

生成モデルはインタラクティブな現実世界のシミュレーターを構築します。LeCun 氏はこれが非常に素晴らしいと考えています。

インターネット データでトレーニングされた生成モデルは、テキスト、画像、ビデオ コンテンツの作成方法に革命をもたらします。研究者の中には、おそらく生成モデルの次のマイルストーンは、道路での車の運転方法や食事の準備方法など、世界における人間の経験のあらゆる側面をシミュレートできる機能になるだろうと予測する人もいます。
現在、非常に包括的な現実世界シミュレーターの助けを借りて、人間はさまざまなシーンやオブジェクトと対話することができ、ロボットも疑似体験から学習することができ、これにより物理的損傷のリスクを回避できます。 。
しかし、このような現実世界のシミュレーターを構築する際の大きな障害の 1 つは、利用可能なデータ セットにあります。インターネット上には何十億ものテキスト、画像、ビデオ クリップが存在しますが、さまざまなデータ セットがさまざまな軸の情報をカバーしているため、世界の現実的な体験をシミュレートするには、これらのデータ セットを統合する必要があります。たとえば、ペアのテキスト画像データには豊富なシーンとオブジェクトが含まれますが、アクションはほとんど含まれません。ビデオの字幕と質問と回答のデータには、豊富な高レベルのアクティビティの説明が含まれますが、低レベルのモーションの詳細はほとんど含まれません。人間のアクティビティ データには、豊富な人間のアクションが含まれますが、アクションはほとんどありません。機械的な動き、ロボットデータには豊富なロボットの動きが含まれていますが、その数は限られています
上記の情報の違いは自然なものであり、克服するのが難しいため、目的に合わせて設計されたシステムを構築することが困難になります。キャプチャ 現実世界のシミュレーターは、現実世界の体験に困難をもたらします。
この記事では、カリフォルニア大学バークレー校、Google DeepMind、MIT およびその他の機関の研究者が、生成モデルを通じて現実世界のインタラクションを学習するユニバーサル シミュレーターである UniSim を調査し、ユニバーサルシミュレーターの第一歩。たとえば、UniSim は、「引き出しを開ける」などの高レベルの命令と、低レベルの命令の視覚的な結果をシミュレートすることで、人間とエージェントが世界とどのように対話するかをシミュレートできます。

- #論文アドレス: https://arxiv.org/pdf/2310.06114.pdf
- Paper のホームページ: https://universal-simulator.github.io/unisim/
この論文では、大量のデータ (インターネットのテキストと画像のペア、ナビゲーションからの豊富なデータ、人間の活動、ロボットの動作など、シミュレーションやレンダリングからのデータを含む) を組み合わせて条件付きビデオ生成を行います。フレームワーク。次に、この論文は、さまざまな軸に沿って豊富なデータを慎重に調整することによって、UniSim がデータのさまざまな軸からのエクスペリエンスをうまく統合し、データを超えて一般化して、静的なシーンとオブジェクトのきめ細かいモーション制御を通じて豊かなインタラクションを可能にすることを示しています。
次のビデオは、UniSim が長いインタラクション期間を持つ例をシミュレートする方法を示しています。このビデオでは、UniSim が 8 つのロボット動作命令を一度にシミュレートすることを示しています。 UniSim の人間の行動のシミュレーション:
UniSim の RL 戦略のシミュレーション展開は次のとおりです:
Meta のチーフ AI サイエンティスト、Yann LeCun 氏、NVIDIA 上級研究員の Jim Fan 氏、およびその他の業界専門家がこの調査を進めました。 LeCun 氏は本作に「クール」という評価を付けました
Jim Fan 氏はこの作品がとても興味深いと述べています。ビデオ拡散モデルはデータ駆動型の物理シミュレーションとして使用され、エージェントはロボット ハードウェアに触れたり損傷を与えたりすることなく、最適なアクションを計画、探索、学習できます。 LLM は単なるオペレーティング システムではなく、完全な現実シミュレータであると言えます。
この論文の最初の著者は、博士号を取得しています。カリフォルニア大学バークレー校の学生シェリー・ヤン氏は、「現実世界のモデルの学習が現実になりつつあります。」
と述べました。
現実世界のインタラクションのシミュレーション
図 3 に示すように、UniSim は、手を洗う、ボウルを持つ、切るなど、キッチン シーンでの一連の豊富なアクションをシミュレートできます。ニンジンと手を乾燥させます。図 3 の右上にはさまざまなスイッチが示されており、図 3 の下部には 2 つのナビゲーション シナリオが示されています。

書き直す必要がある内容は次のとおりです。対応図 3 の右下のナビゲーション シーン

がナビゲーション シーン
に対応します。上の図 3 の右下隅にある図 4 は、8 つの相互作用を順番に自己回帰的にシミュレーションする UniSim の例を示しています。 ##UniSim は、リッチなアクションをサポートするだけでなく、長距離インタラクションにより、非常に多様でランダムな環境変化を実現することもできます。たとえば、一番上のタオルを取り除いた後、表示されるオブジェクトには多様性があります (下の図 5 左を参照)

UniSim Real World Migration の結果。 UniSim の真の価値は現実世界をシミュレートすることにあり、図 7 は、VLM によって生成された言語プラン、言語プランに基づいて UniSim によって生成されたビデオ、および実際のロボットでの実行を示しています。

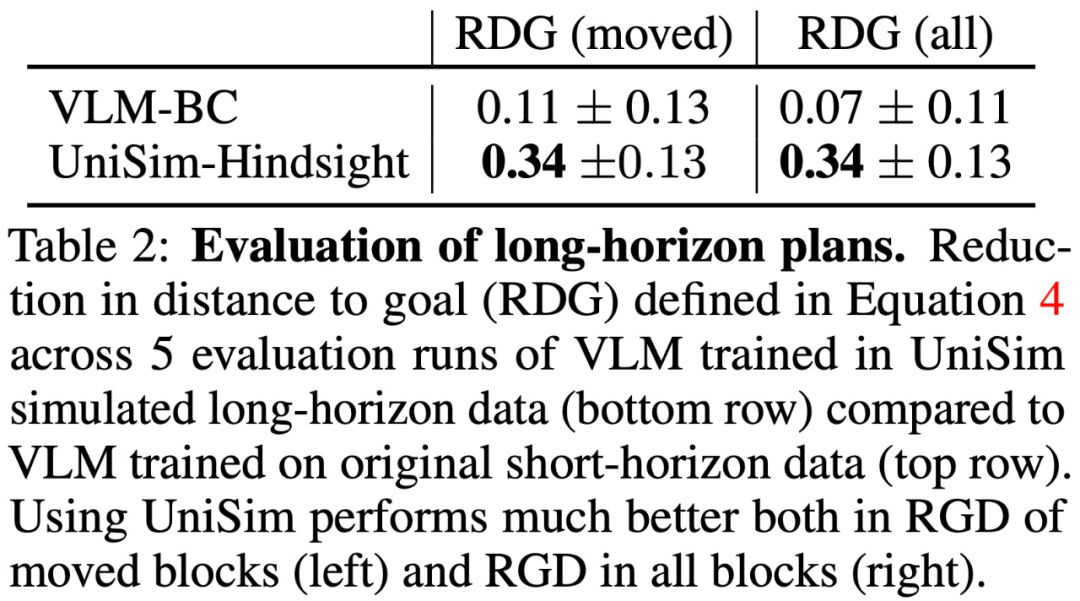
UniSim の移行機能を現実世界でテストすることに加えて、この記事ではシミュレーター ベースの評価も実施しました。結果を表 2 に示します。 :

強化学習用の実世界シミュレーター
 この実験では、現実世界をシミュレートする UniSim の能力も評価します。 -world ロボットはさまざまなアクションをどの程度うまく実行しますか? ロボットは、約 20 ~ 30 ステップの低レベルの制御操作を繰り返し実行することによって、エンドポイントを左右上下に移動します。表 3 は、RL トレーニングにより、さまざまなタスク、特に青いブロックを指すようなタスクで VLA ポリシーのパフォーマンスが大幅に向上することを示しています。次に、図 8 (下の行) に示すように、UniSim でトレーニングされたゼロショット RL ポリシーを実際のロボットに直接展開します。
この実験では、現実世界をシミュレートする UniSim の能力も評価します。 -world ロボットはさまざまなアクションをどの程度うまく実行しますか? ロボットは、約 20 ~ 30 ステップの低レベルの制御操作を繰り返し実行することによって、エンドポイントを左右上下に移動します。表 3 は、RL トレーニングにより、さまざまなタスク、特に青いブロックを指すようなタスクで VLA ポリシーのパフォーマンスが大幅に向上することを示しています。次に、図 8 (下の行) に示すように、UniSim でトレーニングされたゼロショット RL ポリシーを実際のロボットに直接展開します。
以上が生成モデルはインタラクティブな現実世界のシミュレーターを構築します。LeCun 氏はこれが非常に素晴らしいと考えています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
22
96
15
1382
52
83
11
22
96

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
