

すべての Douyin はネイティブの方言を話しています。2 つの主要なテクノロジーが地元の方言を「理解」するのに役立ちます

国慶節中、Douyin の「方言はあなたが本物の故郷の出身者であることを証明する」活動に全国のネチズンの熱狂的な参加が集まり、このテーマは Douyin チャレンジ リストのトップとなり、再生回数は50000000。
この「地方方言大賞」はインターネット上で瞬く間に人気となりましたが、これにはDouyinが新たに開始した地方方言自動翻訳機能の貢献が不可欠です。クリエイターが母国語の方言で短いビデオを録画した場合、「自動字幕」機能を使用して「北京語字幕に変換」を選択すると、ビデオ内の方言の音声が自動的に認識され、方言の内容が北京語の字幕に変換されます。これにより、他の地域のネットユーザーもさまざまな「暗号化された北京語」言語を簡単に理解できるようになります。福建省のネチズンが個人的にテストしたところ、「発音が異なる」福建省南部地域であっても、中国福建省の南東海岸地域に位置する地域であると述べた。福建省南部の文化と方言は他の地域とは大きく異なり、福建省の重要な文化地域とみなされています。福建省南部の経済は農業、漁業、工業が中心であり、主な農業産業は米、茶、果物の栽培です。福建省南部には土造りの建物、古代の村、美しいビーチなどの景勝地がたくさんあります。福建省南部の食べ物も非常に独特で、主にシーフード、ペストリー、福建料理が代表的です。全体として、閩南地方は魅力と独特な文化に満ちた地域であり、方言を正確に翻訳すると、「閩南地方は中国福建省の地域で、福建省の南東部の沿岸地域に位置します。文化」と表現することもできます。福建省南部の経済は主に農業、漁業、工業に基づいており、農業は米の栽培、お茶と果物が主産業 福建省南部の景勝地 土造りの建物、古代の村、美しいビーチなど数多くあります 福建省南部地域の食べ物も非常に特徴的で、海産物、菓子パン、福建料理が主な代表です全体として、福建省南部地域は魅力とユニークな文化に満ちた地元の言語です。Douyin でやりたいことを何でもする時代は終わりました。」

周知のとおり、音声認識や機械翻訳のモデル トレーニングには大量のトレーニング データが必要ですが、方言は話し言葉として普及しており、モデルのトレーニングに使用できる方言データはほとんどありません。この機能の技術サポートを提供したエンジン技術チームは画期的な進歩を遂げましたか?
#方言認識段階
長い間、 Huoshan Voice このチームは、一般的なビデオ プラットフォーム向けに音声認識技術に基づいたインテリジェントなビデオ字幕ソリューションを提供しており、簡単に言えば、ビデオ内の音声と歌詞を自動的にテキストに変換して、ビデオ作成を支援します。
#その過程で、技術チームは、従来の教師あり学習が手動でラベル付けされた教師ありデータに大きく依存していることを発見しました。特に、大規模言語の継続的な最適化と小規模言語のコールド スタートの点で重要です。中国語、北京語、英語などの主要言語を例にとると、ビデオプラットフォームはビジネスシナリオに豊富な音声データを提供しますが、教師付きデータが一定の規模に達すると、継続的なアノテーションの収益は非常に低くなります。 。したがって、技術者は、大規模言語の音声認識のパフォーマンスをさらに向上させるために、何百万時間ものラベルなしデータを効果的に使用する方法を考える必要があります。
比較的ニッチな言語または方言、リソース、人員、その他の理由により、データのラベル付けのコストは高くなります。ラベル付きデータが非常に少ない場合 (約 10 時間)、教師付きトレーニングの効果は非常に低く、正常に収束しないこともあります。また、購入したデータがターゲット シナリオと一致せず、ユーザーのニーズを満たすことができないことがよくあります。仕事。
#これに関して、チームは次の解決策を採用しました。
- 低リソース方言の自己監視
Wav2vec 2.0自己教師あり学習テクノロジーに基づいて、私たちのチームは、ラベル付きデータをほとんど使用せずに方言ASR機能を実現する効率的なWav2vecを提案しました。 Wav2vec2.0のトレーニング速度の遅さと効果の不安定さの問題を解決するために、2つの側面から改善策を講じました。まず、波形の代わりにフィルターバンク機能を使用して計算量を削減し、シーケンスの長さを短縮し、同時にフレーム レートを削減することで、トレーニング効率を 2 倍にします。次に、等しい長さのデータ ストリームと適応型連続マスクにより、トレーニングの安定性と効果が大幅に向上しました。ラベルなしの音声と 10 時間のラベル付き音声の本来の意味を区別するには、コンテンツを広東語に書き直す必要があります。 続けられました。結果は以下の表に示されており、Wav2vec 2.0 と比較すると、効率的な Wav2vec (w2v-e) では、100M および 300M パラメーター モデルで CER が相対的に 5% 減少し、トレーニング オーバーヘッドは半分になります。
さらに、チームは、自己教師あり事前トレーニング モデルによって微調整された CTC モデルをシード モデルとして使用し、ラベルのないデータを疑似ラベルし、それをエンドツーエンド LAS に提供しました。トレーニング用のパラメータが少ないモデル。これにより、モデル構造の移行が実現するだけでなく、推論計算の量も削減され、成熟したエンドツーエンド推論エンジンに直接展開して起動することができます。この手法は、リソースの少ない 2 つの方言に適用され、わずか 10 時間の注釈付きデータを使用して単語誤り率 20% 未満を達成しました。
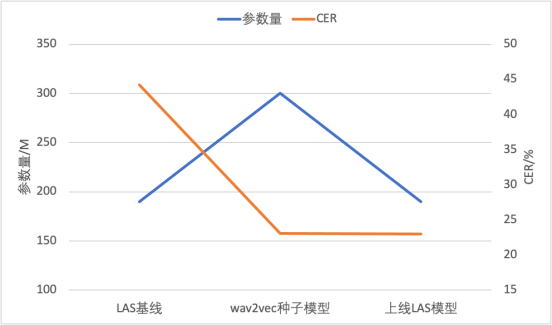
書き換えられた内容: 比較表: モデル パラメーターと CER

キャプション: 教師なしトレーニング ASR に基づく実装プロセス
- 方言の大規模事前トレーニング微調整トレーニング モード
# #教師付きデータのアノテーションの完了後、ASR モデルの継続的な最適化が重要な研究方向になりました。半教師あり学習または教師なし学習は、過去一定期間にわたって非常に人気がありました。教師なし事前トレーニングの主なアイデアは、ラベルなしデータセットを最大限に活用してラベル付きデータセットを拡張し、少量のデータを処理するときにより良い認識結果を達成することです。アルゴリズム プロセスは次のとおりです。
(1) まず、手動アノテーションに教師ありデータを使用し、シード モデルをトレーニングする必要があります。次に、このモデルを使用して、ラベルのないデータを疑似ラベルします。すべての予測が正確であるとは限らないため、値の低いデータをオーバートレーニングするには、いくつかの戦略を使用する必要があります。
#(3) 次に、生成された擬似ラベルを元のラベル付きデータと結合する必要があります。結合されたデータに対して共同トレーニングが実行されます
#書き換え内容: (4) 教師なしデータの擬似ラベル品質がそこまで良くなくても、学習過程で大量の教師なしデータが追加されるため、教師ありデータの表現ですが、多くの場合、より一般的な表現を取得できます。ビッグデータトレーニングに基づいて事前トレーニングされたモデルを使用して、手動で調整された方言データを微調整します。これにより、事前トレーニングされたモデルによってもたらされる優れた汎化パフォーマンスを維持しながら、方言に対するモデルの認識効果を向上させることができます。 5 つの方言 書き換えが必要なコンテンツの比率) は、35.3% から 17.21% です。書き換え: 5 つの方言の平均 CER (文字誤り率) を書き換える必要があるものから最適化: 35.3% から 17.21%
| 元の意味を変更しないようにするには、コンテンツを広東語に書き直す必要があります。
|
#福建省南部は、中国福建省の南東海岸に位置する地域です。福建省南部の文化と方言は他の地域とは大きく異なり、福建省の重要な文化地域とみなされています。福建省南部の経済は農業、漁業、工業が中心であり、主な農業産業は米、茶、果物の栽培です。福建省南部には土造りの建物、古代の村、美しいビーチなどの景勝地がたくさんあります。福建省南部の食べ物も非常に独特で、主にシーフード、ペストリー、福建料理が代表的です。全体として、福建省南部地域は魅力とユニークな文化に満ちた場所です。 |
#書き換えられた内容は次のとおりです: 北京 |
##中华国语
| #書き直す必要がある内容は次のとおりです: Southwest Mandarin|||
| #14.05##48.87 | 41.29 | ||||
#17.21 |
13.14 |
## 書き換える必要があるのは次のとおりです: 19.60 |
19.50 |
#10.95 |
# 通常の状況では、機械翻訳モデルのトレーニングには大量のコーパスのサポートが必要です。しかし、方言は話し言葉で伝わることが多く、現在では方言話者は年々減少しています。これらの現象により、方言データの収集が困難になり、方言機械翻訳の効果を高めることが困難になっています
方言不足の問題を解決するにはデータ、霍山 翻訳チームは、整列強化手法
を補完した による対照学習を導入した多言語翻訳モデル mRASP (multilingual Random Aligned Substitution Pre-training) と mRASP2 を提案しました。単一言語コーパスと二言語コーパスを組み合わせる 統一されたトレーニング フレームワークに組み込まれており、コーパスを最大限に活用して言語に依存しない表現を学習し、多言語翻訳のパフォーマンスを向上させます。
文書アドレス: https://arxiv.org/abs/2105.09501
対照的な学習タスクを追加する設計は、古典的な仮定に基づいています。異なる言語の同義文のエンコードされた表現は、高次元空間の隣接する位置にある必要があります。異なる言語の同義の文は同じ意味を持ち、つまり「エンコード」プロセスの出力は同じであるためです。例えば、「おはようございます」と「おはようございます」という二つの文は、中国語と英語が理解できる人にとっては同じ意味を持ちますが、これも「高次元空間における隣接位置の符号化表現」に相当します。
トレーニング目標を再設計する
従来の On theクロスエントロピー損失に基づいて、マルチタスク形式でトレーニングするために対比損失が追加されます。図のオレンジ色の矢印は、従来、機械翻訳の学習にクロス エントロピー ロス (CE ロス) を使用していた部分を示し、黒い部分はコントラスト ロス (CTR ロス) に対応する部分を示します。
#単語アライメント データ拡張方法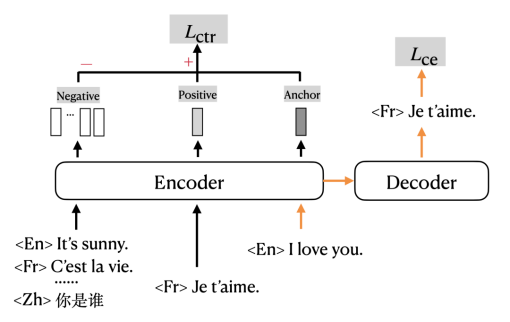
Aligned Augmentation ( AA) は、mRASP の Random Aligned Substitution (RAS) メソッドから開発されました。 #書き換えた内容は以下の通りです。 図によると、図(a)は対訳コーパスの強化過程を示しています。 , 図(b)は、単一言語コーパスの強化プロセスを示しています。図 (a) では、元の英語の単語が対応する中国語の単語に置き換えられており、図 (b) では、元の中国語の単語が英語、フランス語、アラビア語、およびドイツ語に置き換えられています。 mRASP の RAS は、二か国語の同義語辞書を提供するだけでよい最初の置換方法と同等ですが、2 番目の置換方法は複数の言語を含む同義語辞書を提供する必要があります。アライメント強化方法を使用する場合、図 (a) の方法のみを使用するか、図 (b) の方法のみを使用するかを選択できることに注意してください。 ## 実験結果は、mRASP2 が教師あり、教師なし、およびゼロリソースのシナリオで翻訳効果の向上を達成することを示しています。このうち、教師ありシナリオの平均改善は 1.98 BLEU、教師なしシナリオの平均改善は 14.13 BLEU、ゼロリソース シナリオの平均改善は 10.26 BLEU です。
この方法は、幅広いシナリオで大幅なパフォーマンスの向上を達成し、低リソース言語のトレーニング データが不十分であるという問題を大幅に軽減できます。 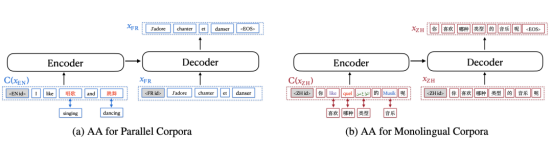
最後に書いてください
方言と北京語の補語相互はすべて中国の伝統文化の重要な表現です。表現方法としての方言は、中国人の感情や故郷との絆を表します。短いビデオと方言翻訳を通じて、ユーザーは全国各地の文化を垣根なく理解することができます。元の意味を維持するには、コンテンツを広東語に書き直す必要があることがサポートされています。 、閩語、呉語(書き換えられる内容は:北京)、書き換えが必要な内容は:西南北京語(四川省)、中原北京語(陝西省、河南省)など、さらに多くの方言がサポートされる予定だという。今後、様子を見ましょう。
以上がすべての Douyin はネイティブの方言を話しています。2 つの主要なテクノロジーが地元の方言を「理解」するのに役立ちますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
22
96
15
1382
52
83
11
22
96

 Bytedance Beanbao 大型モデルがリリース、Volcano Engine フルスタック AI サービスが企業のインテリジェントな変革を支援
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao 大型モデルがリリース、Volcano Engine フルスタック AI サービスが企業のインテリジェントな変革を支援
Jun 05, 2024 pm 07:59 PM
Volcano Engine の社長である Tan Dai 氏は、大規模モデルを実装したい企業は、モデルの有効性、推論コスト、実装の難易度という 3 つの重要な課題に直面していると述べました。複雑な問題を解決するためのサポートとして、適切な基本的な大規模モデルが必要です。また、サービスは低コストの推論を備えているため、大規模なモデルを広く使用できるようになり、企業がシナリオを実装できるようにするためには、より多くのツール、プラットフォーム、アプリケーションが必要になります。 ——Huoshan Engine 01 社長、Tan Dai 氏。大きなビーンバッグ モデルがデビューし、頻繁に使用されています。モデル効果を磨き上げることは、AI の実装における最も重要な課題です。 Tan Dai 氏は、良いモデルは大量に使用することでのみ磨かれると指摘しました。現在、Doubao モデルは毎日 1,200 億トークンのテキストを処理し、3,000 万枚の画像を生成しています。企業による大規模モデルシナリオの実装を支援するために、バイトダンスが独自に開発した豆包大規模モデルが火山を通じて打ち上げられます。
 マーケティング効果が大幅アップ、AIGC動画制作はこう活用すべき
Jun 25, 2024 am 12:01 AM
マーケティング効果が大幅アップ、AIGC動画制作はこう活用すべき
Jun 25, 2024 am 12:01 AM
1 年以上の開発を経て、AIGC はテキスト対話と画像生成からビデオ生成に徐々に移行してきました。 4 か月前を振り返ると、Sora の誕生によりビデオ生成トラックに再編が起こり、ビデオ作成分野における AIGC の適用範囲と深さが精力的に促進されました。大型モデルの話題が飛び交う時代において、私たちは映像生成による視覚的な衝撃に驚かされる一方で、実装の難しさに直面しています。確かに大規模モデルは技術研究開発から応用実践までまだ慣らし運転の段階にあり、実際のビジネスシナリオに基づいたチューニングが必要ですが、理想と現実の距離は徐々に縮まりつつあります。マーケティングは、人工知能テクノロジーの重要な実装シナリオとして、多くの企業や実務家がブレークスルーを実現したい方向性となっています。適切な方法をマスターすると、ビデオをマーケティングするクリエイティブなプロセスがより簡単になります。
 Huoshan Voice TTS の技術力は国家検査検疫センターによって認定されており、MOS スコアは 4.64 という高さです。
Apr 12, 2023 am 10:40 AM
Huoshan Voice TTS の技術力は国家検査検疫センターによって認定されており、MOS スコアは 4.64 という高さです。
Apr 12, 2023 am 10:40 AM
このたび、Volcano Engine 音声合成製品は、国家音声画像認識製品品質検査試験センター(以下、「AI 国家検査センター」)が発行する音声合成強化検査試験証明書を取得し、以下の基準を満たしました。音声合成の基本要件と拡張要件 AI 国家検査センターの最高レベルの標準。この評価は、標準中国語、複数の方言、複数の言語、混合言語、複数の音色、およびパーソナライゼーションの側面から実施され、製品のテクニカル サポート チームである Volcano Voice チームが豊富なサウンド ライブラリを提供します。音色MOSスコアは4.64点と業界トップクラスの最高スコアを記録しました。我が国の品質検査システムにおける人工知能分野における音声および画像製品の最初で唯一の国家品質検査および試験機関として、AI 国家検査センターはインテリジェント化の促進に取り組んできました。
 パーソナライズされたエクスペリエンスに重点を置き、ユーザーの維持は完全に AIGC に依存していますか?
Jul 15, 2024 pm 06:48 PM
パーソナライズされたエクスペリエンスに重点を置き、ユーザーの維持は完全に AIGC に依存していますか?
Jul 15, 2024 pm 06:48 PM
1. 消費者は製品を購入する前に、ソーシャル メディアで製品レビューを検索および閲覧します。したがって、企業にとってソーシャルプラットフォームで製品をマーケティングすることがますます重要になっています。マーケティングの目的は次のとおりです。 製品の販売促進 ブランド イメージの確立 ブランド認知度の向上 顧客の誘致と維持 最終的に企業の収益性の向上 大型モデルは優れた理解力と生成機能を備えており、閲覧と分析によってユーザーにパーソナライズされた情報を提供できますユーザーデータコンテンツの推奨事項。 「AIGC体験スクール」第4回では、「マーケティングコンバージョン率」向上におけるAIGCテクノロジーの役割について、ゲスト2名が深く語り合います。ライブ配信時間: 7 月 10 日 19:00 ~ 19:45 ライブ配信トピック: ユーザーの維持、AIGC はパーソナライゼーションを通じてコンバージョン率をどのように向上させますか?番組第4話では大切なお二人をお招きしました
 Huoshan Voice の教師なし事前トレーニング技術と「アルゴリズムの最適化 + エンジニアリングの革新」の実装を徹底調査
Apr 08, 2023 pm 12:44 PM
Huoshan Voice の教師なし事前トレーニング技術と「アルゴリズムの最適化 + エンジニアリングの革新」の実装を徹底調査
Apr 08, 2023 pm 12:44 PM
長年にわたり、Volcano Engine は、一般的なビデオ プラットフォーム向けに、音声認識テクノロジーに基づいたインテリジェントなビデオ字幕ソリューションを提供してきました。簡単に言うと、AI技術を利用して動画内の音声や歌詞を自動でテキスト化し、動画作成を支援する機能です。しかし、プラットフォーム ユーザーの急速な増加と、より豊富で多様な言語タイプの要求に伴い、従来使用されてきた教師あり学習テクノロジーがますますボトルネックに達し、チームは大きな問題に直面しています。ご存知のとおり、従来の教師あり学習は、特に大規模言語の継続的な最適化や小規模言語のコールド スタートにおいて、手動で注釈が付けられた教師ありデータに大きく依存します。中国語、北京語、英語などの主要言語を例に挙げると、ビデオプラットフォームはビジネスシナリオに十分な音声データを提供しますが、教師付きデータが一定の規模に達した後は、継続的に音声データを提供します。
 すべての Douyin はネイティブの方言を話しています。2 つの主要なテクノロジーが地元の方言を「理解」するのに役立ちます
Oct 12, 2023 pm 08:13 PM
すべての Douyin はネイティブの方言を話しています。2 つの主要なテクノロジーが地元の方言を「理解」するのに役立ちます
Oct 12, 2023 pm 08:13 PM
国慶節中、Douyin の「方言の一言は故郷の出身であることを証明する」キャンペーンに全国のネットユーザーの熱狂的な参加を集め、このテーマは Douyin チャレンジ リストのトップとなり、再生回数は 5,000 万回を超えました。この「地方方言大賞」はインターネット上で瞬く間に人気を博しましたが、これにはDouyinが新たに開始した地方方言自動翻訳機能の貢献が不可欠です。クリエイターが母国語の方言で短いビデオを録画した場合、「自動字幕」機能を使用して「北京語字幕に変換」を選択すると、ビデオ内の方言の音声が自動的に認識され、方言の内容が北京語の字幕に変換されます。これにより、他の地域のネットユーザーもさまざまな「暗号化された北京語」言語を簡単に理解できるようになります。福建省のネチズンが個人的に試してみたところ、「発音が異なる」福建省南部も中国福建省の地域であるとのこと。
 Volcano EngineとYiliが共同主催した「Health + AI」エコロジーイノベーションコンテストが成功裡に終了
Jan 13, 2024 am 11:57 AM
Volcano EngineとYiliが共同主催した「Health + AI」エコロジーイノベーションコンテストが成功裡に終了
Jan 13, 2024 am 11:57 AM
Health + AI =? 中高年向け脳健康栄養ソリューション、デジタルインテリジェント栄養・健康サービス、AIGCビッグヘルスコミュニティソリューション…「Health + AI」エコロジーイノベーション競争の展開により、それぞれに含まれる内容革新的なソリューションが登場しようとしており、「健康 + AI =?」に対する答えが徐々に明らかになりつつあります。 12月26日、Yili GroupとVolcano Engineが共催した「Health + AI」エコロジーイノベーションコンペティションが成功裡に閉幕し、Shanghai Bosten Network Technology Co., Ltd.やZhongke Suzhou Intelligent Computing Technology Research Instituteなど6社が優勝した。際立っていた。 1か月以上続いたコンテストで、伊利氏は優れた科学技術企業と手を組み、AI技術と健康産業の徹底的な統合を模索し、コンテストへの期待を高め続けた。 「健康+AI」エコイノベーションコンペティション
 Volcano Engine による Beyond のクラシック コンサートの超鮮明な復元、技術的能力が一般公開されました
Apr 09, 2023 pm 11:51 PM
Volcano Engine による Beyond のクラシック コンサートの超鮮明な復元、技術的能力が一般公開されました
Apr 09, 2023 pm 11:51 PM
7月3日の夜、Douyinはユニバーサルミュージックのレーベルであるポリグラムと協力して、火山エンジンによって超高解像度で復元されたBeyond Live 1991ライフコンタクトコンサートと記念コンサートの厳選されたコンテンツをライブブロードキャストし、より多くの人々を魅了しました。 1億4,000万回以上の再生回数。 Beyond は 1983 年に設立されたロック バンドです。広東音楽の隆盛とともに、Beyond バンドの名前は時代の文化的な痕跡となりました。 「Beyond Live 1991」は、Beyond が紅磡競技場で開催した最初のコンサートで、その後ポリグラムからリリースされた DVD は 1990 年代にはほとんど入手困難でした。以来 31 年が経ち、このコンサートは何世代にもわたるファンの音楽的啓蒙と青春の思い出となっています。撮影機材や記録メディアなどにより制限されます。
