
 テクノロジー周辺機器
AI
画像とテキストの生成を統合する MiniGPT-5 が登場しました。トークンは Voken になり、モデルは書き込みを続けるだけでなく、自動的に画像を追加することもできます。
テクノロジー周辺機器
AI
画像とテキストの生成を統合する MiniGPT-5 が登場しました。トークンは Voken になり、モデルは書き込みを続けるだけでなく、自動的に画像を追加することもできます。
画像とテキストの生成を統合する MiniGPT-5 が登場しました。トークンは Voken になり、モデルは書き込みを続けるだけでなく、自動的に画像を追加することもできます。

大規模モデルは言語と視覚の間を飛躍させており、テキストと画像のコンテンツをシームレスに理解して生成することを約束しています。最近の一連の研究によると、マルチモーダル機能の統合は成長傾向であるだけでなく、すでにマルチモーダルな会話からコンテンツ作成ツールに至るまで重要な進歩をもたらしています。大規模な言語モデルは、テキストの理解と生成において比類のない機能を実証しています。ただし、一貫したテキストの物語を含む画像を同時に生成することはまだ開発の余地があります。
最近、カリフォルニア大学サンタクルーズ校の研究チームは、MiniGPT-5 に基づく手法を提案しました。 「生成投票」の概念に基づく革新的なインターリーブ視覚言語生成技術。

- 論文アドレス: https://browse.arxiv.org/pdf /2310.02239v1.pdf
- プロジェクトアドレス: https://github.com/eric-ai-lab/MiniGPT-5
MiniGPT-5 は、特別なビジュアル トークン「生成投票」を通じて安定した拡散メカニズムと LLM を組み合わせることで、熟練したマルチモーダル生成への道を示します。モデル。同時に、この記事で提案されている 2 段階のトレーニング方法では、記述のない基本段階の重要性が強調されており、データが不足している場合でもモデルを成功させることができます。このメソッドの一般的な段階ではドメイン固有のアノテーションが必要ないため、このソリューションは既存のメソッドとは異なります。生成されたテキストと画像が調和していることを保証するために、この記事の二重損失戦略が機能し、生成投票方法と分類方法がこの効果をさらに強化します。これらのテクニックに基づいて、この作品は変革的なアプローチを示しています。研究チームは、ViT (Vision Transformer) と Qformer、および大規模な言語モデルを使用することで、マルチモーダル入力を生成投票に変換し、それらを高解像度の Stable Diffusion2.1 とシームレスに組み合わせて、コンテキストを意識した画像生成を実現しました。この論文では、補助入力としての画像を命令調整方法と組み合わせ、テキストと画像の生成損失の使用を先駆的に行い、それによってテキストと視覚の間の相乗効果を拡大します
MiniGPT-5 と CLIP 制約などモデルは照合され、拡散モデルは MiniGPT-4 と巧みに統合され、ドメイン固有のアノテーションに依存することなく、より優れたマルチモーダルな結果が得られます。最も重要なことは、私たちの戦略はマルチモーダル視覚言語の基本モデルの進歩を活用し、マルチモーダル生成機能を強化するための新しい青写真を提供できることです。
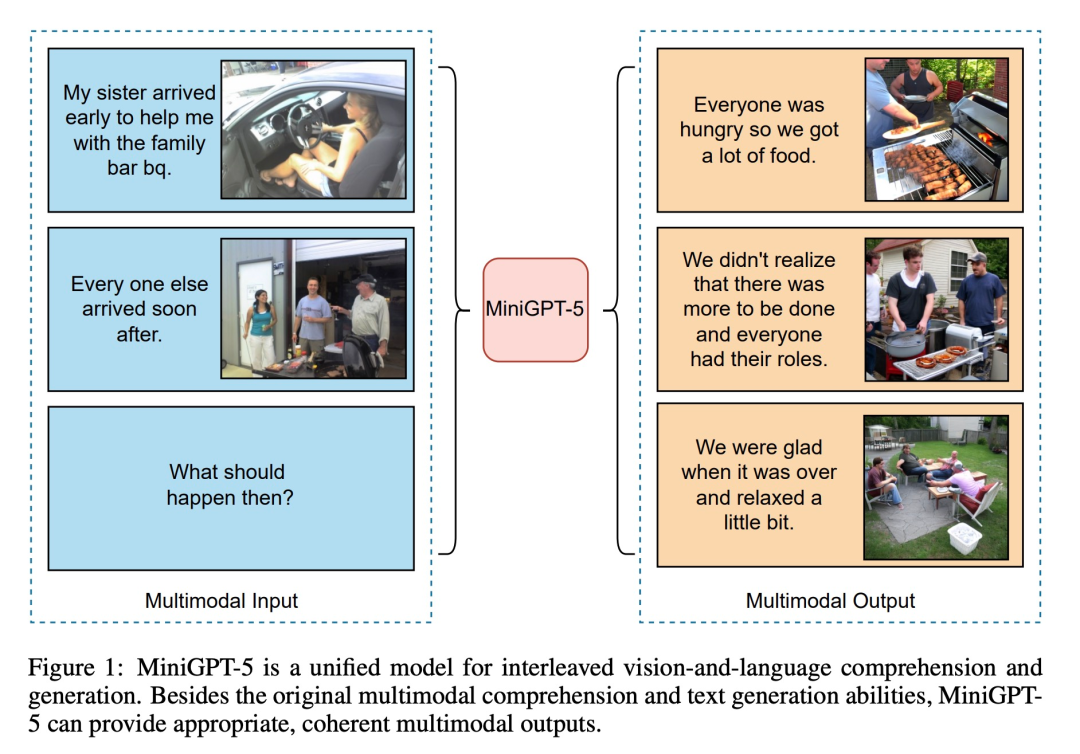
#以下の図に示すように、元のマルチモーダル理解機能とテキスト生成機能に加えて、MiniGPT5 は合理的で一貫したマルチモーダル出力も提供できます。
#この記事の貢献は 3 つの側面に反映されています。
は、説明不要のマルチモーダル生成のための新しい 2 段階のトレーニング戦略に焦点を当てています。シングルモーダル位置合わせステージは、多数のテキストと画像のペアから高品質のテキスト位置合わせされた視覚特徴を取得します。マルチモーダル学習フェーズには、新しいトレーニング タスク、プロンプト コンテキストの生成が含まれており、視覚的プロンプトとテキスト プロンプトが適切に調整されて生成されるようにします。トレーニング段階で分類子を使用しないガイダンスを追加すると、生成の品質がさらに向上します。
- 他のマルチモーダル生成モデルと比較して、MiniGPT-5 は CC3M データセットで最先端のパフォーマンスを実現します。 MiniGPT-5 は、VIST や MMDialog などのよく知られたデータセットに対する新しいベンチマークも確立します。
- #次に、この研究の内容について詳しく見ていきましょう
- ##方法論の概要
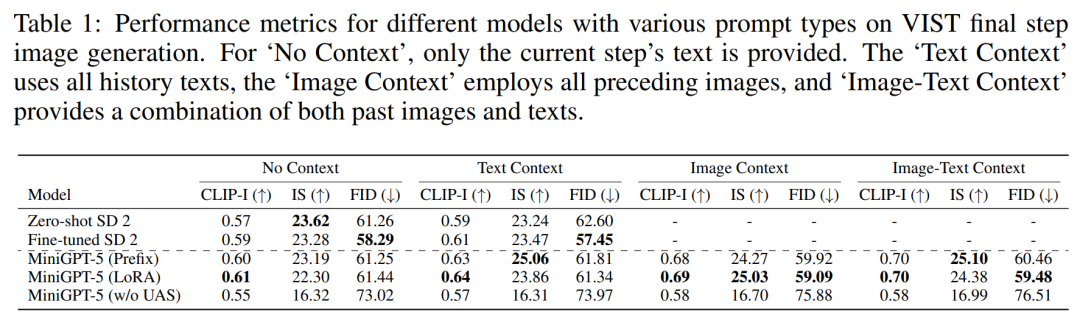
#マルチモーダル入力ステージ マルチモーダル大規模モデル ( MiniGPT-4 は主にマルチモーダルの理解に焦点を当てており、画像を連続入力として処理できます。その機能をマルチモーダル生成に拡張するために、研究者は、視覚的特徴を出力するために特別に設計された生成 Voken を導入しました。さらに、マルチモーダル出力学習のための大規模言語モデル (LLM) フレームワーク内でパラメーター効率の高い微調整手法も採用しました。 マルチモーダル出力生成 生成トークンが生成モデルと正確に位置合わせされていることを確認するために、研究者らは次元マッチングのためのコンパクトなマッピング モジュールを開発し、テキストの空間損失と潜在的な拡散を含むいくつかの教師付き損失を導入しました。モデルの損失。テキストスペースの損失は、モデルがトークンの位置を正確に学習するのに役立ちますが、潜在的な拡散損失はトークンを適切な視覚的特徴と直接位置合わせします。生成記号の特徴は画像によって直接ガイドされるため、この方法は完全な画像の説明を必要とせず、説明不要の学習を実現します ##テキスト ドメインと画像ドメインの間に無視できないドメイン シフトがあることを考慮すると、研究者らは、限定されたインターリーブされたテキストと画像のデータセットを直接トレーニングすると、位置ずれが発生する可能性があることを発見しました。画質が劣化します。 したがって、彼らはこの問題を軽減するために 2 つの異なるトレーニング戦略を使用しました。最初の戦略では、拡散プロセス全体を通じて生成されたトークンの有効性を向上させるために、分類子を使用しないブートストラップ手法を採用します。2 番目の戦略は、大まかな特徴の位置合わせに焦点を当てた最初の事前トレーニング フェーズと、それに続く微調整フェーズの 2 つのフェーズで展開されます。複雑な特徴の学習について。 実験と結果 MiniGPT-5 は信頼できる画像と妥当なテキストを生成できますか? 提案されたモデルの一般性と堅牢性を実証するために、視覚 (画像関連のメトリクス) と言語 (テキストのメトリクス) の両方の領域をカバーして評価しました VIST 最終ステップ評価 実験の最初のセットには、単一ステップの評価が含まれます。つまり、最後のステップでプロンプト モデルに従って対応する画像が生成され、その結果が表 1 に示されています。 MiniGPT-5 は、3 つの設定すべてにおいて、微調整された SD 2 よりも優れたパフォーマンスを発揮します。特に、MiniGPT-5 (LoRA) モデルの CLIP スコアは、特に画像とテキストのプロンプトを組み合わせた場合に、複数のプロンプト タイプにわたって他のバリアントよりも一貫して優れています。一方、FID スコアは MiniGPT-5 (プレフィックス) モデルの競争力を強調しており、画像の埋め込み品質 (CLIP スコアに反映される) と画像の多様性と信頼性 (CLIP スコアに反映される) の間にトレードオフがある可能性があることを示しています。 FID スコア)。単一モダリティ登録ステージを含まずに VIST 上で直接トレーニングされたモデル (UAS なしの MiniGPT-5) と比較すると、モデルは意味のある画像を生成する能力を保持していますが、画像の品質と一貫性は大幅に低下します。この観察は、2 段階のトレーニング戦略の重要性を強調しています
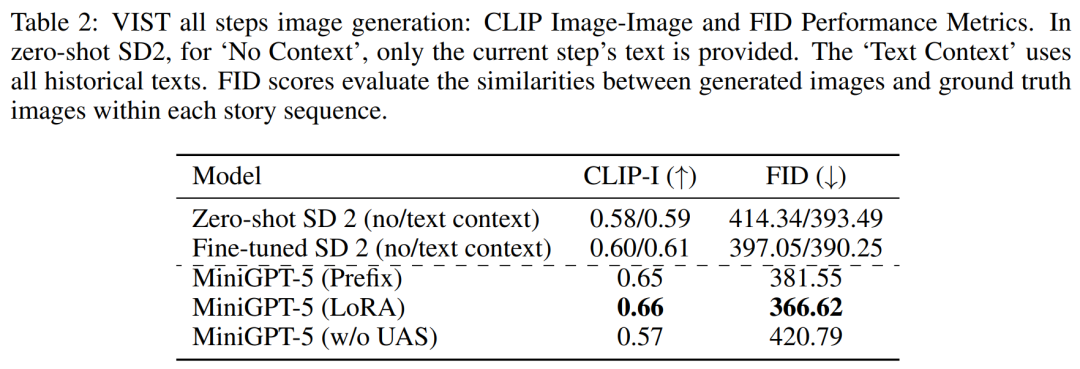
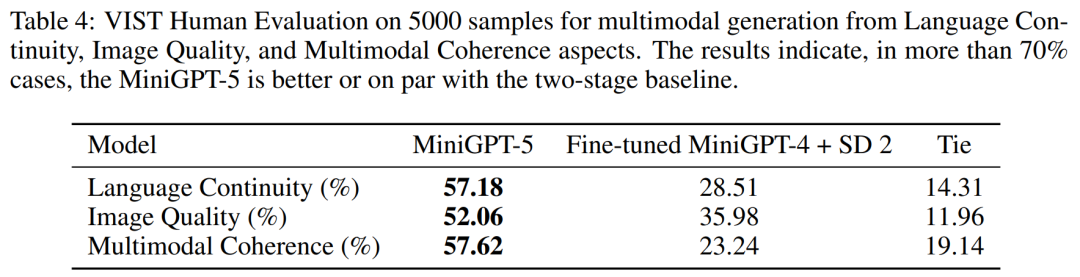
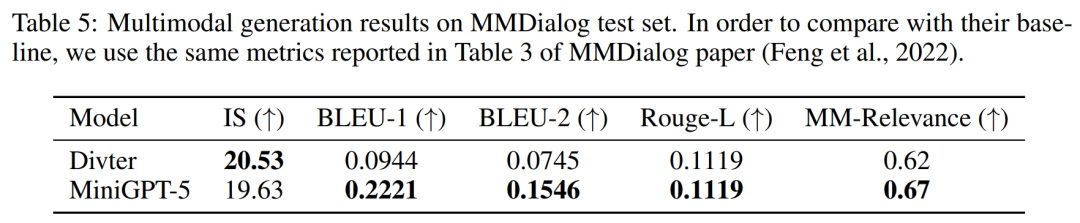
##VIST の複数段階の評価 より詳細かつ包括的な評価では、研究者はモデルに以前の歴史的コンテキストを体系的に提供し、その後、各ステップで生成されたデータを評価しました。 。 表 2 と 3 は、これらの実験の結果をまとめたもので、それぞれ画像と言語のメトリックに関するパフォーマンスの概要を示しています。実験結果は、MiniGPT-5 がロングレベルのマルチモーダル入力キューを利用して、元のモデルのマルチモーダル理解機能を損なうことなく、すべてのデータにわたって一貫した高品質の画像を生成できることを示しています。これは、さまざまな環境における MiniGPT-5 の有効性を強調しています ##VIST 人間による評価 表 4 に示すように、MiniGPT-5 は 57.18% のケースで更新を生成しました。 52.06% のケースでより良い画質を提供し、57.62% のシーンでより一貫性のあるマルチモーダル出力を生成しました。仮定法を使わずにテキストから画像へのプロンプトナレーションを採用した 2 段階のベースラインと比較して、これらのデータは、その強力なマルチモーダル生成機能を明らかに示しています。 ##によると表 5 の結果は、MiniGPT-5 がテキスト返信の生成においてベースライン モデル Divter よりも正確であることを示しています。生成された画像は同様の品質ですが、MiniGPT-5 は MM 相関においてベースライン モデルを上回っており、画像生成を適切に配置し、一貫性の高いマルチモーダル応答を生成する方法をよりよく学習できることを示唆しています
##下の図 9 は、MiniGPT-5 と MMDialog テスト セットを示しています。ベースラインモデルの比較。
研究の詳細については、元の論文を参照してください。 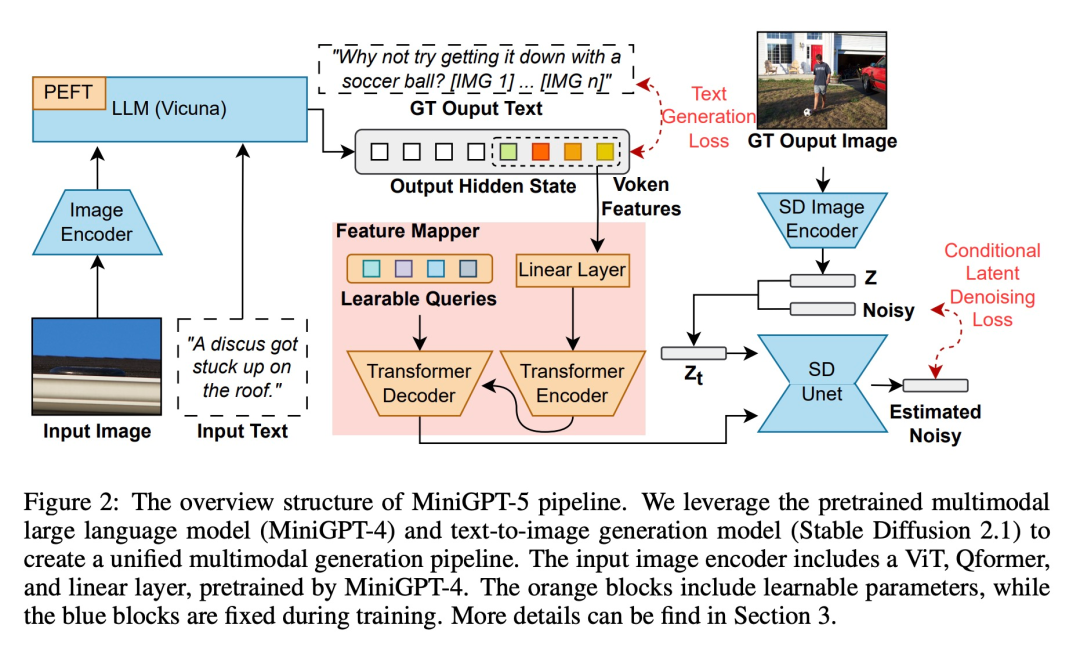
モデルの有効性を評価するために、研究者は複数のベンチマークを選択し、一連の評価を実施しました。実験の目的は、いくつかの重要な質問に対処することです:


 MiniGPT-5 の出力を見て、それがどれほど効果的であるかを見てみましょう。以下の図 7 は、MiniGPT-5 と CC3M 検証セットのベースライン モデルとの比較を示しています。
MiniGPT-5 の出力を見て、それがどれほど効果的であるかを見てみましょう。以下の図 7 は、MiniGPT-5 と CC3M 検証セットのベースライン モデルとの比較を示しています。 以下の図 8 は、 MiniGPT-5 と VIST 検証セット間のベースライン モデルの比較
以下の図 8 は、 MiniGPT-5 と VIST 検証セット間のベースライン モデルの比較

以上が画像とテキストの生成を統合する MiniGPT-5 が登場しました。トークンは Voken になり、モデルは書き込みを続けるだけでなく、自動的に画像を追加することもできます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1657
1657
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
DDREASE は、ハード ドライブ、SSD、RAM ディスク、CD、DVD、USB ストレージ デバイスなどのファイル デバイスまたはブロック デバイスからデータを回復するためのツールです。あるブロック デバイスから別のブロック デバイスにデータをコピーし、破損したデータ ブロックを残して正常なデータ ブロックのみを移動します。 ddreasue は、回復操作中に干渉を必要としないため、完全に自動化された強力な回復ツールです。さらに、ddasue マップ ファイルのおかげでいつでも停止および再開できます。 DDREASE のその他の主要な機能は次のとおりです。 リカバリされたデータは上書きされませんが、反復リカバリの場合にギャップが埋められます。ただし、ツールに明示的に指示されている場合は切り詰めることができます。複数のファイルまたはブロックから単一のファイルにデータを復元します
 Excelのフィルター機能を複数条件で使う方法
Feb 26, 2024 am 10:19 AM
Excelのフィルター機能を複数条件で使う方法
Feb 26, 2024 am 10:19 AM
Excel で複数の条件によるフィルタリングを使用する方法を知る必要がある場合は、次のチュートリアルで、データを効果的にフィルタリングおよび並べ替えできるようにするための手順を説明します。 Excel のフィルタリング機能は非常に強力で、大量のデータから必要な情報を抽出するのに役立ちます。設定した条件でデータを絞り込み、条件に合致した部分のみを表示することができ、データ管理を効率化できます。フィルター機能を利用すると、目的のデータを素早く見つけることができ、データの検索や整理の時間を節約できます。この機能は、単純なデータ リストに適用できるだけでなく、複数の条件に基づいてフィルタリングすることもできるため、必要な情報をより正確に見つけることができます。全体として、Excel のフィルタリング機能は非常に実用的です。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
Alibaba 7B マルチモーダル文書理解の大規模モデルが新しい SOTA を獲得
Apr 02, 2024 am 11:31 AM
マルチモーダル文書理解機能のための新しい SOTA!アリババの mPLUG チームは、最新のオープンソース作品 mPLUG-DocOwl1.5 をリリースしました。これは、高解像度の画像テキスト認識、一般的な文書構造の理解、指示の遵守、外部知識の導入という 4 つの主要な課題に対処するための一連のソリューションを提案しています。さっそく、その効果を見てみましょう。複雑な構造のグラフをワンクリックで認識しMarkdown形式に変換:さまざまなスタイルのグラフが利用可能:より詳細な文字認識や位置決めも簡単に対応:文書理解の詳しい説明も可能:ご存知「文書理解」 「」は現在、大規模な言語モデルの実装にとって重要なシナリオです。市場には文書の読み取りを支援する多くの製品が存在します。その中には、主にテキスト認識に OCR システムを使用し、テキスト処理に LLM と連携する製品もあります。
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
