

4D 画像レーダーと 3D マルチターゲット追跡を組み合わせるにはどうすればよいですか? TBD-EOT が答えかもしれません!

皆さん、こんにちは。自動運転の中心部からのご招待をいただき、誠にありがとうございます。ここで私たちの取り組みを皆さんと共有できることを光栄に思います。
高度な運転支援におけるオンライン 3D マルチオブジェクト トラッキング (MOT) テクノロジーシステム (ADAS) 自動運転 (AD) において重要な応用価値があります。近年、高性能の 3 次元認識に対する業界の需要が高まり続けるにつれ、オンライン 3D MOT アルゴリズムがますます広範な研究と注目を集めるようになりました。 4D ミリ波レーダー (4D イメージング レーダーとも呼ばれます) または LIDAR 点群データの場合、ADAS および AD 分野で現在使用されているオンライン 3D MOT アルゴリズムのほとんどは、ポストターゲット トラッキング (TBD-POT) フレームワークを採用しています。検出追跡戦略。しかし、もう 1 つの重要な MOT フレームワークである統合検出追跡戦略 (JDT-EOT) に基づく拡張オブジェクト追跡は、ADAS および AD 分野では十分に研究されていません。この記事では、実際のオンライン 3D MOT アプリケーション シナリオにおける TBD-POT、JDT-EOT、および当社が提案する TBD-EOT フレームワークのパフォーマンスを初めて体系的に説明し、分析します。特に、このペーパーでは、View-of-Delft (VoD) および TJ4DRadSet データセットの 4D イメージング レーダー点群データに対する 3 つのフレームワークの SOTA 実装のパフォーマンスを評価および比較します。実験結果は、従来の TBD-POT フレームワークには、計算の複雑さが低く、追跡パフォーマンスが高いという利点があり、依然として 3D MOT タスクの最初の選択肢として使用できることを示しています; 同時に、この記事で提案されている TBD-EOT フレームワーク特定のシナリオで TBD-EOT を超える能力がある POT フレームワークの可能性。最近学術界の注目を集めている JDT-EOT フレームワークは、ADAS および AD シナリオではパフォーマンスが低いことは注目に値します。この記事では、さまざまなパフォーマンス評価指標に基づいて上記の実験結果を分析し、実際のアプリケーション シナリオにおけるアルゴリズム追跡パフォーマンスを向上させるための可能な解決策を提供します。 4D イメージング レーダーに基づくオンライン 3D MOT アルゴリズムについて、上記の研究は ADAS および AD の分野における最初のパフォーマンス ベンチマーク テストを提供し、そのようなアルゴリズムの設計と応用に対する重要な視点と提案を提供します
1はじめに
オンライン 3D マルチオブジェクト トラッキング (MOT) は、先進運転支援システム (ADAS) および自動運転 (AD) の重要なコンポーネントです。近年、センサー技術や信号処理技術の発展に伴い、カメラ、ライダー、レーダーなどの各種センサーを活用したオンライン3D MOT技術が注目を集めています。さまざまなセンサーの中で、レーダーは極端な照明や厳しい気象条件下でも動作できる唯一の低コストセンサーとして、インスタンスのセグメンテーション、ターゲット検出、MOT などのセンシングタスクに広く使用されています。ただし、従来の自動車用レーダーは距離とドップラー速度でターゲットを効果的に識別できますが、レーダー測定の角度分解能が低いため、ターゲット検出とマルチターゲット追跡アルゴリズムのパフォーマンスは依然として制限されています。従来の自動車レーダーとは異なり、MIMO技術に基づいて最近登場した4Dイメージングレーダーは、ターゲットの距離、速度、方位角、ピッチ角情報を測定できるため、レーダーベースの3D MOTに新たな開発の可能性をもたらします。
3D MOT アルゴリズムの設計パラダイムは、モデルベースと深層学習ベースの 2 つのカテゴリに分類できます。モデルベースの設計パラダイムは、慎重に設計された多目的動的モデルと測定モデルを使用し、効率的で信頼性の高い 3D MOT 手法の開発に適しています。典型的なモデルベースの MOT フレームワークの中でも、検出-事後追跡戦略を使用した点ターゲット追跡フレームワークは、学界と産業界に広く受け入れられています。点ターゲット追跡フレームワークでは、各ターゲットが 1 回のセンサー スキャンで 1 つの測定ポイントのみを生成すると想定していますが、LIDAR および 4D 画像レーダーの場合、ターゲットは 1 回のスキャンで複数の測定ポイントを生成することがよくあります。したがって、ターゲット追跡を実行する前に、まず同じターゲットからの複数の測定値をターゲット検出器を通じてターゲット検出フレームなどの検出結果に処理する必要があります。検出後追跡フレームワークの有効性は、実際の LIDAR 点群データに基づく多くの 3D MOT タスクで検証されています
別のモデルとして統合検出追跡 (JDT) 戦略を使用した拡張ターゲット追跡 (EOT)ベースの MOT フレームワークは、最近学界で広く注目を集めています。 POT とは異なり、EOT はターゲットが 1 回のセンサー スキャンで複数の測定値を生成できることを前提としているため、JDT の実装時に追加のターゲット検出モジュールは必要ありません。関連する研究では、JDT-EOT は、実際の LIDAR 点群および自動車レーダー検出点データ上の単一ターゲットを追跡する場合に優れたパフォーマンスを達成できることが指摘されています。ただし、複雑な ADAS および AD シナリオにおけるオンライン 3D MOT タスクについては、実際のデータを使用して EOT を評価する研究はほとんどなく、これらの研究では、ADAS/AD に関するさまざまな種類のターゲットに対する EOT フレームワークの MOT パフォーマンスを詳細に評価していません。また、広く受け入れられているパフォーマンス指標を使用した実験結果の系統的な分析はありません。この記事の研究では、包括的な評価と分析を通じて、EOT フレームワークが複雑な ADAS および AD シナリオに適用でき、従来の TBD-POT フレームワークよりも優れた追跡パフォーマンスとコンピューティング効率を達成できるかどうかという未解決の質問に初めて答えることを試みます。この記事の主な貢献内容は主に次のとおりです。
- この記事は、POT フレームワークと EOT フレームワークを比較することにより、ADAS および AD 分野における 4D 画像レーダーに基づくオンライン 3D MOT 手法に関する将来の研究のための最初のパフォーマンス ベンチマークを提供します。この記事のパフォーマンス評価と分析は、POT フレームワークと EOT フレームワークのそれぞれの長所と短所を示し、オンライン 3D MOT アルゴリズムの設計に関するガイダンスと提案を提供します。
- EOT に基づくオンライン 3D MOT 手法の理論と実践の間のギャップを埋めるために、この記事では、実際の ADAS および AD シナリオにおける EOT フレームワークの体系的な研究を初めて実施します。学術界で広く研究されている JDT-EOT フレームワークのパフォーマンスは低いですが、この論文で提案されている TBD-EOT フレームワークは深層学習オブジェクト検出器の利点を活用しており、それによって JDT-EOT よりも優れた追跡パフォーマンスとコンピューティングを実現します。フレームワークと効率。
- 実験結果によると、トラッキング パフォーマンスと計算効率が高いため、4D 画像レーダーに基づくオンライン 3D MOT タスクでは、従来の TBD-POT フレームワークが依然として好ましい選択肢です。ただし、特定の状況では TBD-EOT フレームワークのパフォーマンスが TBD-POT フレームワークのパフォーマンスよりも優れており、実際の ADAS および AD アプリケーションで EOT フレームワークを使用できる可能性を示しています。
2. 方法
このセクションでは、TBD-POT、JDT-EOT、TBD-EOT など、4D 画像レーダー点群データのオンライン 3D MOT のための 3 つのアルゴリズム フレームワークを紹介します。以下の図に示されています:
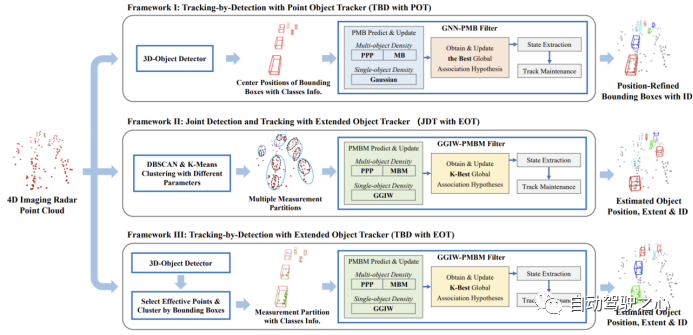
書き換えられた内容: A. フレームワーク 1: 検出後の追跡戦略を使用した点ターゲットの追跡 (未定 - 点ターゲットの追跡)
TBD-POT フレームワークは、さまざまなセンサーに基づく MOT 研究で広く受け入れられています。この追跡フレームワークでは、4D イメージング レーダー点群が最初にターゲット検出器によって処理されて 3D 検出フレームが生成され、ターゲットの位置、検出フレーム サイズ、向き、ターゲット カテゴリ、検出スコア、その他の情報が提供されます。計算を簡略化するために、POT アルゴリズムは通常、直交座標系の 2 次元の目標位置を測定として選択し、鳥瞰図 (BEV) の下で MOT を実行します。推定されたターゲット位置は、3D 検出フレームの他の情報と結合されて、最終的な 3D 追跡結果が得られます。 TBD-POT フレームワークには 2 つの主な利点があります: 1) POT アルゴリズムはターゲット タイプや検出スコアなどの追加情報を利用して追跡パフォーマンスを向上させることができます; 2) POT アルゴリズムは一般に EOT アルゴリズムよりも計算が複雑ではありません。
POT アルゴリズムとしてグローバル最近傍ポアソン マルチ ベルヌーイ フィルター (GNN-PMB) を選択します。これにより、LIDAR ベースのオンライン 3D MOT タスクで SOTA パフォーマンスが実現されます。 GNN-PMB は、PMB 密度を伝播することによってマルチターゲットの状態を推定します。未検出のターゲットはポアソン点過程 (PPP) によってモデル化され、検出されたターゲットはマルチ ベルヌーイ (MB) 密度によってモデル化されます。データの関連付けは、ローカルおよびグローバルの仮定を管理することによって実現されます。それぞれの瞬間において、測定値は、すでに追跡されたターゲット、新たに検出されたターゲット、または誤った警報に関連付けられる可能性があり、さまざまな局所仮説が形成されます。互換性のあるローカルな仮定は、現在のすべてのターゲットと測定値の間の関係を記述するグローバルな仮定に統合されます。複数のグローバル仮説を計算して伝播するポアソンマルチベルヌーイ混合 (PMBM) フィルターとは異なり、GNN-PMB は最適なグローバル仮説のみを伝播するため、計算の複雑さが軽減されます。要約すると、この記事で検討した最初のオンライン 3D MOT フレームワークは、深層学習ベースのオブジェクト検出器と GNN-PMB アルゴリズムを組み合わせたものです
B. フレームワーク 2: 共同検出と追跡の使用 戦略の拡張ターゲット追跡(JDT-EOT)
最初のフレームワーク TBD-POT とは異なり、JDT-EOT フレームワークは、複数のターゲットを同時に検出および追跡することで、4D 画像レーダー点群を直接処理できます。まず、点群がクラスター化されて、可能な測定分割 (点クラスター) が形成されます。その後、EOT アルゴリズムがこれらの点クラスターを使用して 3D MOT を実行します。理論的には、点群には前処理された 3D 検出フレームよりも豊富な情報があるため、このフレームワークはターゲットの位置と形状をより正確に推定し、ターゲットのミスを減らすことができます。ただし、大量のクラッターを含む 4D イメージング レーダー点群の場合、正確な測定分割を生成することは困難です。異なるターゲットの点群の空間分布も異なる可能性があるため、JDT-EOT フレームワークは通常、DBSCAN や K-means などの複数のクラスタリング アルゴリズムを異なるパラメータ設定と組み合わせて使用し、可能な限り多くの測定区分を生成します。これにより、EOT の計算の複雑さがさらに増し、このフレームワークのリアルタイム パフォーマンスに影響します。
この記事では、JDT-EOT フレームワークを実装するために、Gamma Gaussian Inverse Wishart (GGIW) 分布に基づいた PMBM フィルターを選択します。 GGIW-PMBM フィルターは、SOTA 推定精度と計算量を備えた EOT アルゴリズムの 1 つです。 PMBM フィルターが選択されたのは、アルゴリズムがマルチ ベルヌーイ混合物 (MBM) 密度を使用してターゲットをモデル化し、複数のグローバルな仮定を伝播するため、レーダー測定の高い不確実性への対処が容易になるためです。 GGIW モデルは、ターゲットによって生成される測定ポイントの数がポアソン分布に従い、単一の測定がガウス分布に従うことを前提としています。この仮定の下では、各ターゲットの形状は逆ウィシャート (IW) 密度で表される楕円であり、楕円の長軸と短軸を使用してターゲットの長方形の外枠を形成できます。この形状モデリングは比較的単純で、多くのタイプのターゲットに適しており、既存の EOT アルゴリズム実装の中で計算の複雑さが最も低くなります。
C. フレームワーク 3: 検出後の追跡戦略を使用した拡張ターゲット追跡 (TBD-EOT)
EOT フレームワークの下で深層学習オブジェクト検出器を活用するために、3 番目の MOT フレームワークである TBD-EOT を提案します。完全な点群上でクラスター化する JDT-EOT フレームワークとは異なり、TBD-EOT フレームワークは、クラスター化する前に、ターゲット 3D 検出フレーム内の有効なレーダー測定ポイントを最初に選択します。これらの測定ポイントは、実際のオブジェクトから取得される可能性が高くなります。 JDT-EOT と比較して、TBD-EOT フレームワークには 2 つの利点があります。まず、クラッタに起因する可能性のある測定ポイントを削除することにより、EOT アルゴリズムにおけるデータ関連付けステップの計算の複雑さが大幅に軽減され、誤検出の数も削減される可能性があります。第 2 に、EOT アルゴリズムは検出器から得られた情報を利用して追跡パフォーマンスをさらに向上させることができます。たとえば、ターゲットのカテゴリごとに異なる追跡パラメータを設定したり、検出スコアの低いターゲット検出フレームを破棄したりするなどです。 TBD-EOT フレームワークは、展開時に TBD-POT と同じターゲット検出器を使用し、EOT フィルターとして GGIW-PMBM を使用します。
3. 実験と分析
A. データセットと評価指標
この記事は、No. 0、8、12、18 に掲載されています。 VoD データセットの 3 つの MOT フレームワークが、TJ4DRadSet のシーケンス 0、10、23、31、および 41 の自動車、歩行者、および自転車のカテゴリで評価されました。 TBD-POT および TBD-EOT フレームワークに入力されるターゲット検出結果は、4D イメージング レーダー点群上の SOTA ターゲット検出器の 1 つである SMURF によって提供されます。 JDT-EOT ではターゲットの種類情報を取得できないため、GGIW-PMBM アルゴリズムの状態抽出プロセスにターゲットの形状とサイズに基づいてカテゴリを決定するヒューリスティックなターゲット分類ステップを追加しました。
この記事のその後の評価では、MOTA、MOTP、TP、FN、FP、IDS などの一般的に使用される一連の MOT パフォーマンス指標が選択されました。さらに、新しい MOT パフォーマンス指標である高次追跡精度 (HOTA) も適用しました。 HOTA は、検出精度 (DetA)、関連付け精度 (AssA)、および測位精度 (LocA) のサブ指標に分解でき、MOT パフォーマンスをより明確に分析するのに役立ちます。
トラッキング フレームワークのパフォーマンス比較の内容を書き直す必要があります
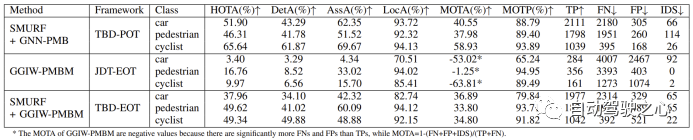
VoD データ セットでは、3 つの MOT に対して SMURF GNN-PMB および GGIW-PMBM が実装されていますフレームワーク アルゴリズム パラメーターの調整は SMURF GGIW-PMBM を使用して実行されました。それらのパフォーマンスを次の表に示します。
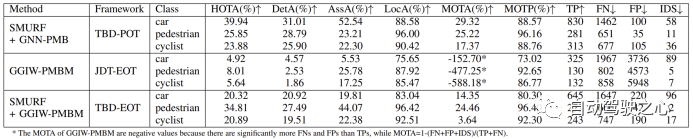
TJ4DRadSet データ セットでの各アルゴリズムのパフォーマンスを次の表に示します。
1) GGIW-PMBM のパフォーマンス
実験結果は、GGIW-PMBM のパフォーマンスが予想よりも低いことを示しています。追跡結果には多数の FP と FN が含まれるため、3 つのカテゴリに対する GGIW-PMBM の検出精度は低くなります。この現象の原因を分析するために、未分類の追跡結果を使用して、以下の表に示すように TP と FN を計算しました。 3 つのカテゴリの TP の数が大幅に増加していることが観察でき、GGIW-PMBM が実際のターゲット位置に近い追跡結果を生成できることを示しています。ただし、以下の図に示すように、GGIW-PMBM によって推定されたターゲットのほとんどは同様の長さと幅を持っているため、ヒューリスティック ターゲット分類ステップではターゲットのサイズに基づいてターゲットの種類を効果的に区別できなくなり、追跡パフォーマンスに悪影響を及ぼします。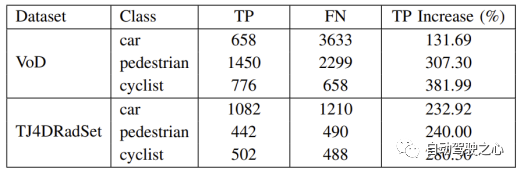
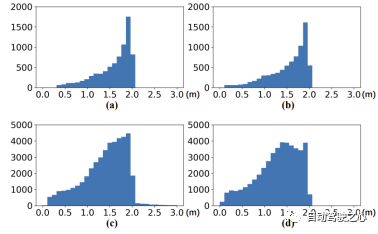
2) SMURF GNN-PMB および SMURF GGIW-PMBM
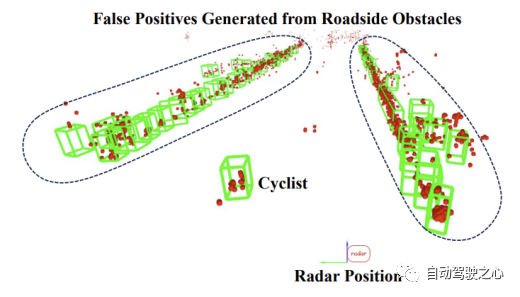
### のパフォーマンスSMURF GNN-PMB と SMURF GGIW-PMBM は両方とも、物体検出器からの情報を利用します。実験結果によると、自動車カテゴリにおける前者のパフォーマンスは後者のパフォーマンスよりも大幅に優れています。これは主に後者の方が自動車ターゲットの測位精度が低いためです。この現象の主な理由は、点群分布モデリングのエラーです。以下の図に示すように、車両ターゲットの場合、レーダー点群はレーダー センサーに近い側に集中する傾向があります。これは、測定点がターゲット表面上に均一に分布するという GGIW モデルの仮定と矛盾し、SMURF GGIW-PMBM によって推定されるターゲットの位置と形状が真の値から乖離する原因となります。したがって、車両などの大きなターゲットを追跡する場合、ガウス プロセスなどのより正確なターゲット測定モデルを使用すると、TBD-EOT フレームワークのパフォーマンスが向上する可能性がありますが、アルゴリズムの計算の複雑さも増加する可能性があります。
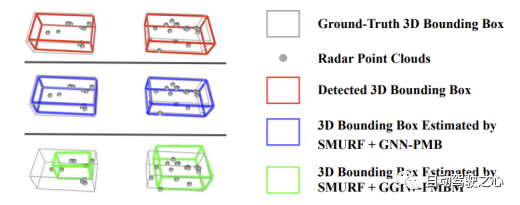 また、自転車カテゴリーにおける SMURF GGIW-PMBM と SMURF GNN-PMB のパフォーマンスの差が縮まり、歩行者カテゴリーにおける前者の HOTA インデックスが後者よりもさらに優れていることも観察されました。 。さらに、SMURF GGIW-PMBM では、歩行者および自転車カテゴリの IDS の数も少なくなります。これらの現象の原因には、第一に、GGIW-PMBM が推定された GGIW 密度に基づいてターゲットの検出確率を適応的に計算すること、第二に、GGIW-PMBM がターゲットの位置だけでなくターゲットの測定値も考慮して、ターゲットの可能性を計算することが考えられます。相関仮説 点の数と空間分布。歩行者や自転車などの小さなターゲットの場合、レーダー ポイントはターゲット表面上でより均等に分布しており、GGIW モデルの仮定とより一致しているため、SMURF GGIW-PMBM は点群からの情報を使用して、検出をより正確に推定できます。確率と関連する仮説の尤度を計算し、それによって軌道の中断とエラー相関を減らし、測位、相関、ID 維持のパフォーマンスを向上させます。
また、自転車カテゴリーにおける SMURF GGIW-PMBM と SMURF GNN-PMB のパフォーマンスの差が縮まり、歩行者カテゴリーにおける前者の HOTA インデックスが後者よりもさらに優れていることも観察されました。 。さらに、SMURF GGIW-PMBM では、歩行者および自転車カテゴリの IDS の数も少なくなります。これらの現象の原因には、第一に、GGIW-PMBM が推定された GGIW 密度に基づいてターゲットの検出確率を適応的に計算すること、第二に、GGIW-PMBM がターゲットの位置だけでなくターゲットの測定値も考慮して、ターゲットの可能性を計算することが考えられます。相関仮説 点の数と空間分布。歩行者や自転車などの小さなターゲットの場合、レーダー ポイントはターゲット表面上でより均等に分布しており、GGIW モデルの仮定とより一致しているため、SMURF GGIW-PMBM は点群からの情報を使用して、検出をより正確に推定できます。確率と関連する仮説の尤度を計算し、それによって軌道の中断とエラー相関を減らし、測位、相関、ID 維持のパフォーマンスを向上させます。
4. 結論
この論文では、4D イメージング レーダー点群に基づくオンライン 3D MOT タスクにおける POT フレームワークと EOT フレームワークのパフォーマンスを比較します。 VoD および TJ4DRadSet データセットの自動車、歩行者、および自転車のカテゴリで、TBD-POT、JDT-EOT、および TBD-EOT の 3 つのフレームワークの追跡パフォーマンスを評価します。結果は、従来の TBD-POT フレームワークが依然として有効であり、そのアルゴリズム実装 SMURF GNN-PMB が自動車および自転車カテゴリで最高のパフォーマンスを発揮することを示しています。ただし、JDT-EOT フレームワークはクラッター測定値を効果的に除去できないため、測定分割の仮定が多すぎて、GGIW-PMBM のパフォーマンスが不十分になります。この論文で提案する TBD-EOT フレームワークの下では、SMURF GGIW-PMBM は、歩行者カテゴリで最高の相関と測位精度を達成し、歩行者と自転車カテゴリで信頼性の高い ID 推定を達成し、TBD-POT フレームワークを超える優位性を実証します。ただし、SMURF GGIW-PMBM は、不均一に分布したレーダー点群を効果的にモデル化できないため、車両ターゲットの追跡パフォーマンスが低下します。したがって、より現実的で計算複雑性が低い拡張ターゲット モデルについては、今後さらなる研究が必要です。
 書き直す必要がある内容は次のとおりです。元のリンク: https ://mp.weixin .qq.com/s/ZizQlEkMQnlKWclZ8Q3iog
書き直す必要がある内容は次のとおりです。元のリンク: https ://mp.weixin .qq.com/s/ZizQlEkMQnlKWclZ8Q3iog
以上が4D 画像レーダーと 3D マルチターゲット追跡を組み合わせるにはどうすればよいですか? TBD-EOT が答えかもしれません!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
20
15
1376
52
77
11
18
20

 4K HD映像がわかりやすい!この大規模なマルチモーダル モデルは、Web ポスターのコンテンツを自動的に分析するため、作業者にとって非常に便利です。
Apr 23, 2024 am 08:04 AM
4K HD映像がわかりやすい!この大規模なマルチモーダル モデルは、Web ポスターのコンテンツを自動的に分析するため、作業者にとって非常に便利です。
Apr 23, 2024 am 08:04 AM
PDF、Web ページ、ポスター、Excel グラフの内容を自動的に分析できる大型モデルは、アルバイトにとってはあまり便利ではありません。上海 AILab、香港中文大学、その他の研究機関が提案した InternLM-XComposer2-4KHD (略称 IXC2-4KHD) モデルは、これを実現します。解像度制限が 1500x1500 以下である他のマルチモーダル大型モデルと比較して、この作業ではマルチモーダル大型モデルの最大入力画像が 4K (3840x1600) 解像度を超え、任意のアスペクト比と 336 ピクセルをサポートし、 4K 動的解像度の変更。発売から3日後、このモデルはHuggingFaceのビジュアル質疑応答モデルの人気ランキングで1位となった。扱いやすい
 CVPR 2024 | フォトリアルなシーン生成のための LiDAR 拡散モデル
Apr 24, 2024 pm 04:28 PM
CVPR 2024 | フォトリアルなシーン生成のための LiDAR 拡散モデル
Apr 24, 2024 pm 04:28 PM
原題: TowardsRealisticSceneGenerationwithLiDARDiffusionModels 論文リンク: https://hancyran.github.io/assets/paper/lidar_diffusion.pdf コードリンク: https://lidar-diffusion.github.io 著者の所属: CMU Toyota Research Institute 南カリフォルニア大学論文アイデア : 拡散モデル (DM) はフォトリアリスティックな画像合成に優れていますが、これを LIDAR シーン生成に適応させるには大きな課題が生じます。これは主に、ポイント空間で運用する DM が困難であるためです。
 RVフュージョンのパフォーマンスがすごい! RCBEVDet: レーダーにも春、最新の SOTA があります!
Apr 02, 2024 am 11:49 AM
RVフュージョンのパフォーマンスがすごい! RCBEVDet: レーダーにも春、最新の SOTA があります!
Apr 02, 2024 am 11:49 AM
上記と著者の個人的な理解は、このディスカッションペーパーが焦点を当てている主な問題は、自動運転のプロセスにおける 3D ターゲット検出テクノロジーの応用であるということです。環境ビジョンカメラ技術の開発により、3D オブジェクト検出のための高解像度のセマンティック情報が提供されますが、この方法は、深度情報を正確にキャプチャできないことや、悪天候や低照度条件でのパフォーマンスの低下などの問題によって制限されます。この問題に対応して、議論ではサラウンドビューカメラと経済的なミリ波レーダーセンサーを組み合わせた新しいマルチモード3D目標検出方法RCBEVDetが提案されました。この方法は、複数のセンサーからの情報を総合的に使用することで、より豊富なセマンティック情報を提供し、悪天候や低照度条件でのパフォーマンスの低下などの問題の解決策を提供します。この問題を解決するために、議論ではサラウンドビューカメラを組み合わせる方法が提案されました。
 LiDAR シミュレーションの新しいアイデア | LidarDM: 4D ワールドの生成に役立ち、シミュレーションキラー~
Apr 12, 2024 am 11:46 AM
LiDAR シミュレーションの新しいアイデア | LidarDM: 4D ワールドの生成に役立ち、シミュレーションキラー~
Apr 12, 2024 am 11:46 AM
原題: LidarDM: GenerativeLiDARSimulationinaGeneratedWorld 論文リンク: https://arxiv.org/pdf/2404.02903.pdf コードリンク: https://github.com/vzyrianov/lidardm 著者の所属: イリノイ大学、マサチューセッツ工科大学 論文のアイデア:この記事の紹介 LidarDM は、現実的で、レイアウトを認識し、物理的に信憑性があり、時間的に一貫性のある LIDAR ビデオを生成できる新しい LIDAR 生成モデルです。 LidarDM には、LIDAR 生成モデリングにおいて前例のない 2 つの機能があります。(1)
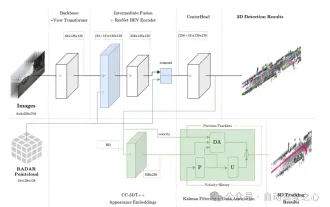 BEVFormerを超えて! CR3DT: RV フュージョンは新しい SOTA (ETH) の 3D 検出と追跡を支援します
Apr 24, 2024 pm 06:07 PM
BEVFormerを超えて! CR3DT: RV フュージョンは新しい SOTA (ETH) の 3D 検出と追跡を支援します
Apr 24, 2024 pm 06:07 PM
上記と筆者の個人的な理解 この記事では、3D ターゲット検出とマルチターゲット追跡のためのカメラとミリ波レーダーの融合手法 (CR3DT) を紹介します。 LIDAR ベースの手法はこの分野に高い基準を設定していますが、その高いコンピューティング能力と高コストにより、カメラベースの 3D ターゲット検出および追跡ソリューションの自動運転分野でのこのソリューションの開発は制限されています。コストが比較的低く、多くの学者の注目を集めていますが、結果が芳しくないためです。そこで、カメラとミリ波レーダーの融合が有力な解決策となりつつあります。既存のカメラ フレームワーク BEVDet の下で、ミリ波レーダーの空間情報と速度情報を融合し、それを CC-3DT++ 追跡ヘッドと組み合わせることで、3D ターゲットの検出と追跡の精度が大幅に向上しました。
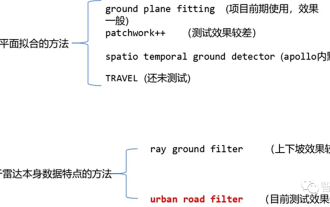 「詳細な分析」: 自動運転における LiDAR 点群セグメンテーション アルゴリズムの調査
Apr 23, 2023 pm 04:46 PM
「詳細な分析」: 自動運転における LiDAR 点群セグメンテーション アルゴリズムの調査
Apr 23, 2023 pm 04:46 PM
現在、一般的なレーザー点群セグメンテーション アルゴリズムには、平面フィッティングに基づく方法とレーザー点群データの特性に基づく方法の 2 つがあります。詳細は以下のとおりです。 点群地面分割アルゴリズム 01 平面フィッティングに基づく手法 - GroundPlaneFitting アルゴリズムの考え方: 簡単な処理方法は、空間を x 方向 (車の頭の方向) に沿っていくつかのサブ平面に分割し、次に、Ground Plane Fitting Algorithm (GPF) を使用すると、急な傾斜を処理できる地面セグメンテーション方法が得られます。この方法は、グローバル平面を単一フレームの点群に当てはめる方法であり、点群の数が多い場合に効果的ですが、点群がまばらな場合、16 ラインなどの検出漏れや誤検出が発生しやすくなります。ライダー。アルゴリズム擬似コード: 擬似コード アルゴリズム プロセスは、特定の点群 P のセグメンテーションの最終結果です。
 厳しい気象条件下でのLiDARセンシング技術ソリューション
May 10, 2023 pm 04:07 PM
厳しい気象条件下でのLiDARセンシング技術ソリューション
May 10, 2023 pm 04:07 PM
01概要 自動運転車は、さまざまなセンサーを利用して周囲の環境に関する情報を収集します。車両の動作は環境への配慮に基づいて計画されているため、安全上の理由からその信頼性が非常に重要です。アクティブ LIDAR センサーはシーンの正確な 3D 表現を作成できるため、自動運転車の環境認識に価値を加えることができます。 LiDAR の性能は、霧、雪、雨などの悪天候下では、光の散乱や遮蔽により変化します。この制限により、最近、知覚パフォーマンスの低下を軽減する方法に関する多大な研究が促進されています。このペーパーでは、悪天候に対処するための LiDAR ベースの環境センシングのさまざまな側面を収集、分析、および議論します。また、適切なデータの利用可能性、生の点群処理とノイズ除去、堅牢な知覚アルゴリズム、およびノイズを軽減するためのセンサー フュージョンなどのトピックについて説明します。
 Python で Pygame を使用してレーダー スキャン アニメーションを作成する
Aug 28, 2023 am 10:09 AM
Python で Pygame を使用してレーダー スキャン アニメーションを作成する
Aug 28, 2023 am 10:09 AM
Pygame は、ビデオ ゲームを作成するために設計されたクロスプラットフォーム Python モジュールのセットです。これには、Python プログラミング言語で使用するために設計されたコンピューター グラフィックスとサウンド ライブラリが含まれています。 Pygame はゲーム開発エンジンではありませんが、開発者が Python を使用して 2D ゲームを作成できるようにするツールとライブラリのセットです。 Pygame は、画像の読み込みと操作、サウンドの再生と録音、キーボードとマウスの入力処理、スプライトとグループの管理、衝突検出など、開発者がゲームを作成するのに役立つさまざまな関数とクラスを提供します。また、アニメーション、スクロール、タイルベースのマップなどの一般的なゲーム開発タスクのサポートも組み込まれています。 Pygame はオープンソースで無料で使用でき、Windows、macOS、Linux で使用できます。
