

GPT-3 などの大規模言語モデルの出現により、自然言語処理 (NLP) の分野で大きな進歩が見られました。これらの言語モデルには、人間のようなテキストを生成する機能があり、チャットボットや翻訳などのさまざまなシナリオで広く使用されています

ただし、専門化とカスタマイズとなると、アプリケーションシナリオで使用される場合、汎用の大規模言語モデルでは専門的な知識が不十分な場合があります。特殊なコーパスを使用してこれらのモデルを微調整するには、多くの場合、費用と時間がかかります。 「Retrieval Enhanced Generation」(RAG)は、プロフェッショナル アプリケーション向けの新しいテクノロジー ソリューションを提供します。
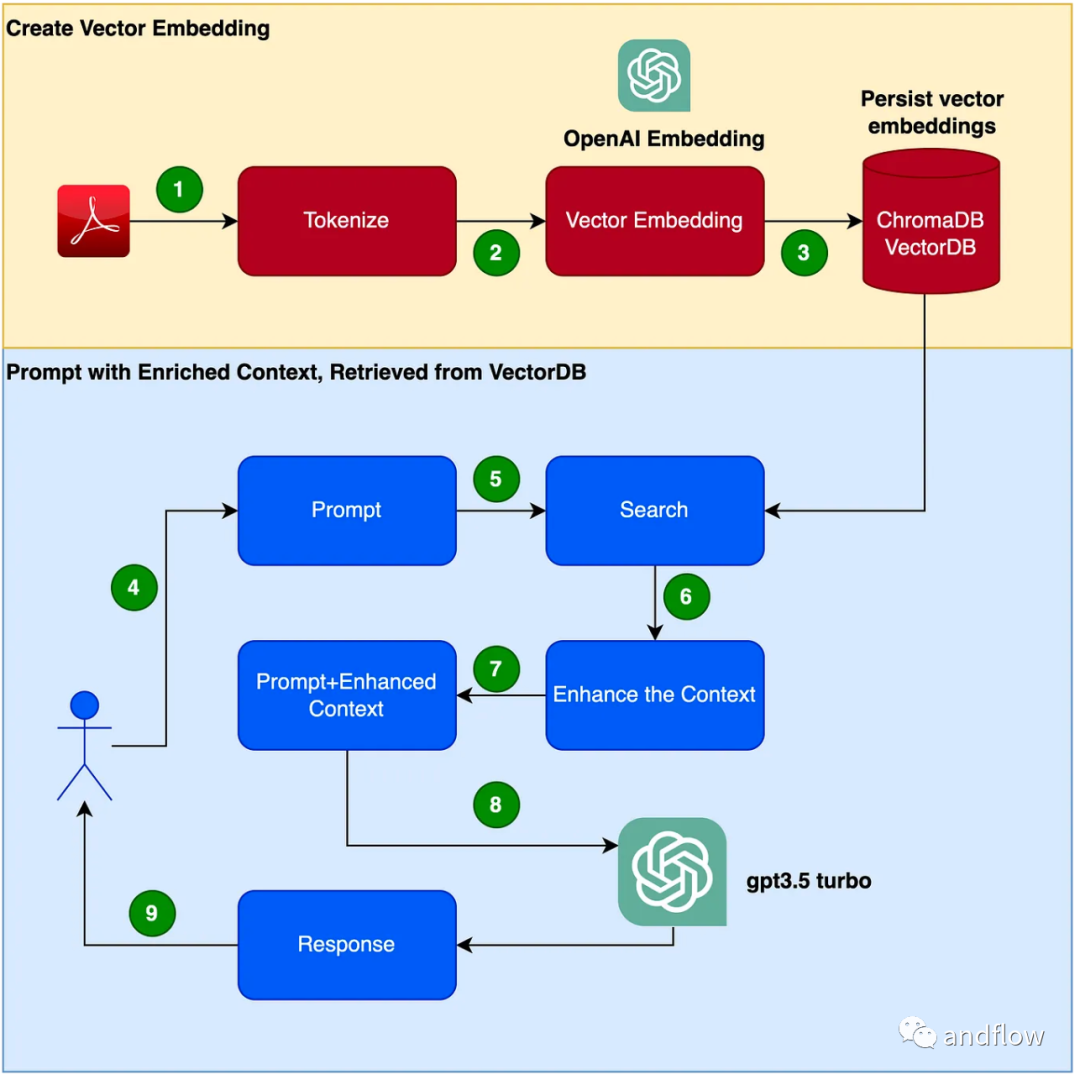
以下では、主に RAG がどのように機能するかを紹介し、製品マニュアルを専門的なコーパスとして使用し、GPT-3.5 Turbo を質疑応答モデルとして使用する実践例を使用して、その効果を検証します。
ケース: 特定の製品に関する質問に回答できるチャットボットを開発します。企業には独自のユーザー マニュアルがあります。
RAG は、ドメイン固有の質問と回答に対する効果的なソリューションを提供します。主に業界の知識を保存および検索用のベクトルに変換し、検索結果とユーザーの質問を組み合わせて迅速な情報を形成し、最後に大規模なモデルを使用して適切な回答を生成します。検索メカニズムと言語モデルを組み合わせることで、モデルの応答性が大幅に向上します。
チャットボット プログラムを作成する手順は次のとおりです。
(1) Python 仮想環境をセットアップする バージョンや依存関係の競合を避けるために、Python をサンドボックス化する仮想環境をセットアップします。次のコマンドを実行して、新しい Python 仮想環境を作成します。
需要重写的内容是:pip安装virtualenv,python3 -m venv ./venv,source venv/bin/activate
書き換える必要がある内容は次のとおりです: (2) OpenAI キーの生成
GPT を使用するにはアクセスに OpenAI キーが必要です
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
export OPENAI_API_KEY=<openai-key></openai-key>
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData,embeddings,collection_name=collection_name,persist_directory=persist_directory)vectDB.persist()
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm(OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
chat_history = []qry = ""while qry != 'done':qry = input('Question: ')if qry != exit:response = chatQA({"question": qry, "chat_history": chat_history})print(response["answer"])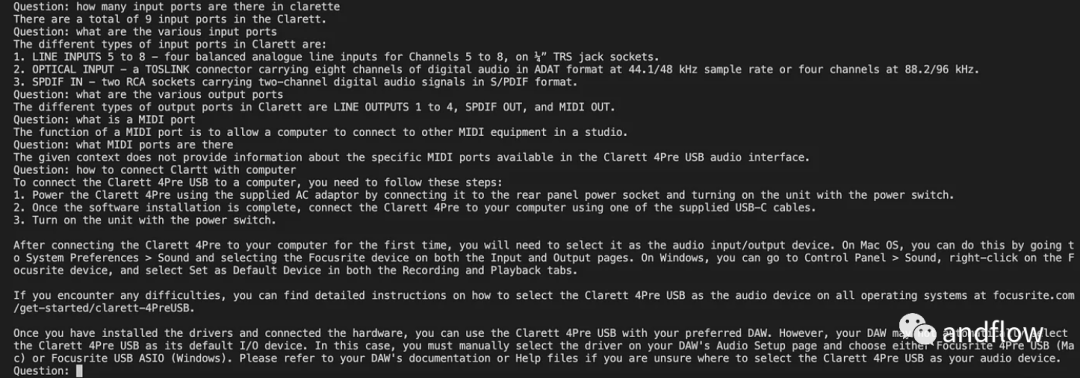

RAG は、GPT などの言語モデルの利点と情報検索の利点を組み合わせています。特定の知識コンテキスト情報を利用してプロンプトワードの豊富さを強化することにより、言語モデルはより正確な知識コンテキストに関連した回答を生成できます。 RAG は、「微調整」よりも効率的でコスト効率の高いソリューションを提供し、業界アプリケーションまたはエンタープライズ アプリケーション向けにカスタマイズ可能な対話型ソリューションを提供します。
以上がエンジニアリング効率の向上 - 拡張検索生成 (RAG)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



