエリして、ビデオ全体にわたるモーション軌跡を取得できます。
この記事で提案する方法では、次のことが可能です。 1) ビデオ全体のすべてのポイントに対して生成 グローバルに一貫性のある完全なモーション軌跡、2) オクルージョンによるポイントの追跡、3) さまざまなカメラとシーン アクションの組み合わせによる現実世界のビデオの処理。 TAP ビデオ追跡ベンチマークでは、この方法は以前の方法をはるかに上回り、良好なパフォーマンスを示しました。
3. 方法
この論文では、ビデオ シーケンスから密集した長距離の動きを推定するためのテスト時間の最適化に基づく方法を提案します。まず、この論文で提案されている方法の概要を説明します。
- Input: 著者の方法は、フレームのセットとノイズの多い動き推定のペア (オプティカル フローなど) を取得します。フィールド) を入力として使用します。
- メソッド操作: これらの入力を使用して、メソッドはビデオ全体の完全でグローバルに一貫したモーション表現を見つけようとします。
- 結果の特徴: 最適化後、この表現はビデオ内の任意のフレームの任意のピクセルでクエリできるため、ビデオ全体にわたってスムーズで正確なモーション軌跡が得られます。このメソッドは、ポイントがいつオクルージョンされるかを識別し、オクルージョンを通過するポイントを追跡することもできます。
- コアコンテンツ:
- OmniMotion表現: 後続のセクションでは、著者は最初に、と呼ばれる基本的な表現について説明します。オムニモーション用。
- 最適化プロセス: 次に、著者はビデオからこの表現を復元する方法の最適化プロセスについて説明します。
この方法は、包括的で一貫したビデオ モーション表現を提供し、オクルージョンなどの困難な問題を効果的に解決できます。さあ、
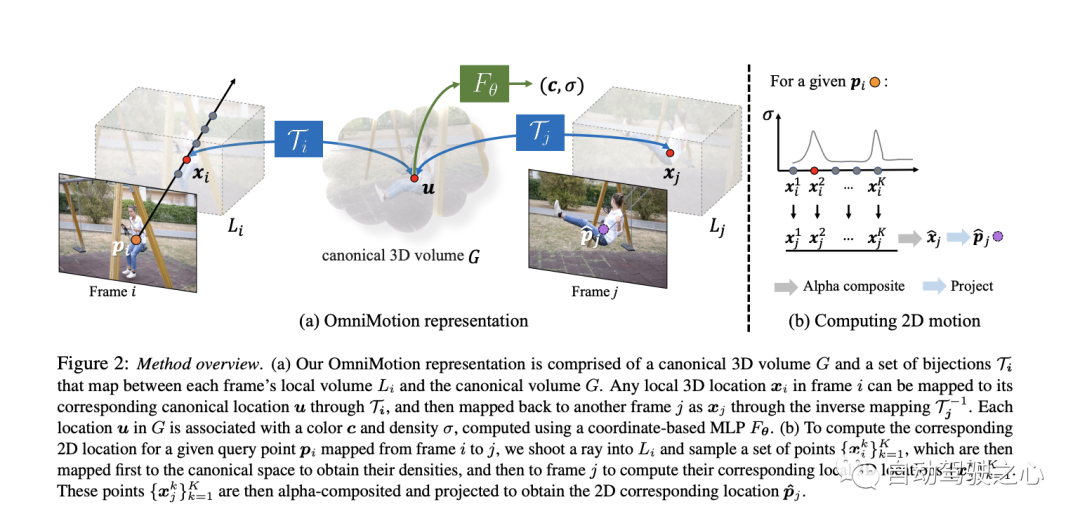
3.1 正準 3D ボリューム
ビデオ コンテンツは、G という名前の典型的なボリュームで表され、観察されたシーンの 3 次元マップとして機能します。 NeRF で行われたのと同様に、G #Map で各典型的な 3D 座標 uvw## に対して座標ベースのネットワーク nerf を定義しました。密度 σ と色 c。 G に保存されている密度は、表面が一般的な空間のどこにあるかを示します。 3D 全単射と組み合わせると、複数のフレームにわたってサーフェスを追跡し、オクルージョン関係を理解できるようになります。 G に保存されている色を使用すると、最適化中に測光損失を計算できます。
3.2 3D 全単射この記事では、 で示される連続全単射マッピングを紹介します。これは、3D 点をローカル座標系から標準 3D 座標系に変換します。この正準座標は、シーン ポイントまたは 3D 軌跡の時間における一貫した参照または「インデックス」として機能します。全単射マッピングを使用する主な利点は、すべてが同じ正準点から発生するため、異なるフレーム間の 3D 点に定期的な一貫性が提供されることです。 あるローカル フレームから別のローカル フレームの 3D ポイントへのマッピング方程式は次のとおりです。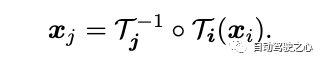
フレーム間の動きを再計算します。
このセクションでは、フレーム i のクエリピクセルの 2D モーションを計算する方法を説明します。直感的には、まずレイ上の点をサンプリングすることによってクエリ ピクセルが 3D に「リフト」され、次にこれらの 3D 点が全単射マッピング i とマッピング j を使用してターゲット フレーム j に「マッピング」され、その後、さまざまなサンプルからのアルファ合成が続きます。」は「レンダリング」され、最後に 2D に「投影」されて、想定される対応関係が得られます。
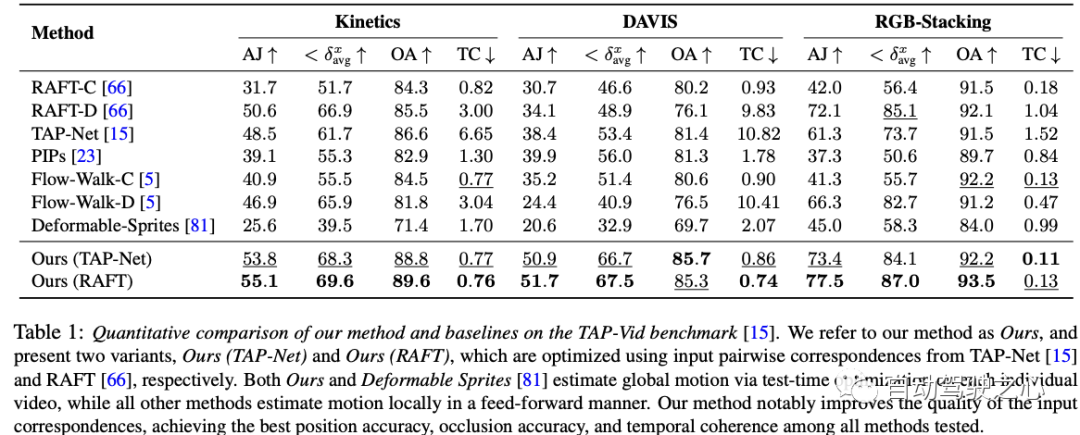 この実験データ表は、3 つのデータセットの結果を示しています。 - Kinetics、DAVIS、RGB-Stacking でのさまざまな動き推定方法のパフォーマンス。個々のメソッドのパフォーマンスを評価するには、AJ、avg、OA、TC の 4 つの指標が使用されます。著者らが提案した 2 つの手法 (弊社 (TAP-Net) と弊社 (RAFT)) に加えて、他に 7 つの手法があります。どちらの著者の手法も、ほとんどのメトリクスとデータセットで良好に機能することは注目に値します。具体的には、私たちの (RAFT) メソッドは、3 つのデータセットすべての AJ、avg、OA で最良の結果を達成し、TC では 2 番目に優れた結果を達成しました。私たちの (TAP-Net) 手法も、いくつかの測定において同様の優れたパフォーマンスを達成します。一方、他の方法では、これらのメトリックに対するパフォーマンスがまちまちです。著者の方法と「変形可能なスプライト」方法は、各ビデオのテスト時の最適化を通じてグローバル モーションを推定するのに対し、他のすべての方法は順方向アプローチを使用してローカルでモーション推定を実行することに注意してください。要約すると、著者の方法は、位置精度、咬合精度、および時間的連続性において、テストされた他のすべての方法を上回っており、大きな利点を示しています。
この実験データ表は、3 つのデータセットの結果を示しています。 - Kinetics、DAVIS、RGB-Stacking でのさまざまな動き推定方法のパフォーマンス。個々のメソッドのパフォーマンスを評価するには、AJ、avg、OA、TC の 4 つの指標が使用されます。著者らが提案した 2 つの手法 (弊社 (TAP-Net) と弊社 (RAFT)) に加えて、他に 7 つの手法があります。どちらの著者の手法も、ほとんどのメトリクスとデータセットで良好に機能することは注目に値します。具体的には、私たちの (RAFT) メソッドは、3 つのデータセットすべての AJ、avg、OA で最良の結果を達成し、TC では 2 番目に優れた結果を達成しました。私たちの (TAP-Net) 手法も、いくつかの測定において同様の優れたパフォーマンスを達成します。一方、他の方法では、これらのメトリックに対するパフォーマンスがまちまちです。著者の方法と「変形可能なスプライト」方法は、各ビデオのテスト時の最適化を通じてグローバル モーションを推定するのに対し、他のすべての方法は順方向アプローチを使用してローカルでモーション推定を実行することに注意してください。要約すると、著者の方法は、位置精度、咬合精度、および時間的連続性において、テストされた他のすべての方法を上回っており、大きな利点を示しています。
 これは、DAVIS のアブレーション実験結果の表です。データセット。アブレーション実験は、システム全体のパフォーマンスに対する各コンポーネントの寄与を検証するために実施されます。この表には 4 つの方法がリストされています。そのうち 3 つは特定の主要コンポーネントを削除したバージョンであり、最終的な「完全」バージョンにはすべてのコンポーネントが含まれています。
これは、DAVIS のアブレーション実験結果の表です。データセット。アブレーション実験は、システム全体のパフォーマンスに対する各コンポーネントの寄与を検証するために実施されます。この表には 4 つの方法がリストされています。そのうち 3 つは特定の主要コンポーネントを削除したバージョンであり、最終的な「完全」バージョンにはすべてのコンポーネントが含まれています。
- 不可逆: このバージョンでは、「可逆性」コンポーネントが削除されています。完全な方法と比較して、そのすべてのメトリクスは、特に AJ と で大幅に低下しており、可逆性がシステム全体で重要な役割を果たしていることがわかります。
- フォトメトリックなし: このバージョンでは、「フォトメトリック」コンポーネントが削除されています。 「完全」バージョンよりもパフォーマンスは低くなりますが、「不可逆」バージョンと比較するとパフォーマンスが向上します。これは、測光コンポーネントがパフォーマンスの向上に一定の役割を果たしているものの、その重要性は可逆コンポーネントに比べて低い可能性があることを示しています。
- 均一サンプリング: このバージョンでは、統一サンプリング戦略が使用されています。また、完全バージョンよりも若干パフォーマンスが劣りますが、それでも「不可逆性」バージョンや「アルミニウム」バージョンよりは優れています。
- 完全版: これは、すべてのコンポーネントを備えた完全版であり、すべてのメトリクスで最高のパフォーマンスを実現します。これは、各コンポーネントがパフォーマンスの向上に貢献していることを示しており、特にすべてのコンポーネントが統合されている場合、システムは最高のパフォーマンスを達成できます。
# 全体として、このアブレーション実験の結果は、各コンポーネントのパフォーマンスがある程度向上しているものの、可逆性が最も重要なコンポーネントである可能性があることを示しています。パフォーマンスの低下は非常に深刻です
5. ディスカッション

この作業で使用された DAVIS データセット 実行されたアブレーション実験は、提供されたものです。システム全体のパフォーマンスに対する各コンポーネントの重要な役割について貴重な洞察を得ることができます。実験結果から、可逆性コンポーネントが全体のフレームワークにおいて重要な役割を果たしていることが明確にわかります。この重要なコンポーネントが欠けていると、システムのパフォーマンスが大幅に低下します。これは、動的ビデオ分析における可逆性を考慮することの重要性をさらに強調しています。同時に、測光コンポーネントの損失もパフォーマンスの低下につながりますが、可逆性ほどパフォーマンスに大きな影響を与えるものではないようです。さらに、統合サンプリング戦略はパフォーマンスに一定の影響を与えますが、その影響は最初の 2 つに比べて比較的小さいです。最後に、完全なアプローチでは、これらすべてのコンポーネントが統合され、あらゆる考慮事項の下で達成可能な最高のパフォーマンスが示されます。全体として、この作業は、ビデオ分析のさまざまなコンポーネントがどのように相互作用するか、および全体的なパフォーマンスに対するそれらのコンポーネントの具体的な貢献についての洞察を得る貴重な機会を提供し、それによってビデオ処理アルゴリズムを設計および最適化する際の統合アプローチの必要性を強調します。
#しかし、多くの動き推定方法と同様に、私たちの方法は、高速で非常に非剛的な動きや小さな構造を処理するという困難に直面しています。これらのシナリオでは、ペアごとの対応方法では、正確なグローバル モーションを計算するための十分な信頼性の高い対応が得られない可能性があります。さらに、根底にある最適化問題の高度に非凸的な性質により、特定の難しいビデオでは、最適化プロセスが初期化に非常に敏感になる可能性があることが観察されています。これにより、最適化されていない極小値が発生する可能性があります。たとえば、サーフェスの順序が間違っていたり、正規空間内でオブジェクトが重複していたりします。これらは、最適化によって修正することが難しい場合があります。 最後に、この方法は現在の形式では計算コストが高くなる可能性があります。まず、フロー収集プロセスには、すべてのペアごとのフローの包括的な計算が含まれ、シーケンスの長さに応じて二次関数的に増加します。しかし、ボキャブラリー ツリーやキーフレーム ベースのマッチングなどのより効率的なマッチング方法を模索し、構造モーションや SLAM 文献からインスピレーションを得ることによって、このプロセスのスケーラビリティを改善できると考えています。第二に、ニューラル暗黙的表現を使用する他の方法と同様に、私たちの方法には比較的長い最適化プロセスが含まれます。この分野における最近の研究は、このプロセスを加速し、さらに長いシーケンスに拡張するのに役立つ可能性があります。6. 結論
この論文では、新しいテスト時間最適化手法を提案します。ビデオ全体で完全かつグローバルに一貫したモーションを推定します。 OmniMotion と呼ばれる新しいビデオ モーション表現が導入されました。これは、各フレームの準 3D 標準ボリュームとローカル正準全単射で構成されます。 OmniMotion は、さまざまなカメラ設定やシーン ダイナミクスを使用して通常のビデオを処理し、オクルージョンを通じて正確かつスムーズな長距離モーションを生成できます。以前の最先端の方法と比較して、定性的および量的の両方で大幅な改善が達成されています。
以上がタイトルリライト: ICCV 2023 優秀学生論文追跡、Github が 1.6K スターを獲得、魔法のような包括的な情報!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
最初のパイロットおよび重要な記事では、主に自動運転技術で一般的に使用されるいくつかの座標系と、それらの間の相関と変換を完了し、最終的に統合環境モデルを構築する方法を紹介します。ここでの焦点は、車両からカメラの剛体への変換 (外部パラメータ)、カメラから画像への変換 (内部パラメータ)、および画像からピクセル単位への変換を理解することです。 3D から 2D への変換には、対応する歪み、変換などが発生します。要点:車両座標系とカメラ本体座標系を平面座標系とピクセル座標系に書き換える必要がある 難易度:画像の歪みを考慮する必要がある 歪み補正と歪み付加の両方を画面上で補正する2. はじめに ビジョンシステムには、ピクセル平面座標系 (u, v)、画像座標系 (x, y)、カメラ座標系 ()、世界座標系 () の合計 4 つの座標系があります。それぞれの座標系には関係性があり、
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
原題: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 論文リンク: https://arxiv.org/pdf/2402.02519.pdf コードリンク: https://github.com/HKUST-Aerial-Robotics/SIMPL 著者単位: 香港科学大学DJI 論文のアイデア: この論文は、自動運転車向けのシンプルで効率的な動作予測ベースライン (SIMPL) を提案しています。従来のエージェントセントとの比較
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
