

新しいタイトル: ADAPT: エンドツーエンドの自動運転の説明可能性の予備調査

この記事は自動運転ハート公式アカウントの許可を得て転載しておりますので、転載については転載元にご連絡ください。
著者の個人的な考え
エンドツーエンドは今年非常に人気のある方向性であり、今年の CVPR 最優秀論文も受賞しました。ただし、エンドツーエンドには、解釈可能性の低さ、収束トレーニングの難しさなど、多くの問題もあります。エンドツーエンドの解釈可能性を共有します。最新の説明作品は ADAPT です。このメソッドは、Transformer アーキテクチャに基づいており、マルチタスクの共同トレーニングを通じて、車両の動作の説明と各決定の推論をエンドツーエンドで出力します。 ADAPT に関する著者の考えの一部は次のとおりです:
- ここでは、ビデオの 2D 特徴を使用した予測を示します。2D 特徴を 2D 特徴に変換した後、効果がより良くなる可能性があります。 bev 機能です。
- LLM と組み合わせると、効果がさらに高まる可能性があります。たとえば、テキスト生成部分は LLM に置き換えられます。
- 現在の作業は、歴史的なビデオを入力として使用することです。予測されたアクションとその説明も歴史的なものです。将来のアクションとそのアクションに対応する原因を予測することの方が意味があるかもしれません。
- 画像をトークン化した トークンは少し多すぎます。役に立たない情報がたくさんあるかもしれません。Token-Learner を試してみるとよいでしょう。
出発点は何ですか?
エンドツーエンドの自動運転は運輸業界において大きな可能性を秘めており、現在この分野の研究が盛んに行われています。例えば、CVPR2023の最優秀論文であるUniADは、エンドツーエンドの自動運転を行っています。しかし、自動化された意思決定プロセスの透明性と説明可能性の欠如は、その発展を妨げるでしょう 結局のところ、道路を走行する実際の車両にとって安全性は最優先事項です。モデルの解釈可能性を向上させるためにアテンション マップやコスト ボリュームを使用するという初期の試みがいくつかありましたが、これらの方法を理解するのは困難です。したがって、この研究の出発点は、意思決定を説明するわかりやすい方法を見つけることです。下の図はいくつかの方法を比較したものですが、明らかに言葉で見た方が理解しやすいです。
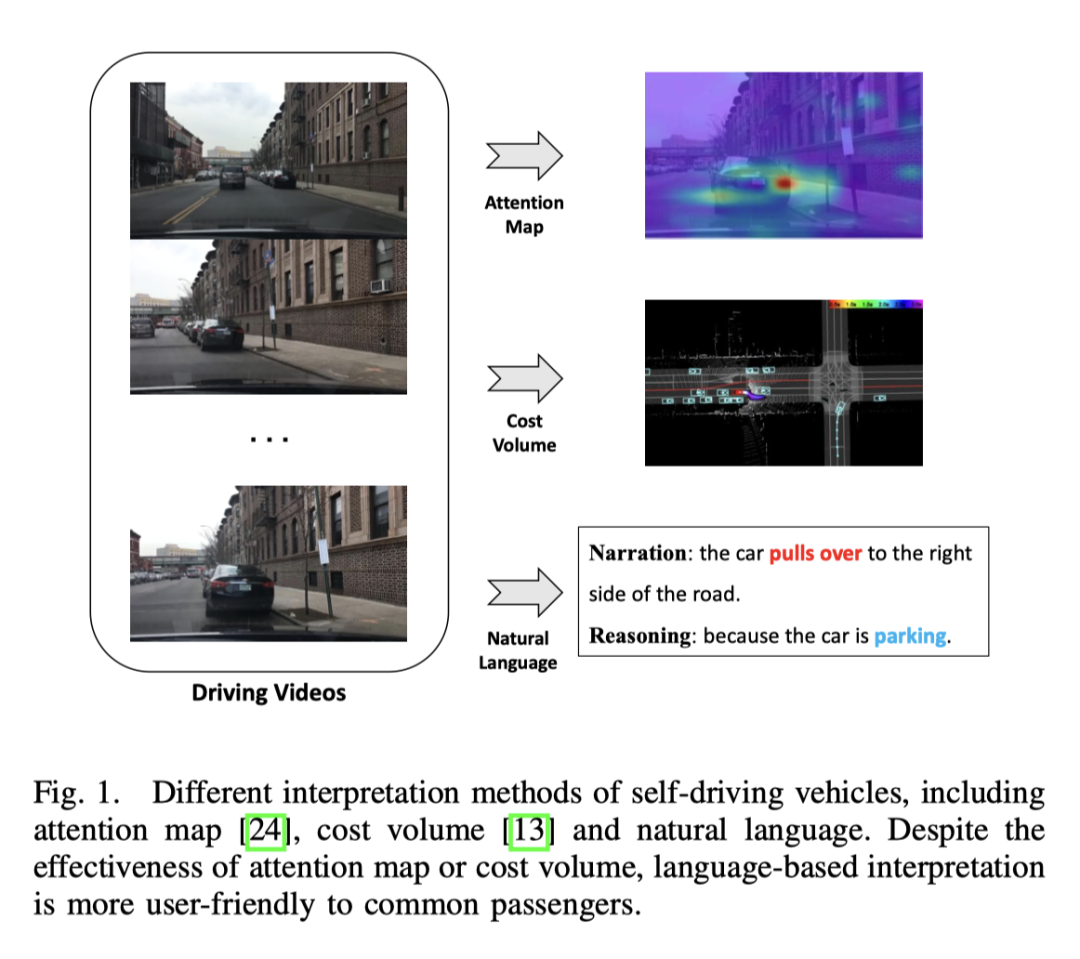
ADAPT の利点は何ですか?
- 車両の動作の説明と各決定の理由をエンドツーエンドで出力できます;
- この方法は、変圧器ネットワーク構造に基づいており、次のように組み合わせられます。トレーニング;
- BDD-X (Berkeley DeepDrive eXplanation) データ セットで SOTA 効果を達成;
- 実際のシナリオでシステムの有効性を検証するために、展開可能な一連のこのシステムは、オリジナルのビデオを入力し、アクションの説明と推論をリアルタイムで出力できます。
##エフェクト表示
#効果は依然として非常に優れており、特に3番目の暗い夜のシーン、信号機が注目されました。 
この分野の現在の進捗状況
ビデオキャプション
ビデオ説明の主な目的は、特定のビデオを次の形式で説明することです。自然言語 オブジェクトとその関係。初期の研究では、特定の要素を固定テンプレートに埋め込むことで、特定の構文構造を持つ文が生成されていましたが、柔軟性に欠け、豊かさに欠けていました。
柔軟な構文構造を持つ自然な文を生成するために、いくつかの方法ではシーケンス学習技術を使用します。具体的には、これらのメソッドはビデオ エンコーダを使用して特徴を抽出し、言語デコーダを使用して視覚的なテキストの配置を学習します。説明をより豊かにするために、これらのメソッドはオブジェクト レベルの表現も利用して、ビデオ内で詳細なオブジェクト認識インタラクション機能を取得します。既存のアーキテクチャは一般的なビデオ キャプションの方向で一定の結果を達成しましたが、アクションに直接適用することはできません。なぜなら、単純にビデオの説明を自動運転アクションの表現に転送すると、自動運転タスクにとって重要な車速などの重要な情報が失われるからです。このマルチモーダルな情報を効果的に利用して文章を生成する方法はまだ研究中です。 PaLM-E は、マルチモーダルな文で優れた仕事をします。エンドツーエンドの自動運転
学習ベースの自動運転は、活発な研究分野です。最近の CVPR2023 の最優秀論文である UniAD (その後の FusionAD を含む)、および Wayve の World モデルベースの作品 MILE はすべて、この方向の研究です。出力形式には、UniAD のような軌道ポイントと、MILE のような直接の車両動作が含まれます。
さらに、車両、自転車、歩行者などの交通参加者の将来の行動をモデル化して車両のウェイポイントを予測する方法もあれば、センサー入力から直接車両の制御を予測する方法もあります。この作業の予測サブタスク自動運転の解釈可能性
自動運転の分野では、ほとんどの解釈可能方法は視覚に基づいており、一部は LiDAR の作業に基づいています。一部の方法では、アテンション マップを利用して重要でない画像領域を除外し、自動運転車の動作が合理的で説明可能に見えるようにします。ただし、アテンション マップには、それほど重要ではない領域が含まれる場合があります。 LIDAR と高精度地図を入力として使用し、他の交通参加者の境界ボックスを予測し、オントロジーを利用して意思決定推論プロセスを説明する方法もあります。さらに、HD マップへの依存を減らすために、セグメンテーションを通じてオンライン マップを構築する方法もあります。ビジョンまたは LIDAR ベースの方法では良好な結果が得られますが、口頭での説明が不足しているため、システム全体が複雑で理解しにくいように見えます。研究では、ビデオの特徴をオフラインで抽出して制御信号を予測し、ビデオ説明のタスクを実行することで、自動運転車のテキスト解釈の可能性を初めて調査しています。
自動運転におけるマルチタスク学習
このエンドツーエンドのフレームワークは、マルチタスク学習を使用して、テキスト生成と予測制御信号の 2 つのタスクでモデルを共同トレーニングします。マルチタスク学習は自動運転に広く使用されています。データ活用の向上と機能の共有により、異なるタスクを共同トレーニングすることで各タスクのパフォーマンスが向上するため、本研究では制御信号予測とテキスト生成の 2 つのタスクの共同トレーニングを使用します。
ADAPT メソッド
次はネットワーク構造図です。
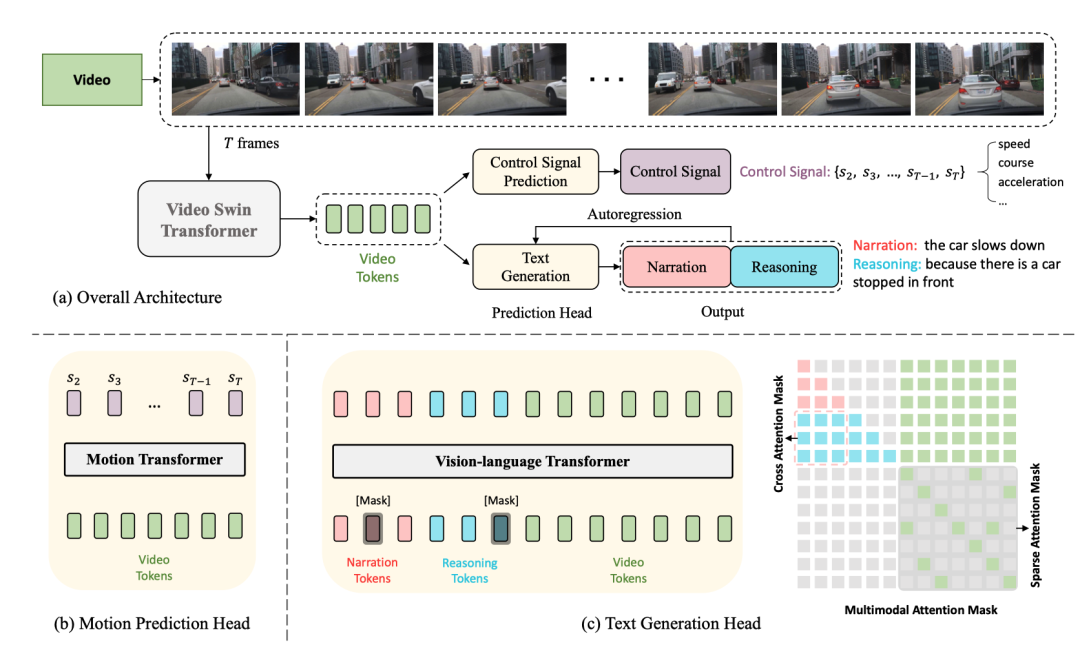
全体構造は 2 つに分かれていますタスク:
- 運転キャプション生成 (DCG): ビデオを入力し、2 つの文を出力します。最初の文は車の動作を説明し、2 番目の文はこの動作を実行する理由を説明します。信号が青になったため、車は加速しています。"
- 制御信号予測 (CSP): 同じビデオを入力し、速度、方向、加速度などの一連の制御信号を出力します。
そのうち、DCG と CSP の 2 つのタスクはビデオ エンコーダーを共有しますが、異なる予測ヘッドを使用して異なる最終出力を生成します。
DCG タスクでは、ビジョン言語変換エンコーダーを使用して 2 つの自然言語文を生成します。
CSP タスクの場合、モーション変換エンコーダを使用して制御信号のシーケンスを予測します
ビデオ エンコーダ
ビデオ スイング トランスフォーマは、ここで入力に使用されます。ビデオ フレームはビデオ特徴トークンに変換されます。
Input zhenimage、形状は 、フィーチャのサイズは 、ここで はフィーチャの寸法ですチャネル .
予測ヘッド
テキスト生成ヘッド
上記の機能 はトークン化後に取得されます。 寸法 のビデオ トークンを作成し、MLP を使用してテキスト トークンの埋め込みに合わせて寸法を調整し、テキスト トークンとビデオ トークンを一緒にビジョンにフィードします。アクションを生成するための言語変換エンコーダ 説明と推論。
制御信号予測ヘッド
は、入力 フレーム ビデオに対応します。制御信号 の出力があります。 CSP ヘッド Yes 。各制御信号は必ずしも 1 次元である必要はなく、速度、加速度、方向などを同時に含むなど、多次元にすることもできます。ここでのアプローチは、ビデオ特徴をトークン化し、モーション トランスフォーマーを通じて一連の出力信号を生成することです。損失関数は MSE、
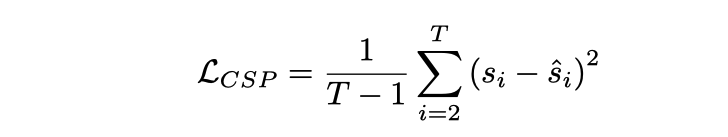
であることに注意してください。いいえ 最初のフレームでは動的情報が少なすぎるため、最初のフレームが含まれます
共同トレーニング
このフレームでは、共有ビデオ エンコーダのため、実際にはCSP と DCG の 2 つのタスクがビデオ表現のレベルで連携していると仮定しました。出発点は、動作記述と制御信号の両方がきめ細かい車両動作の異なる表現であり、動作推論の説明は主に車両動作に影響を与える運転環境に焦点を当てているということです。
共同トレーニングをトレーニングに使用する
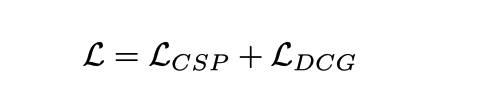
共同トレーニングの場所ですが、推論中に独立して実行できることに注意してください。CSP タスクわかりやすい フローチャートに従って映像を直接入力して制御信号を出力するだけ DCGタスクは映像を直接入力して説明と推論を出力 テキストの生成は自己回帰手法に基づいており、ワードごとに行われる[CLS ] の単語が [SEP] で終わるか、長さのしきい値に達しています。
実験計画と比較
データ セット
使用されたデータ セットは BDD-X です。このデータ セットには 7000 セグメントが含まれています。ビデオ信号と制御信号。各ビデオの長さは約 40 秒、画像サイズは 、周波数は FPS です。各ビデオには、加速、右折、合流などの 1 ~ 5 つの車両の動作が含まれています。これらのアクションはすべて、アクションの説明 (例: 「車が停止した」) や推論 (例: 「信号が赤だから」) を含むテキストで注釈が付けられます。合計で約 29,000 の動作アノテーションのペアがあります。
具体的な実装の詳細
- ビデオ swin トランスフォーマーは Kinetics-600 で事前トレーニングされています
- ビジョン言語トランスフォーマーとモーション トランスフォーマーはランダムです初期化された
- には固定ビデオ swin パラメーターがないため、全体がエンドツーエンドのトレーニングになります。
- 入力ビデオ フレーム サイズはサイズ変更およびトリミングされ、ネットワークへの最終入力となります。は 224x224
- 説明と推論には、単語全体ではなく WordPiece 埋め込み [75] を使用します (例: 「stops」は「stop」と「#s」に切り取られます)。各文の最大長は次のとおりです。 15
- トレーニング中、マスクされた言語モデリングはトークンの 50% をランダムにマスクします。各マスク トークンには [MASK] トークンになる確率が 80%、単語がランダムに選択される確率が 10% あります。残りの 10% の確率は変わりません。
- AdamW オプティマイザーが使用されており、トレーニング ステップの最初の 10% にはウォームアップ メカニズムがあります
- 4 つの V100 GPU でのトレーニングには約 13 時間かかります
共同トレーニングの効果
ここでは、共同トレーニングの有効性を示すために比較された 3 つの実験を示します。
Single
CSP タスクを削除し、DCG タスクのみを保持することを指します。これは、キャプション モデルのトレーニングのみに相当します。
Single
CSP タスクはまだ存在しませんが、DCG モジュールに入るときに、ビデオマークに加えて、制御信号マークも入力する必要があります
効果の比較は次のとおりです
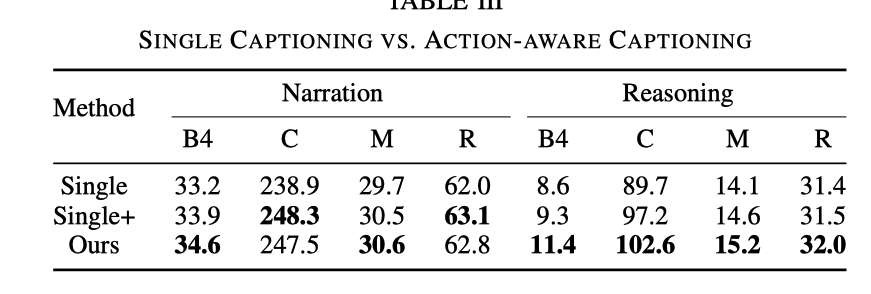
DCGタスクのみとの比較、ADAPT の推論効果は大幅に優れています。制御信号入力があると効果は向上しますが、CSPタスクを追加した場合の効果には及びません。 CSP タスクを追加した後、ビデオを表現し理解する能力が強化されました。
さらに、以下の表は、CSP に対する共同トレーニングの効果も向上していることを示しています。

ここで は精度と理解できます。具体的には、予測された制御信号が切り捨てられます。式は次のとおりです。
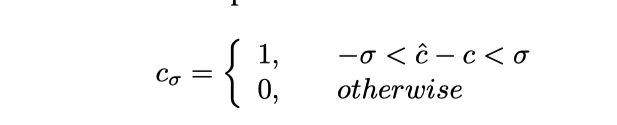
さまざまな種類の制御信号の影響
実験では、速度と機首方位が基本的な信号として使用されます。ただし、実験により、信号の 1 つだけを使用した場合、効果は両方の信号を同時に使用した場合ほど良くないことが判明しました。具体的なデータを次の表に示します。
##これは、速度と方向の 2 つの信号が、ネットワークがアクションの説明と推論をよりよく学習するのに役立つことを示しています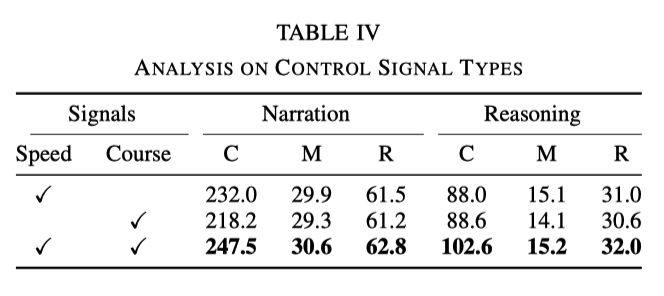
比較一般的な記述タスクでは、運転記述タスクの生成は、動作記述と推論の 2 つの文で構成されます。それは次の表からわかります:
行 1 と行 3 は、クロス アテンションを使用した効果がより優れていることを示しており、理解しやすいです。説明に基づく推論はモデルのトレーニングに役立ちます。 2 行目と 3 行目は、推論と説明を交換する順序も失われ、推論が記述に依存していることを示しています;- 次の 3 行を比較すると、説明のみを出力し、推論のみを出力します両方です。両方を出力する場合ほど効果は高くありません。
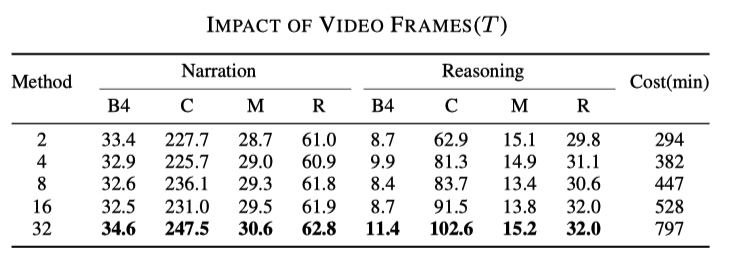
サンプリング レートの影響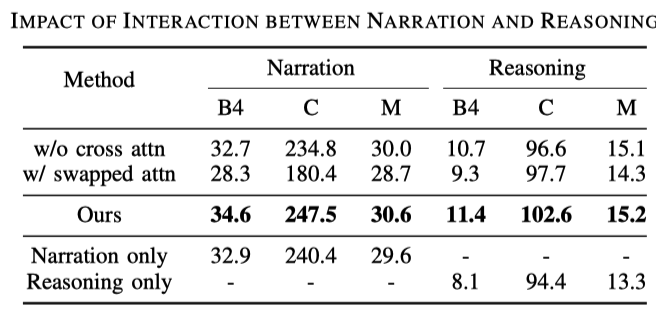
これ結果は推測できます。使用するフレームが多いほど、結果は良くなりますが、次の表に示すように、対応する速度も遅くなります
 ##必須 書き換えられた内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/MSTyr4ksh0TOqTdQ2WnSeQ
##必須 書き換えられた内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/MSTyr4ksh0TOqTdQ2WnSeQ
以上が新しいタイトル: ADAPT: エンドツーエンドの自動運転の説明可能性の予備調査の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7455
7455
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
原題: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 論文リンク: https://arxiv.org/pdf/2402.02519.pdf コードリンク: https://github.com/HKUST-Aerial-Robotics/SIMPL 著者単位: 香港科学大学DJI 論文のアイデア: この論文は、自動運転車向けのシンプルで効率的な動作予測ベースライン (SIMPL) を提案しています。従来のエージェントセントとの比較
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
